Colonne Identity per Generare Chiavi Surrogate Disponibili nel Tuo Lakehouse!
Cos'è una colonna Identity?
Una colonna Identity è una colonna in un database che genera automaticamente un numero ID univoco per ogni nuova riga di dati. Questo numero non è correlato al contenuto della riga.
Le colonne Identity sono una forma di chiavi surrogate. Nei data warehouse, è comune utilizzare una chiave aggiuntiva, chiamata chiave surrogate, per identificare univocamente ogni riga e tenere traccia delle modifiche ai dati nel tempo. Inoltre, è consigliabile utilizzare chiavi surrogate rispetto alle chiavi naturali. Le chiavi surrogate sono generate dal sistema e non dipendono da diversi campi per identificare l'unicità della riga.
Quindi, le colonne Identity vengono utilizzate per creare chiavi surrogate, che possono fungere da chiavi primarie e esterne nei modelli dimensionali per data warehouse e data mart. Come si vede di seguito, queste chiavi sono le colonne che collegano tra loro tabelle diverse in un modello dimensionale tradizionale come uno schema a stella.
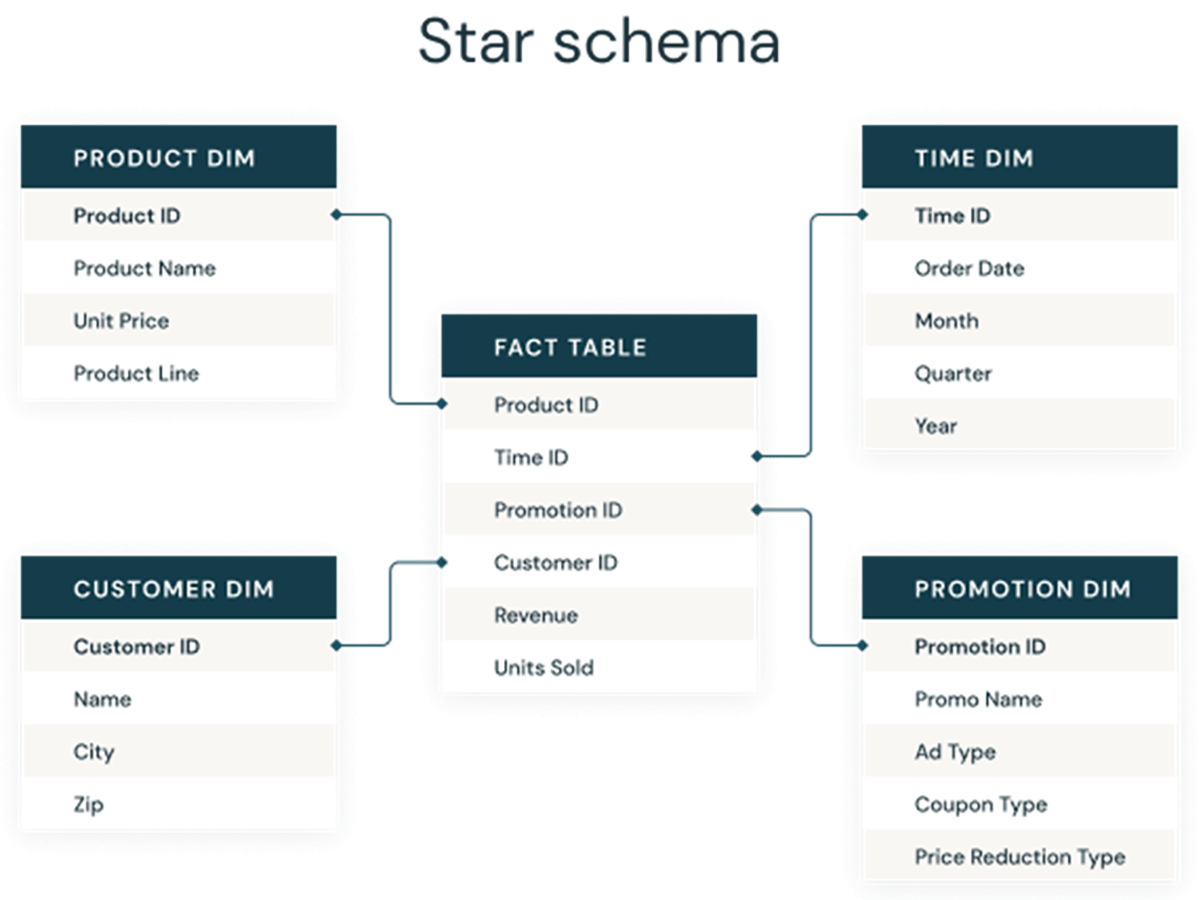
Approcci tradizionali per generare chiavi surrogate sui data lake
La maggior parte delle tecnologie big data utilizza il parallelismo, ovvero la capacità di dividere un'attività in parti più piccole che possono essere completate contemporaneamente, per migliorare le prestazioni. Agli albori dei data lake, non esisteva un modo semplice per creare sequenze univoche su un gruppo di macchine. Ciò ha portato alcuni data engineer a utilizzare metodi meno affidabili per generare chiavi surrogate senza una funzionalità adeguata, come:
monotonically_increasing_id(),row_number(),Rank OVER,ZipWithIndex(),ZipWithUniqueIndex(),- Hash di riga con
hash(),e - Hash di riga con
md5().
Sebbene queste funzioni siano in grado di svolgere il lavoro in determinate circostanze, sono spesso piene di molti avvisi e limitazioni riguardo al popolamento sparso delle sequenze, problemi di prestazioni su larga scala e problemi di transazioni concorrenti.
I database sono in grado di generare sequenze fin dagli albori, per generare chiavi surrogate che identifichino univocamente una riga di dati con l'assistenza di un gestore di transazioni centralizzato. Tuttavia, le implementazioni tipiche richiedono lock e commit transazionali, che possono essere difficili da gestire.
Le colonne Identity su Delta Lake semplificano la generazione di chiavi surrogate
Le colonne Identity risolvono i problemi sopra menzionati e forniscono una soluzione semplice e performante per la generazione di chiavi surrogate. Delta Lake è il primo protocollo di data lake a supportare le colonne Identity per la generazione di chiavi surrogate.
Delta Lake ora supporta la creazione di colonne IDENTITY che possono generare automaticamente numeri ID univoci e auto-incrementanti quando vengono caricate nuove righe. Sebbene questi numeri ID potrebbero non essere consecutivi, Delta si impegna al massimo per mantenere il divario il più piccolo possibile. Puoi utilizzare questa funzionalità per creare facilmente chiavi surrogate per i tuoi carichi di lavoro di data warehousing.
Come creare una chiave surrogate con una colonna Identity utilizzando SQL e Delta Lake
[Consigliato] Genera Sempre Come Identity
Creare una colonna Identity in SQL è semplice come creare una tabella Delta Lake. Dichiarando le tue colonne, aggiungi un nome di colonna chiamato id, o come preferisci, con un tipo di dati BIGINT, quindi inserisci GENERATED ALWAYS AS IDENTITY.
Ora, ogni volta che esegui un'operazione su questa tabella in cui inserisci dati, ometti questa colonna dall'inserimento e Delta Lake genererà automaticamente un valore univoco per la colonna IDENTITY per ogni riga inserita nella tabella Delta Lake.
Ecco un semplice esempio di come utilizzare le colonne Identity in Delta Lake:
D'ora in poi, la colonna Identity denominata "id" si auto-incrementerà ogni volta che inserirai nuovi record nella tabella. Puoi quindi inserire nuovi dati in questo modo:
Nota come la colonna della chiave surrogate denominata "id" è assente dalla parte INSERT dell'istruzione. Delta Lake popolerà le chiavi surrogate quando scriverà la tabella nello storage di oggetti cloud (ad es. AWS S3, Azure Data Lake Storage o Google Cloud Storage). Scopri di più nella documentazione.
Genera per DEFAULT
Esiste anche l'opzione GENERATED BY DEFAULT AS IDENTITY, che consente di sovrascrivere l'inserimento dell'identità, mentre l'opzione ALWAYS non può essere sovrascritta.
Ci sono alcune avvertenze da tenere a mente quando si adotta questa nuova funzionalità. Le colonne Identity non possono essere aggiunte a tabelle esistenti; le tabelle dovranno essere ricreate con la nuova colonna Identity aggiunta. Per fare ciò, crea semplicemente un nuovo DDL della tabella con la colonna Identity e inserisci le colonne esistenti nella nuova tabella, e le chiavi surrogate verranno generate per la nuova tabella.
Inizia oggi stesso con le Colonne Identity con Delta Lake su Databricks SQL
Le colonne Identity sono ora GA (Generalmente Disponibili) in Databricks Runtime 10.4+ e in Databricks SQL 2022.17+. Con le colonne Identity, puoi ora abilitare tutti i tuoi carichi di lavoro di data warehousing per avere tutti i vantaggi di un'architettura Lakehouse, accelerata da Photon. Prova oggi stesso le colonne Identity su Databricks SQL.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.