Qu'est-ce qu'une base de données relationnelle (SGBDR) ?
Stockez et gérez des données structurées dans des tables aux relations définies, en garantissant l'intégrité des données grâce aux propriétés ACID.
- Comprendre ce que sont les systèmes de gestion de bases de données relationnelles (SGBDR) et comment ils organisent les données en tables structurées et liées entre elles.
- Découvrir les principes des bases de données relationnelles, notamment les clés primaires, les clés étrangères, la normalisation et les requêtes SQL.
- Comprendre pourquoi les solutions SGBDR demeurent essentielles pour les systèmes transactionnels exigeant la cohérence des données et l'intégrité référentielle.
Qu'est-ce qu'une base de données relationnelle ?
Une base de données relationnelle est un type de base de données qui stocke les données et y donne accès dans des tables pouvant être liées entre elles par des colonnes et des lignes communes, appelées relations, avec des identifiants uniques (clés) qui indiquent les différentes relations entre les tables.
Ce modèle relationnel est similaire à un modèle de feuille de calcul en ce sens que les lignes représentent les enregistrements individuels, tels que les clients, les comptes ou les transactions, tandis que les colonnes représentent les attributs de ces enregistrements, tels que l'ID client, le numéro de compte ou le montant de la transaction. Avec ce modèle, les lignes d'une table peuvent être liées aux lignes d'une autre table à l'aide de clés communes qui établissent les relations entre les tables.
Ce modèle fournit un moyen standard de représenter et d'interroger des données qui peut être utilisé par une multitude d'applications.
Un RDBMS (RDBMS) est une solution (parfois appelée moteur de base de données) qui implémente le modèle de base de données relationnelle et gère les données relationnelles (et pas uniquement les tables), depuis les opérations d'écriture et de lecture sur disque jusqu'à la maintenance des index, en passant par l'exécution des query et l'application de l'intégrité des données.
Concepts fondamentaux du modèle relationnel
Tables, lignes et colonnes
La structure fondamentale du modèle relationnel est l'organisation des données en tables, lignes et colonnes. Les tables sont des structures de données bidimensionnelles créées pour présenter un ensemble de données associées, organisées de manière logique pour permettre l'exécution de requêtes structurées.
Les lignes représentent des entités ou des enregistrements spécifiques (tuples) dans une table de base de données relationnelle et contiennent la valeur de chaque colonne.
Les colonnes représentent les catégories d'attributs de chaque enregistrement d'une ligne.
En substance, les colonnes définissent la structure et les lignes fournissent les données réelles. Un simple tableau de produits peut inclure les lignes de produits spécifiques suivantes avec des colonnes d'attributs associés :
| ID de produit | Nom du produit | Type de produit | Prix ($) |
|---|---|---|---|
| PSHL16 | Saucisse de porc piquante de Chuck | Saucisses de porc piquantes (450 g) | 5.99 |
| PSML16 | Chuck’s Mild Pork Sausage | Saucisses de porc douces (1 lb) | 5.99 |
| GTS16 | Chuck’s Ground Turkey Sausage | Dinde hachée assaisonnée (1 lb) | 6.59 |
| GT48 | Chuck’s Ground Turkey | Dinde hachée (3 lb) | 18.59 |
Schéma et données structurées
Le schéma d'une base de données relationnelle décrit la structure de la base de données. Il définit un modèle décrivant l'apparence attendue des données et les règles qu'elles doivent respecter. Les données structurées sont stockées dans un format cohérent et prévisible conformément à ce schéma (lignes et colonnes avec des relations cohérentes qui définissent quels types de données peuvent aller où et comment elles doivent être représentées).
Un bon schéma assure l'intégrité et la cohérence des types de données. Avec une structure connue, vous pouvez optimiser le stockage et les queries pour maintenir les performances et améliorer la compréhension, car chaque table et chaque colonne a la même signification.
Contraintes et index
Il peut y avoir des contraintes et des règles lors de l'écriture dans un tableau. Par exemple, dans l'exemple ci-dessus, chaque produit doit être associé à un ID de produit réel et chaque type de produit décrira les produits en boyaux (saucisses) ou hachés ainsi que le poids de manière cohérente. Il peut également définir des garde-fous, par exemple que chaque colonne doit contenir des valeurs (NOT NULL) sans doublons (UNIQUE), à l'exception du prix.
Cela signifie que chaque ligne possède les mêmes champs et que chaque champ a la même signification. Avec un schéma strict, les données restent propres, les relations restent valides et les requêtes restent prévisibles.
Les bases de données relationnelles peuvent également avoir des index qui permettent de trouver plus rapidement des lignes sans une analyse complète de la table. Un index stocke les valeurs de la colonne et fournit des pointeurs vers les lignes de la table où ces valeurs apparaissent. Les performances peuvent être ralenties lors de l'interrogation de grandes tables, et l'indexation évite d'analyser chaque ligne d'une table.
Les bases de données stockent les index dans plusieurs types de structures optimisées pour améliorer la vitesse de récupération des données :
- L'indexation en arbre B est une structure de données courante conçue pour gérer efficacement de grands datasets en réduisant la hauteur de l'arbre. Chaque nœud d'un arbre B peut stocker plusieurs clés et avoir plusieurs enfants, ce qui minimise le nombre d'opérations d'E/S disque requises pour l'accès aux données. En autorisant plus d'enfants sous un même nœud qu'un arbre de recherche binaire auto-équilibré classique, l'arbre B réduit la hauteur de l'arbre et place les données dans moins de blocs séparés.
- Les tables de hachage sont des structures de données qui associent des clés à des valeurs et utilisent une fonction de hachage pour convertir une clé en un indice où la valeur correspondante est stockée. Les index basés sur le hachage sont efficaces pour les recherches par correspondance exacte, mais ils ne sont pas universellement pris en charge ou utilisés comme type d'index par défaut dans tous les RDBMS et ne préservent pas l'ordre comme les B-Trees.
Clés et relations
Les clés sont essentielles pour garantir l'unicité, l'intégrité et la récupération efficace des données. Elles identifient de manière unique les lignes, établissent des relations entre les tables et empêchent la duplication, formant ainsi l'épine dorsale de la conception de schémas relationnels. Les points de données dans les tables peuvent être joints avec des clés communes, ce qui permet de requêter les tables pour produire des rapports. En utilisant des clés communes, les relations peuvent être de type un-à-un, un-à-plusieurs et plusieurs-à-plusieurs.
Les tables se connectent à l'aide de plusieurs types de clés :
- Les super-clés sont des ensembles d'un ou plusieurs attributs qui peuvent identifier un enregistrement de manière unique.
- Une clé candidate est un ensemble minimal d'attributs permettant d'identifier de manière unique un enregistrement
- Une clé primaire est une clé unique qui identifie une ligne dans sa table. Par exemple, dans une table de clients, l'ID client serait une clé primaire.
- Une clé alternative est une clé candidate qui n'est pas choisie comme clé primaire.
- Une clé étrangère est une colonne qui pointe vers une clé primaire dans une autre table. Par exemple, une table de transactions peut faire référence à l'ID client de la table des clients avec Orders.customer_id.
- Une clé composite est requise lorsqu'une combinaison de deux ou plusieurs attributs est nécessaire pour identifier tous les enregistrements d'une table.
Propriétés clés des bases de données relationnelles
Les bases de données relationnelles sont des groupes d'opérations (transactions) qui fonctionnent ensemble et possèdent plusieurs caractéristiques déterminantes pour les rendre fiables. Ces transactions suivent un ensemble de règles appelées ACID, qui signifie :
- Atomicité : Toutes les mises à jour doivent être entièrement terminées
- Cohérence : les règles sont toujours appliquées
- Isolation : les transactions simultanées n'interfèrent pas avec leurs états intermédiaires respectifs
- Durabilité : une fois validées, les données peuvent survivre à des pannes ou à des interruptions de service.
Ces règles contribuent à garantir l'intégrité des données au niveau transactionnel, en assurant que les opérations de base de données s'achèvent de manière fiable et correcte. La conception du schéma, les types de données et les contraintes garantissent que les valeurs dans les colonnes sont atomiques et de signification cohérente. Les contraintes sont utilisées pour maintenir la cohérence entre plusieurs tables.
Une autre propriété essentielle des bases de données relationnelles est le langage de requête structuré (SQL), le langage le plus courant pour l'extraction de données. Comme les données sont stockées dans des tables prévisibles avec des relations, le langage SQL est utilisé pour répondre efficacement à des questions complexes afin d'analyser les données. Il offre une méthode standard pour exécuter des requêtes, récupérer des données, insérer/mettre à jour/supprimer des enregistrements, créer de nouvelles bases de données ou de nouvelles tables et définir des autorisations sur les tables, les procédures et les vues.
Les bases de données relationnelles doivent également assurer la sécurité/le contrôle d'accès pour protéger les données sur plusieurs dimensions :
- Authentification : ceux qui accèdent à la base de données sont bien ceux qu'ils prétendent être.
- Autorisation : vous faites ce que vous êtes autorisé à faire.
- Audit – Confirmation de ce que vous avez fait et quand
La sécurité des bases de données comprend également des fonctionnalités telles que le chiffrement pour protéger les données en cas d'interception ou de vol, ainsi que la sauvegarde et la récupération pour que les données ne soient pas perdues lors de pannes du système.
Les bases de données relationnelles sont devenues les « systèmes de référence » par défaut en raison de leur normalisation et de leur maturité. Les fonctionnalités, structures et capacités standard permettent à un SGBDR de rester prévisible, fiable, sûr et évolutif au fil du temps. Par exemple, avec SQL comme méthode de requête standard, les concepts et compétences de base peuvent être transférés d'un SGBDR à un autre, et les applications et outils de données peuvent être maintenus au fil des migrations. La normalisation augmente également la concurrence entre les fournisseurs et la diversité des choix.
Les bases de données relationnelles existent depuis longtemps. Cette maturité signifie qu'elles sont éprouvées pour des charges de travail réelles et optimisées pour des transactions extrêmement affinées.
Bases de données relationnelles et non relationnelles
La différence la plus évidente entre les bases de données relationnelles et non relationnelles est que les bases de données non relationnelles ne stockent pas de données structurées dans des tables. Elles ont la flexibilité de stocker des données dans des conteneurs dans le format qui convient le mieux aux données stockées. Ces données vaguement définies et non structurées peuvent comprendre des e-mails, des documents professionnels, des vidéos et des images. Mais elles peuvent également stocker un mélange de données transactionnelles structurées et de données non structurées.
Les bases de données non relationnelles sont souvent appelées bases de données NoSQL, un terme qui signifiait à l'origine « pas seulement SQL », reflétant le fait que ces systèmes ne reposent pas sur SQL comme interface principale, même si beaucoup d'entre eux prennent désormais en charge les requêtes basées sur SQL.
Les bases de données relationnelles utilisent un schéma fixe avec des lignes et des colonnes et des relations avec des clés et des jointures SQL, tandis que les bases de données non relationnelles stockent les données dans des structures flexibles qui ne nécessitent pas de schéma prédéfini, comme les paires clé-valeur, les nœuds/arêtes et les documents. Avec les bases de données relationnelles, les données doivent correspondre au schéma lors de l'écriture, tandis qu'avec les bases de données non relationnelles, la forme des données peut varier, car elles sont interprétées lors de leur lecture et les relations sont généralement gérées dans les applications, et non dans la base de données.
Les bases de données relationnelles emploient également par défaut des Transactions ACID fortes, tandis que les bases de données NoSQL sont traditionnellement conçues pour une cohérence à terme et privilégient la disponibilité et la vitesse à l'exactitude.
Les bases de données relationnelles sont choisies lorsqu'une structure claire avec des règles fortes est nécessaire, ainsi qu'une abondance de relations entre les points de données. Un modèle relationnel est le mieux adapté au reporting et à l'analytique avec des transactions qui doivent toujours être correctes. Les bases de données relationnelles sont idéales pour l'analytique ad hoc, le filtrage et le regroupement complexes, tandis que les bases de données non relationnelles sont souvent optimisées pour un ensemble de queries restreint. Les bases de données relationnelles montent généralement en charge verticalement, les systèmes modernes prenant en charge la montée en charge horizontale par le biais de réplicas, du sharding ou de l'exécution distribuée, souvent avec une complexité accrue, tandis que les bases de données non relationnelles sont conçues pour monter en charge horizontalement et sont généralement choisies pour les grands réseaux distribués.
Les bases de données non relationnelles sont choisies pour des données flexibles ou en évolution rapide à très grande échelle avec des modèles de requêtes simples.
Exemples courants de RDBMS
- MySQL – Un SGBDR open source, désormais détenu par Oracle Corp., qui implémente la norme SQL. C'est souvent le choix privilégié pour les applications web, les systèmes d'entreprise et les services critiques basés sur les données qui exigent de hautes performances. Il est couramment utilisé pour les applications web, les boutiques et catalogues en ligne, les comptes utilisateur et les systèmes d'authentification, la journalisation et l'analytique, les applications SaaS et les tableaux de bord.
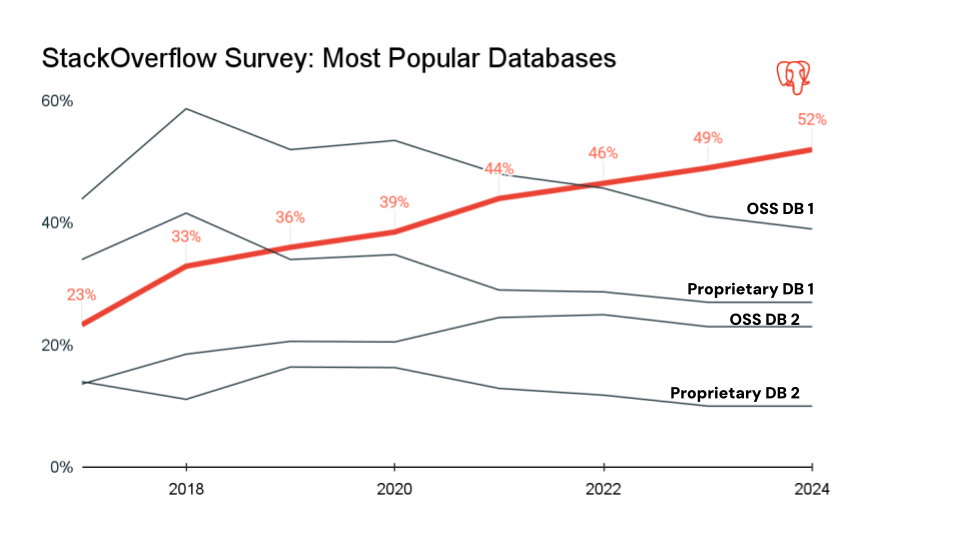
- PostgreSQL – Un RDBMS open source très extensible, connu pour ses normes strictes et sa conformité ACID, avec un bon équilibre entre fiabilité et flexibilité. Il prend en charge le stockage SQL et le stockage JSON/JSONB semi-structuré et utilise le contrôle de concurrence multiversion. PostgreSQL est utilisé pour les applications web, les plateformes SaaS multi-tenant, les transactions financières, l'analytique et le reporting, les données scientifiques et les charges de travail OLTP. Il est populaire auprès des entreprises exclusivement en ligne. Au cours des sept dernières années, Postgres est devenue la base de données la plus populaire au sein de la communauté des développeurs et constitue le choix de base de données de facto pour les applications modernes.
- SQLite – Une base de données relationnelle sans serveur, multiplateforme et open source qui utilise SQL et s'exécute au sein d'une application via une bibliothèque C légère. Elle ne nécessite aucune installation ni administration. SQLite est principalement utilisé pour les systèmes embarqués et les petites applications sur les appareils personnels.
- Oracle : un SGBDR propriétaire de qualité professionnelle développé par Oracle Corp. Connu pour son évolutivité, son clustering et sa fiabilité, il est optimisé pour les charges de travail transactionnelles (OLTP) et analytiques (OLAP) et utilisé pour les systèmes bancaires, les compagnies aériennes, la santé, les télécommunications, le gouvernement et les systèmes ERP/CRM à grande échelle.
- Microsoft SQL Server – Le RDBMS propriétaire de Microsoft, conçu pour les entreprises, basé sur Transact-SQL (T-SQL), l'extension SQL de Microsoft. Disponible sur Windows et Linux, SQL Server est connu pour ses outils de gestion et d'administration, ainsi que pour sa forte intégration avec Microsoft Azure et d'autres technologies Microsoft. Les cas d'utilisation typiques incluent l'ERP, le CRM, les RH, l'e-commerce, la Business Intelligence et l'analytique. SQL Server est particulièrement performant dans les secteurs de la finance, de la banque et de la santé.
- IBM Db2 – Une famille propriétaire de systèmes RDBMS développée par IBM, offrant de hautes performances, une grande fiabilité et un traitement de données à l'échelle de l'entreprise. Les versions SGBDR de Db2 fonctionnent sur plusieurs plateformes, dont Linux, UNIX, Windows, IBM AS/400 et les mainframes IBM. Il est basé sur SQL, mais prend en charge les documents JSON, le stockage XKL, les données de séries chronologiques, le stockage en colonnes et les fonctionnalités de graphe dans certaines versions. Elle est largement utilisée dans les domaines de la finance, du gouvernement, de la santé, de l'assurance, du commerce de détail, du transport aérien et dans les environnements IT d'entreprise.
- MariaDB – Un SGBDR open source créé en tant que remplacement direct et communautaire de MySQL, géré par la fondation MariaDB. Il est largement utilisé pour les charges de travail OLTP et OLAP dans les applications Web, les plateformes SaaS, les systèmes cloud et les entreprises, et constitue un choix fréquent pour les systèmes Linux et les piles open source. Les cas d'utilisation courants incluent les applications web et les sites web, les plateformes SaaS, la gestion de contenu, le e-commerce et l'analytique.
Le guide pratique de l'IA agentique pour l'entreprise

SQL, RDBMS et FAQ connexes
SQL est-il une base de données relationnelle ?
Non, SQL est un langage de requête utilisé pour interagir avec une base de données relationnelle, et non un système de base de données.
MySQL est-elle une base de données relationnelle ?
Oui, MySQL est un RDBMS avec une structure basée sur des tables prenant en charge les relations entre les tables.
Excel est-il relationnel ?
Non, Excel est le tableur de Microsoft, pas un RDBMS. Bien qu'Excel utilise un format de tableau, il n'y a pas de schéma appliqué avec une structure et des contraintes cohérentes. Excel ne peut pas exécuter de requêtes SQL de manière autonome et il n'y a pas de Transactions ACID.
Quelle est la différence entre la terminologie de base de données relationnelle et de SGBDR ?
Bien qu'étroitement liées et souvent utilisées de manière interchangeable, les bases de données relationnelles font référence au modèle de données lui-même, tandis qu'un RDBMS est un système logiciel qui gère ce modèle de données.
Avantages et limites
Les avantages de l'utilisation des bases de données relationnelles incluent :
- Forte intégrité des données et cohérence garanties par les Transactions ACID pour assurer l'absence de mises à jour partielles, de données corrompues et la fiabilité des Opérations. Des données structurées et bien définies garantissent des données propres et prévisibles.
- Les capacités d'interrogation et l'outillage standardisés avec SQL fournissent le filtrage, le regroupement, l'agrégation, l'indexation et les jointures complexes pour rendre les bases de données relationnelles idéales pour l'analytique, le reporting et la logique métier complexe.
- Fortes de plusieurs décennies de maturité, les bases de données relationnelles sont bien prises en charge et offrent des performances fiables, des modèles de sécurité et de disponibilité robustes et un écosystème d'outils pour réduire les risques.
Les limitations incluent :
- Le schéma rigide et fixe des bases de données relationnelles réduit l'agilité et n'est pas adapté aux données non structurées ou semi-structurées ni aux formes d'enregistrement qui changent fréquemment.
- Les bases de données relationnelles sont excellentes pour la mise à l'échelle verticale, mais la mise à l'échelle horizontale est complexe.
- Les performances peuvent se dégrader avec de très grands datasets et des jointures complexes, ce qui peut ralentir les charges de travail distribuées.
- Les SGBDR commerciaux peuvent être coûteux, en particulier à monter en charge.
- OLTP n'est pas conçu pour les queries analytiques complexes.
- Facilité de création de silos de données, ce qui augmente les coûts de stockage.
- Complexité de l'ETL (dans le cas du déplacement de données entre les entrepôts opérationnels et analytiques).
- Gestion des données semi-structurées (Delta, Iceberg, Parquet -- ce que l'on trouve dans le lakehouse).
- Difficulté avec les types de données non standard pour l'intégration ML/IA
- Non conçu pour traiter les données en streaming
- Gardez votre indépendance vis-à-vis des fournisseurs
Évolution au-delà des RDBMS traditionnels
- L'ère du data warehouse : les SGBDR sont conçus pour utiliser des données actuelles et sont optimisés pour de nombreuses petites lectures/écritures pour le traitement transactionnel en ligne (OLTP). Par conséquent, ils peuvent avoir des difficultés avec l'analytique à l'échelle de la montée en charge. Pour surmonter cette limitation, les data warehouses utilisent des schémas dénormalisés qui peuvent traiter des query volumineuses et complexes sur des données actuelles et historiques pour le traitement analytique en ligne (OLAP).
- Défi du Big Data : les SGBDR peinent à gérer des données massives, rapides, diverses et distribuées. Leur schéma rigide, leur mise à l'échelle verticale et la surcharge des Transactions ACID les rendent moins adaptés à l'analytique distribuée à grande échelle. Les SGBDR traditionnels reposent sur des jointures exécutées sur un stockage géré localement, ce qui limite l'évolutivité dans les environnements distribués.
- Exigences du cloud natif : les systèmes de bases de données relationnelles traditionnels éprouvent des difficultés dans les architectures cloud natives qui privilégient le stockage objet. Ils sont conçus pour le stockage par blocs avec un matériel étroitement couplé et un accès disque à faible latence. Historiquement, le stockage objet n'offrait pas les garanties de faible latence requises pour le traitement des Transactions ACID classique, ce qui représentait un défi pour les conceptions de RDBMS traditionnels. Le stockage objet est optimisé pour le throughput plutôt que pour la latence. Les applications cloud natif montent également en charge horizontalement, tandis que les conceptions de RDBMS traditionnels reposent sur un compute et un stockage étroitement couplés, souvent centrés autour d'un serveur principal.
- Data lakes modernes : les architectures Lakehouse ont évolué pour pallier les limitations des data lakes traditionnels en combinant l'évolutivité et le faible coût des data lakes avec la structure, la gouvernance et les caractéristiques de performance des data warehouses et des systèmes relationnels.
Un lakehouse utilise le stockage d'objets cloud natif pour la persistance des données tout en introduisant des formats de table gérés, des couches de métadonnées et des journaux de transactions qui permettent l'application des schémas, l'accès SQL et les Transactions ACID directement sur ce stockage. Cela permet aux données structurées, semi-structurées et non structurées de coexister dans un système unique.
Contrairement aux premiers data lakes qui reposaient fortement sur le principe du « schema-on-read » et sur une logique de traitement externe, les lakehouses prennent en charge le « schema-on-write » ou l'évolution gérée des schémas au niveau de la table. Cela permet d'obtenir des définitions de données cohérentes, d'assurer la qualité des données et d'effectuer des analyses fiables. En découplant le stockage du compute, les architectures lakehouse permettent à plusieurs moteurs de compute de fonctionner sur les mêmes données pour l'analytique, le Data Engineering, le streaming et le machine learning. Cette flexibilité rend les lakehouses bien adaptés à l'analytique à grande échelle, à la Business Intelligence et aux charges de travail de données avancées, tout en maintenant la rentabilité et l'ouverture grâce à des formats de fichiers et de tables ouverts. - Architecture Lakebase : Un lakebase est une nouvelle catégorie de base de données opérationnelle conçue pour les applications modernes et intelligentes. Alors que les RDBMS excellent en matière de cohérence transactionnelle et de schémas structurés, ils sont isolés des données analytiques, des pipelines de machine learning et de l'intelligence en temps réel dont les applications dépendent de plus en plus. Un Lakebase combine des capacités de base de données essentielles comme les transactions, l'indexation et l'accès à faible latence avec une intégration native au lakehouse, permettant aux applications de fonctionner directement sur des données fraîches, partagées, analytiques et prêtes pour l'IA. Cela permet à un système unique de prendre en charge à la fois les charges de travail opérationnelles et le comportement intelligent des applications data-driven, sans dupliquer les données ni diviser les architectures.
Combattre les idées reçues
- Toutes les bases de données sont relationnelles
Il existe de nombreuses bases de données non relationnelles qui ne suivent pas le modèle relationnel (stockage de données dans des tables et utilisation de SQL pour définir et interroger les relations). - Les bases de données relationnelles sont uniquement SQL
La plupart des bases de données relationnelles utilisent SQL comme langage principal. SQL a été conçu pour le modèle relationnel, mais certaines bases de données utilisent d'autres langages relationnels, tels que Quel, Tutorial D, Rel et Datalog. - Les bases de données relationnelles sont obsolètes
Les bases de données relationnelles sont loin d'être obsolètes. Elles restent inégalées pour les données complexes et structurées et constituent toujours la colonne vertébrale des systèmes critiques actuels. Et SQL reste l'un des langages les plus utilisés. Aujourd'hui, les bases de données relationnelles coexistent avec NoSQL, les lacs de données et les lakehouses à mesure que les cas d'utilisation des données continuent d'évoluer.
Conclusion
Les bases de données relationnelles dotées d'un schéma structuré qui organisent les données en tables, lignes et colonnes, avec des clés et des jointures pour une récupération rapide des données et des transactions ACID fiables, restent une architecture de base pour les applications d'entreprise critiques et sécurisées. Avec une structure conçue pour des requêtes rapides et fiables, les bases de données relationnelles garantissent l'intégrité et la cohérence des types de données, et vous pouvez optimiser le stockage et les requêtes pour maintenir les performances. Elles peuvent également coexister avec des bases de données non relationnelles dans des environnements modernes de data lake et de lakehouse distribués.
La standardisation et la maturité des RDBMS signifient qu'ils sont éprouvés pour les charges de travail réelles et optimisés pour des transactions extrêmement affinées. Les architectures modernes telles que lakebase étendent ces fondations relationnelles éprouvées aux environnements cloud natifs, permettant à la fiabilité relationnelle et à l'analytique basée sur SQL de coexister avec le stockage d'objets évolutif et le compute distribué.
Ressources complémentaires
- Introduction pour débutants couvrant les tables, les relations et les concepts de base
- Présentation complète de l'architecture, des fonctionnalités et des applications d'entreprise des RDBMS
- Explication complète de la 1NF à la 5NF avec des exemples
- Analyse détaillée de l'atomicité, de la cohérence, de l'isolation et de la durabilité
- Couverture complète incluant les règles de Codd et les fondements théoriques
- Lakehouse : une nouvelle génération de plateformes ouvertes qui unifie l'entreposage des données et l'analytique avancée
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.