Data Lake sur Azure
Source de données, origine de données complète et faisant autorité pour alimenter votre lakehouse
Qu’est-ce qu’un data lake?
Exécutez vos charges de travail liées aux données, à l'analytique et à l'IA sur une plateforme cloud native simple d'utilisation, ouverte et collaborative. Cette plateforme s'intègre facilement à vos outils de sécurité et de gestion, ce qui vous permet d'étendre vos politiques de gouvernance existantes pour une tranquillité d'esprit et un contrôle accrus.

Qu’est-ce qu’un Azure data lake?
Un Azure data lake comprend des services de stockage de données et d’analyse évolutifs et cloud . Azure data lake Storage permet aux entreprises de stocker des données de toute taille, de tout format et de toute vitesse pour une grande variété de cas d’utilisation de traitement, d’analyse et de Data Science . Lorsqu’il est utilisé avec d’autres services Azure , tels que Azure Databricks , Azure data lake Storage est un moyen beaucoup plus rentable de stocker et de récupérer des données dans l’ensemble de votre organisation.
Que vos données soient volumineuses ou petites, rapides ou lentes, structurées ou non structurées, Azure data lake s’intègre à Azure identité, gestion et sécurité pour simplifier la gestion des données et la gouvernance. Le stockage Azure chiffre automatiquement vos données, et Azure Databricks fournit des outils pour protéger les données afin de répondre aux besoins de sécurité et de conformité de votre organisation.

Pourquoi avez-vous besoin d’un Azure data lake?
Les lacs de données sont au format ouvert, ce qui permet aux utilisateurs d’éviter de s’enfermer dans un système propriétaire comme un data warehouse. Les normes et les formats ouverts sont devenus de plus en plus importants dans les architectures de données modernes. Les lacs de données sont également très durables et peu coûteux en raison de leur capacité à monter en charge et à tirer parti du stockage objet. De plus, l’analytique avancée et la machine learning sur les données non structurées font partie des priorités les plus stratégiques des entreprises d’aujourd’hui. La capacité unique d’ingérer des données brutes dans une variété de formats (structurés, non structurés et semi-structurés), ainsi que les autres avantages mentionnés, font d’un data lake le choix évident pour le stockage de données.
Lorsqu’ils sont correctement architecturés, les lacs de données offrent la possibilité de :
- Alimentation Data Science et machine learning
- Centralisez, consolidez et cataloguez vos données
- Intégrez rapidement et de manière transparente diverses sources de données, origines de données et formats
- Démocratisez vos données en proposant aux utilisateurs des outils en libre-service
Quelle est la différence entre un Azure data lake et un Azure data warehouse?
Un data lake est un emplacement central qui contient une grande quantité de données dans leur format natif et brut, ainsi qu’un moyen d’organiser de grands volumes de données très diverses. Par rapport à un data warehousehiérarchique, qui stocke les données dans des fichiers ou des dossiers, un data lake utilise une architecture plate pour stocker les données. Les lacs de données sont généralement configurés sur des clusters de matériel de base évolutif. Par conséquent, vous pouvez stocker des données brutes dans le lac au cas où elles seraient nécessaires à une date ultérieure, sans vous soucier du format, de la taille ou de la capacité de stockage des données.
De plus, data lake clusters peuvent exister on-premise ou dans le cloud. Historiquement, le terme «data lake» était souvent associé au stockage d’objets orienté Hadoop, mais aujourd’hui, le terme fait généralement référence à la catégorie plus large du stockage d’objets. Le stockage objet stocke les données à l’aide de balises de métadonnées et d’un identifiant unique, ce qui facilite la localisation et la récupération des données dans toutes les régions et améliore les performances. Le lakehouse Databricks Plateforme met à disposition toutes les données de votre data lake pour un nombre illimité de cas d’utilisation data-driven .

Pourquoi utiliser Delta Lake format pour vos Azure data lake?
Voici cinq raisons principales de convertir un lac de données de Apache Parquet, CSV, JSON et d’autres formats au formatDelta Lake :
- Prévenir la corruption des données
- Requêtes plus rapides
- Augmenter l’actualisation des données
- Reproduire des modèles ML
- Assurer la conformité
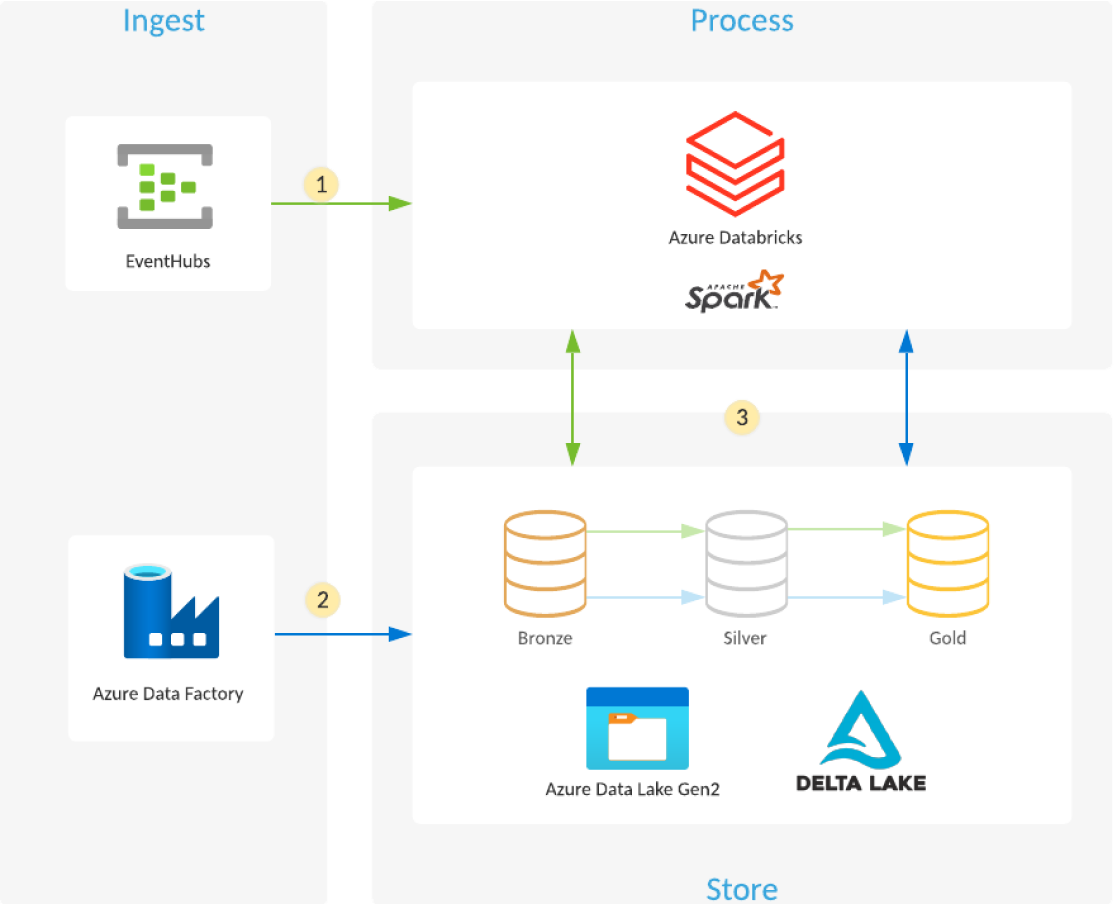
Comment créer un data lake à l’aide de Azure Databricks et de Azure data lake Storage ?
Les Delta Lake gérés dans Azure Databricks offrent une couche de fiabilité qui vous permet de conserver, d’analyser et de tirer de la valeur de vos data lake sur le cloud.
- Azure Databricks lit streaming données des files d’attente d’événements, telles que Azure Event Hubs, Azure IoT Hub ou Kafka, et charge les événements bruts dans des tables et des dossiers de Delta Lake optimisés et compressés (couche Bronze) stockés dans Azure data lake Storage.
- Planifié ou déclenché Azure pipeline Data Factory copie les données de différentes sources de données, origine de données dans leur format brut dans Azure data lake Storage. Le Auto Loader dans Azure Databricks traite les fichiers au fur et à mesure qu’ils arrivent et les charge dans des tables et des dossiers de Delta Lake optimisés et compressés (couche Bronze) stockés dans Azure data lake Storage.
- streaming ou planifié/déclenché Azure Databricks Job lit les nouvelles transactions à partir de la couche Bronze, puis les joint, les nettoie, les transforme et les agrège avant d’utiliser les transactions ACID (INSERT, UPDATE, DELETE, MERGE) pour les charger dans des ensembles de données organisés (couches Silver et Gold ) stockés dans Delta Lake sur Azure data lake Storage.
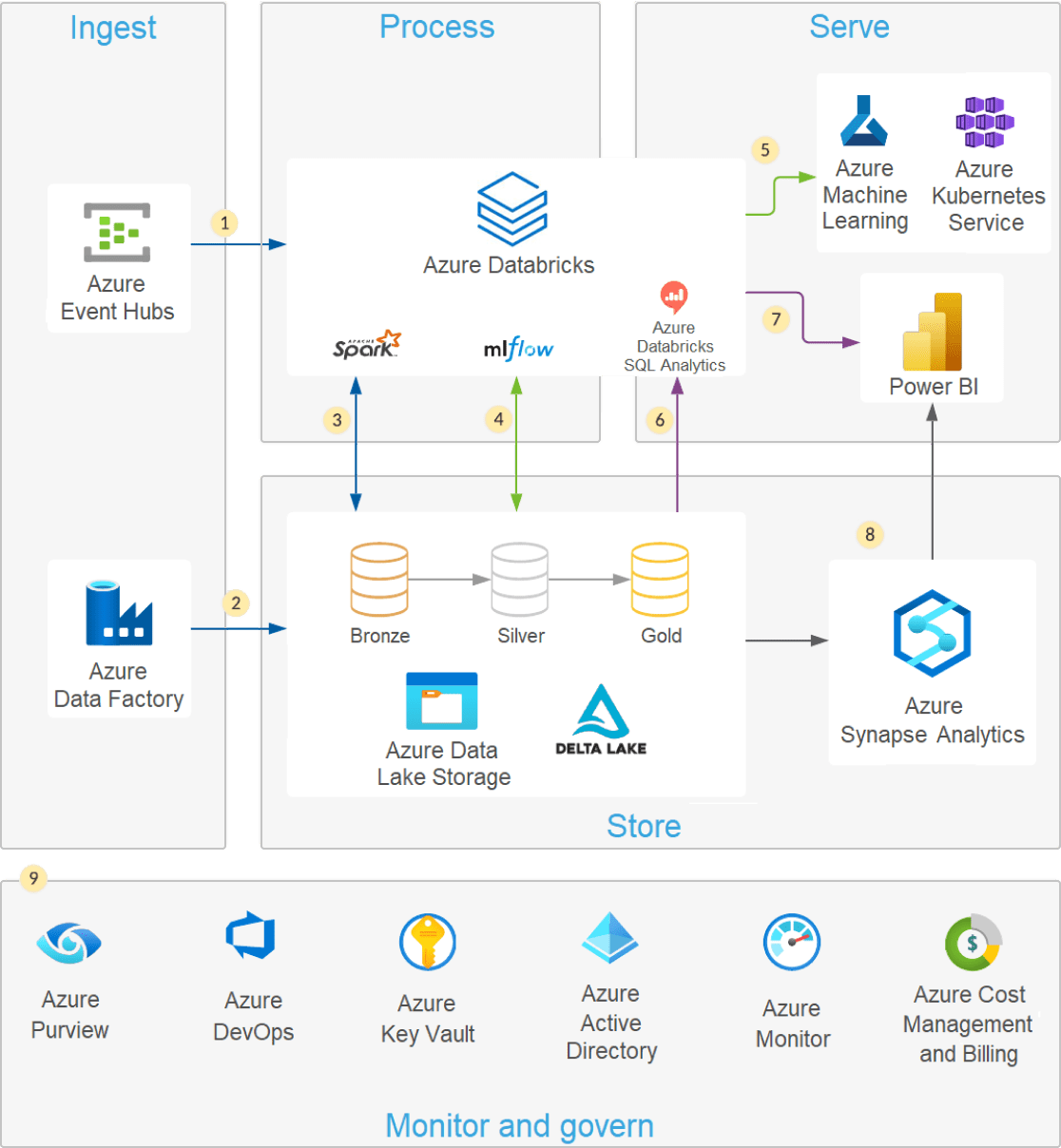
Architecture data lake moderne
Une architecture lakehouse moderne qui combine la performance, la fiabilité et l’intégrité des données d’un entrepôt avec la flexibilité, la flexibilité et la prise en charge des données non structurées disponibles en un data lake.
Les lacs de données modernes tirent parti de l’élasticité cloud pour stocker des quantités pratiquement illimitées de données « en l’état », sans qu’il soit nécessaire d’imposer un schéma ou une structure. Le langage de requête structuré (SQL) est un langage d’interrogation puissant qui vous permet d’explorer vos données et de découvrir des informations précieuses. Delta Lake s’agit d’une couche de stockage open source qui apporte de la fiabilité au lac de données avec Transactions ACID, une gestion évolutive des métadonnées et un traitement unifié des données streaming et batch . Delta Lake est entièrement compatible et apporte de la fiabilité à votre data lakeexistante.
Vous pouvez facilement interroger votre data lake à l’aide de SQL et Delta Lake avec Azure Databricks. Delta Lake vous permet d’exécuter des requêtes SQL sur vos données streaming et batch sans déplacer ni copier vos données. Azure Databricks offre des avantages supplémentaires lorsque vous travaillez avec Delta Lake pour sécuriser votre data lake grâce à une intégration native avec cloud services, offre des performances optimales et aide à auditer et à dépanner les pipelines de données.
- Delta Lake s’intègre au stockage cloud évolutif ou HDFS pour aider à éliminer les silos de données
- Explorez votre utilisation des données SQL des requêtes et une couche de transactions conforme à ACID directement sur votre data lake
- Tirez parti des « tableaux médaillons » Gold, Silver et Bronze pour consolider et simplifier la qualité des données pour vos flux de travail de pipeline de données et analytiques
- Utilisez Delta Lake time travel pour voir comment vos données ont évolué au fil du temps
- Azure Databricks optimise les performances grâce à des fonctionnalités telles que le cache Delta, le compactage de fichiers et l’omission de données