Scalare i calcoli SHAP con PySpark e Pandas UDF
di Sepideh Ebrahimi e P. Patel
Motivazione
Con la proliferazione delle applicazioni dei modelli di Machine Learning (ML) e soprattutto di Deep Learning (DL) nei processi decisionali, sta diventando sempre più fondamentale guardare attraverso la scatola nera e giustificare le decisioni aziendali chiave basate sui risultati di tali modelli. Ad esempio, se un modello ML rifiuta la richiesta di prestito di un cliente o assegna un rischio di credito a un determinato cliente nel prestito peer-to-peer, fornire agli stakeholder aziendali una spiegazione del motivo per cui è stata presa questa decisione potrebbe essere un potente strumento per incoraggiare l'adozione dei modelli. In molti casi, l'ML interpretabile non è solo un requisito aziendale, ma anche un requisito normativo per comprendere perché una determinata decisione o opzione è stata fornita a un cliente. SHapley Additive exPlanations (SHAP) è uno strumento importante che si può sfruttare per l'IA spiegabile e per aiutare a creare fiducia nei risultati dei modelli di ML e delle reti neurali nella risoluzione di problemi aziendali.
SHAP è un framework all'avanguardia per la spiegazione dei modelli basato sulla Teoria dei giochi. L'approccio consiste nel trovare una relazione lineare tra le feature di un modello e l'output del modello per ogni punto dati nel tuo set di dati. Utilizzando questo framework, è possibile interpretare l'output del modello a livello globale o locale. L'interpretabilità globale aiuta a capire in che misura ogni feature contribuisce ai risultati in modo positivo o negativo. D'altra parte, l'interpretabilità locale aiuta a capire l'effetto di ogni feature per una data osservazione.
Le implementazioni di SHAP più comuni, ampiamente adottate nella community della data science, vengono eseguite su macchine a nodo singolo, il che significa che eseguono tutti i calcoli su un singolo core, indipendentemente da quanti core siano disponibili. Pertanto, non sfruttano le capacità di calcolo distribuito e sono vincolate dalle limitazioni di un singolo core.
In questo post, dimostreremo un modo semplice per parallelizzare i calcoli dei valori SHAP su più macchine, in particolare per l'interpretabilità locale. Spiegheremo poi come questa soluzione scala al crescere del numero di righe e colonne nel set di dati. Infine, evidenzieremo alcuni dei nostri risultati su cosa funziona e cosa evitare quando si parallelizzano i calcoli SHAP con Spark.
SHAP a nodo singolo
Per ottenere la spiegabilità, SHAP converte un modello in un Explainer; le singole previsioni del modello vengono poi spiegate applicando ad esse l'Explainer. Esistono diverse implementazioni per il calcolo dei valori SHAP in diversi linguaggi di programmazione, inclusa una popolare in Python. Con questa implementazione, per ottenere spiegazioni per ogni osservazione, è possibile applicare un explainer appropriato per il modello in uso. Il seguente snippet di codice illustra come applicare un TreeExplainer a un classificatore Random Forest.
Questo metodo funziona bene per piccoli volumi di dati, ma quando si tratta di spiegare l'output di un modello di ML per milioni di record, non scala bene a causa della natura a nodo singolo dell'implementazione. Ad esempio, la visualizzazione nella figura 1 sottostante mostra la crescita del tempo di esecuzione di un calcolo dei valori SHAP su una macchina a nodo singolo (4 core e 30,5 GB di memoria) per un numero crescente di record. La macchina ha esaurito la memoria per dimensioni dei dati superiori a 1 milione di righe e 50 colonne, pertanto tali valori non sono presenti nella figura. Come si può vedere, il tempo di esecuzione cresce in modo quasi lineare con il numero di record, il che non è sostenibile in scenari reali. Attendere, ad esempio, 10 ore per capire perché un modello di machine learning ha effettuato una previsione non è né efficiente né accettabile in molti contesti aziendali.
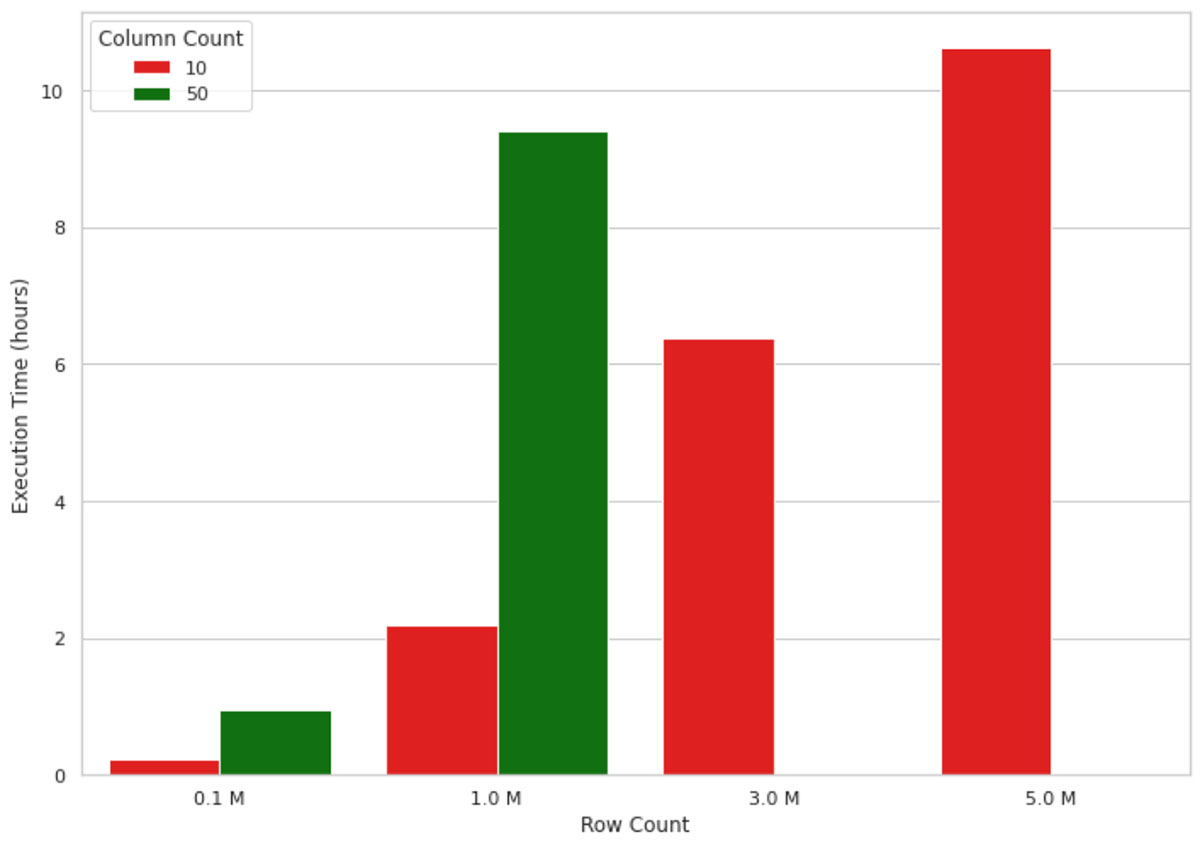
Un modo per risolvere questo problema è l'uso del calcolo approssimativo. È possibile impostare l'argomento approximate su True nel metodo shap_values. In questo modo, le suddivisioni inferiori nell'albero avranno pesi maggiori e non vi è alcuna garanzia che i valori SHAP siano coerenti con il calcolo esatto. Ciò accelererà i calcoli, ma potresti ottenere una spiegazione imprecisa dell'output del tuo modello. Inoltre, l'argomento approximate è disponibile solo in TreeExplainer.
Un approccio alternativo consisterebbe nello sfruttare un framework di elaborazione distribuita come Apache Spark™ per parallelizzare l'applicazione dell'Explainer su più core.
Scalare i calcoli SHAP con PySpark
Per distribuire i calcoli SHAP, stiamo lavorando con questa implementazione Python e con le UDF di Pandas in PySpark. Stiamo usando il set di dati kddcup99 per creare un rilevatore di intrusioni di rete, un modello predittivo in grado di distinguere tra connessioni dannose, chiamate intrusioni o attacchi, e buone connessioni normali. Questo set di dati è noto per essere difettoso per scopi di rilevamento delle intrusioni. Tuttavia, in questo post, ci stiamo concentrando esclusivamente sui calcoli dei valori SHAP e non sulla semantica del modello di ML sottostante.
I due modelli che abbiamo creato per i nostri esperimenti sono semplici classificatori Random Forest addestrati su set di dati con 10 e 50 feature per mostrare la scalabilità della soluzione su diverse dimensioni di colonna. Si noti che il set di dati originale ha meno di 50 colonne e abbiamo replicato alcune di queste colonne per raggiungere il volume di dati desiderato. I volumi di dati con cui abbiamo sperimentato vanno da 4 MB a 1,85 GB.
Prima di addentrarci nel codice, forniamo una rapida panoramica di come funzionano i Dataframe Spark e le UDF. I Dataframe Spark sono distribuiti (per righe) in un cluster, ogni raggruppamento di righe è chiamato partizione e ogni partizione (per impostazione predefinita) può essere elaborata da 1 core. È così che Spark ottiene fondamentalmente l'elaborazione parallela. Le UDF di Pandas sono una scelta naturale, poiché pandas può essere facilmente integrato con SHAP ed è performante. Una UDF di pandas, a volte nota come UDF vettorizzata, offre prestazioni migliori rispetto alle UDF di Python utilizzando Apache Arrow per ottimizzare il trasferimento dei dati.
Lo snippet di codice seguente mostra come parallelizzare l'applicazione di un Explainer con una UDF Pandas in PySpark. Definiamo una UDF pandas denominata calculate_shap e quindi passiamo questa funzione a mapInPandas. Questo metodo viene quindi usato per applicare il metodo parallelizzato al dataframe PySpark. Useremo questa UDF per eseguire i nostri test delle prestazioni di SHAP.
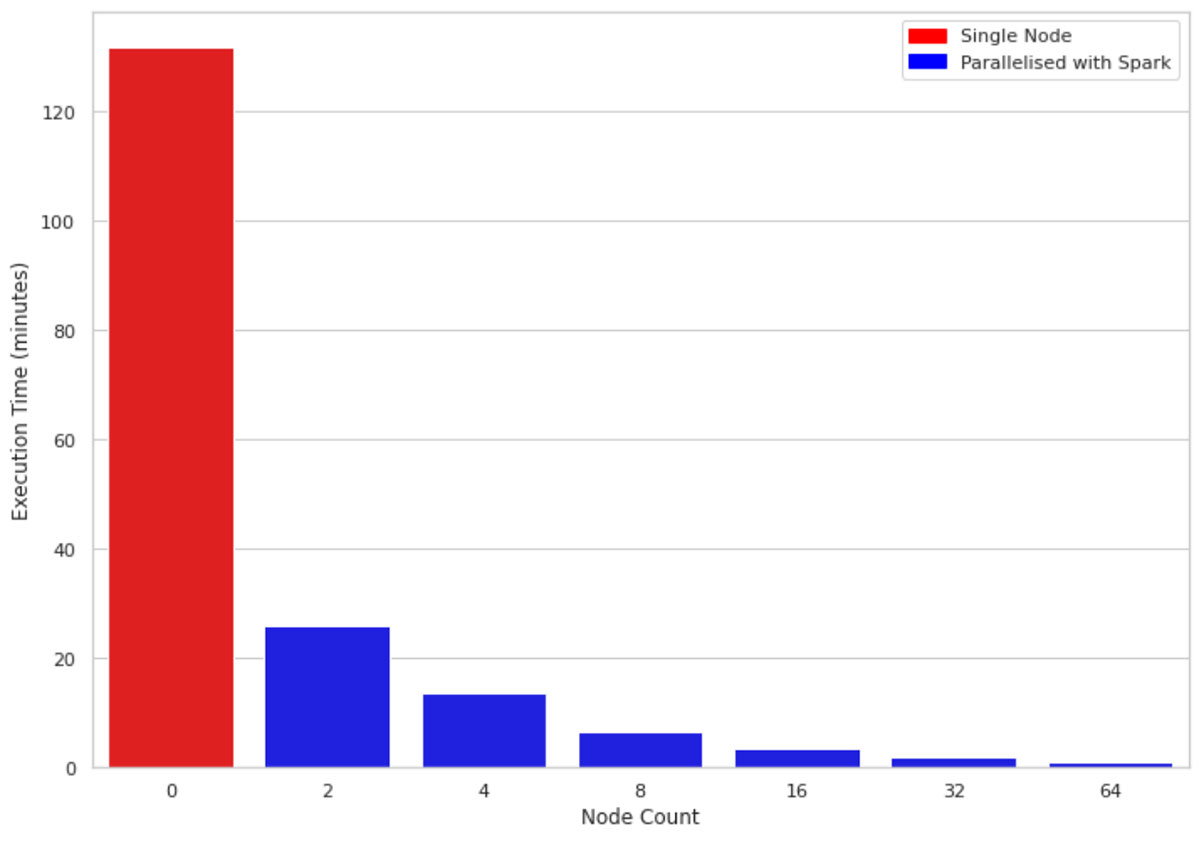
La Figura 2 confronta il tempo di esecuzione di 1 milione di righe e 10 colonne su una macchina a nodo singolo rispetto a clusters di dimensioni 2, 4, 8, 16, 32 e 64 rispettivamente. Le macchine sottostanti per tutti i cluster sono simili (4 core e 30,5 GB di memoria). Un'osservazione interessante è che il codice parallelizzato sfrutta tutti i core sui nodi del clusters. Pertanto, anche l'utilizzo di un cluster di dimensione 2 migliora le prestazioni di quasi 5 volte.
Scalabilità con l'aumento delle dimensioni dei dati
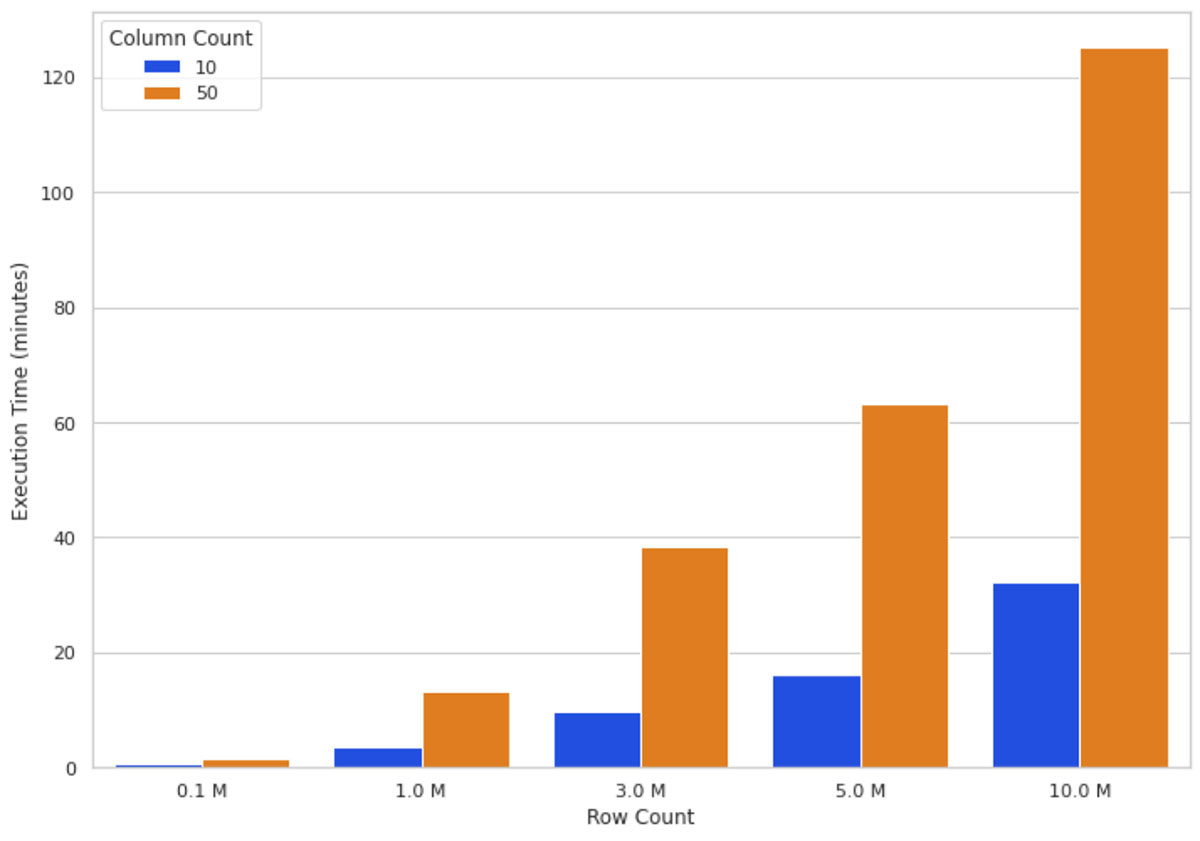
A causa del modo in cui è implementato SHAP, le feature aggiuntive hanno un impatto maggiore sulle prestazioni rispetto alle righe aggiuntive. Ora sappiamo che i valori SHAP possono essere calcolati più rapidamente usando Spark e UDF Pandas. Vediamo ora il comportamento di SHAP con feature/colonne aggiuntive.
Intuitivamente, l'aumento delle dimensioni dei dati significa più calcoli da elaborare per l'algoritmo SHAP. La figura 3 illustra i tempi di esecuzione dei valori SHAP su un cluster a 16 nodi per diversi numeri di righe e colonne. Si può notare che il tempo di esecuzione aumenta in modo quasi direttamente proporzionale all'aumentare del numero di righe: raddoppiare il numero di righe quasi raddoppia il tempo di esecuzione. L'aumento del numero di colonne ha una relazione proporzionale con il tempo di esecuzione; l'aggiunta di una colonna aumenta il tempo di esecuzione di quasi l'80%.
Queste osservazioni (Figura 2 e Figura 3) ci hanno portato a concludere che più dati si hanno, più è possibile scalare il calcolo orizzontalmente (aggiungendo più nodi worker) per mantenere ragionevole il tempo di esecuzione.
Quando considerare la parallelizzazione?
Le domande a cui volevamo rispondere sono: quando vale la pena parallelizzare? Quando si dovrebbe iniziare a usare PySpark per parallelizzare i calcoli SHAP, anche con la consapevolezza che ciò potrebbe aumentare il carico di calcolo? Abbiamo impostato un esperimento per misurare l'effetto del raddoppio delle dimensioni del cluster sul miglioramento del tempo di esecuzione del calcolo SHAP. Lo scopo dell'esperimento è capire quale dimensione di dati giustifichi l'impiego di più risorse orizzontali (ovvero, l'aggiunta di più nodi worker) per il problema.
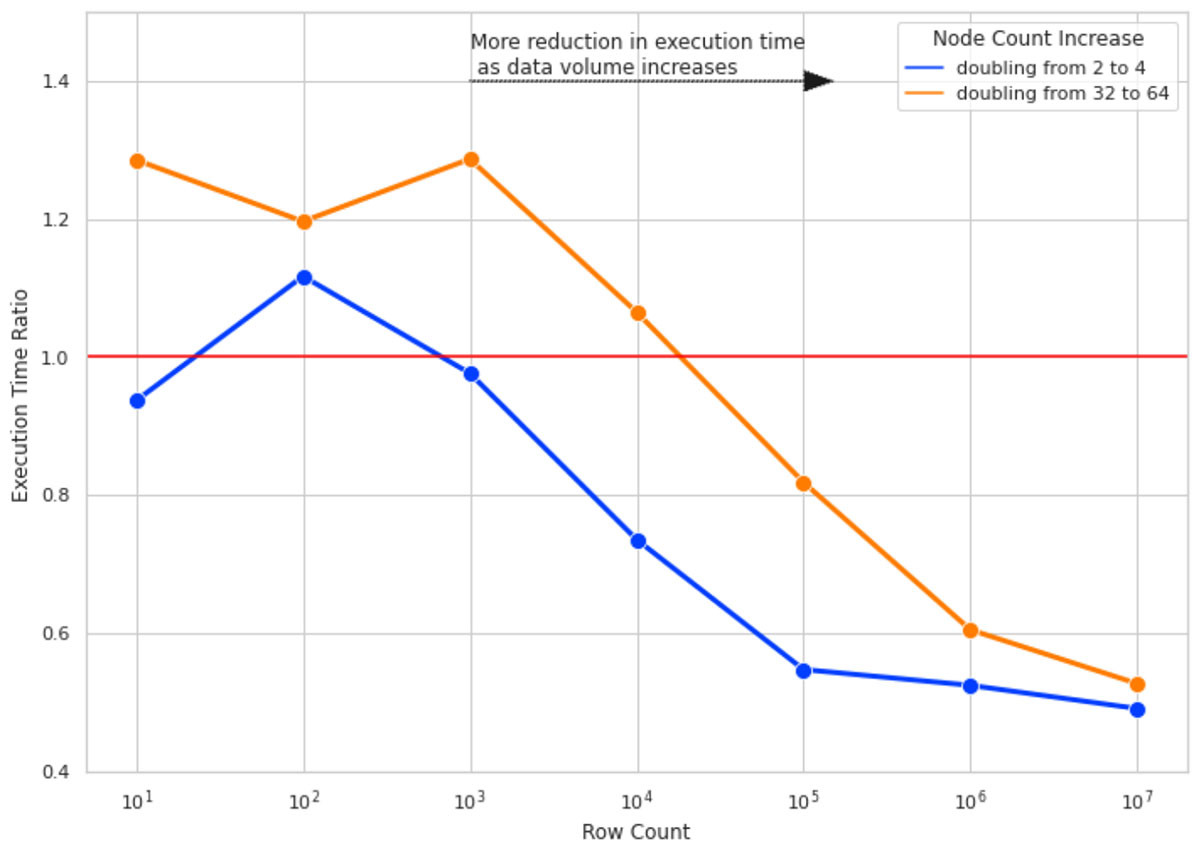
Abbiamo eseguito i calcoli SHAP per 10 colonne di dati e per un numero di righe di 10, 100, 1.000 e così via, fino a 10 milioni. Per ogni numero di righe, abbiamo misurato 4 volte il tempo di esecuzione del calcolo SHAP per cluster di dimensioni pari a 2, 4, 32 e 64. Il rapporto del tempo di esecuzione è il rapporto tra il tempo di esecuzione del calcolo dei valori SHAP su clusters maggiori (4 e 64) e quello su clusters con la metà dei nodi (rispettivamente 2 e 32).
La figura 4 illustra il risultato di questo esperimento. Ecco i punti principali:
-
- Per un numero ridotto di righe, raddoppiare le dimensioni dei clusters non migliora il tempo di esecuzione e, in alcuni casi, lo peggiora a causa dell'overhead aggiunto dalla gestione delle attività di Spark (da qui il rapporto del tempo di esecuzione > 1).
- Aumentando il numero di righe, raddoppiare la dimensione dei clusters diventa più efficace. Per 10 milioni di righe di dati, raddoppiare la dimensione del cluster quasi dimezza il tempo di esecuzione.
- Per tutti i numeri di righe, raddoppiare la dimensione del cluster da 2 a 4 è più efficace che raddoppiarla da 32 a 64 (notare il divario tra le linee blu e arancione). Man mano che la dimensione del cluster cresce, aumenta anche l'overhead dovuto all'aggiunta di più nodi. Ciò è dovuto a dimensioni delle partizioni in cui la dimensione dei dati per partizione è troppo piccola, e ciò aggiunge più overhead per creare un'attività separata per elaborare la piccola quantità di dati piuttosto che utilizzare una dimensione dati/partizione più ottimale.
Problemi
Ripartizione
Come accennato in precedenza, Spark implementa il parallelismo attraverso il concetto di partizioni; i dati vengono partizionati in blocchi di righe e ogni partizione viene elaborata da un singolo core per impostazione predefinita. Quando i dati vengono letti inizialmente da Apache Spark, questo potrebbe non creare necessariamente partizioni ottimali per il calcolo che si desidera eseguire sul cluster. In particolare, per il calcolo dei valori SHAP, possiamo potenzialmente ottenere prestazioni migliori ripartizionando il nostro set di dati.
È importante trovare un equilibrio tra la creazione di partizioni abbastanza piccole e non così piccole che l'overhead per la loro creazione superi i benefici della parallelizzazione dei calcoli.
Per il nostro test delle prestazioni abbiamo deciso di utilizzare tutti i core del cluster utilizzando il seguente codice:
Per volumi di dati ancora più grandi, è consigliabile impostare il numero di partizioni a 2 o 3 volte il numero di core. L'importante è fare un Experiment e trovare la migliore strategia di partizionamento per i propri dati.
Uso di display()
Se si lavora su un notebook Databricks, è consigliabile evitare l'uso della funzione display() quando si effettua il benchmark dei tempi di esecuzione. L'uso di display() potrebbe non mostrare necessariamente la durata di una trasformazione completa; ha un limite di righe implicito che viene inserito nella query e, a seconda dell'attività operativa che si desidera misurare, ad esempio la scrittura su un file, si verifica un overhead aggiuntivo nel recupero dei risultati sul driver. I nostri tempi di esecuzione sono stati misurati utilizzando il metodo write di Spark con il formato “noop”.
Conclusione
In questo post su un blog, abbiamo introdotto una soluzione per accelerare i calcoli SHAP parallelizzandoli con PySpark e le UDF di Pandas. Abbiamo quindi valutato le prestazioni della soluzione su volumi di dati crescenti, diversi tipi di macchine e configurazioni variabili. Ecco i punti chiave:
-
-
- Il calcolo SHAP a nodo singolo cresce linearmente con il numero di righe e colonne.
- La parallelizzazione dei calcoli SHAP con PySpark migliora le prestazioni eseguendo i calcoli su tutte le CPU del cluster.
- Aumentare la dimensione del cluster è più efficace quando si hanno Big Data. Per dati di piccole dimensioni, questo metodo non è efficace.
-
Lavori futuri
Scalabilità verticale - Lo scopo del post su un blog era mostrare come la scalabilità orizzontale con set di dati di grandi dimensioni possa migliorare le prestazioni del calcolo dei valori SHAP. Siamo partiti dal presupposto che ogni nodo del nostro cluster avesse 4 core e 30,5 GB. In futuro, sarebbe interessante testare le prestazioni della scalabilità sia verticale che orizzontale; ad esempio, confrontando le prestazioni tra un cluster di 4 nodi (4 core, 30,5 GB ciascuno) e un cluster di 2 nodi (8 core, 61 GB ciascuno).
Serializzazione/Deserializzazione - Come accennato, uno dei motivi principali per utilizzare le UDF di Pandas rispetto alle UDF di Python è che le UDF di Pandas utilizzano Apache Arrow per migliorare la serializzazione/deserializzazione dei dati tra la JVM e il processo python. Potrebbero esserci alcune potenziali ottimizzazioni durante la conversione delle partizioni di dati Spark in batch di record Arrow; sperimentare con la dimensione del batch di Arrow potrebbe portare a ulteriori guadagni in termini di prestazioni.
Confronto con le implementazioni distribuite di SHAP - Sarebbe interessante confrontare i risultati della nostra soluzione con le implementazioni distribuite di SHAP, come Shparkley. Nel condurre un tale studio comparativo, sarebbe importante assicurarsi innanzitutto che gli output di entrambe le soluzioni siano confrontabili.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.