Semplificare la Change Data Capture con Databricks Delta Live Tables
Questa guida illustrerà come sfruttare il Change Data Capture (CDC) nelle pipeline di Delta Live Tables per identificare nuovi record e acquisire le modifiche apportate al set di dati nel tuo data lake. Le pipeline di Delta Live Tables ti consentono di sviluppare pipeline di dati scalabili, affidabili e a bassa latenza, eseguendo al contempo il Change Data Capture nel tuo data lake con risorse computazionali minime richieste e gestione fluida dei dati fuori ordine.
Contesto sul Change Data Capture
Il Change Data Capture (CDC) è un processo che identifica e acquisisce modifiche incrementali (eliminazioni, inserimenti e aggiornamenti di dati) nei database, come il tracciamento dello stato di clienti, ordini o prodotti per applicazioni dati quasi in tempo reale. Il CDC fornisce l'evoluzione dei dati in tempo reale elaborando i dati in modo incrementale continuo man mano che si verificano nuovi eventi.
Dato che oltre l'80% delle organizzazioni prevede di implementare strategie multi-cloud entro il 2025, scegliere l'approccio giusto per la tua azienda che consenta la centralizzazione fluida in tempo reale di tutte le modifiche dei dati nella tua pipeline ETL attraverso più ambienti è fondamentale.
Catturando gli eventi CDC, gli utenti Databricks possono rimaterializzare la tabella di origine come Tabella Delta nel Lakehouse ed eseguire le loro analisi su di essa, potendo combinare i dati con sistemi esterni. Il comando MERGE INTO in Delta Lake su Databricks consente ai clienti di inserire e eliminare in modo efficiente record nei loro data lake – puoi consultare la nostra precedente analisi approfondita sull'argomento qui. Questo è un caso d'uso comune che osserviamo molti clienti Databricks stanno sfruttando Delta Lakes per eseguire, e mantenere i loro data lake aggiornati con dati aziendali in tempo reale.
Mentre Delta Lake fornisce una soluzione completa per la sincronizzazione CDC in tempo reale in un data lake, siamo ora entusiasti di annunciare la funzionalità Change Data Capture in Delta Live Tables che rende la tua architettura ancora più semplice, efficiente e scalabile. DLT consente agli utenti di ingerire dati CDC in modo fluido utilizzando SQL e Python.
Le precedenti soluzioni CDC con tabelle delta utilizzavano l'operazione MERGE INTO che richiede l'ordinamento manuale dei dati per evitare errori quando più righe del set di dati di origine corrispondono durante il tentativo di aggiornare le stesse righe della tabella Delta di destinazione. Per gestire i dati fuori ordine, era necessario un passaggio aggiuntivo per pre-elaborare la tabella di origine utilizzando un'implementazione foreachBatch per eliminare la possibilità di corrispondenze multiple, conservando solo l'ultima modifica per ogni chiave (Vedi l'esempio di change data capture). La nuova operazione APPLY CHANGES INTO nelle pipeline DLT gestisce automaticamente e in modo fluido i dati fuori ordine senza alcuna necessità di intervento manuale da parte dell'ingegneria dei dati.
CDC con Databricks Delta Live Tables
In questo post, dimostreremo come utilizzare il comando APPLY CHANGES INTO nelle pipeline di Delta Live Tables per un caso d'uso CDC comune in cui i dati CDC provengono da un sistema esterno. Sono disponibili una varietà di strumenti CDC come Debezium, Fivetran, Qlik Replicate, Talend e StreamSets. Sebbene le implementazioni specifiche differiscano, questi strumenti acquisiscono e registrano generalmente la cronologia delle modifiche dei dati nei log; le applicazioni downstream consumano questi log CDC. Nel nostro esempio, i dati vengono caricati nello storage di oggetti cloud da uno strumento CDC come Debezium, Fivetran, ecc.
Abbiamo dati da vari strumenti CDC che arrivano in uno storage di oggetti cloud o in una coda di messaggi come Apache Kafka. Tipicamente vediamo il CDC utilizzato nell'ingestione in quella che chiamiamo architettura a medaglione. Un'architettura a medaglione è un modello di progettazione dati utilizzato per organizzare logicamente i dati in un Lakehouse, con l'obiettivo di migliorare in modo incrementale e progressivo la struttura e la qualità dei dati man mano che fluiscono attraverso ogni livello dell'architettura. Delta Live Tables ti consente di applicare in modo fluido le modifiche dai feed CDC alle tabelle nel tuo Lakehouse; combinare questa funzionalità con l'architettura a medaglione consente alle modifiche incrementali di fluire facilmente attraverso i carichi di lavoro analitici su larga scala. L'utilizzo del CDC insieme all'architettura a medaglione offre molteplici vantaggi agli utenti poiché solo i dati modificati o aggiunti devono essere elaborati. Pertanto, consente agli utenti di mantenere in modo conveniente le tabelle gold aggiornate con i dati aziendali più recenti.
NOTA: L'esempio qui si applica sia alle versioni SQL che Python del CDC e anche a un modo specifico di utilizzare le operazioni, per valutare le variazioni, si prega di consultare la documentazione ufficiale qui.
Prerequisiti
Per ottenere il massimo da questa guida, dovresti avere una conoscenza di base di:
- SQL o Python
- Delta Live Tables
- Sviluppo di pipeline ETL e/o lavoro con sistemi Big Data
- Notebook interattivi e cluster Databricks
- Devi avere accesso a un Workspace Databricks con i permessi per creare nuovi cluster, eseguire job e salvare dati in una posizione su storage di oggetti cloud esterno o DBFS.
- Per la pipeline che stiamo creando in questo post, è necessario selezionare l'edizione del prodotto "Advanced" che supporta l'applicazione dei vincoli di qualità dei dati.
Il Dataset
Qui stiamo consumando dati CDC dall'aspetto realistico da un database esterno. In questa pipeline, utilizzeremo la libreria Faker per generare il set di dati che uno strumento CDC come Debezium può produrre e portare nello storage cloud per l'ingestione iniziale in Databricks. Utilizzando Auto Loader carichiamo incrementalmente i messaggi dallo storage di oggetti cloud, e li memorizziamo nella tabella Bronze poiché memorizza i messaggi grezzi. Le tabelle Bronze sono destinate all'ingestione dei dati che consentono un rapido accesso a una singola fonte di verità. Successivamente eseguiamo APPLY CHANGES INTO dal livello Bronze pulito per propagare gli aggiornamenti a valle alla Tabella Silver. Man mano che i dati fluiscono verso le tabelle Silver, generalmente diventano più raffinati e ottimizzati ("just-enough") per fornire a un'azienda una visione di tutte le sue entità aziendali chiave. Vedi il diagramma sottostante.
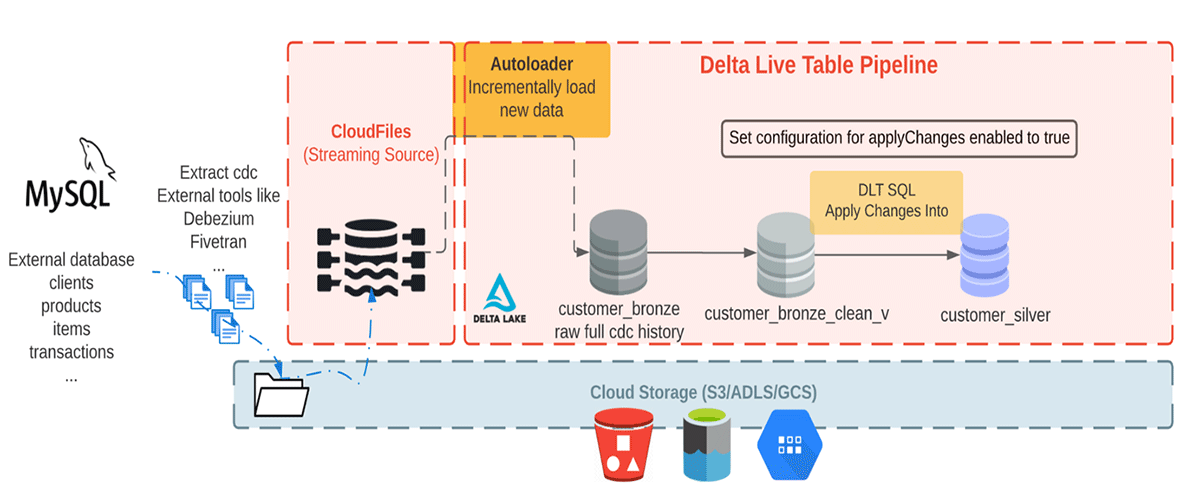
Questo post si concentra su un semplice esempio che richiede un messaggio JSON con quattro campi: nome del cliente, email, indirizzo e ID, insieme ai due campi: operation (che memorizza il codice dell'operazione (DELETE, APPEND, UPDATE, CREATE) e operation_date (che memorizza la data e l'ora in cui il record è arrivato per ogni azione di operazione) per descrivere i dati modificati.
Per generare un set di dati di esempio con i campi sopra, stiamo utilizzando un pacchetto Python che genera dati fittizi, Faker. Puoi trovare il notebook relativo a questa sezione di generazione dati qui. In questo notebook forniamo il nome e la posizione di archiviazione per scrivere i dati generati lì. Stiamo utilizzando la funzionalità DBFS di Databricks, consulta la documentazione DBFS per saperne di più sul suo funzionamento. Quindi, utilizziamo una User-Defined-Function PySpark per generare il set di dati sintetico per ogni campo e scriviamo i dati nella posizione di archiviazione definita, a cui faremo riferimento in altri notebook per accedere al set di dati sintetico.
Ingestione del dataset grezzo utilizzando Auto Loader
Secondo il paradigma dell'architettura Medallion, il livello bronze detiene la qualità dei dati più grezza. A questo stadio possiamo leggere incrementalmente nuovi dati utilizzando Autoloader da una posizione nello storage cloud. Qui stiamo aggiungendo il percorso al nostro set di dati generato alla sezione di configurazione nelle impostazioni della pipeline, il che ci consente di caricare il percorso di origine come variabile. Quindi ora la nostra configurazione nelle impostazioni della pipeline appare così:
Quindi carichiamo questa proprietà di configurazione nei nostri notebook.
Diamo un'occhiata alla tabella Bronze che ingeriremo, a. In SQL, e b. Utilizzando Python
a. SQL
b. Python
Le istruzioni precedenti utilizzano Auto Loader per creare una tabella live in streaming chiamata customer_bronze da file JSON. Quando si utilizza Autoloader in Delta Live Tables, non è necessario fornire alcuna posizione per lo schema o il checkpoint, poiché tali posizioni saranno gestite automaticamente dalla pipeline DLT.
Auto Loader fornisce una sorgente Structured Streaming chiamata cloud_files in SQL e cloudFiles in Python, che accetta come parametri un percorso di archiviazione cloud e un formato.
Per ridurre i costi di calcolo, si consiglia di eseguire la pipeline DLT in modalità Triggered come micro-batch, supponendo che non si abbiano requisiti di latenza molto bassi.
Expectations and high-quality data
Nel passaggio successivo per creare un set di dati di alta qualità, diversificato e accessibile, imponiamo criteri di aspettativa di controllo qualità utilizzando Constraints. Attualmente, un vincolo può essere di tipo retain, drop o fail. Per maggiori dettagli vedere qui. Tutti i vincoli vengono registrati per consentire un monitoraggio della qualità semplificato.
a. SQL
b. Python
Using APPLY CHANGES INTO statement to propagate changes to downstream target table
Prima di eseguire la query Apply Changes Into, dobbiamo assicurarci che esista una tabella di destinazione in streaming che conterrà i dati più aggiornati. Se non esiste, dobbiamo crearne una. Le celle sottostanti sono esempi di creazione di una tabella di destinazione in streaming. Si noti che al momento della pubblicazione di questo blog, l'istruzione di creazione della tabella di destinazione in streaming è richiesta insieme alla query Apply Changes Into, ed entrambe devono essere presenti nella pipeline, altrimenti la query di creazione della tabella fallirà.
a. SQL
b. Python
Ora che abbiamo una tabella di destinazione in streaming, possiamo propagare le modifiche alla tabella di destinazione downstream utilizzando la query Apply Changes Into. Mentre il feed CDC include eventi INSERT, UPDATE e DELETE, il comportamento predefinito di DLT è quello di applicare eventi INSERT e UPDATE da qualsiasi record nel set di dati di origine che corrisponde alle chiavi primarie, e sequenziato da un campo che identifica l'ordine degli eventi. Più specificamente, aggiorna qualsiasi riga nella tabella di destinazione esistente che corrisponde alla chiave/e primaria o inserisce una nuova riga quando un record corrispondente non esiste nella tabella di destinazione in streaming. Possiamo usare APPLY AS DELETE WHEN in SQL, o il suo equivalente apply_as_deletes in Python per gestire gli eventi DELETE.
In questo esempio abbiamo usato "id" come chiave primaria, che identifica univocamente i clienti e consente agli eventi CDC di applicarsi a quei record cliente identificati nella tabella di destinazione in streaming. Poiché "operation_date" mantiene l'ordine logico degli eventi CDC nel set di dati di origine, usiamo "SEQUENCE BY operation_date" in SQL, o il suo equivalente "sequence_by = col("operation_date")" in Python per gestire gli eventi di modifica che arrivano fuori ordine. Tieni presente che il valore del campo che utilizziamo con SEQUENCE BY (o sequence_by) dovrebbe essere univoco tra tutti gli aggiornamenti della stessa chiave. Nella maggior parte dei casi, la colonna di sequenza sarà una colonna con informazioni timestamp.
Infine abbiamo usato "COLUMNS * EXCEPT (operation, operation_date, _rescued_data)" in SQL, o il suo equivalente "except_column_list"= ["operation", "operation_date", "_rescued_data"] in Python per escludere tre colonne di "operation", "operation_date", "_rescued_data" dalla tabella di destinazione in streaming. Per impostazione predefinita, tutte le colonne sono incluse nella tabella di destinazione in streaming, quando non specifichiamo la clausola "COLUMNS".
a. SQL
b. Python
Per consultare l'elenco completo delle clausole disponibili, vedere qui.
Si noti che, al momento della pubblicazione di questo blog, una tabella che legge dalla destinazione di una query APPLY CHANGES INTO o dalla funzione apply_changes deve essere una tabella live e non può essere una tabella live in streaming.
Un notebook SQL e Python è disponibile come riferimento per questa sezione. Ora che abbiamo tutte le celle pronte, creiamo una Pipeline per ingerire dati dallo storage oggetti cloud. Apri Jobs in una nuova scheda o finestra nel tuo workspace e seleziona "Delta Live Tables".
La pipeline associata a questo blog ha le seguenti impostazioni della pipeline DLT:
- Seleziona "Create Pipeline" per creare una nuova pipeline
- Specifica un nome come "Retail CDC Pipeline"
- Specifica i Notebook Paths che hai già creato in precedenza, uno per il set di dati generato utilizzando il pacchetto Faker e un altro percorso per l'ingestione dei dati generati in DLT. Il secondo percorso del notebook può fare riferimento al notebook scritto in SQL o Python, a seconda della lingua scelta.
- Per accedere ai dati generati nel primo notebook, aggiungi il percorso del dataset nella configurazione. Qui abbiamo archiviato i dati in "/tmp/demo/cdc_raw/customers", quindi impostiamo "source" su "/tmp/demo/cdc_raw/" per fare riferimento a "source/customers" nel nostro secondo notebook.
- Specifica il Target (che è facoltativo e si riferisce al database di destinazione), dove puoi interrogare le tabelle risultanti dalla tua pipeline.
- Specifica la Posizione di Archiviazione nel tuo object storage (che è facoltativo), per accedere ai tuoi dataset prodotti da DLT e ai log dei metadati per la tua pipeline.
- Imposta la Modalità Pipeline su Triggered. In modalità Triggered, la pipeline DLT consumerà tutti i nuovi dati nella sorgente contemporaneamente e, una volta completata l'elaborazione, terminerà automaticamente la risorsa di calcolo. Puoi passare dalla modalità Triggered alla modalità Continuous modificando le impostazioni della tua pipeline. Impostare "continuous": false nel JSON equivale a impostare la pipeline in modalità Triggered.
- Per questo carico di lavoro puoi disabilitare l'autoscaling in Autopilot Options e utilizzare un solo worker cluster. Per i carichi di lavoro di produzione, consigliamo di abilitare l'autoscaling e impostare il numero massimo di worker necessari per la dimensione del cluster.
- Seleziona "Start"
- La tua pipeline è creata e in esecuzione ora!
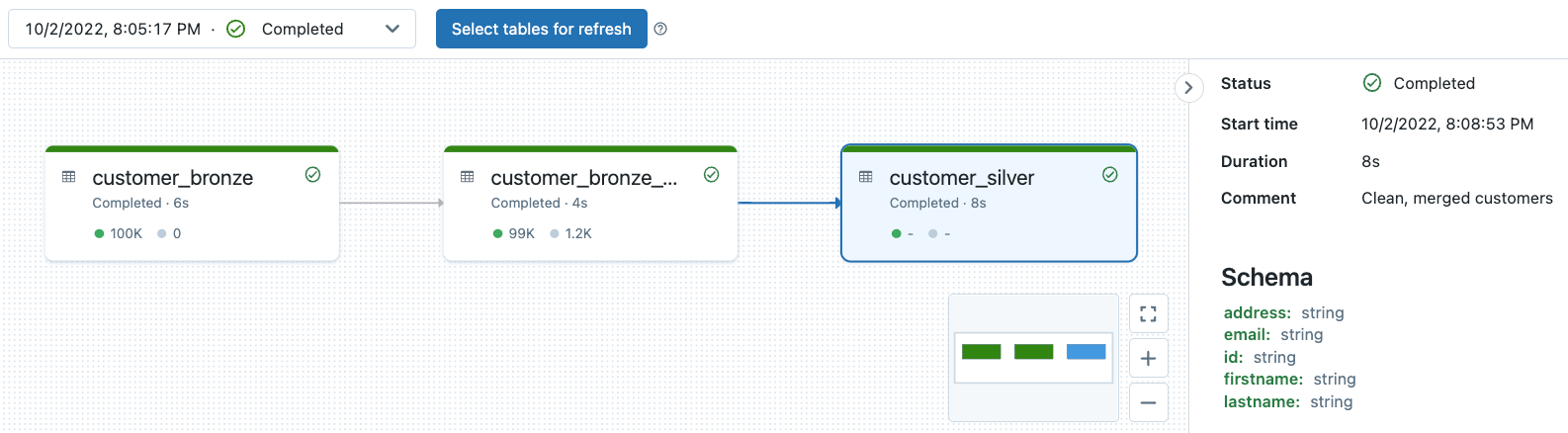
Osservabilità della Lineage della Pipeline DLT e Monitoraggio della Qualità dei Dati
Tutti i log della pipeline DLT sono archiviati nella posizione di archiviazione della pipeline. Puoi specificare la tua posizione di archiviazione solo quando crei la tua pipeline. Nota che una volta creata la pipeline non puoi più modificare la posizione di archiviazione.
Puoi consultare il nostro precedente approfondimento sull'argomento qui. Prova questo notebook per vedere l'osservabilità della pipeline e il monitoraggio della qualità dei dati sull'esempio di pipeline DLT associata a questo blog.
Conclusione
In questo blog, abbiamo mostrato come abbiamo reso semplice per gli utenti implementare in modo efficiente il change data capture (CDC) nella loro piattaforma Lakehouse con Delta Live Tables (DLT). DLT fornisce controlli di qualità integrati con una profonda visibilità sulle operazioni della pipeline, osservando la lineage della pipeline, monitorando lo schema e i controlli di qualità in ogni fase della pipeline. DLT supporta la gestione automatica degli errori e la migliore capacità di autoscaling per i carichi di lavoro di streaming, il che consente agli utenti di avere dati di qualità con le risorse ottimali richieste per il loro carico di lavoro.
Gli ingegneri dei dati possono ora implementare facilmente il CDC con una nuova API dichiarativa APPLY CHANGES INTO con DLT in SQL o Python. Questa nuova funzionalità consente alle tue pipeline ETL di identificare facilmente le modifiche e applicarle su decine di migliaia di tabelle con supporto a bassa latenza.
Guarda questo webinar per scoprire come Delta Live Tables semplifica la complessità della trasformazione dei dati e dell'ETL, e consulta il nostro documento Change data capture with Delta Live Tables, il github ufficiale e segui i passaggi in questo video per creare la tua pipeline!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.