Spark Connect disponibile in Apache Spark 3.4
Esegui Applicazioni Spark Ovunque
di Allan Folting, Hyukjin Kwon, Xiao Li, Herman van Hövell, Stefania Leone, Martin Grund, Reynold Xin e Kris Mo
L'anno scorso Spark Connect è stato introdotto al Data and AI Summit. Come parte della versione rilasciata di recente di Apache SparkTM 3.4, Spark Connect è ora disponibile a livello generale. Abbiamo anche recentemente riarchitettato Databricks Connect per basarlo su Spark Connect. Questo post del blog illustra cos'è Spark Connect, come funziona e come utilizzarlo.
Gli utenti possono ora connettere IDE, Notebook e moderne applicazioni dati direttamente ai cluster Spark
Spark Connect introduce un'architettura client-server disaccoppiata che abilita la connettività remota ai cluster Spark da qualsiasi applicazione, in esecuzione ovunque. Questa separazione tra client e server consente alle moderne applicazioni dati, IDE, Notebook e linguaggi di programmazione di accedere a Spark in modo interattivo.
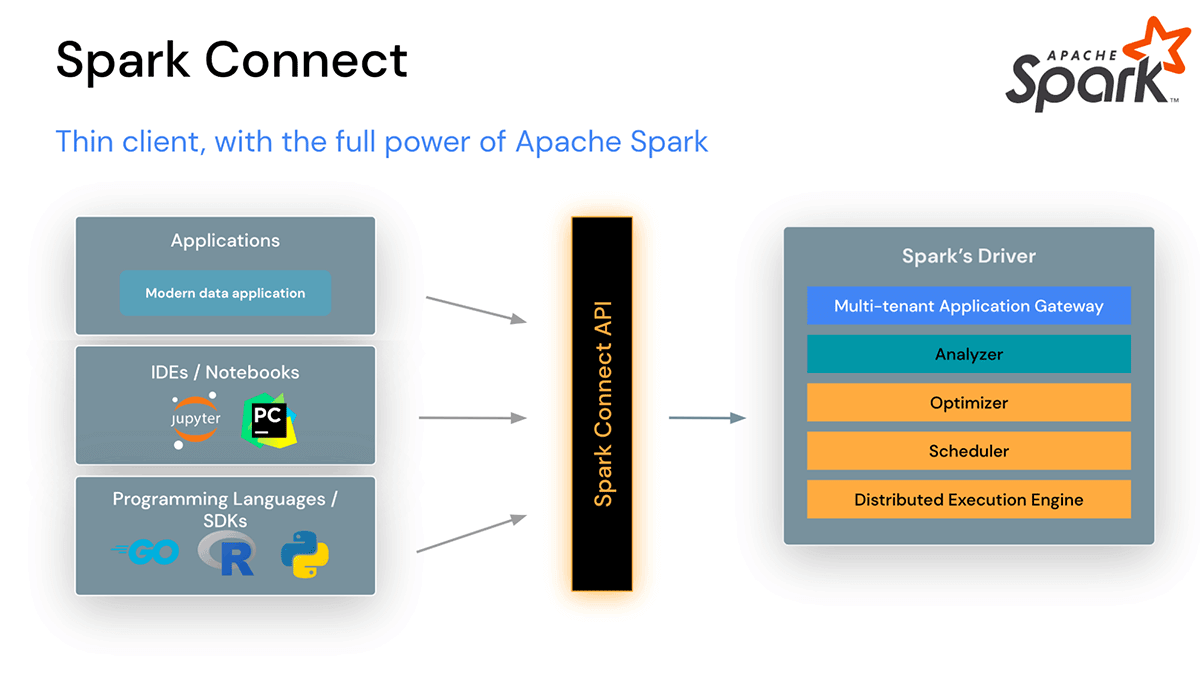
Spark Connect migliora Stabilità, Aggiornamenti, Debug e Osservabilità
Con questa nuova architettura, Spark Connect mitiga anche problemi operativi comuni:
Stabilità: Le applicazioni che utilizzano molta memoria ora influenzeranno solo il proprio ambiente poiché possono essere eseguite nei propri processi al di fuori del cluster Spark. Gli utenti possono definire le proprie dipendenze nell'ambiente client e non devono preoccuparsi di potenziali conflitti di dipendenze sul driver Spark.
Ad esempio, se si dispone di un'applicazione client che recupera un ampio set di dati da Spark per l'analisi o per eseguire trasformazioni, tale applicazione non verrà più eseguita sul driver Spark. Ciò significa che, se l'applicazione utilizza molta memoria o cicli di CPU, non competerà per le risorse con altre applicazioni sul driver Spark, causando potenzialmente il rallentamento o il fallimento di tali altre applicazioni, poiché ora viene eseguita nel proprio ambiente separato e dedicato.
Aggiornabilità: In passato, era estremamente complicato aggiornare Spark, perché tutte le applicazioni sullo stesso cluster Spark dovevano essere aggiornate insieme al cluster contemporaneamente. Con Spark Connect, le applicazioni possono essere aggiornate indipendentemente dal server, grazie alla separazione tra client e server. Ciò rende l'aggiornamento molto più semplice perché le organizzazioni non devono apportare modifiche alle proprie applicazioni client durante l'aggiornamento di Spark.
Debug e osservabilità: Spark Connect abilita il debug interattivo passo-passo durante lo sviluppo direttamente dal tuo IDE preferito. Allo stesso modo, le applicazioni possono essere monitorate utilizzando le metriche native e le librerie di logging del framework dell'applicazione.
Ad esempio, è possibile eseguire il debug interattivo passo-passo di un'applicazione client Spark Connect in Visual Studio Code, ispezionare oggetti ed eseguire comandi di debug per testare e correggere problemi nel codice.
Come funziona Spark Connect
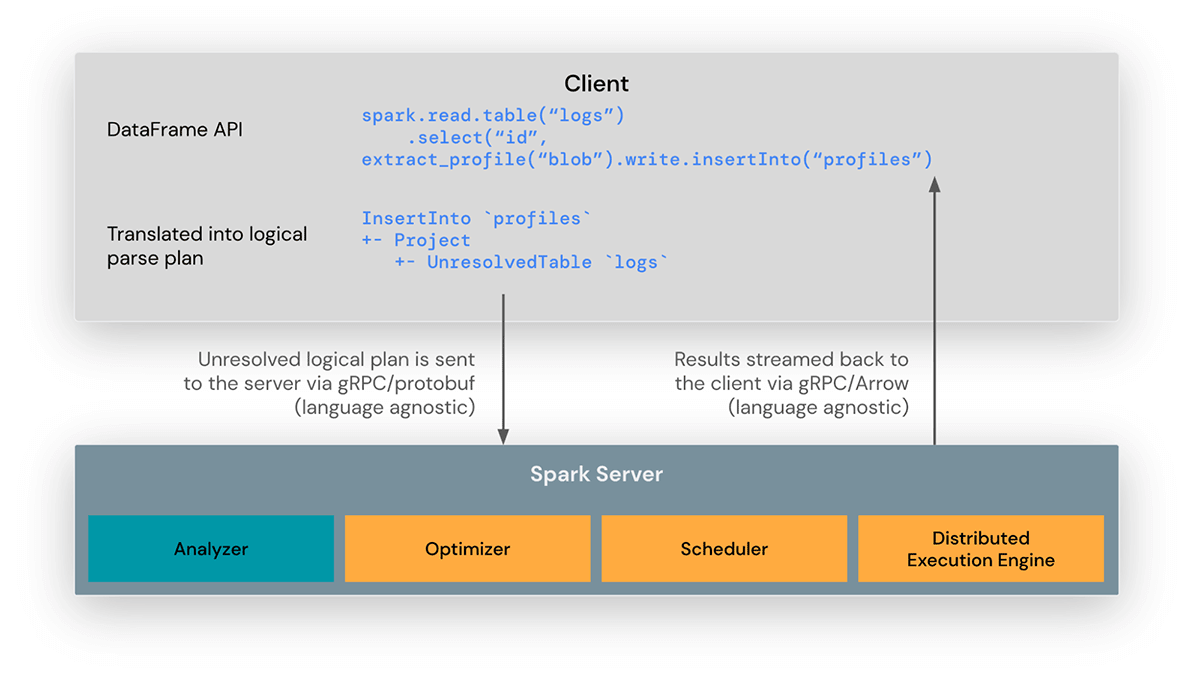
La libreria client Spark Connect è progettata per semplificare lo sviluppo di applicazioni Spark. È una API sottile che può essere incorporata ovunque: in server di applicazioni, IDE, notebook e linguaggi di programmazione. L'API Spark Connect si basa sull'API DataFrame di Spark utilizzando piani logici non risolti come protocollo agnostico rispetto al linguaggio tra client e driver Spark.
Il client Spark Connect traduce le operazioni DataFrame in piani logici non risolti che vengono codificati utilizzando protocol buffer. Questi vengono inviati al server utilizzando il framework gRPC.
L'endpoint Spark Connect incorporato nel driver Spark riceve e traduce i piani logici non risolti in operatori di piano logico di Spark. Questo è simile all'analisi di una query SQL, dove attributi e relazioni vengono analizzati e viene costruito un piano di analisi iniziale. Da lì, entra in gioco il normale processo di esecuzione di Spark, garantendo che Spark Connect sfrutti tutte le ottimizzazioni e i miglioramenti di Spark. I risultati vengono trasmessi in streaming al client tramite gRPC come batch di risultati codificati in Apache Arrow.
Come usare Spark Connect
A partire da Spark 3.4, Spark Connect è disponibile e supporta applicazioni PySpark e Scala. Illustreremo un esempio di connessione a un server Apache Spark con Spark Connect da un'applicazione client utilizzando la libreria client Spark Connect.
Quando si scrivono applicazioni Spark, l'unico momento in cui è necessario considerare Spark Connect è quando si creano sessioni Spark. Tutto il resto del codice è esattamente lo stesso di prima.
Per utilizzare Spark Connect, è sufficiente impostare una variabile d'ambiente (SPARK_REMOTE) che la tua applicazione possa leggere, senza apportare modifiche al codice, oppure è possibile includere esplicitamente Spark Connect nel codice durante la creazione delle sessioni Spark.
Diamo un'occhiata a un esempio di notebook Jupyter. In questo notebook creiamo una sessione Spark Connect a un cluster Spark locale, creiamo un DataFrame PySpark e mostriamo i primi 10 artisti musicali per numero di ascoltatori.
In questo esempio, specifichiamo esplicitamente che vogliamo utilizzare Spark Connect impostando la proprietà remota durante la creazione della nostra sessione Spark (SparkSession.builder.remote...).
Codice Jupyter notebook che utilizza Spark Connect
Puoi scaricare il set di dati utilizzato nell'esempio da qui: Music artists popularity | Kaggle
Come illustrato nel seguente esempio, Spark Connect rende anche facile passare da un cluster Spark all'altro, ad esempio quando si sviluppa e si testa su un cluster Spark locale e successivamente si sposta il codice in produzione su un cluster remoto.
In questo esempio, impostiamo la variabile d'ambiente TEST_ENV per guidare quale cluster Spark e quale posizione dati utilizzerà la nostra applicazione, in modo da non dover apportare modifiche al codice per passare tra i nostri cluster di test, staging e produzione.
Passaggio tra diversi cluster Spark utilizzando una variabile d'ambiente
Per saperne di più su come utilizzare Spark Connect, visita le pagine Panoramica di Spark Connect e Guida rapida a Spark Connect.
Databricks Connect è basato su Spark Connect
A partire da Databricks Runtime 13.0, Databricks Connect è ora basato su Spark Connect open-source. Con questa architettura “v2”, Databricks Connect diventa un client sottile, semplice e facile da usare. Può essere incorporato ovunque per connettersi a Databricks: in IDE, Notebook e qualsiasi applicazione, consentendo a clienti e partner di creare nuove esperienze utente (interattive) basate sul tuo Databricks Lakehouse. È molto facile da usare: gli utenti incorporano semplicemente la libreria Databricks Connect nelle loro applicazioni e si connettono al loro Databricks Lakehouse.
API supportate in Apache Spark 3.4
PySpark: In Spark 3.4, Spark Connect supporta la maggior parte delle API PySpark, incluse DataFrame, Functions e Column. Le API PySpark supportate sono etichettate come “Supports Spark Connect” nella documentazione di riferimento alle API, così puoi verificare se le API che stai utilizzando sono disponibili prima di migrare il codice esistente a Spark Connect.
Scala: In Spark 3.4, Spark Connect supporta la maggior parte delle API Scala, incluse Dataset, functions e Column.
Il supporto per lo streaming arriverà presto e non vediamo l'ora di collaborare con la community per fornire più API per Spark Connect nelle prossime release di Spark.
Spark Connect in Apache Spark 3.4 apre l'accesso a Spark da qualsiasi applicazione basata su DataFrame/DataSet in PySpark e Scala e pone le basi per supportare altre lingue di programmazione in futuro.
Con lo sviluppo semplificato delle applicazioni client, la mitigazione della contesa di memoria sul driver Spark, la gestione separata delle dipendenze per le applicazioni client, gli aggiornamenti indipendenti di client e server, il debug IDE passo-passo e il logging e le metriche del client leggero, Spark Connect rende l'accesso a Spark ubiquitario.
Per saperne di più su Spark Connect e iniziare, visita le pagine Panoramica di Spark Connect e Guida rapida di Spark Connect .
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.