Applicare la crittografia a livello di colonna ed evitare la duplicazione dei dati con PII
Utilizzo di librerie di crittografia Fernet, UDF e segreti Databricks per proteggere in modo discreto i dati PII
di Keyuri Shah e Fred Kimball
Questo è un guest post di Keyuri Shah, lead software engineer, e Fred Kimball, software engineer, Northwestern Mutual.
Proteggere le PII (informazioni personali identificabili) è molto importante dato che il numero di violazioni dei dati e di record con informazioni sensibili esposti ogni giorno è in aumento. Per evitare di diventare la prossima vittima e proteggere gli utenti dal furto di identità e dalle frodi, dobbiamo incorporare più livelli di sicurezza dei dati e delle informazioni.
Poiché utilizziamo la piattaforma Databricks, dobbiamo assicurarci di consentire l'accesso alle informazioni sensibili solo alle persone giuste. Utilizzando una combinazione di librerie di crittografia Fernet, funzioni definite dall'utente (UDF) e segreti Databricks, Northwestern Mutual ha sviluppato un processo per crittografare le informazioni PII e consentire solo a coloro che ne hanno un bisogno aziendale di decrittografarle, senza passaggi aggiuntivi necessari per il lettore di dati.
La necessità di proteggere le PII
La gestione di qualsiasi quantità di dati dei clienti oggigiorno richiede quasi certamente la protezione delle PII. Questo è un rischio elevato per le organizzazioni di tutte le dimensioni, poiché casi come la violazione dei dati di Capital One hanno comportato il furto di milioni di record sensibili di clienti a causa di un semplice errore di configurazione. Sebbene la crittografia del dispositivo di archiviazione e il mascheramento delle colonne a livello di tabella siano misure di sicurezza efficaci, l'accesso interno non autorizzato a questi dati sensibili rappresenta ancora una minaccia importante. Pertanto, abbiamo bisogno di una soluzione che impedisca a un utente normale con accesso a file o tabelle di recuperare informazioni sensibili all'interno di Databricks.
Tuttavia, abbiamo anche bisogno che coloro che hanno un bisogno aziendale di leggere informazioni sensibili siano in grado di farlo. Non vogliamo che ci sia una differenza nel modo in cui ogni tipo di utente legge la tabella. Sia le letture normali che quelle decrittografate dovrebbero avvenire sullo stesso oggetto Delta Lake per semplificare la costruzione delle query per l'analisi dei dati e la costruzione dei report.
Costruire il processo per applicare la crittografia a livello di colonna
Date queste esigenze di sicurezza, abbiamo cercato di creare un processo sicuro, non intrusivo e facile da gestire. Il diagramma seguente fornisce una panoramica generale dei componenti necessari per questo processo
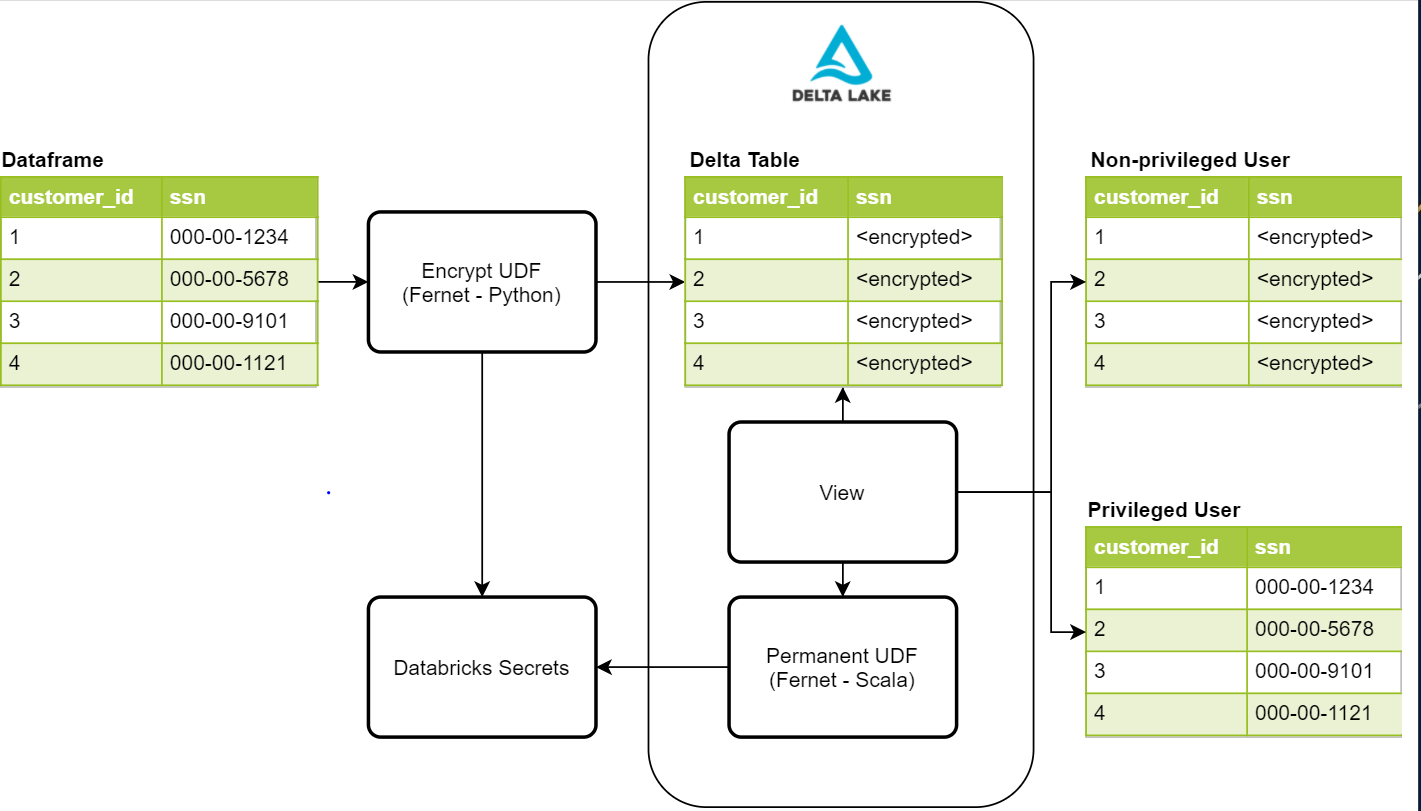
Scrivere PII protette con Fernet
Il primo passo in questo processo è proteggere i dati crittografandoli. Una possibile soluzione è la libreria Python Fernet. Fernet utilizza la crittografia simmetrica, che è costruita con diversi primitivi crittografici standard. Questa libreria viene utilizzata all'interno di un UDF di crittografia che ci consentirà di crittografare qualsiasi colonna data in un dataframe. Per archiviare la chiave di crittografia, utilizziamo i segreti Databricks con controlli di accesso in atto per consentire solo al nostro processo di ingestione dati di accedervi. Una volta che i dati vengono scritti nelle nostre tabelle Delta Lake, le colonne PII che contengono valori come il numero di previdenza sociale, il numero di telefono, il numero di carta di credito e altri identificatori saranno impossibili da leggere per un utente non autorizzato.
Leggere i dati protetti da una vista con UDF personalizzato
Una volta che abbiamo scritto e protetto i dati sensibili, abbiamo bisogno di un modo per gli utenti privilegiati di leggere i dati sensibili. La prima cosa da fare è creare un UDF permanente da aggiungere all'istanza Hive in esecuzione su Databricks. Affinché un UDF sia permanente, deve essere scritto in Scala. Fortunatamente, Fernet ha anche un'implementazione Scala che possiamo sfruttare per le nostre letture decrittografate. Questo UDF accede anche allo stesso segreto che abbiamo utilizzato nella scrittura crittografata per eseguire la decrittografia e, in questo caso, viene aggiunto alla configurazione Spark del cluster. Ciò richiede l'aggiunta di controlli di accesso al cluster per utenti privilegiati e non privilegiati per controllare il loro accesso alla chiave. Una volta creato l'UDF, possiamo utilizzarlo all'interno delle nostre definizioni di vista per consentire agli utenti privilegiati di visualizzare i dati decrittografati.
Attualmente, abbiamo due oggetti vista per un singolo set di dati, uno per gli utenti privilegiati e uno per quelli non privilegiati. La vista per gli utenti non privilegiati non ha l'UDF, quindi vedranno i valori PII come valori crittografati. L'altra vista per gli utenti privilegiati ha l'UDF, quindi possono vedere i valori decrittografati in testo normale per le loro esigenze aziendali. L'accesso a queste viste è inoltre controllato dai controlli di accesso alle tabelle forniti da Databricks.
Nel prossimo futuro, vogliamo sfruttare una nuova funzionalità di Databricks chiamata funzioni di vista dinamiche. Queste funzioni di vista dinamiche ci consentiranno di utilizzare una sola vista e restituire facilmente i valori crittografati o decrittografati in base al gruppo Databricks di cui fanno parte. Ciò ridurrà la quantità di oggetti che stiamo creando nel nostro Delta Lake e semplificherà le nostre regole di controllo degli accessi alle tabelle.
Entrambe le implementazioni consentono agli utenti di eseguire il loro sviluppo o analisi senza preoccuparsi se devono o meno decrittografare i valori letti dalla vista e consentono l'accesso solo a coloro che ne hanno un bisogno aziendale.
Vantaggi di questo metodo di crittografia a livello di colonna
In sintesi, i vantaggi dell'utilizzo di questo processo sono:
- La crittografia può essere eseguita utilizzando librerie Python o Scala esistenti
- I dati PII sensibili hanno un ulteriore livello di sicurezza quando archiviati in Delta Lake
- Lo stesso oggetto Delta Lake viene utilizzato dagli utenti con tutti i livelli di accesso a tale oggetto
- Gli analisti non sono ostacolati, indipendentemente dal fatto che siano autorizzati a leggere le PII
Per un esempio di come potrebbe apparire, il seguente notebook potrebbe fornire una guida:
Risorse aggiuntive:
Librerie Fernet
Crea UDF permanente
Funzioni di vista dinamiche
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.