Uno sguardo completo su date e timestamp in Apache Spark™ 3.0
Apache Spark is a very popular tool for processing structured and unstructured data. When it comes to processing structured data, it supports many basic data types, like integer, long, double, string, etc. Spark also supports more complex data types, like the Date and Timestamp, which are often difficult for developers to understand. In this blog post, we take a deep dive into the Date and Timestamp types to help you fully understand their behavior and how to avoid some common issues. In summary, this blog covers four parts:
- The definition of the Date type and the associated calendar. It also covers the calendar switch in Spark 3.0.
- The definition of the Timestamp type and how it relates to time zones. It also explains the detail of time zone offset resolution, and the subtle behavior changes in the new time API in Java 8, which is used by Spark 3.0.
- The common APIs to construct date and timestamp values in Spark.
- The common pitfalls and best practices to collect date and timestamp objects on the Spark driver.
Date and calendar
The definition of a Date is very simple: It's a combination of the year, month and day fields, like (year=2012, month=12, day=31). However, the values of the year, month and day fields have constraints, so that the date value is a valid day in the real world. For example, the value of month must be from 1 to 12, the value of day must be from 1 to 28/29/30/31 (depending on the year and month), and so on.
These constraints are defined by one of many possible calendars. Some of them are only used in specific regions, like the Lunar calendar. Some of them are only used in history, like the Julian calendar. At this point, the Gregorian calendar is the de facto international standard and is used almost everywhere in the world for civil purposes. It was introduced in 1582 and is extended to support dates before 1582 as well. This extended calendar is called the Proleptic Gregorian calendar.
Starting from version 3.0, Spark uses the Proleptic Gregorian calendar, which is already being used by other data systems like pandas, R and Apache Arrow. Before Spark 3.0, it used a combination of the Julian and Gregorian calendar: For dates before 1582, the Julian calendar was used, for dates after 1582 the Gregorian calendar was used. This is inherited from the legacy java.sql.Date API, which was superseded in Java 8 by java.time.LocalDate, which uses the Proleptic Gregorian calendar as well.
Notably, the Date type does not consider time zones.
Timestamp and time zone
The Timestamp type extends the Date type with new fields: hour, minute, second (which can have a fractional part) and together with a global (session scoped) time zone. It defines a concrete time instant on Earth. For example, (year=2012, month=12, day=31, hour=23, minute=59, second=59.123456) with session timezone UTC+01:00. When writing timestamp values out to non-text data sources like Parquet, the values are just instants (like timestamp in UTC) that have no time zone information. If you write and read a timestamp value with different session timezone, you may see different values of the hour/minute/second fields, but they are actually the same concrete time instant.
The hour, minute and second fields have standard ranges: 0–23 for hours and 0–59 for minutes and seconds. Spark supports fractional seconds with up to microsecond precision. The valid range for fractions is from 0 to 999,999 microseconds.
At any concrete instant, we can observe many different values of wall clocks, depending on time zone.
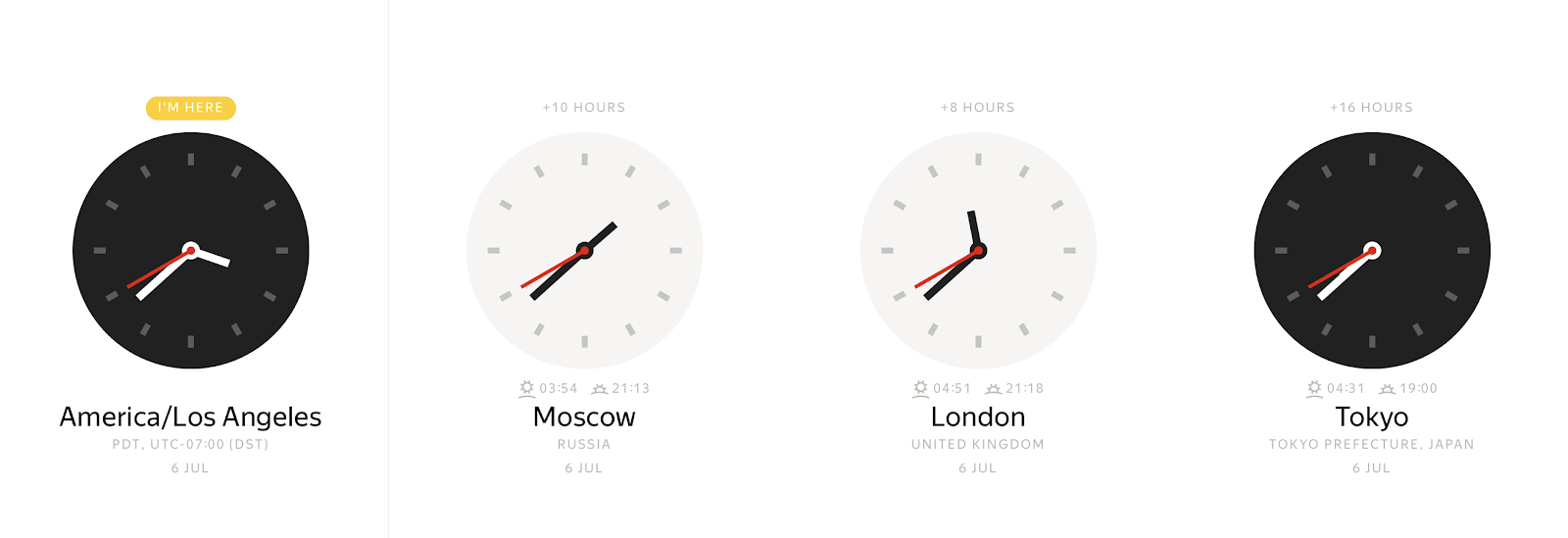
And conversely, any value on wall clocks can represent many different time instants. The time zone offset allows us to unambiguously bind a local timestamp to a time instant. Usually, time zone offsets are defined as offsets in hours from Greenwich Mean Time (GMT) or UTC+0 (Coordinated Universal Time). Such a representation of time zone information eliminates ambiguity, but it is inconvenient for end users. Users prefer to point out a location around the globe such as America/Los_Angeles or Europe/Paris.
This additional level of abstraction from zone offsets makes life easier but brings its own problems. For example, we now have to maintain a special time zone database to map time zone names to offsets. Since Spark runs on the JVM, it delegates the mapping to the Java standard library, which loads data from the Internet Assigned Numbers Authority Time Zone Database (IANA TZDB). Furthermore, the mapping mechanism in Java's standard library has some nuances that influence Spark's behavior. We focus on some of these nuances below.
Since Java 8, the JDK has exposed a new API for date-time manipulation and time zone offset resolution, and Spark migrated to this new API in version 3.0. Although the mapping of time zone names to offsets has the same source, IANA TZDB, it is implemented differently in Java 8 and higher versus Java 7.
As an example, let's take a look at a timestamp before the year 1883 in the 
America/Los_Angeles time zone: 1883-11-10 00:00:00. This year stands out from others because on November 18, 1883, all North American railroads switched to a new standard time system that henceforth governed their timetables.
Using the Java 7 time API, we can obtain time zone offset at the local timestamp as -08:00:
Java 8 API functions return a different result:
Prior to November 18, 1883, time of day was a local matter, and most cities and towns used some form of local solar time, maintained by a well-known clock (on a church steeple, for example, or in a jeweler's window). That's why we see such a strange time zone offset.
The example demonstrates that Java 8 functions are more precise and take into account historical data from IANA TZDB. After switching to the Java 8 time API, Spark 3.0 benefited from the improvement automatically and became more precise in how it resolves time zone offsets.
As we mentioned earlier, Spark 3.0 also switched to the Proleptic Gregorian calendar for the date type. The same is true for the timestamp type. The ISO SQL:2016 standard declares the valid range for timestamps is from 0001-01-01 00:00:00 to 9999-12-31 23:59:59.999999. Spark 3.0 fully conforms to the standard and supports all timestamps in this range. Comparing to Spark 2.4 and earlier, we should highlight the following sub-ranges:
0001-01-01 00:00:00..1582-10-03 23:59:59.999999. Spark 2.4 uses the Julian calendar and doesn't conform to the standard. Spark 3.0 fixes the issue and applies the Proleptic Gregorian calendar in internal operations on timestamps such as getting year, month, day, etc. Due to different calendars, some dates that exist in Spark 2.4 don't exist in Spark 3.0. For example, 1000-02-29 is not a valid date because 1000 isn't a leap year in the Gregorian calendar. Also, Spark 2.4 resolves time zone name to zone offsets incorrectly for this timestamp range.1582-10-04 00:00:00..1582-10-14 23:59:59.999999. This is a valid range of local timestamps in Spark 3.0, in contrast to Spark 2.4 where such timestamps didn't exist.1582-10-15 00:00:00..1899-12-31 23:59:59.999999. Spark 3.0 resolves time zone offsets correctly using historical data from IANA TZDB. Compared to Spark 3.0, Spark 2.4 might resolve zone offsets from time zone names incorrectly in some cases, as we showed above in the example.1900-01-01 00:00:00..2036-12-31 23:59:59.999999. Sia Spark 3.0 che Spark 2.4 sono conformi allo standard ANSI SQL e utilizzano il calendario Gregoriano nelle operazioni di data e ora, come ad esempio l'estrazione del giorno del mese.2037-01-01 00:00:00..9999-12-31 23:59:59.999999. Spark 2.4 può risolvere in modo errato gli offset dei fusi orari e in particolare gli offset dell'ora legale a causa del bug JDK #8073446. Spark 3.0 non soffre di questo difetto.
Un altro aspetto della mappatura dei nomi dei fusi orari agli offset è la sovrapposizione dei timestamp locali che può verificarsi a causa dell'ora legale (DST) o del passaggio a un altro offset di fuso orario standard. Ad esempio, il 3 novembre 2019, 02:00:00 le lancette sono state spostate indietro di 1 ora alle 01:00:00. Il timestamp locale 
2019-11-03 01:30:00 America/Los_Angeles può essere mappato a 2019-11-03 01:30:00 UTC-08:00 o 2019-11-03 01:30:00 UTC-07:00. Se non si specifica l'offset e ci si limita a impostare il nome del fuso orario (ad esempio, '2019-11-03 01:30:00 America/Los_Angeles'), Spark 3.0 utilizzerà l'offset precedente, corrispondente tipicamente all'ora "estiva". Il comportamento diverge da Spark 2.4 che utilizza l'offset "invernale". In caso di un intervallo, in cui le lancette saltano in avanti, non esiste un offset valido. Per una tipica modifica dell'ora legale di un'ora, Spark sposterà tali timestamp al timestamp valido successivo corrispondente all'ora "estiva".
Come possiamo vedere dagli esempi precedenti, la mappatura dei nomi dei fusi orari agli offset è ambigua e non è uno a uno. Nei casi in cui è possibile, raccomandiamo di specificare gli offset esatti del fuso orario quando si creano timestamp, ad esempio timestamp '2019-11-03 01:30:00 UTC-07:00'.
Spostiamoci dalla mappatura nome zona-offset e diamo un'occhiata allo standard ANSI SQL. Esso definisce due tipi di timestamp:
TIMESTAMP WITHOUT TIME ZONEoTIMESTAMP- Timestamp locale come (ANNO, MESE, GIORNO, ORA, MINUTO, SECONDO). Questi tipi di timestamp non sono legati a nessun fuso orario e sono di fatto timestamp dell'orologio "wall clock".TIMESTAMP WITH TIME ZONE- Timestamp con fuso orario come (ANNO, MESE, GIORNO, ORA, MINUTO, SECONDO, ORA_FUSO, MINUTO_FUSO). I timestamp rappresentano un istante nel fuso orario UTC + un offset di fuso orario (in ore e minuti) associato a ciascun valore.
L'offset del fuso orario di un TIMESTAMP WITH TIME ZONE non influisce sul punto fisico nel tempo che il timestamp rappresenta, poiché questo è completamente rappresentato dall'istante UTC fornito dagli altri componenti del timestamp. Invece, l'offset del fuso orario influisce solo sul comportamento predefinito di un valore di timestamp per la visualizzazione, l'estrazione di componenti di data/ora (ad esempio, EXTRACT) e altre operazioni che richiedono la conoscenza di un fuso orario, come l'aggiunta di mesi a un timestamp.
Spark SQL definisce il tipo di timestamp come TIMESTAMP WITH SESSION TIME ZONE, che è una combinazione dei campi (ANNO, MESE, GIORNO, ORA, MINUTO, SECONDO, SESSION TZ) in cui i campi ANNO fino a SECONDO identificano un istante temporale nel fuso orario UTC, e dove SESSION TZ viene preso dalla configurazione SQL spark.sql.session.timeZone. Il fuso orario della sessione può essere impostato come:
- Offset di zona
'(+|-)HH:mm'. Questa forma ci permette di definire un punto fisico nel tempo in modo non ambiguo. - Nome del fuso orario nella forma di ID regione
'area/città', come'America/Los_Angeles'. Questa forma di informazione sul fuso orario soffre di alcuni dei problemi che abbiamo descritto sopra, come la sovrapposizione dei timestamp locali. Tuttavia, ogni istante temporale UTC è associato in modo non ambiguo a un offset di fuso orario per qualsiasi ID di regione, e di conseguenza, ogni timestamp con un fuso orario basato sull'ID regione può essere convertito in modo non ambiguo in un timestamp con un offset di zona.
Per impostazione predefinita, il fuso orario della sessione è impostato sul fuso orario predefinito della Java virtual machine.
TIMESTAMP WITH SESSION TIME ZONE di Spark è diverso da:
TIMESTAMP WITHOUT TIME ZONE, perché un valore di questo tipo può essere mappato a più istanti fisici nel tempo, mentre qualsiasi valore diTIMESTAMP WITH SESSION TIME ZONEè un istante fisico concreto nel tempo. Il tipo SQL può essere emulato utilizzando un offset di fuso orario fisso in tutte le sessioni, ad esempio UTC+0. In tal caso, potremmo considerare i timestamp in UTC come timestamp locali.TIMESTAMP WITH TIME ZONE, perché secondo lo standard SQL i valori di colonna di questo tipo possono avere diversi offset di fuso orario. Questo non è supportato da Spark SQL.
Dovremmo notare che i timestamp associati a un fuso orario globale (in scope di sessione) non sono qualcosa di nuovo inventato da Spark SQL. RDBMS come Oracle forniscono un tipo simile anche per i timestamp: TIMESTAMP WITH LOCAL TIME ZONE.
Costruzione di date e timestamp
Spark SQL fornisce alcuni metodi per costruire valori di data e timestamp:
- Costruttori predefiniti senza parametri:
CURRENT_TIMESTAMP()eCURRENT_DATE(). - Da altri tipi primitivi Spark SQL, come
INT,LONGeSTRING - Da tipi esterni come
datetimedi Python o classi Javajava.time.LocalDate/Instant. - Deserializzazione da origini dati CSV, JSON, Avro, Parquet, ORC o altre.
La funzione MAKE_DATE introdotta in Spark 3.0 accetta tre parametri: ANNO, MESE dell'anno e GIORNO del mese e crea un valore DATE. Tutti i parametri di input vengono convertiti implicitamente al tipo INT quando possibile. La funzione verifica che le date risultanti siano date valide nel calendario Gregoriano Prolettico, altrimenti restituisce NULL. Ad esempio in PySpark:
Per stampare il contenuto del DataFrame, chiamiamo l'azione show(), che converte le date in stringhe sugli executor e trasferisce le stringhe al driver per visualizzarle sulla console:
Analogamente, possiamo creare valori di timestamp tramite le funzioni MAKE_TIMESTAMP. Come MAKE_DATE, esegue la stessa validazione per i campi data e accetta inoltre i campi ora ORA (0-23), MINUTO (0-59) e SECONDO (0-60). SECONDO ha il tipo Decimal(precision = 8, scale = 6) perché i secondi possono essere forniti con la parte frazionaria fino alla precisione del microsecondo. Ad esempio in PySpark:
Come abbiamo fatto per le date, stampiamo il contenuto del DataFrame ts utilizzando l'azione show(). In modo simile, show() converte i timestamp in stringhe, ma ora tiene conto del fuso orario della sessione definito dalla configurazione SQL spark.sql.session.timeZone. Vedremo questo nei seguenti esempi.
Spark non può creare l'ultimo timestamp perché questa data non è valida: il 2019 non è un anno bisestile.
Potresti notare che non abbiamo fornito alcuna informazione sul fuso orario nell'esempio precedente. In tal caso, Spark prende un fuso orario dalla configurazione SQL spark.sql.session.timeZone e lo applica alle invocazioni delle funzioni. Puoi anche scegliere un fuso orario diverso passandolo come ultimo parametro di MAKE_TIMESTAMP. Ecco un esempio in PySpark:
Come dimostra l'esempio, Spark tiene conto dei fusi orari specificati ma adegua tutti i timestamp locali al fuso orario della sessione. I fusi orari originali passati alla funzione MAKE_TIMESTAMP andranno persi perché il tipo TIMESTAMP WITH SESSION TIME ZONE presuppone che tutti i valori appartengano a un unico fuso orario e non memorizza nemmeno un fuso orario per ogni valore. Secondo la definizione di TIMESTAMP WITH SESSION TIME ZONE, Spark memorizza i timestamp locali nel fuso orario UTC e utilizza il fuso orario della sessione durante l'estrazione di campi data/ora o la conversione dei timestamp in stringhe.
Inoltre, i timestamp possono essere costruiti dal tipo LONG tramite casting. Se una colonna LONG contiene il numero di secondi dall'epoca 1970-01-01 00:00:00Z, può essere convertita al tipo TIMESTAMP di Spark SQL:
Sfortunatamente, questo approccio non ci permette di specificare la parte frazionaria dei secondi. In futuro, Spark SQL fornirà funzioni speciali per creare timestamp da secondi, millisecondi e microsecondi dall'epoca: timestamp_seconds(), timestamp_millis() e timestamp_micros().
Un altro modo è costruire date e timestamp da valori di tipo STRING. Possiamo creare letterali usando parole chiave speciali:
o tramite casting che possiamo applicare a tutti i valori di una colonna:
Le stringhe timestamp di input vengono interpretate come timestamp locali nel fuso orario specificato o nel fuso orario della sessione se un fuso orario viene omesso nella stringa di input. Stringhe con pattern insoliti possono essere convertite in timestamp utilizzando la funzione to_timestamp(). I pattern supportati sono descritti in Datetime Patterns for Formatting and Parsing:
La funzione si comporta in modo simile a CAST se non si specifica alcun pattern.
Per facilità d'uso, Spark SQL riconosce valori stringa speciali in tutti i metodi sopra che accettano una stringa e restituiscono un timestamp e una data:
- epoch è un alias per date '1970-01-01' o timestamp
'1970-01-01 00:00:00Z' - now è il timestamp o la data corrente nel fuso orario della sessione. All'interno di una singola query produce sempre lo stesso risultato.
- today è l'inizio della data corrente per il tipo
TIMESTAMPo semplicemente la data corrente per il tipoDATE. - tomorrow è l'inizio del giorno successivo per i timestamp o semplicemente il giorno successivo per il tipo
DATE. - yesterday è il giorno prima di quello corrente o il suo inizio per il tipo
TIMESTAMP.
Ad esempio:
Una delle grandi caratteristiche di Spark è la creazione di Datasets da collezioni esistenti di oggetti esterni sul lato driver e la creazione di colonne di tipi corrispondenti. Spark converte istanze di tipi esterni in rappresentazioni interne semanticamente equivalenti. PySpark consente di creare un Dataset con colonne DATE e TIMESTAMP da collezioni Python, ad esempio:
PySpark converte gli oggetti datetime di Python in rappresentazioni interne di Spark SQL sul lato driver utilizzando il fuso orario di sistema, che può essere diverso dalle impostazioni del fuso orario della sessione di Spark spark.sql.session.timeZone. I valori interni non contengono informazioni sul fuso orario originale. Le operazioni future sui valori di date e timestamp parallelizzati terranno conto solo del fuso orario delle sessioni di Spark SQL secondo la definizione del tipo TIMESTAMP WITH SESSION TIME ZONE.
In modo simile a quanto dimostrato sopra per le collezioni Python, Spark riconosce i seguenti tipi come tipi data/ora esterni nelle API Java/Scala:
- java.sql.Date e java.time.LocalDate come tipi esterni per il tipo DATE di Spark SQL
- java.sql.Timestamp e java.time.Instant per il tipo TIMESTAMP.
C'è una differenza tra i tipi java.sql.* e java.time.*. java.time.LocalDate e java.time.Instant sono stati aggiunti in Java 8 e i tipi si basano sul calendario Gregoriano Prolettico — lo stesso calendario utilizzato da Spark dalla versione 3.0. java.sql.Date e java.sql.Timestamp hanno un calendario sottostante diverso — il calendario ibrido (Giuliano + Gregoriano dal 1582-10-15), che è lo stesso del calendario legacy utilizzato da Spark nelle versioni precedenti alla 3.0. A causa dei diversi sistemi di calendario, Spark deve eseguire operazioni aggiuntive durante le conversioni in rappresentazioni interne di Spark SQL e ribasare le date/timestamp di input da un calendario all'altro. L'operazione di ribasamento ha un piccolo overhead per i timestamp moderni dopo il 1900 e può essere più significativa per i timestamp vecchi.
L'esempio seguente mostra la creazione di timestamp da collezioni Scala. Nel primo esempio, costruiamo un oggetto java.sql.Timestamp da una stringa. Il metodo valueOf interpreta le stringhe di input come un timestamp locale nel fuso orario predefinito della JVM, che può essere diverso dal fuso orario della sessione di Spark. Se è necessario costruire istanze di java.sql.Timestamp o java.sql.Date in un fuso orario specifico, si consiglia di consultare java.text.SimpleDateFormat (e il suo metodo setTimeZone) o java.util.Calendar.
Analogamente, possiamo creare una colonna DATE da collezioni di java.sql.Date o java.LocalDate. La parallelizzazione delle istanze di java.LocalDate è completamente indipendente dal fuso orario della sessione di Spark o dal fuso orario predefinito della JVM, ma non possiamo dire lo stesso per la parallelizzazione delle istanze di java.sql.Date. Ci sono delle sfumature:
- Le istanze di
java.sql.Daterappresentano date locali nel fuso orario predefinito della JVM sul driver - Per conversioni corrette ai valori di Spark SQL, il fuso orario predefinito della JVM sul driver e sugli executor deve essere lo stesso.
Per evitare problemi legati a calendari e fusi orari, raccomandiamo i tipi Java 8 java.LocalDate/Instant come tipi esterni nella parallelizzazione di collezioni Java/Scala di timestamp o date.
Raccolta di date e timestamp
L'operazione inversa alla parallelizzazione è la raccolta di date e timestamp dagli executor al driver e la restituzione di una collezione di tipi esterni. Nell'esempio precedente, possiamo recuperare il DataFrame al driver tramite l'azione collect():
Spark trasferisce i valori interni delle colonne date e timestamp come istanti temporali nel fuso orario UTC dagli executor al driver, ed esegue conversioni in oggetti datetime Python nel fuso orario di sistema sul driver, non utilizzando il fuso orario della sessione Spark SQL. collect() è diverso dall'azione show() descritta nella sezione precedente. show() utilizza il fuso orario della sessione durante la conversione dei timestamp in stringhe, e raccoglie le stringhe risultanti sul driver.
Nelle API Java e Scala, Spark esegue le seguenti conversioni per impostazione predefinita:
- I valori
DATEdi Spark SQL vengono convertiti in istanze dijava.sql.Date. - I timestamp vengono convertiti in istanze di
java.sql.Timestamp.
Entrambe le conversioni vengono eseguite nel fuso orario predefinito della JVM sul driver. In questo modo, per avere gli stessi campi data-ora che possiamo ottenere tramite Date.getDay(), getHour(), ecc. e tramite le funzioni Spark SQL DAY, HOUR, il fuso orario predefinito della JVM sul driver e il fuso orario della sessione sugli executor dovrebbero essere gli stessi.
Similmente alla creazione di date/timestamp da java.sql.Date/Timestamp, Spark 3.0 esegue il rebasamento dal calendario Gregoriano Prolettico al calendario ibrido (Giuliano + Gregoriano). Questa operazione è quasi gratuita per date moderne (dopo il 1582) e timestamp (dopo il 1900), ma potrebbe comportare un certo overhead per date e timestamp antichi.
Possiamo evitare tali problemi legati al calendario, e chiedere a Spark di restituire tipi java.time, che sono stati aggiunti da Java 8. Se impostiamo la configurazione SQL spark.sql.datetime.java8API.enabled su true, l'azione Dataset.collect() restituirà:
java.time.LocalDateper il tipoDATEdi Spark SQLjava.time.Instantper il tipoTIMESTAMPdi Spark SQL
Ora le conversioni non soffrono di problemi legati al calendario perché i tipi Java 8 e Spark SQL 3.0 si basano entrambi sul calendario Gregoriano Prolettico. L'azione collect() non dipende più dal fuso orario predefinito della JVM. Le conversioni dei timestamp non dipendono affatto dal fuso orario. Per quanto riguarda la conversione delle date, utilizza il fuso orario della sessione dalla configurazione SQL spark.sql.session.timeZone. Ad esempio, diamo un'occhiata a un Dataset con colonne DATE e TIMESTAMP, impostiamo il fuso orario predefinito della JVM su Europe/Moscow, ma il fuso orario della sessione su America/Los_Angeles.
L'azione show() stampa il timestamp nel fuso orario della sessione America/Los_Angeles, ma se raccogliamo il Dataset, verrà convertito in java.sql.Timestamp e stampato in Europe/Moscow dal metodo toString:
In realtà, il timestamp locale 2020-07-01 00:00:00 è 2020-07-01T07:00:00Z in UTC. Possiamo osservarlo se abilitiamo l'API Java 8 e raccogliamo il Dataset:
L'oggetto java.time.Instant può essere successivamente convertito in qualsiasi timestamp locale indipendentemente dal fuso orario globale della JVM. Questo è uno dei vantaggi di java.time.Instant rispetto a java.sql.Timestamp. Il primo richiede la modifica dell'impostazione globale della JVM, che influenza altri timestamp sulla stessa JVM. Pertanto, se le tue applicazioni elaborano date o timestamp in fusi orari diversi, e le applicazioni non dovrebbero entrare in conflitto tra loro durante la raccolta dei dati sul driver tramite l'API Java/Scala Dataset.collect(), raccomandiamo di passare all'API Java 8 utilizzando la configurazione SQL spark.sql.datetime.java8API.enabled.
Conclusione
In questo post del blog, abbiamo descritto i tipi DATE e TIMESTAMP di Spark SQL. Abbiamo mostrato come costruire colonne di date e timestamp da altri tipi primitivi Spark SQL e tipi Java esterni, e come raccogliere colonne di date e timestamp sul driver come tipi Java esterni. Dalla versione 3.0, Spark è passato dal calendario ibrido, che combina i calendari Giuliano e Gregoriano, al calendario Gregoriano Prolettico (vedi SPARK-26651 per maggiori dettagli). Questo ha permesso a Spark di eliminare molti problemi come quelli che abbiamo dimostrato in precedenza. Per compatibilità con le versioni precedenti, Spark restituisce ancora timestamp e date nel calendario ibrido (java.sql.Date e java.sql.Timestamp) dalle azioni di tipo collect. Per evitare problemi di risoluzione del calendario e del fuso orario quando si utilizzano le azioni collect di Java/Scala, l'API Java 8 può essere abilitata tramite la configurazione SQL spark.sql.datetime.java8API.enabled. Provalo oggi stesso gratuitamente su Databricks come parte del nostro Databricks Runtime 7.0.

Libro O'Reilly Learning Spark
La 2a edizione gratuita include aggiornamenti su Spark 3.0, inclusi i nuovi type hint Python per Pandas UDF, la nuova implementazione di data/ora, ecc.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.