Organizzazione Funzionale dell'Area di Lavoro su Databricks
Databricks Admin Essentials: Blog 1/5
Introduzione
Questo blog è la prima parte della nostra serie Admin Essentials, in cui ci concentreremo su argomenti importanti per chi gestisce e mantiene gli ambienti Databricks. Tieni d'occhio i blog aggiuntivi su governance dei dati, operazioni e automazione, gestione utenti e accessibilità, e monitoraggio e gestione dei costi nel prossimo futuro!
Nel 2020, Databricks ha iniziato a rilasciare anteprime private di diverse funzionalità della piattaforma conosciute collettivamente come Enterprise 2.0 (o E2); queste funzionalità hanno fornito la prossima iterazione della piattaforma Lakehouse, creando la scalabilità e la sicurezza per eguagliare la potenza e la velocità già disponibili su Databricks. Quando Enterprise 2.0 è diventato pubblicamente disponibile, una delle aggiunte più attese è stata la possibilità di creare più workspace da un singolo account. Questa funzionalità ha aperto nuove possibilità di collaborazione, allineamento organizzativo e semplificazione. Come abbiamo scoperto da allora, tuttavia, ha anche sollevato una serie di domande. Sulla base della nostra esperienza con clienti enterprise di ogni dimensione, forma e settore, questo blog fornirà risposte e best practice alle domande più comuni sulla gestione dei workspace all'interno di Databricks; a livello fondamentale, questo si riduce a una semplice domanda: quando esattamente dovrebbe essere creato un nuovo workspace? Nello specifico, evidenzieremo le strategie chiave per organizzare i tuoi workspace e le best practice per ciascuna.
Basi dell'organizzazione dei workspace
Sebbene ogni provider cloud (AWS, Azure e GCP) abbia un'architettura sottostante diversa, l'organizzazione dei workspace Databricks tra i cloud è simile. La costruzione logica di livello superiore è un account master E2 (AWS) o un oggetto subscription (Azure Databricks/GCP). In AWS, forniamo un singolo account E2 per organizzazione che offre un pannello unificato di visibilità e controllo per tutti i workspace. In questo modo, la tua attività di amministrazione è centralizzata, con la possibilità di abilitare SSO, Audit Logs e Unity Catalog. Azure ha relativamente meno restrizioni sulla creazione di oggetti subscription di livello superiore; tuttavia, raccomandiamo comunque che il numero di subscription di livello superiore utilizzate per creare workspace Databricks sia controllato il più possibile. Faremo riferimento alla costruzione di livello superiore come account durante questo blog, sia che si tratti di un account AWS E2 o di una subscription GCP/Azure.
All'interno di un account di livello superiore, è possibile creare più workspace. Il numero massimo raccomandato di workspace per account è compreso tra 20 e 50 su Azure, con un limite rigido su AWS. Questo limite deriva dall'overhead amministrativo che deriva da un numero crescente di workspace: la gestione della collaborazione, dell'accesso e della sicurezza su centinaia di workspace può diventare un compito estremamente difficile, anche con processi di automazione eccezionali. Di seguito, presentiamo un modello di oggetto di alto livello di un account Databricks.
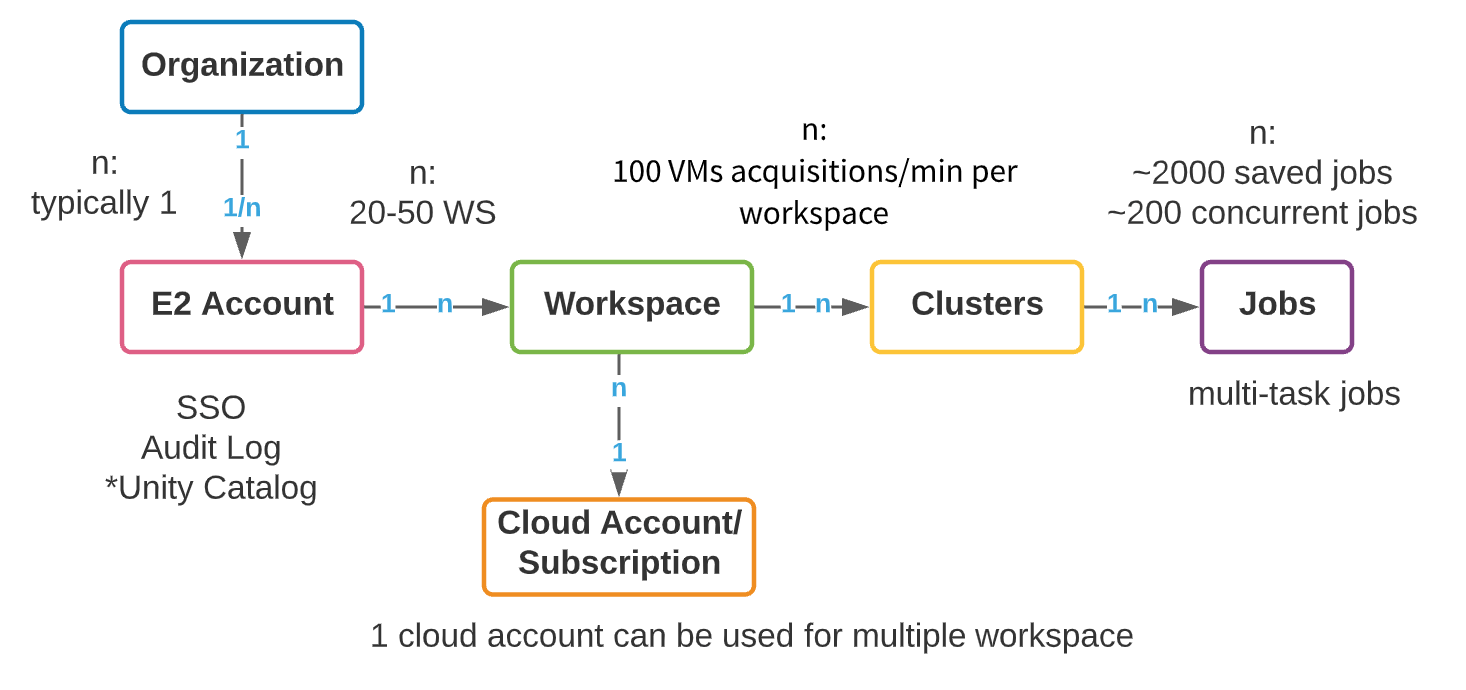
Le aziende devono creare risorse nei loro account cloud per supportare i requisiti di multi-tenancy. La creazione di account cloud e workspace separati per ogni nuovo caso d'uso presenta alcuni chiari vantaggi: facilità di monitoraggio dei costi, isolamento dei dati e degli utenti e un raggio d'azione più ridotto in caso di incidenti di sicurezza. Tuttavia, la proliferazione degli account comporta un set separato di complessità: la governance, la gestione dei metadati e l'overhead di collaborazione crescono insieme al numero di account. La chiave, ovviamente, è l'equilibrio. Di seguito, esamineremo prima alcune considerazioni generali per l'organizzazione dei workspace enterprise; quindi, esamineremo due strategie comuni di isolamento dei workspace che vediamo tra i nostri clienti: basate su LOB (Line of Business) e basate su prodotto. Ognuna ha punti di forza, debolezza e complessità che discuteremo prima di fornire le best practice.
Considerazioni generali sull'organizzazione dei workspace
Quando si progetta la strategia dei workspace, la prima cosa che vediamo spesso fare ai clienti è scegliere le opzioni organizzative a livello macro; tuttavia, ci sono molte decisioni a livello inferiore che sono altrettanto importanti! Abbiamo raccolto le più pertinenti di seguito.
Un semplice approccio a tre workspace
Sebbene dedichiamo la maggior parte di questo blog a come suddividere i workspace per la massima efficacia, esiste un'intera classe di clienti Databricks per i quali un singolo workspace unificato per ambiente è più che sufficiente! Infatti, questo è diventato sempre più pratico con l'ascesa di funzionalità come Repos, Unity Catalog, landing page basate su persona, ecc. In tali casi, raccomandiamo comunque la separazione dei workspace di Sviluppo, Staging e Produzione per scopi di validazione e QA. Questo crea un ambiente ideale per piccole imprese o team che valorizzano l'agilità rispetto alla complessità.
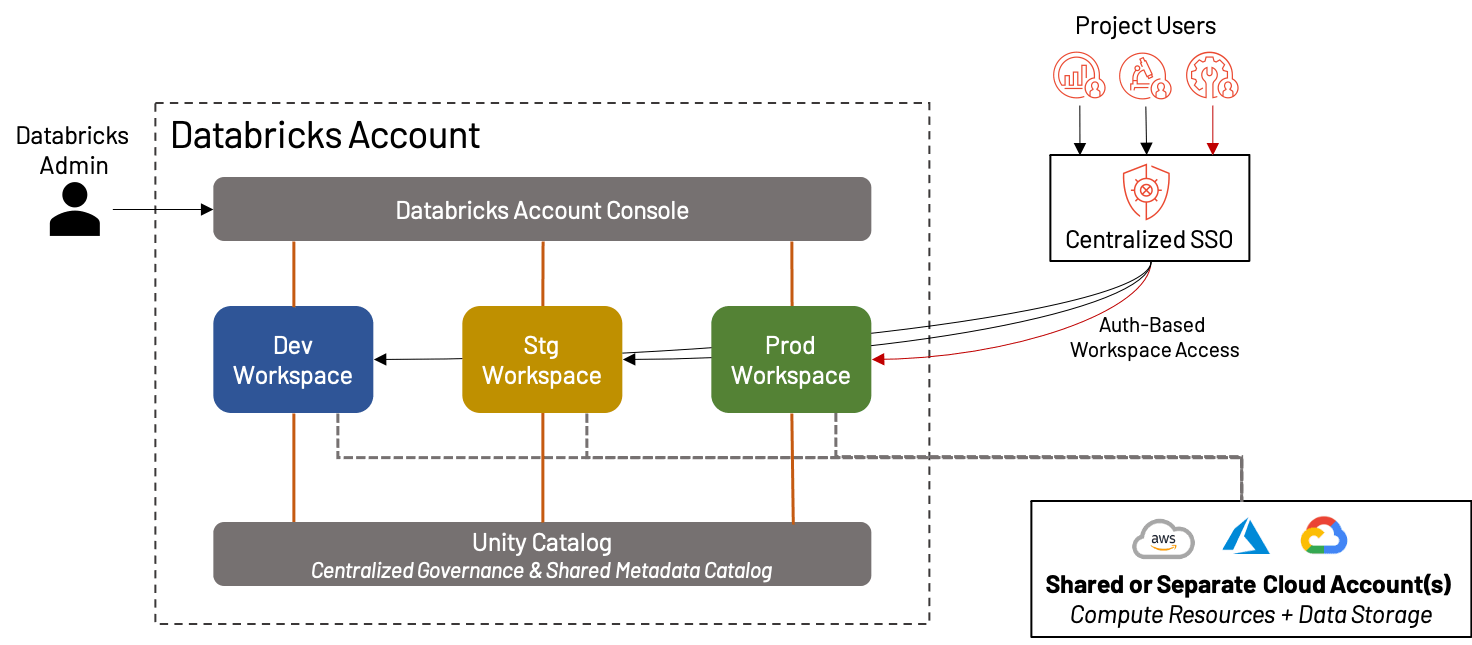
I vantaggi e gli svantaggi della creazione di un singolo set di workspace sono:
+ Non c'è preoccupazione di ingombrare il workspace internamente, mescolare asset o diluire i costi/l'utilizzo tra pi�ù progetti/team; tutto è nello stesso ambiente
+ La semplicità di organizzazione significa una ridotta gestione amministrativa
- Per le organizzazioni più grandi, un singolo workspace dev/stg/prd è insostenibile a causa dei limiti della piattaforma, del disordine, dell'incapacità di isolare i dati e delle preoccupazioni sulla governance
Se un singolo set di workspace sembra l'approccio giusto per te, le seguenti best practice ti aiuteranno a mantenere il tuo Lakehouse operativo senza intoppi:
- Definisci un processo standardizzato per il rilascio del codice tra i vari ambienti; poiché c'è un solo set di ambienti, questo può essere più semplice rispetto ad altri approcci. Sfrutta funzionalità come Repos e Secrets e strumenti esterni che promuovono buoni processi CI/CD per assicurarti che le tue transizioni avvengano in modo automatico e fluido.
- Stabilisci e rivedi regolarmente i gruppi dell'Identity Provider mappati agli asset Databricks; poiché questi gruppi sono il motore principale dell'autorizzazione utente in questa strategia, è fondamentale che siano accurati e che mappino le risorse dati e di calcolo sottostanti appropriate. Ad esempio, la maggior parte degli utenti probabilmente non necessita di accesso al workspace di produzione; solo una piccola manciata di ingegneri o amministratori potrebbe avere le autorizzazioni.
- Tieni d'occhio il tuo utilizzo e conosci i limiti delle risorse Databricks; se l'utilizzo del tuo workspace o il numero di utenti inizia a crescere, potresti dover considerare l'adozione di una strategia di organizzazione del workspace più complessa per evitare i limiti per workspace. Sfrutta il tagging delle risorse ove possibile per monitorare i costi e le metriche di utilizzo.
Utilizzo dei sandbox workspace
In qualsiasi delle strategie menzionate in questo articolo, un ambiente sandbox è una buona pratica per consentire agli utenti di incubare e sviluppare lavori meno formali, ma comunque potenzialmente preziosi. Fondamentalmente, questi ambienti sandbox devono bilanciare la libertà di esplorare dati reali con la protezione contro l'impatto involontario (o intenzionale) sui carichi di lavoro di produzione. Una best practice comune per tali workspace è ospitarli in un account cloud completamente separato; questo limita notevolmente il raggio d'azione degli utenti nel workspace. Allo stesso tempo, l'impostazione di semplici guardrail (come le Policy dei Cluster, limitando l'accesso ai dati a set di dati "di gioco" o puliti, e chiudendo la connettività in uscita ove possibile) significa che gli utenti possono avere una relativa libertà di fare (quasi) tutto ciò che vogliono senza bisogno di una supervisione costante dell'amministratore. Infine, la comunicazione interna è altrettanto importante; se gli utenti creano inconsapevolmente un'applicazione straordinaria nella Sandbox che attira migliaia di utenti, o si aspettano un supporto di livello di produzione per il loro lavoro in questo ambiente, quei risparmi amministrativi svaniranno rapidamente.
Le best practice per i sandbox workspace includono:
- Utilizza un account cloud separato che non contenga dati sensibili o di produzione.
- Imposta semplici guardrail in modo che gli utenti possano avere una relativa libertà sull'ambiente senza bisogno di supervisione amministrativa.
- Comunica chiaramente che l'ambiente sandbox è "self-service".
Isolamento dei dati e sensibilità
I dati sensibili stanno acquisendo sempre più importanza tra i nostri clienti in tutti i settori; dati che un tempo erano limitati ai fornitori di assistenza sanitaria o ai processori di carte di credito stanno ora diventando fonte per la comprensione dell'analisi dei pazienti o del sentiment dei clienti, l'analisi dei mercati emergenti, il posizionamento di nuovi prodotti e quasi tutto il resto che puoi immaginare. Questa ricchezza di dati comporta un alto rischio potenziale, con minacce sempre crescenti di violazioni dei dati; per questo motivo, mantenere i dati sensibili segregati e protetti è importante indipendentemente dalla strategia organizzativa scelta. Databricks fornisce diversi mezzi per proteggere i dati sensibili (come ACL e condivisione sicura), e combinato con gli strumenti del provider cloud, può rendere il Lakehouse che costruisci il più a basso rischio possibile. Alcune delle best practice relative all'isolamento dei dati e alla sensibilità includono:
- Comprendi le tue esigenze uniche di sicurezza dei dati; questo è il punto più importante. Ogni azienda ha dati diversi e i tuoi dati guideranno la tua governance.
- Applica policy e controlli sia a livello di storage che a livello di metastore. Le policy S3 e le ACL ADLS dovrebbero sempre essere applicate utilizzando il principio del minimo privilegio. Sfrutta Unity Catalog per applicare un ulteriore livello di controllo sull'accesso ai dati.
- Separa i tuoi dati sensibili da quelli non sensibili sia logicamente che fisicamente; molti clienti utilizzano account cloud completamente separati (e workspace Databricks) per dati sensibili e non sensibili.
DR e backup regionale
Il Disaster Recovery (DR) è un argomento ampio che è importante sia che tu utilizzi AWS, Azure o GCP; non copriremo tutto in questo blog, ma ci concentreremo piuttosto su come il DR e le considerazioni regionali influiscono sulla progettazione del workspace. In questo contesto, DR implica la creazione e la manutenzione di un workspace in una regione separata dal workspace di produzione standard.
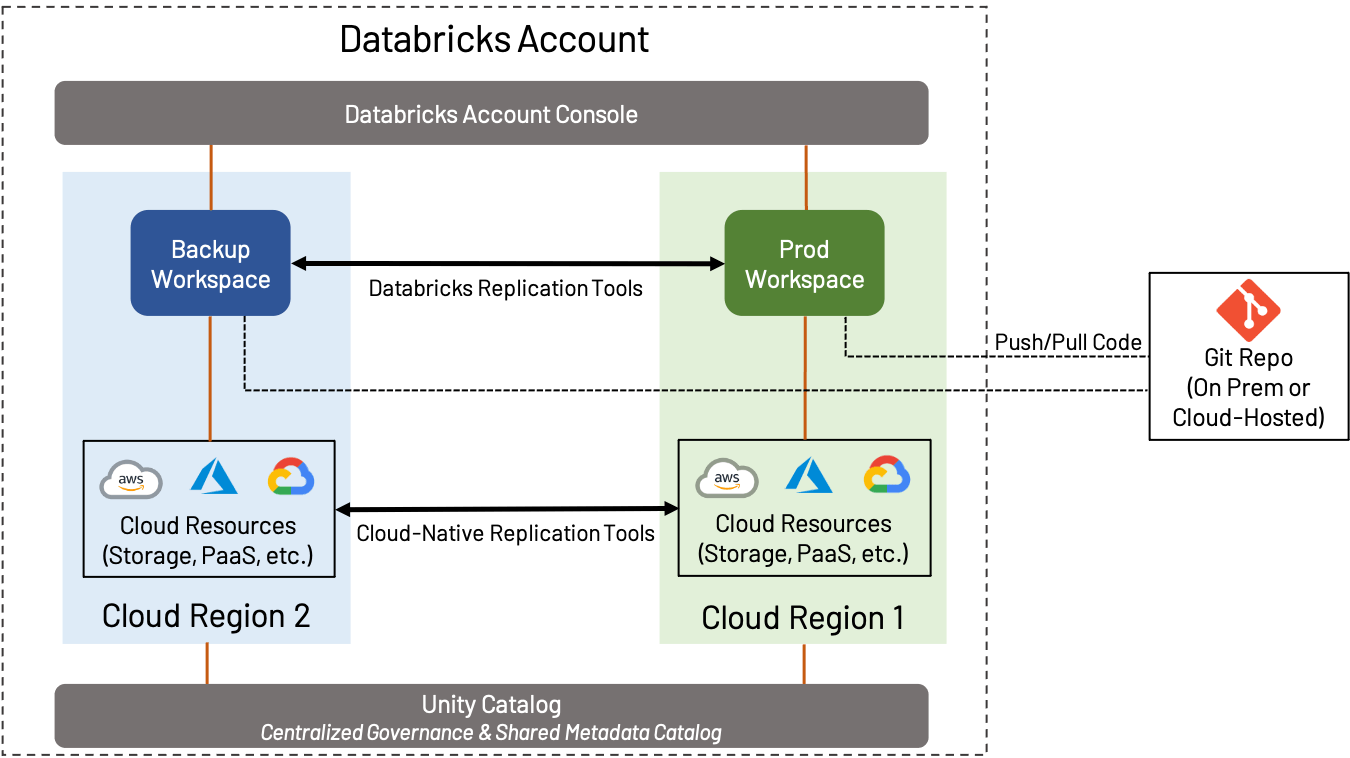
La strategia di DR può variare ampiamente a seconda delle esigenze del business. Ad esempio, alcuni clienti preferiscono mantenere una configurazione active-active, in cui tutte le risorse di un workspace vengono costantemente replicate in un workspace secondario; questo fornisce la massima ridondanza, ma implica anche complessità e costi (il trasferimento costante di dati tra regioni e l'esecuzione di repliche e deduplicazioni di oggetti è un processo complicato). D'altra parte, alcuni clienti preferiscono fare il minimo necessario per garantire la continuità operativa; un workspace secondario può contenere pochissimo fino a quando non si verifica il failover, o può essere sottoposto a backup solo occasionalmente. Determinare il giusto livello di failover è cruciale.
Indipendentemente dal livello di DR che scegli di implementare, raccomandiamo quanto segue:
- Archivia il codice in un repository Git a tua scelta, on-premise o nel cloud, e utilizza funzionalità come Repos per sincronizzarlo con Databricks ove possibile.
- Ove possibile, utilizza Delta Lake in combinazione con Deep Clone per replicare i dati; questo fornisce un modo semplice e open-source per eseguire il backup efficiente dei dati.
- Utilizza gli strumenti cloud-native forniti dal tuo provider cloud per eseguire il backup di elementi come dati non archiviati in Delta Lake, database esterni, configurazioni, ecc.
- Utilizza strumenti come Terraform per eseguire il backup di oggetti come notebook, job, segreti, cluster e altri oggetti del workspace.
Ricorda: Databricks è responsabile della manutenzione dell'infrastruttura regionale del workspace nel Control Plane, ma tu sei responsabile degli asset specifici del tuo workspace, nonché dell'infrastruttura cloud su cui si basano i tuoi job di produzione.
Isolamento per linea di business (LOB)
Ora ci addentriamo nell'organizzazione effettiva dei workspace in un contesto aziendale. L'isolamento dei progetti basato su LOB deriva dal tradizionale modo di guardare alle risorse IT incentrato sull'impresa – porta con sé anche molti punti di forza (e debolezza) tradizionali dell'allineamento incentrato su LOB. Come tale, per molte grandi aziende, questo approccio alla gestione del workspace risulterà naturale.
In una strategia di workspace basata su LOB, ogni unità funzionale di un'azienda riceverà un set di workspace; tradizionalmente, questo includerà workspace di sviluppo, staging e produzione, anche se abbiamo visto clienti con fino a 10 fasi intermedie, ognuna potenzialmente con il proprio workspace (sconsigliato)! Il codice viene scritto e testato in DEV, quindi promosso (tramite automazione CI/CD) a STG, e infine arriva in PRD, dove viene eseguito come job pianificato fino alla deprecazione. Il tipo di ambiente e la LOB indipendente sono i motivi principali per avviare un nuovo workspace in questo modello; farlo per ogni caso d'uso o data product potrebbe essere eccessivo.
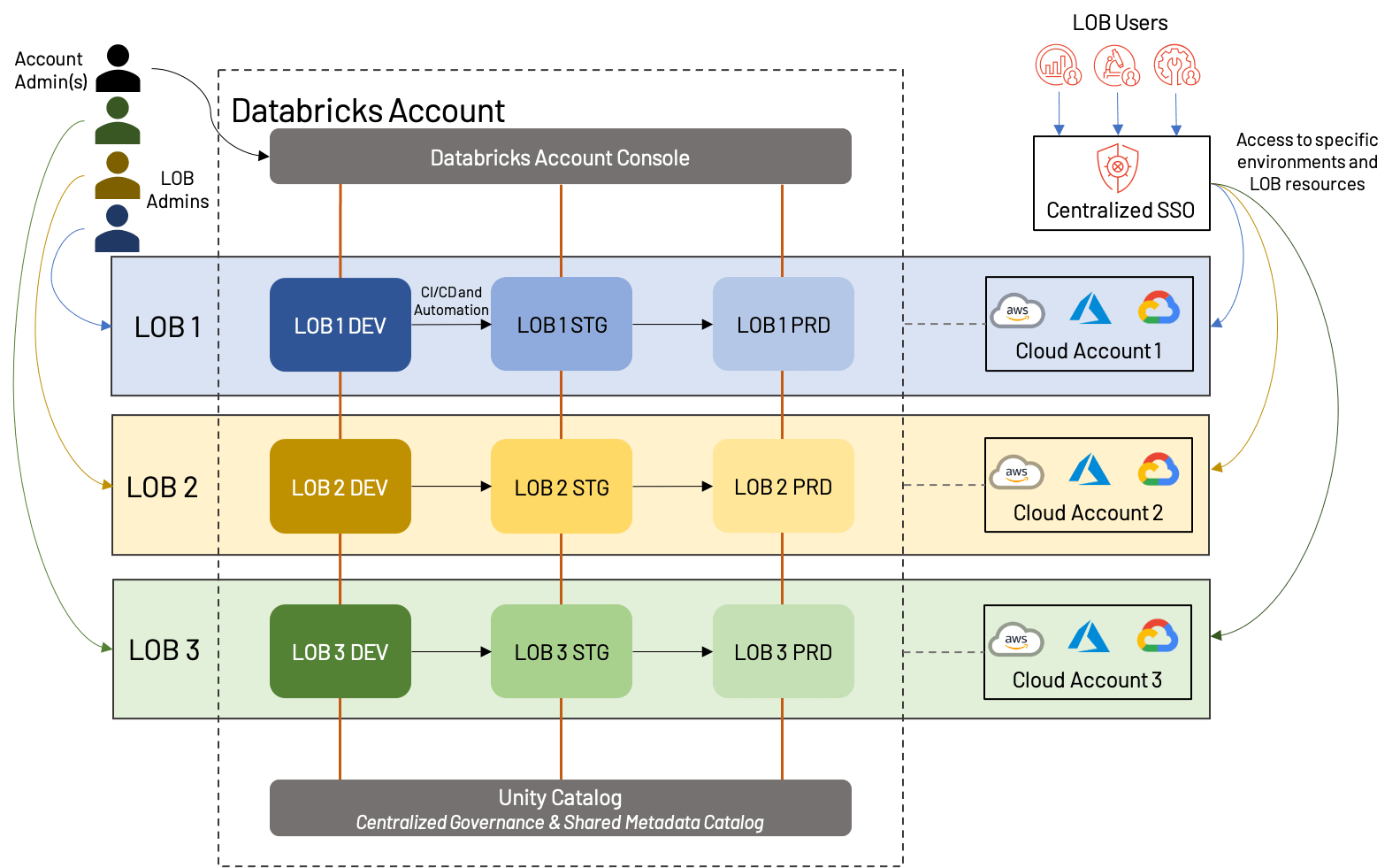
Il diagramma sopra mostra un modo potenziale in cui può essere strutturato un workspace basato su LOB; in questo caso, ogni LOB ha un account cloud separato con un workspace in ogni ambiente (dev/stg/prd) e ha anche un amministratore dedicato. È importante notare che tutti questi workspace rientrano nello stesso account Databricks e sfruttano lo stesso Unity Catalog. Alcune variazioni includerebbero la condivisione di account cloud (e potenzialmente risorse sottostanti come VPC e servizi cloud), l'utilizzo di un account cloud dev/stg/prd separato, o la creazione di metastore esterni separati per ogni LOB. Questi sono tutti approcci ragionevoli che dipendono fortemente dalle esigenze aziendali.
Nel complesso, ci sono una serie di vantaggi, così come alcuni svantaggi nell'approccio LOB:
+Gli asset per ogni LOB possono essere isolati, sia dal punto di vista del cloud che da quello del workspace; questo semplifica la reportistica/analisi dei costi e rende il workspace meno disordinato.
+Una chiara divisione di utenti e ruoli migliora la governance complessiva del Lakehouse e riduce il rischio generale.
+L'automazione della promozione tra ambienti crea un processo efficiente e a basso overhead.
-È necessaria una pianificazione preliminare per garantire che i processi cross-LOB siano standardizzati e che l'account Databricks complessivo non raggiunga i limiti della piattaforma.
-L'automazione e i processi amministrativi richiedono specialisti per l'impostazione e la manutenzione.
Come best practice, raccomandiamo quanto segue a coloro che costruiscono Lakehouse basati su LOB:
- Adottare un modello di accesso con privilegi minimi utilizzando un controllo degli accessi granulare per utenti e ambienti; in generale, pochissimi utenti dovrebbero avere accesso alla produzione e le interazioni con questo ambiente dovrebbero essere automatizzate e altamente controllate. Registrare questi utenti e gruppi nel proprio identity provider e sincronizzarli con il Lakehouse.
- Comprendere e pianificare i limiti sia del provider cloud che della piattaforma Databricks; questi includono, ad esempio, il numero di workspace, il rate limiting delle API su ADLS, il throttling sui flussi Kinesis, ecc.
- Utilizzare un metastore/catalogo standardizzato con controlli di accesso rigorosi ove possibile; ciò consente il riutilizzo degli asset senza compromettere l'isolamento. Unity Catalog consente controlli granulari su tabelle e asset del workspace, che includono oggetti come gli esperimenti di MLflow.
- Sfruttare la condivisione dei dati ove possibile per condividere in modo sicuro i dati tra LOB senza dover duplicare gli sforzi.
Isolamento dei prodotti dati
Cosa facciamo quando i LOB devono collaborare in modo interfunzionale, o quando un semplice modello dev/stg/prd non si adatta ai casi d'uso del nostro LOB? Possiamo abbandonare parte della formalità di una rigorosa struttura Lakehouse basata su LOB e adottare un approccio leggermente più moderno; chiamiamo questo isolamento del workspace per Data Product. Il concetto è che invece di isolare strettamente per LOB, isoliamo invece per progetti di primo livello, dando a ciascuno un ambiente di produzione. Mescoliamo anche ambienti di sviluppo condivisi per evitare la proliferazione dei workspace e semplificare il riutilizzo degli asset.
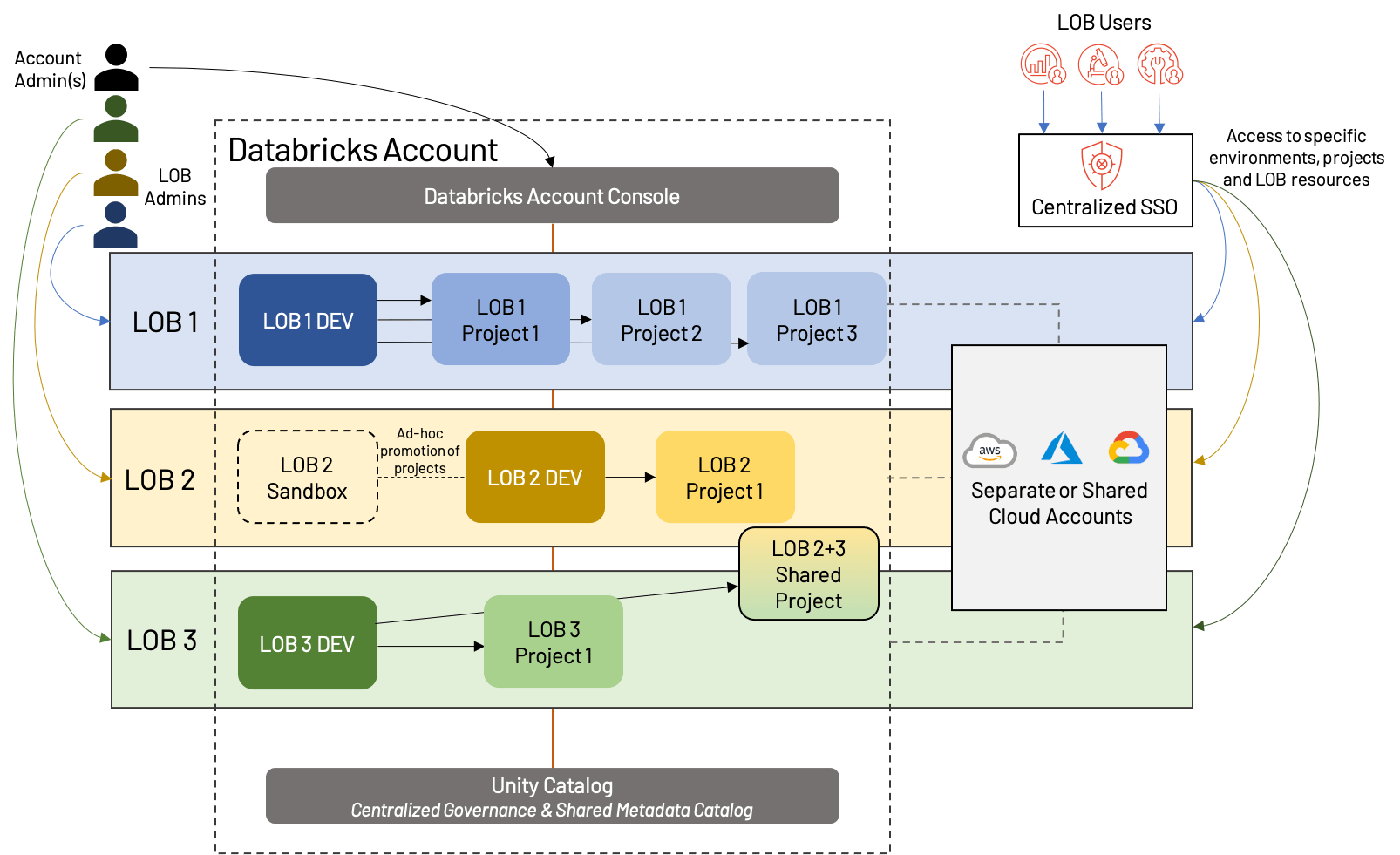
A prima vista, questo sembra simile all'isolamento basato su LOB sopra, ma ci sono alcune distinzioni importanti:
- Un workspace di sviluppo condiviso, con workspace separati per ogni progetto di primo livello (il che significa che ogni LOB può avere un numero diverso di workspace nel complesso)
- La presenza di workspace sandbox, specifici per un LOB, che offrono maggiore libertà e minore automazione rispetto ai workspace Dev tradizionali
- Condivisione di risorse e/o workspace; questo è possibile anche nelle architetture basate su LOB, ma è spesso complicato da una separazione più rigida
Questo approccio condivide molti dei punti di forza e di debolezza dell'isolamento basato su LOB, ma offre maggiore flessibilità ed enfatizza il valore dei progetti nel Lakehouse moderno. Sempre più spesso, vediamo questo diventare lo "standard d'oro" per l'organizzazione dei workspace, corrispondente al movimento della tecnologia da driver di costo a generatore di valore. Come sempre, le esigenze aziendali possono portare a lievi deviazioni da questa architettura di esempio, come dev/stg/prd dedicati per progetti particolarmente grandi, progetti cross-LOB, maggiore o minore segregazione delle risorse cloud, ecc. Indipendentemente dalla struttura esatta, suggeriamo le seguenti best practice:
- Condividere dati e risorse quando possibile; sebbene la segregazione dell'infrastruttura e dei workspace sia utile per la governance e il monitoraggio, la proliferazione delle risorse diventa rapidamente un onere. Un'analisi attenta in anticipo aiuterà a identificare le aree di riutilizzo.
- Anche quando non si condivide ampiamente tra i progetti, utilizzare un metastore condiviso come Unity Catalog e codebase condivisi (tramite, ad esempio, Repos) ove possibile.
- Utilizzare Terraform (o strumenti simili) per automatizzare il processo di creazione, gestione ed eliminazione di workspace e infrastrutture cloud.
- Fornire flessibilità agli utenti tramite ambienti sandbox, ma garantire che dispongano di adeguate protezioni per limitare le dimensioni dei cluster, l'accesso ai dati, ecc.
Riepilogo
Per sfruttare appieno tutti i vantaggi del Lakehouse e supportare la crescita e la gestibilità future, è necessario prestare attenzione alla pianificazione del layout del workspace. Altri artefatti associati da considerare durante questa progettazione includono un model registry centralizzato, codebase e catalogo per facilitare la collaborazione senza compromettere la sicurezza. Per riassumere alcune delle best practice evidenziate in questo articolo, i nostri punti chiave sono elencati di seguito:
Best Practice #1: Minimizzare il numero di account di primo livello (sia a livello di provider cloud che Databricks) ove possibile, e creare un workspace solo quando la separazione è necessaria per conformità, isolamento o vincoli geografici. Nel dubbio, mantieni la semplicità!
Best Practice #2: Decidere una strategia di isolamento che fornisca flessibilità a lungo termine senza complessità eccessiva. Sii realistico riguardo alle tue esigenze e implementa linee guida rigorose prima di iniziare a caricare workload sul tuo Lakehouse; in altre parole, misura due volte, taglia una volta!
Best Practice #3: Automatizza i tuoi processi cloud. Questo copre ogni aspetto della tua infrastruttura (molti dei quali saranno trattati nei prossimi blog!), inclusi SSO/SCIM, Infrastructure-as-Code con uno strumento come Terraform, pipeline CI/CD e Repos, backup cloud e monitoraggio (utilizzando sia strumenti cloud-native che di terze parti).
Best Practice #4: Considera l'istituzione di un team COE per la governance centrale di una strategia aziendale, dove gli aspetti ripetibili di una pipeline di dati e machine learning sono tematizzati e automatizzati in modo che diversi team di dati possano utilizzare capacità self-service con sufficienti protezioni. Il team COE è spesso un hub leggero ma critico per i team di dati e dovrebbe considerarsi un abilitatore, mantenendo documentazione, SOP, guide pratiche e FAQ per educare gli altri utenti.
Best Practice #5: Il Lakehouse fornisce un livello di governance che il Data Lake non offre; approfittane! Valuta le tue esigenze di conformità e governance come uno dei primi passi per stabilire il tuo Lakehouse e sfrutta le funzionalità fornite da Databricks per garantire che il rischio sia minimizzato. Ciò include la consegna di log di audit, HIPAA e PCI (ove applicabile), adeguati controlli di esfiltrazione, uso di ACL e controlli utente, e revisione regolare di tutto quanto sopra.
Forniremo altri blog di best practice per amministratori nel prossimo futuro, su argomenti che vanno dalla Data Governance alla Gestione Utenti. Nel frattempo, contatta il tuo team account Databricks per domande sulla gestione dei workspace, o se desideri saperne di più sulle best practice sulla Databricks Lakehouse Platform!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.