Sicurezza dell'IA agentiva: Nuovi rischi e controlli nel Databricks AI Security Framework (DASF v3.0)
35 nuovi rischi di agentic AI e 6 controlli di mitigazione per agenti che accedono ai dati, chiamano strumenti ed eseguono azioni
di David Veuve, Omar Khawaja, Arun Pamulapati, Nishith Sinha e Caelin Kaplan
- Il Databricks AI Security Framework (DASF) ora copre l'Agentic AI come 13° componente di sistema, aggiungendo 35 nuovi rischi tecnici di sicurezza e 6 nuovi controlli di mitigazione per aiutare le organizzazioni a distribuire agenti autonomi con fiducia.
- Questa estensione affronta i rischi unici della memoria, della pianificazione e dell'uso degli strumenti degli agenti, comprese le minacce introdotte dal Model Context Protocol (MCP), lo standard emergente per la connessione degli agenti agli strumenti aziendali.
- Il whitepaper DASF Agentic AI Extension e il compendio aggiornato sono ora disponibili. Scaricali per valutare le tue architetture di agenti, mappare i tuoi ecosistemi di strumenti e implementare controlli di difesa in profondità specificamente progettati per l'autonomia.
Siamo entusiasti di annunciare il rilascio del whitepaper Databricks AI Security Framework (DASF) Agentic AI Extension! I clienti Databricks stanno già distribuendo agenti AI che interrogano database, chiamano API esterne, eseguono codice e coordinano con altri agenti. Sentiamo continuamente che i team responsabili di queste distribuzioni si pongono domande difficili: cosa succede quando l'AI può fare cose, non solo dirle? Ecco perché abbiamo esteso DASF.
Con questo aggiornamento, introduciamo nuove indicazioni per la protezione di agenti AI autonomi:
- 35 nuovi rischi di sicurezza per agenti AI che coprono il ragionamento, la memoria e l'uso degli strumenti da parte dell'agente
- 6 nuovi controlli di mitigazione tra cui il privilegio minimo, il sandboxing e la supervisione umana
- Linee guida di sicurezza per server e client del Model Context Protocol (MCP)
- Copertura per i rischi dei sistemi multi-agente e le minacce alla comunicazione tra agenti
Insieme, queste aggiunte aiutano le organizzazioni a distribuire agenti AI in modo sicuro, mantenendo al contempo governance, osservabilità e controlli di sicurezza a difesa stratificata.
Ciò porta il framework completo a 97 rischi e 73 controlli. Abbiamo aggiornato il compendio DASF (Google sheet, Excel) per includere questi nuovi rischi e controlli, mappandoli agli standard di settore per facilitare l'operatività immediata. Queste aggiunte sono catalogate come DASF v3.0 nella colonna "DASF Revision".
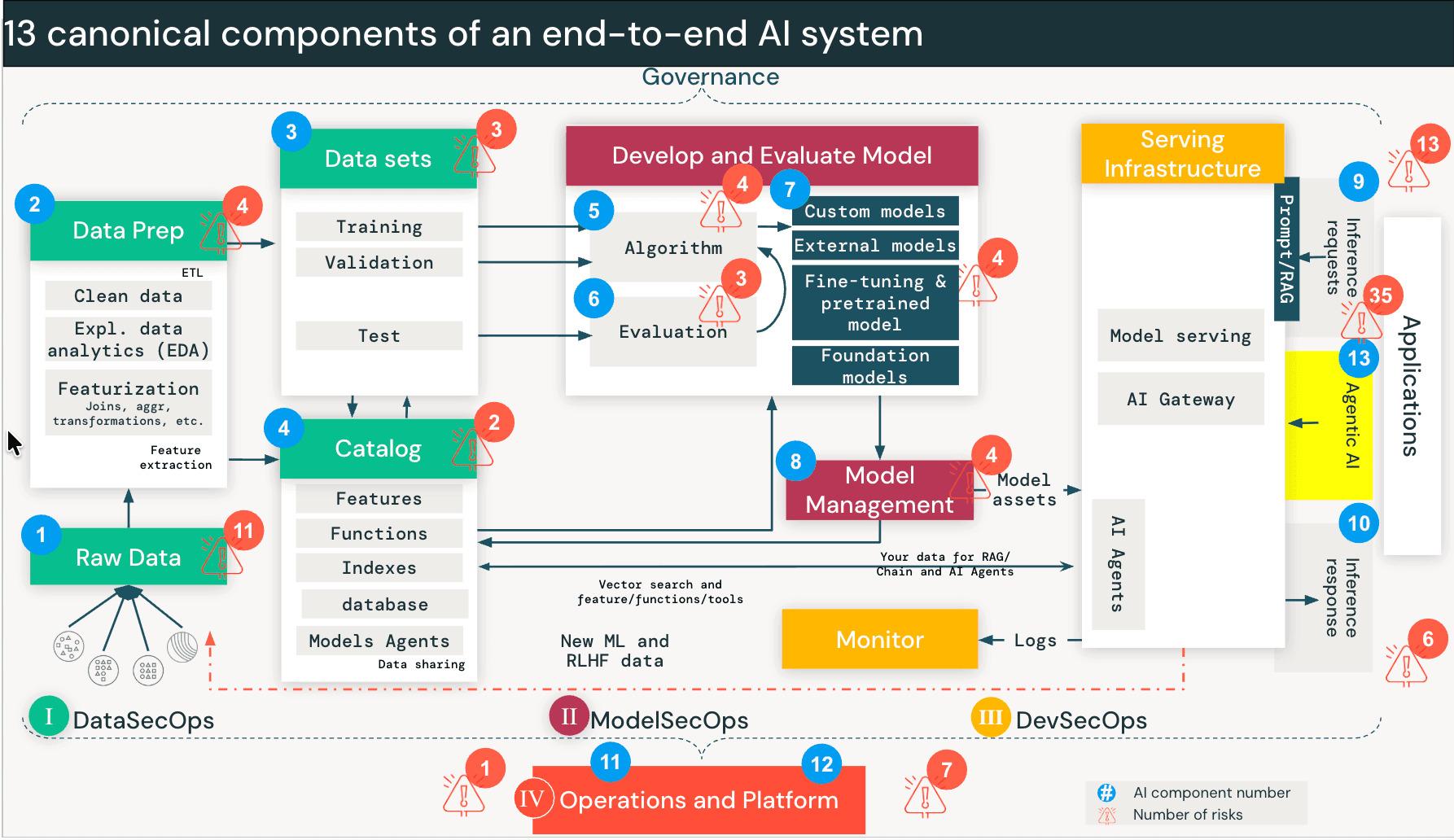
{kind=link}
Rischi di sicurezza quando gli agenti AI possono intraprendere azioni
I sistemi AI tradizionali come RAG operano principalmente in modalità di sola lettura. Ma gli agenti AI possono intraprendere azioni come interrogare database, chiamare API, eseguire codice e interagire con strumenti esterni.
Gli agenti funzionano in modo diverso. Quando un utente interagisce con un agente, il modello avvia un ciclo: scompone la richiesta in sotto-attività, sceglie uno strumento (ad esempio, "Interroga Database Vendite"), lo esegue, valuta l'output e decide se chiamare un altro strumento successivamente. Questo continua fino al completamento dell'attività. L'agente prende decisioni in tempo reale su quali dati accedere e quali strumenti invocare — decisioni che prima venivano prese dagli esseri umani o codificate nella logica dell'applicazione.
Ciò crea una nuova classe di rischio che chiamiamo Discovery and Traversal. Un agente progettato per trovare soluzioni attraverserà percorsi dati e interfacce di strumenti che non erano mai stati previsti per l'utente richiedente. Non sta sfruttando un bug. Sta facendo esattamente ciò per cui è stato costruito. Ma senza controlli adeguati, l'utente eredita effettivamente i permessi dell'agente anziché i propri.
Il Trifecta Letale. Ricerche recenti del settore, tra cui “Agents Rule of Two” di Meta e modelli simili come “Lethal Trifecta” di Simon Willison, evidenziano le condizioni in cui ciò diventa pericoloso. Il profilo di rischio aumenta quando tre condizioni sono presenti contemporaneamente:
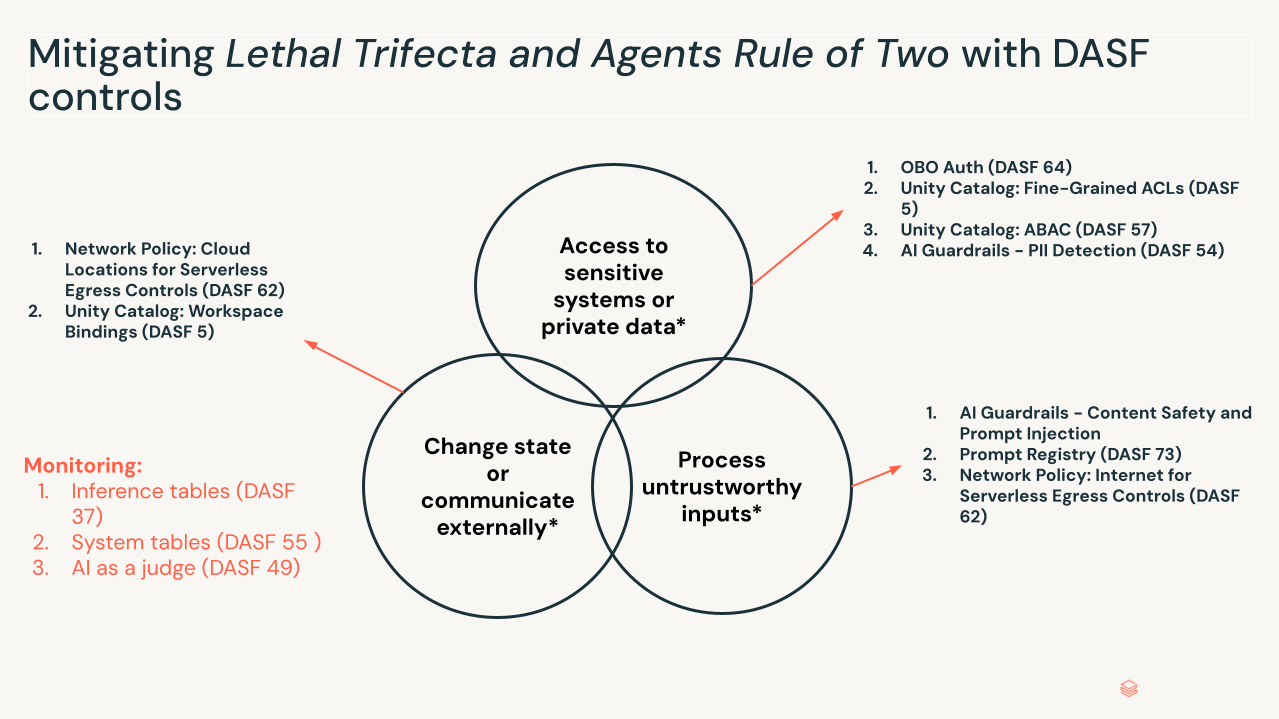
- Accesso a sistemi sensibili o dati privati: L'agente può recuperare dati privati o riservati.
- Elaborazione di input non attendibili: L'agente elabora dati provenienti dall'esterno del confine di fiducia — prompt utente, siti web esterni, email in arrivo.
- Modifica dello stato o comunicazione esterna: L'agente può modificare lo stato tramite strumenti o connessioni MCP — invio di email, esecuzione di SQL, modifica di codice.
Con tutte e tre le condizioni presenti, un prompt injection indiretto incorporato in dati non attendibili può dirottare l'intero set di funzionalità dell'agente, trasformandolo in un "deputato confuso" che esegue azioni autorizzate con intento malevolo. Rimuovere qualsiasi singola gamba limitando i permessi, aggiungendo un checkpoint umano, validando l'intento prima della selezione dello strumento e interrompendo la catena di attacco.
Come è organizzata l'estensione
I 35 nuovi rischi e i 6 controlli sono organizzati attorno a tre sotto-componenti che mappano il modo in cui gli agenti funzionano effettivamente:
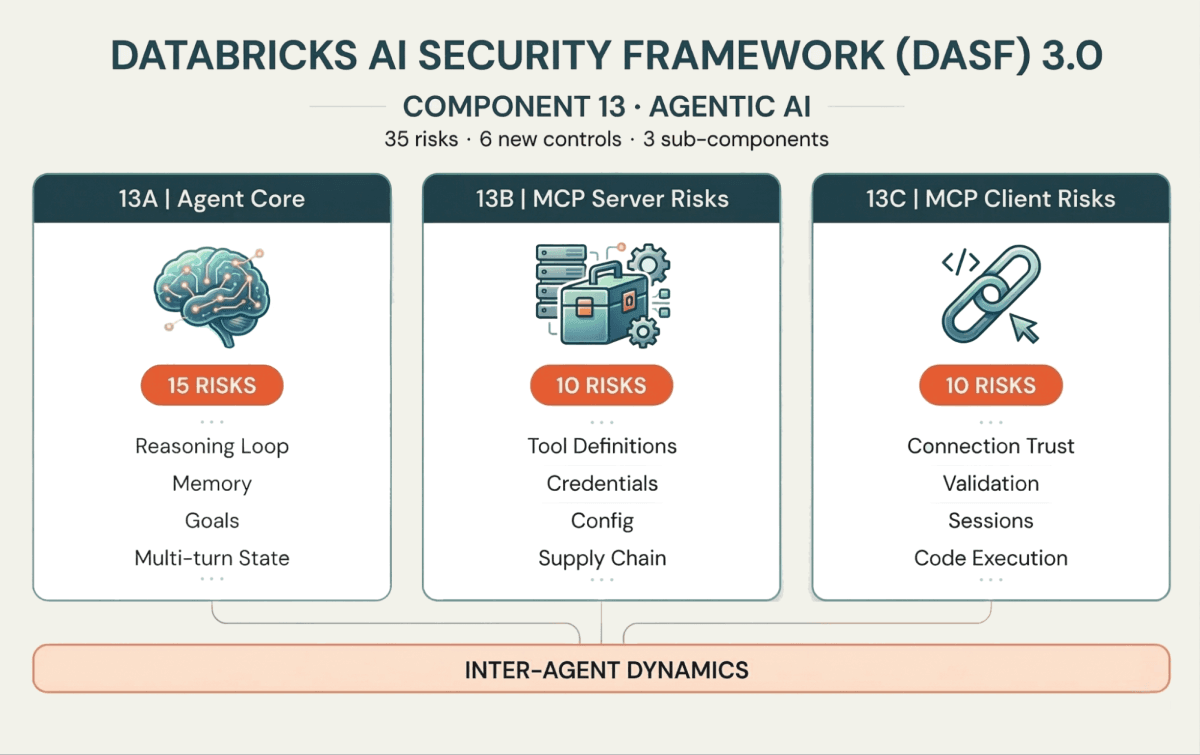
13A: Il Core dell'Agente (cervello e memoria)
Questi rischi riguardano il ciclo di ragionamento dell'agente. Il Memory Poisoning (Rischio 13.1) introduce un contesto falso che altera le decisioni attuali o future. L'Intent Breaking & Goal Manipulation (Rischio 13.6) costringe l'agente a deviare dal suo obiettivo. E poiché gli agenti operano in cicli multi-turno, i Cascading Hallucination Attacks (Rischio 13.5) possono amplificare un piccolo errore attraverso le iterazioni fino a un'azione distruttiva.
13B: Rischi del Server MCP (l'interfaccia dello strumento)
Gli agenti interagiscono con sistemi esterni tramite strumenti, sempre più standardizzati tramite il Model Context Protocol (MCP). Sul lato server, gli aggressori possono implementare il Tool Poisoning (Rischio 13.18) — iniettando comportamenti malevoli nelle definizioni degli strumenti — o sfruttare il Prompt Injection (Rischio 13.16) all'interno delle descrizioni degli strumenti per aggirare i controlli di sicurezza.
13C: Rischi del Client MCP (il livello di connessione)
Sul lato client, se l'agente si connette a un Malicious Server (Rischio 13.26) o non riesce a convalidare le risposte del server, rischia l'Client-Side Code Execution (Rischio 13.32) o la Data Leakage (Rischio 13.30). Con l'aumentare dell'adozione di MCP, la protezione del confine client-server è importante quanto la protezione del ragionamento dell'agente.
Dinamiche inter-agente
Gli agenti comunicheranno sempre più tra loro. Ciò crea rischi di Agent Communication Poisoning (Rischio 13.12) e Rogue Agents in Multi-Agent Systems (Rischio 13.13) — agenti che operano al di fuori dei confini di monitoraggio, un problema che si aggrava con la scalabilità.
Controlli per la protezione di agenti AI e sistemi autonomi
Il DASF è sempre stato incentrato sulla difesa stratificata. Ma quando un sistema AI può intraprendere azioni, i controlli di accesso in sola lettura non sono sufficienti. I nuovi controlli affrontano direttamente questo problema:
- Privilegio minimo per gli strumenti (DASF 5, DASF 57, DASF 64): Gli agenti necessitano di permessi granulari limitati al loro compito immediato, riducendo il raggio d'azione allo stesso modo in cui RBAC e ABAC limitano quello di un essere umano. Solo perché un agente può chiamare lo strumento delle metriche HR, non significa che dovrebbe farlo quando risponde a una richiesta di vendita.
- Supervisione umana (Human-in-the-loop) (DASF 66): Per azioni ad alto rischio, richiedere la verifica umana prima dell'esecuzione dello strumento. La progettazione del controllo tiene conto dell'affaticamento da approvazione — se si sovraccarica il revisore umano, si è creata una nuova vulnerabilità, non risolta una.
- Sandboxing e isolamento (DASF 34, DASF 62): Il codice generato dall'agente viene eseguito in ambienti effimeri e isolati. Se un agente decide di scrivere ed eseguire uno script, tale esecuzione non dovrebbe avere accesso al sistema più ampio e alle connessioni in uscita verso destinazioni sconosciute.
- AI Gateway e Guardrails (DASF 54): Gli agenti necessitano di protezioni contro scenari in cui un agente viene manipolato per esporre dati che non dovrebbe. Le interazioni degli agenti tramite gateway e guardrail come monitoraggio, filtraggio di sicurezza e rilevamento PII devono essere applicate. Questi guardrail possono essere applicati all'input o all'output di un agente (o entrambi). È inoltre ugualmente importante monitorare ciò che viene effettivamente restituito dall'agente.
- Osservabilità del pensiero (DASF 65): La registrazione standard indica cosa è successo. Il tracing degli agenti cattura il perché — i passaggi di pianificazione, il ragionamento nella selezione dello strumento, la catena di pensiero che ha portato a un'azione. Senza questo, non è possibile controllare le decisioni di un agente o rilevare quando il suo ragionamento è stato compromesso.
Per i clienti Databricks, il compendio mappa questi controlli alle funzionalità della piattaforma, tra cui la governance di Unity Catalog per l'accesso ai dati degli agenti, il Agent Bricks Framework, le guardrail di AI Gateway e le impostazioni di sicurezza di AI Search.
Costruito con la community
Questa estensione riflette gli input di revisori e collaboratori di Databricks e della community della sicurezza, inclusi i team di Atlassian, Experian e ComplyLeft. Ci siamo inoltre basati ampiamente sul lavoro di MITRE ATLAS, OWASP, NIST e Cloud Security Alliance: il compendio aggiornato mappa tutti i 97 rischi e i 73 controlli a questi standard di settore.
Inizia
Scarica il whitepaper DASF Agentic AI Extension per il trattamento completo di tutti i 35 nuovi rischi dell'AI agentica e i 6 nuovi controlli, e prendi il compendio aggiornato (Google Sheet, Excel) che ora mappa i rischi e i controlli agentici insieme al DASF originale. Usa queste risorse per:
- Valutare le tue attuali architetture di agenti rispetto al modello di rischio dell'AI agentica.
- Mappare i tuoi ecosistemi di strumenti, inclusi server e client MCP, ai vettori di minaccia identificati.
- Implementare i controlli consigliati per garantire che i tuoi agenti operino entro confini sicuri e governati.
Per un contesto più approfondito, leggi il whitepaper completo DASF ed esplora la documentazione Agent Bricks Framework per vedere come questi controlli funzionano sulla piattaforma.
Contatta il tuo team account Databricks o inviaci un'email a dasf@databricks.com con il tuo feedback: questo framework appartiene alla community tanto quanto a noi.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.