Evoluzione dello schema nelle operazioni di merge e metriche operative in Delta Lake
Delta Lake 0.6.0 introduce l'evoluzione dello schema e miglioramenti delle prestazioni nelle operazioni di merge e nelle metriche operative nella cronologia delle tabelle
di Tathagata Das e Denny Lee
Ottieni un'anteprima di il nuovo ebook di O'Reilly per la guida passo passo necessaria per iniziare a usare Delta Lake.
Prova questo notebook per riprodurre i passaggi descritti di seguito
Abbiamo recentemente annunciato il rilascio di Delta Lake 0.6.0, che introduce l'evoluzione dello schema e miglioramenti delle prestazioni nelle operazioni di merge e metriche operative nella cronologia delle tabelle. Le funzionalità principali di questa release sono:
- Supporto per l'evoluzione dello schema nelle operazioni di merge (#170) - Ora puoi far evolvere automaticamente lo schema della tabella con l'operazione di merge. Questo è utile in scenari in cui desideri aggiornare i dati di modifica in una tabella e lo schema dei dati cambia nel tempo. Invece di rilevare e applicare le modifiche allo schema prima dell'aggiornamento, il merge può far evolvere contemporaneamente lo schema e aggiornare le modifiche.
- Prestazioni di merge migliorate con ripartizionamento automatico (#349) - Quando esegui il merge in tabelle partizionate, puoi scegliere di ripartizionare automaticamente i dati in base alle colonne di partizione prima di scrivere sulla tabella. Nei casi in cui l'operazione di merge su una tabella partizionata è lenta perché genera troppi file piccoli (#345), l'abilitazione del ripartizionamento automatico (spark.delta.merge.repartitionBeforeWrite) può migliorare le prestazioni.
- Prestazioni migliorate quando non è presente una clausola INSERT (#342) - Ora puoi ottenere prestazioni migliori in un'operazione di merge se non contiene alcuna clausola INSERT.
- Metriche operative in DESCRIBE HISTORY (#312) - Ora puoi visualizzare le metriche operative (ad esempio, numero di file e righe modificate) per tutte le scritture, aggiornamenti ed eliminazioni su una tabella Delta nella cronologia della tabella.
- Supporto per la lettura di tabelle Delta da qualsiasi file system (#347) - Ora puoi leggere tabelle Delta su qualsiasi sistema di archiviazione con un'implementazione Hadoop FileSystem. Tuttavia, la scrittura su tabelle Delta richiede ancora la configurazione di un'implementazione LogStore che fornisca le garanzie necessarie sul sistema di archiviazione.
Evoluzione dello schema nelle operazioni di merge
Come notato nelle precedenti release di Delta Lake, Delta Lake include la capacità di eseguire operazioni di merge per semplificare le tue operazioni di inserimento/aggiornamento/eliminazione in un'unica operazione atomica, oltre a includere la capacità di applicare ed evolvere il tuo schema (maggiori dettagli sono disponibili anche in questo tech talk). Con il rilascio di Delta Lake 0.6.0, ora puoi far evolvere il tuo schema all'interno di un'operazione di merge.
Mostriamo questo utilizzando un esempio tempestivo; puoi trovare il codice di esempio originale in questo notebook. Inizieremo con un piccolo sottoinsieme del dataset COVID-19 (2019-nCoV) Data Repository by Johns Hopkins CSSE che abbiamo reso disponibile in /databricks-datasets. Questo è un dataset comunemente utilizzato da ricercatori e analisti per ottenere informazioni sul numero di casi di COVID-19 in tutto il mondo. Uno dei problemi con i dati è che lo schema cambia nel tempo.
Ad esempio, i file che rappresentano i casi di COVID-19 dal 1° marzo al 21 marzo (al 30 aprile 2020) hanno lo schema seguente:
Ma i file dal 22 marzo in poi (al 30 aprile) avevano colonne aggiuntive tra cui FIPS, Admin2, Active e Combined_Key.
Nel nostro codice di esempio, abbiamo rinominato alcune delle colonne (ad es. Long_ -> Longitude, Province/State -> Province_State, ecc.) poiché sono semanticamente le stesse. Invece di far evolvere lo schema della tabella, abbiamo semplicemente rinominato le colonne.
Se la preoccupazione principale fosse solo unire gli schemi, potremmo utilizzare la funzionalità di evoluzione dello schema di Delta Lake utilizzando l'opzione “mergeSchema” in DataFrame.write(), come mostrato nell'istruzione seguente.
Ma cosa succede se è necessario aggiornare un valore esistente e contemporaneamente unire lo schema? Con Delta Lake 0.6.0, questo può essere ottenuto con l'evoluzione dello schema per le operazioni di merge. Per visualizzare questo, iniziamo rivedendo i vecchi dati che sono una riga.
Successivamente simuliamo una voce di aggiornamento che segue lo schema di new_data
e uniamo simulated_update e new_data con un totale di 40 righe.
Abbiamo impostato il seguente parametro per configurare il tuo ambiente per l'evoluzione automatica dello schema:
Ora possiamo eseguire un'unica operazione atomica per aggiornare i valori (dal 21/03/2020) e unire il nuovo schema con la seguente istruzione.
Rivediamo la tabella Delta Lake con la seguente istruzione:
Metriche Operative
Puoi approfondire le metriche operative esaminando la cronologia della tabella Delta Lake (colonna operationMetrics) nell'interfaccia utente di Spark eseguendo la seguente istruzione:
Di seguito è riportato un output abbreviato del comando precedente.
Noterai due versioni della tabella, una per il vecchio schema e un'altra versione per il nuovo schema. Rivedendo le metriche operative di seguito, si nota che sono state inserite 39 righe e aggiornata 1 riga.
Puoi saperne di più sui dettagli di queste metriche operative andando alla scheda SQL all'interno dell'interfaccia utente di Spark.
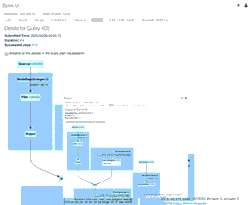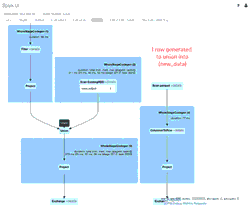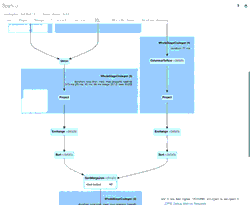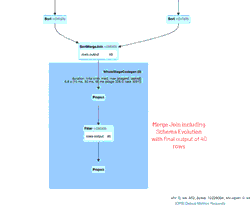
La GIF animata evidenzia i componenti principali dell'interfaccia utente di Spark per la tua revisione.
- 39 righe iniziali da un file (per 11/04/2020 con il nuovo schema) che hanno creato il DataFrame new_data iniziale
- 1 riga di aggiornamento simulata generata che si unirebbe al DataFrame new_data
- 1 riga dal file (per 21/03/2020 con il vecchio schema) che ha creato il DataFrame old_data.
- Un SortMergeJoin utilizzato per unire i due DataFrame da persistere nella nostra tabella Delta Lake.
Per approfondire come interpretare queste metriche operative, consulta la tech talk Diving into Delta Lake Part 3: How do DELETE, UPDATE, and MERGE work.

Inizia con Delta Lake 0.6.0
Prova Delta Lake con gli snippet di codice precedenti sulla tua istanza Apache Spark 2.4.5 (o superiore) (su Databricks, prova questo con DBR 6.6+). Delta Lake rende i tuoi data lake più affidabili (sia che tu ne crei uno nuovo o migri un data lake esistente). Per saperne di più, fai riferimento a https://delta.io/ e unisciti alla community di Delta Lake tramite Slack e Google Group. Puoi tenere traccia di tutte le prossime release e delle funzionalità pianificate nei milestone di GitHub. Puoi anche provare Delta Lake gestito su Databricks con un account gratuito.
Crediti
Vogliamo ringraziare i seguenti contributori per gli aggiornamenti, le modifiche alla documentazione e i contributi in Delta Lake 0.6.0: Ali Afroozeh, Andrew Fogarty, Anurag870, Burak Yavuz, Erik LaBianca, Gengliang Wang, IonutBoicuAms, Jakub Orłowski, Jose Torres, KevinKarlBob, Michael Armbrust, Pranav Anand, Rahul Govind, Rahul Mahadev, Shixiong Zhu, Steve Suh, Tathagata Das, Timothy Zhang, Tom van Bussel, Wesley Hoffman, Xiao Li, chet, Eugene Koifman, Herman van Hovell, hongdd, lswyyy, lys0716, Mahmoud Mahdi, Maryann Xue
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.