Valutazione del modello in MLflow
di Mark Zhang
Molti data scientist e ingegneri ML oggi utilizzano MLflow per gestire i loro modelli. MLflow è una piattaforma open-source che consente agli utenti di governare tutti gli aspetti del ciclo di vita ML, inclusi, ma non solo, sperimentazione, riproducibilità, deployment e registro dei modelli. Un passaggio critico durante lo sviluppo di modelli ML è la valutazione delle loro prestazioni su nuovi set di dati.
Motivazione
Perché Valutiamo i Modelli?
La valutazione del modello è una parte integrante del ciclo di vita ML. Consente ai data scientist di misurare, interpretare e spiegare le prestazioni dei loro modelli. Accelera il tempo di sviluppo del modello fornendo informazioni su come e perché i modelli si comportano nel modo in cui si comportano. Soprattutto con l'aumentare della complessità dei modelli ML, essere in grado di osservare e comprendere rapidamente le prestazioni dei modelli ML è essenziale in un percorso di sviluppo ML di successo.
Stato della Valutazione del Modello in MLflow
Attualmente, molti utenti valutano le prestazioni del loro modello MLflow del flavor del modello python_function (pyfunc) tramite l'API mlflow.evaluate, che supporta la valutazione di modelli di classificazione e regressione. Calcola e registra un set di metriche di performance specifiche per attività integrate, grafici di performance del modello e spiegazioni del modello al server MLflow Tracking.
Per valutare i modelli MLflow rispetto a metriche personalizzate non incluse nel set di metriche di valutazione integrate, gli utenti dovrebbero definire un plugin di valutazione del modello personalizzato. Ciò comporterebbe la creazione di una classe di valutazione personalizzata che implementa l'interfaccia ModelEvaluator, quindi la registrazione di un punto di ingresso per il valutatore come parte di un plugin MLflow. Questa rigidità e complessità potrebbero essere proibitive per gli utenti.
Secondo un sondaggio interno sui clienti, il 75% degli intervistati afferma di utilizzare frequentemente o sempre metriche specializzate e focalizzate sul business oltre a quelle di base come accuratezza e perdita. I data scientist utilizzano spesso queste metriche personalizzate poiché sono più descrittive degli obiettivi di business (ad es. tasso di conversione) e contengono euristiche aggiuntive non catturate dalla previsione del modello stessa.
In questo blog, introduciamo un modo semplice e conveniente per valutare i modelli MLflow su metriche personalizzate definite dall'utente. Con questa funzionalità, un data scientist può facilmente incorporare questa logica nella fase di valutazione del modello e determinare rapidamente il modello con le migliori prestazioni senza ulteriori analisi downstream.
*Nota: In MLflow 2.4, mlflow.evaluate è stato ampliato per supportare modelli LLM di testo, riassunto di testo e domande e risposte
Utilizzo
Metriche Integrate
MLflow integra un set di metriche di performance e di spiegabilità del modello comunemente utilizzate sia per modelli classificatori che regressori. Valutare i modelli su queste metriche è semplice. Tutto ciò che serve è creare un set di dati di valutazione contenente i dati di test e i target e chiamare mlflow.evaluate.
A seconda del tipo di modello, vengono calcolate metriche diverse. Fare riferimento alla sezione Comportamento del Valutatore Predefinito nella documentazione API di mlflow.evaluate per le informazioni più aggiornate relative alle metriche integrate.
Esempio
Di seguito è riportato un semplice esempio di come un modello MLflow classificatore viene valutato con metriche integrate.
Innanzitutto, importare le librerie necessarie
Quindi, dividiamo il set di dati, addestriamo il modello e creiamo il nostro set di dati di valutazione
Infine, avviamo una run MLflow e chiamiamo mlflow.evaluate
Possiamo trovare le metriche e gli artefatti registrati nell'interfaccia utente di MLflow:
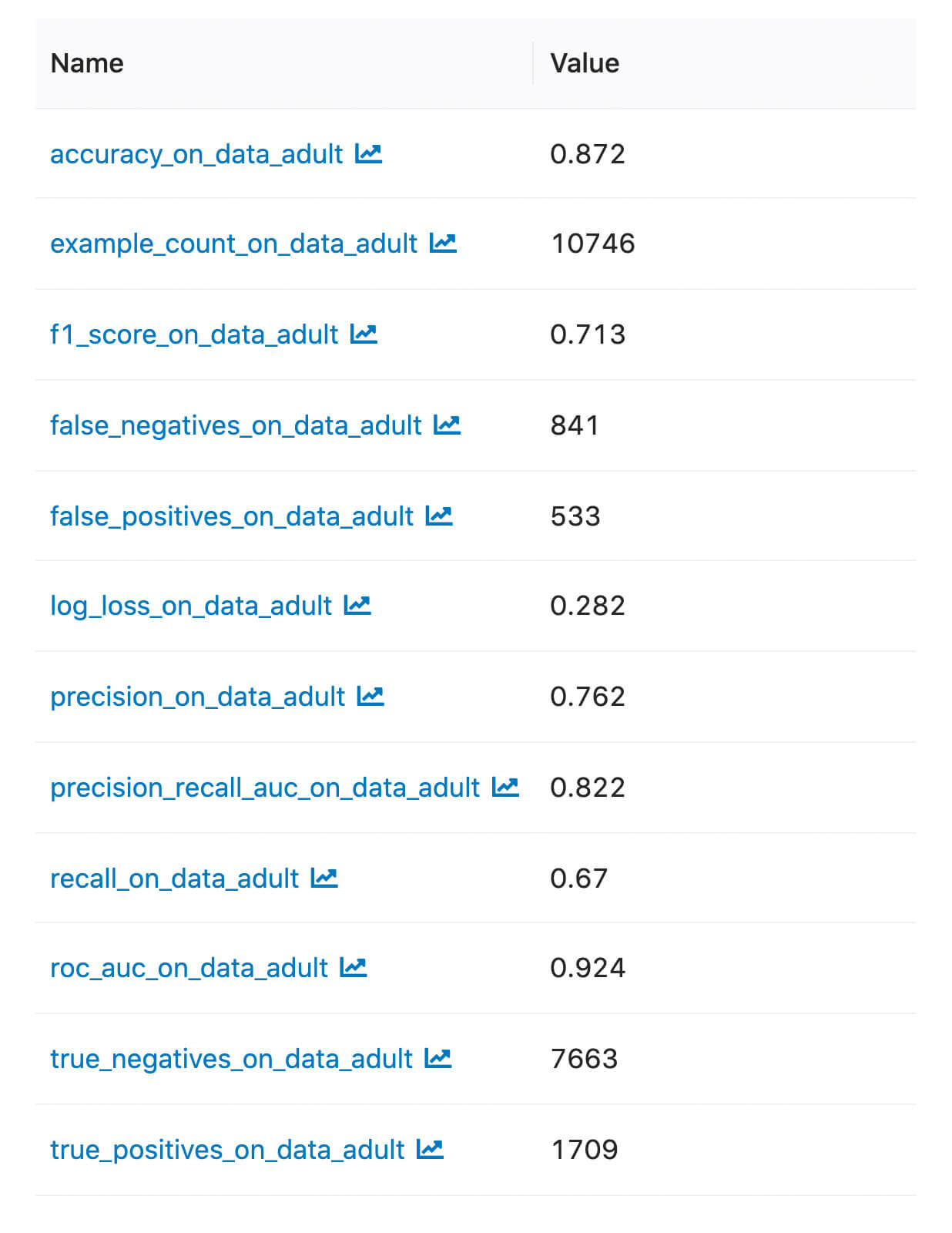
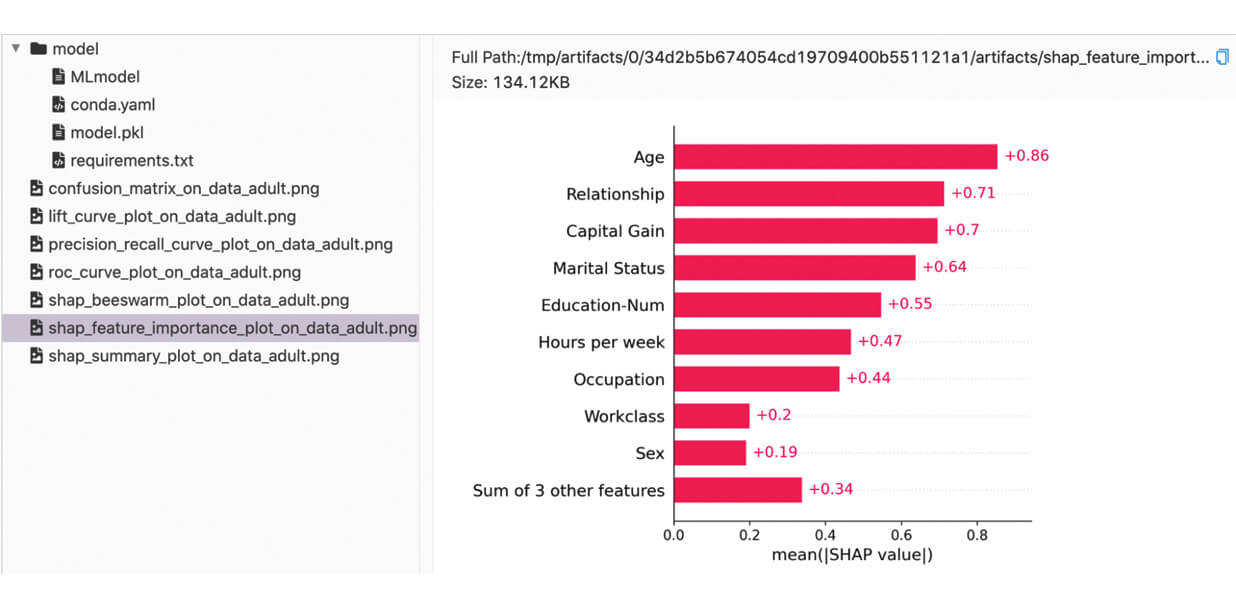
Metriche Personalizzate
Per valutare un modello rispetto a metriche personalizzate, passiamo semplicemente un elenco di funzioni di metriche personalizzate all'API mlflow.evaluate.
Requisiti di Definizione della Funzione
Le funzioni di metriche personalizzate dovrebbero accettare due parametri obbligatori e uno opzionale nell'ordine seguente:
eval_df: un DataFrame Pandas o Spark contenente una colonnapredictione una colonnatarget.Ad esempio, se l'output del modello è un vettore di tre numeri, il DataFrame
eval_dfapparirebbe così: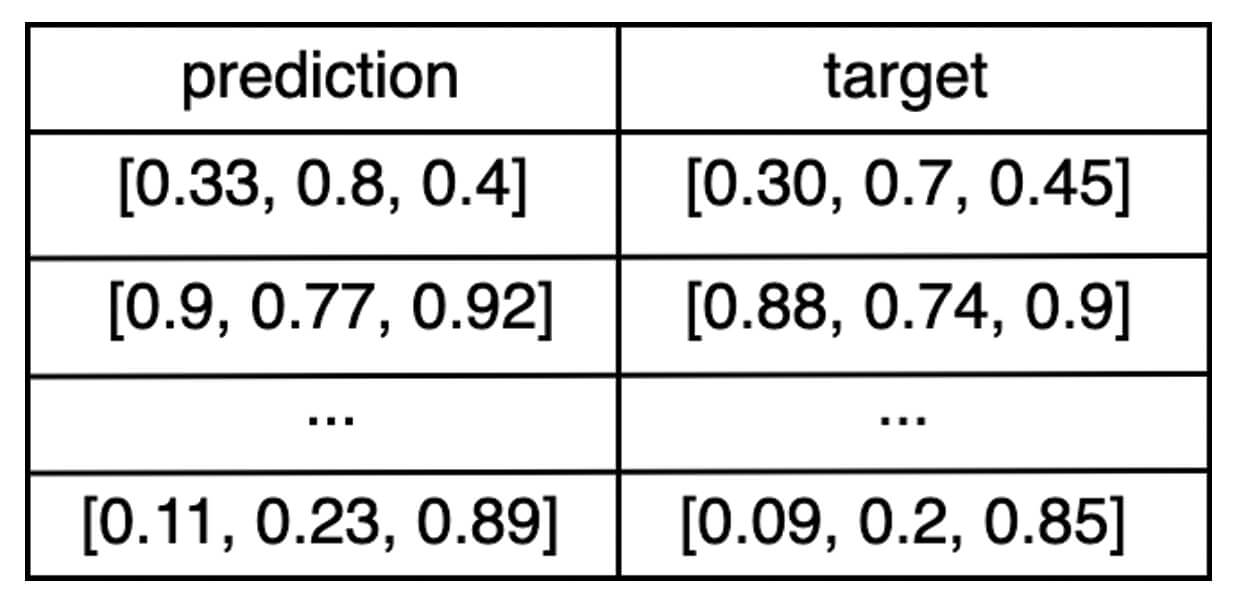
builtin_metrics: un dizionario contenente le metriche integrateAd esempio, per un modello regressore,
builtin_metricsapparirebbe così:- (Opzionale)
artifacts_dir: percorso di una directory temporanea che può essere utilizzata dalla funzione di metrica personalizzata per archiviare temporaneamente gli artefatti prodotti prima della registrazione in MLflow.Ad esempio, notare che questo apparirà diverso a seconda della configurazione specifica dell'ambiente. Ad esempio, su MacOS potrebbe apparire così:
Se gli artefatti dei file sono archiviati altrove rispetto a
artifacts_dir, assicurarsi che persistano fino al termine dell'esecuzione dimlflow.evaluate.
Requisiti del Valore di Ritorno
La funzione dovrebbe restituire un dizionario che rappresenta le metriche prodotte e può opzionalmente restituire un secondo dizionario che rappresenta gli artefatti prodotti. Per entrambi i dizionari, la chiave per ogni voce rappresenta il nome della metrica o dell'artefatto corrispondente.
Mentre ogni metrica deve essere uno scalare, ci sono vari modi per definire gli artefatti:
- Il percorso di un file artefatto
- La rappresentazione stringa di un oggetto JSON
- Un DataFrame pandas
- Un array numpy
- Una figura matplotlib
- Altri oggetti verranno tentati di essere serializzati con il protocollo predefinito
Consulta la documentazione di mlflow.evaluate per dettagli più approfonditi.
Esempio
Esaminiamo un esempio concreto che utilizza metriche personalizzate. Per questo, creeremo un modello giocattolo dal dataset California Housing.
Quindi, impostiamo il nostro dataset e modello
Ecco la parte entusiasmante: definire la nostra funzione di metriche personalizzate, e un artefatto personalizzato!!
Infine, per collegare tutto questo, avvieremo un'esecuzione MLflow e chiameremo mlflow.evaluate:
Le metriche e gli artefatti personalizzati registrati si trovano accanto alle metriche e agli artefatti predefiniti. Le regioni evidenziate in rosso mostrano le metriche e gli artefatti personalizzati registrati nella pagina dell'esecuzione.
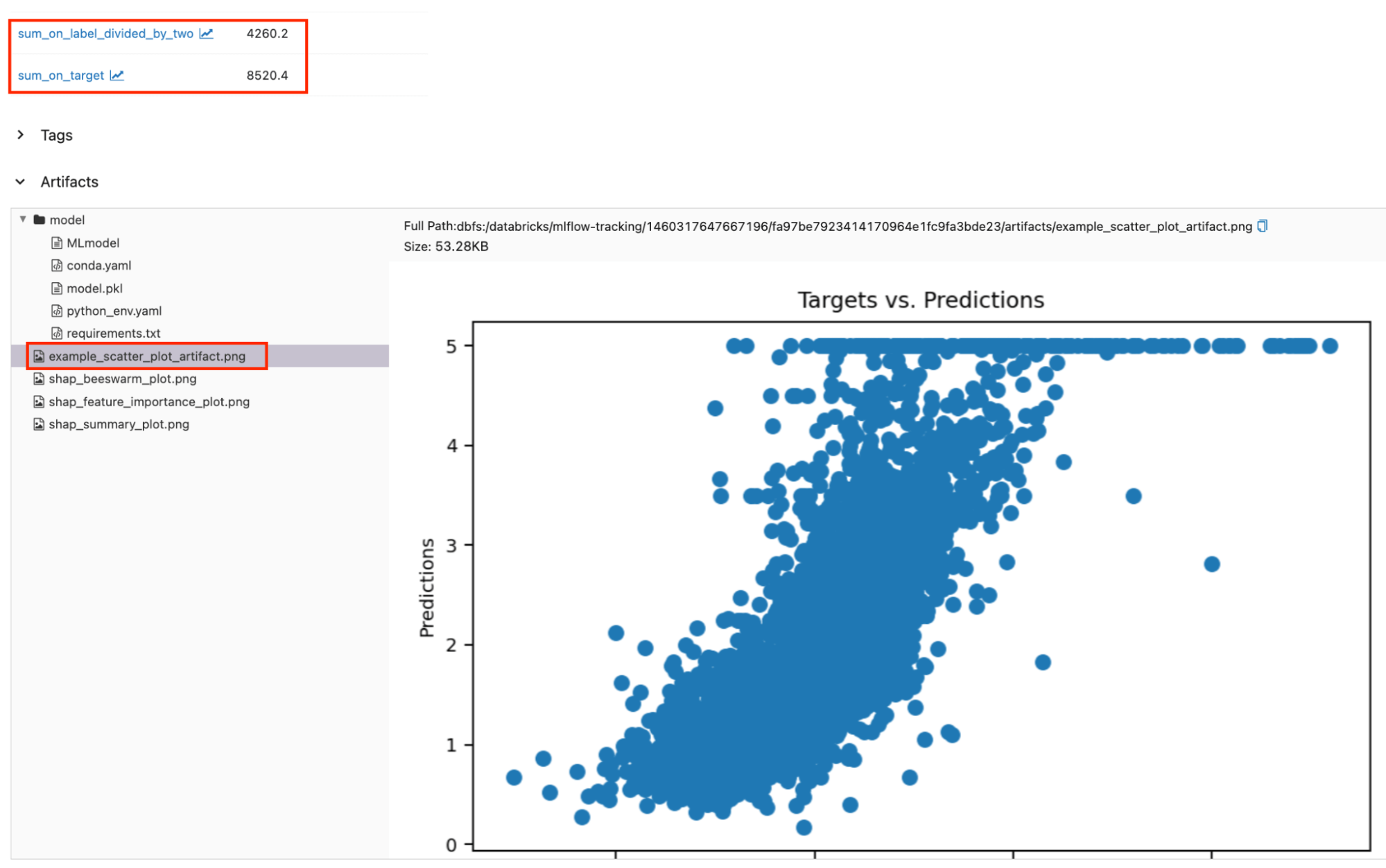
Accesso ai Risultati della Valutazione in Modo Programmatico
Finora, abbiamo esplorato i risultati della valutazione sia per le metriche predefinite che per quelle personalizzate nell'interfaccia utente di MLflow. Tuttavia, possiamo accedervi anche in modo programmatico tramite l'oggetto EvaluationResult restituito da mlflow.evaluate. Continuiamo il nostro esempio di metriche personalizzate sopra e vediamo come possiamo accedere ai suoi risultati di valutazione in modo programmatico. (Assumendo che result sia la nostra istanza di EvaluationResult d'ora in poi).
Possiamo accedere all'insieme delle metriche calcolate tramite il dizionario result.metrics contenente sia il nome che i valori scalari delle metriche. Il contenuto di result.metrics dovrebbe apparire così:
Allo stesso modo, l'insieme degli artefatti è accessibile tramite il dizionario result.artifacts. I valori di ogni voce sono un oggetto EvaluationArtifact. result.artifacts dovrebbe apparire così:
Notebook di Esempio
Dietro le Quinte
Il diagramma seguente illustra come funziona tutto questo dietro le quinte:
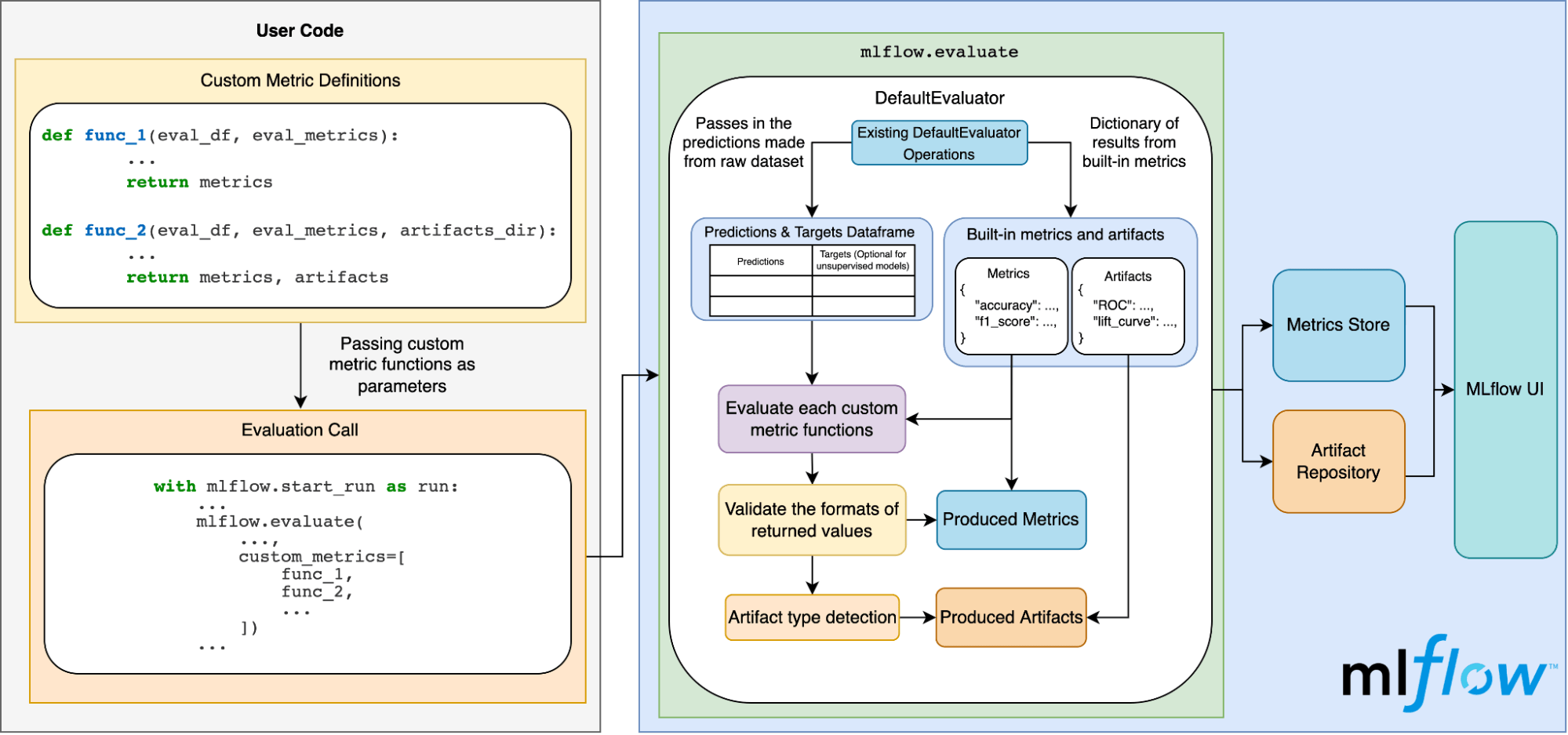
Conclusione
In questo post del blog, abbiamo trattato:
- L'importanza della valutazione del modello e di ciò che è attualmente supportato in MLflow.
- Perché è importante avere un modo semplice per gli utenti MLflow di incorporare metriche personalizzate nei loro modelli MLflow.
- Come valutare i modelli con metriche predefinite.
- Come valutare i modelli con metriche personalizzate.
- Come MLflow gestisce la valutazione del modello dietro le quinte.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.