Piattaforma di AI serving che si adatta al tuo modello
Un'unica piattaforma per tutti i modelli AI - ML classico, deep learning e agenti - oltre 300K QPS, meno di 10 ms, nessuna ottimizzazione richiesta
di Anshul Gupta
- Cos'è: una piattaforma completamente gestita che esegue qualsiasi modello in produzione, da un classificatore scikit-learn da 2 MB su un singolo core CPU a un LLM da 70B con fine-tuning su otto GPU, senza configurazioni manuali.
- La sfida che risolve: i modelli personalizzati hanno profili di risorse e pattern di traffico estremamente diversi, quindi nessuna singola configurazione statica è adatta a tutti. La piattaforma invece si adatta, mantenendo bassa la latenza e garantendo l'efficienza di ogni nodo.
- I risultati: oltre 300K QPS con un overhead di latenza p99 <10 ms e costi infrastrutturali inferiori fino al 90% per i clienti che migrano da stack autogestiti.
Le sfide dell'inferenza di modelli personalizzati
Quando si distribuisce un modello di machine learning in produzione, ci si impegna a rispettare un contratto: ogni richiesta viene completata entro pochi millisecondi, indipendentemente dai picchi di traffico, e i costi rimangono contenuti quando il traffico è basso. Il model serving è l'infrastruttura che garantisce il rispetto di questo contratto e, per gran parte della storia di questo settore, mantenerlo è stato difficile quanto creare il modello stesso.
I modelli personalizzati sono fondamentalmente diversi dai modelli foundation. Una piattaforma che ospita un modello foundation (Llama, Mistral, una variante di CLIP) sa esattamente cosa sta eseguendo: l'architettura, l'impronta di memoria, le caratteristiche di inferenza, e può ottimizzare a fondo per quel singolo modello. Le piattaforme per modelli personalizzati sono l'opposto. La stessa piattaforma deve servire un classificatore scikit-learn da 2 MB su un singolo core CPU e un LLM da 70B ottimizzato tramite fine-tuning su otto GPU; un ranker a bassa latenza che non può tollerare code e un modello di embedding che trae vantaggio da un batching aggressivo. Una piattaforma in grado di servire ogni tipo di modello, senza che ve ne siano due con lo stesso profilo di risorse, andamento del traffico o budget di latenza.
Le piattaforme tradizionali trasferiscono questa complessità sul cliente: numero di repliche, concorrenza per replica, soglie di autoscaling. Questo è ancora un approccio DIY, solo a un livello di astrazione più elevato. E non finisce mai: ogni nuovo modello e variazione di traffico richiedono una nuova profilazione e ottimizzazione, così i migliori ingegneri si trovano a gestire emergenze in produzione prima e dopo il rilascio, e il serving diventa la zavorra che rallenta ogni lancio. Il risultato è il costo che incide di più: modelli testati in sviluppo rimangono fermi per settimane prima di raggiungere la produzione.
La nostra missione: eliminare la tassa sullo stack ML
Riconfigurare manualmente l'infrastruttura di serving è una tassa su ogni modello eseguito da un'organizzazione; su larga scala diventa strutturale, con team che creano gruppi di serving dedicati il cui unico compito è mantenere i modelli attivi e performanti in produzione. La chiamiamo la tassa sullo stack ML.
Databricks Custom Model Serving è una piattaforma di inferenza in tempo reale completamente gestita per qualsiasi modello pacchettizzato in MLflow. La nostra missione è cancellare questa tassa nelle tre fasi della vita di un modello, in modo che i team di serving dei nostri clienti possano concentrarsi su attività a maggior valore aggiunto:
- Semplificare la pre-produzione. Un modello addestrato in Databricks viene distribuito con un solo clic: replichiamo esattamente l'ambiente, senza sorprese a runtime, e ottimizziamo i tempi di distribuzione per mantenere rapide le iterazioni e i rollback.
- Rendere la produzione affidabile, scalabile ed efficiente in termini di costi. L'infrastruttura si adatta a ciascun modello e al suo traffico a runtime, mantenendo bassa la latenza e riducendo i costi senza dover configurare parametri manuali. (L'argomento principale di questo post.)
- Semplificare la post-produzione. Ogni endpoint invia automaticamente telemetria a Unity Catalog (metriche, log e tracce nativi di OTel, tabelle di inferenza istantanee che acquisiscono ogni richiesta a Delta e MLflow Tracing). Genie Code si integra con tutto questo per offrire un'osservabilità operativa di tipo agentico unica nel suo genere. L'osservabilità per l'AI è un problema di contesto, e l'intero contesto risiede in un'unica piattaforma.
Questo funziona perché Custom Model Serving è integrato nativamente in Databricks: dati, feature, addestramento, pacchettizzazione MLflow, serving e agenti costituiscono un unico stack governato, non sistemi separati assemblati alla meno peggio.
Questo post tratta la seconda fase, spiegando come raggiungiamo oltre 300.000 QPS a bassa latenza su un'ampia varietà di modelli con un approccio senza parametri manuali. Questo è ciò che fa scomparire la tassa.
Architettura
Tre vincoli influenzano ogni decisione nell'architettura: bassa latenza, scalabilità elevata ed efficienza dei costi. Si contrastano a vicenda (il modo più semplice per ridurre la latenza è il sovradimensionamento, mentre per ridurre i costi è il sottodimensionamento) e riuscire a soddisfarli tutti e tre contemporaneamente, per ogni tipo di modello e senza alcuno spreco di risorse, è la vera sfida ingegneristica.
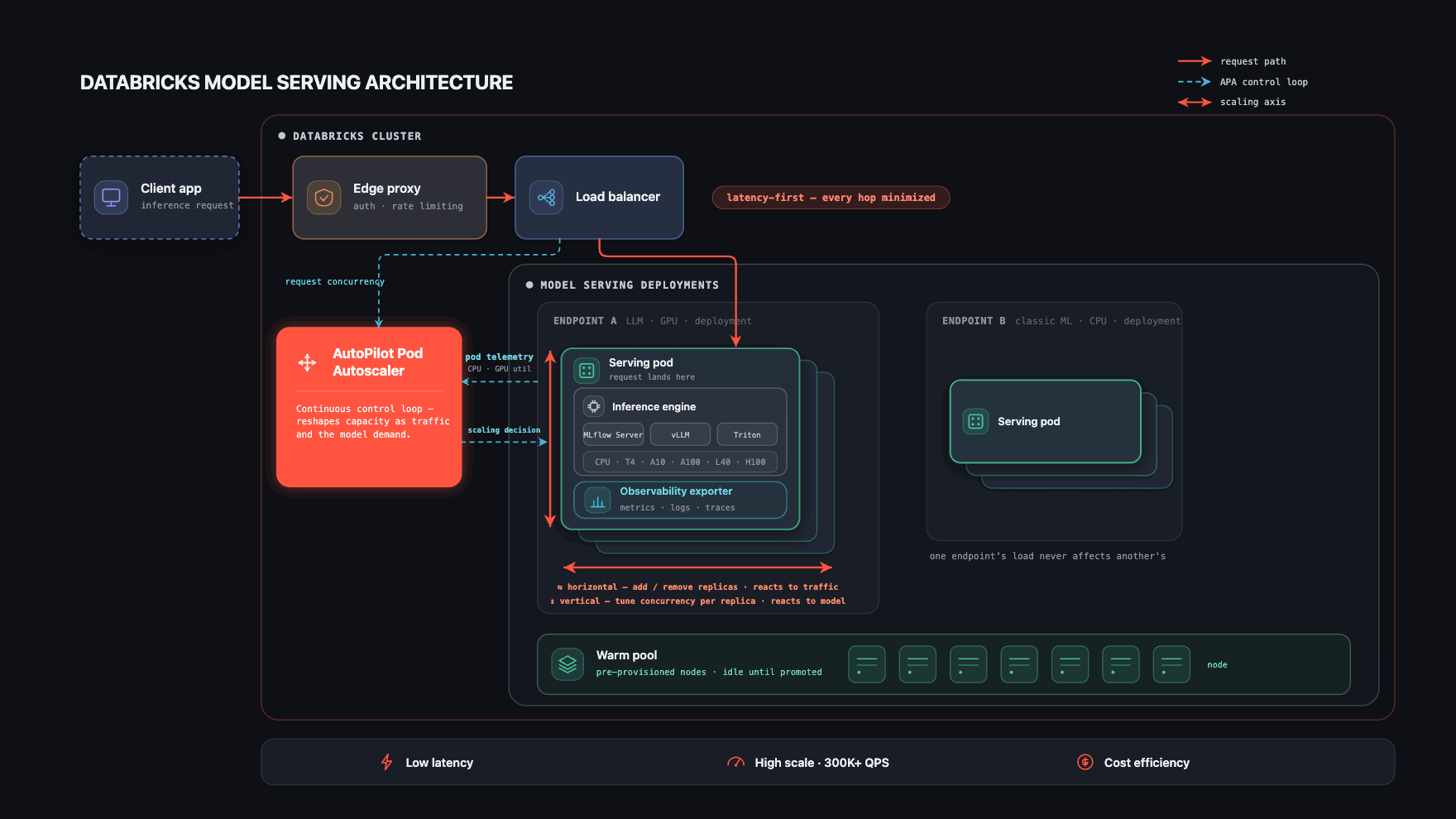
Tre elementi ne garantiscono il funzionamento.
- Un percorso di richiesta breve e isolato che riduce al minimo l'overhead di latenza a ogni hop.
- Selezione automatica del runtime: ogni modello viene eseguito sul motore di inferenza più adatto.
- Il cuore della piattaforma: un autoscaler che si adatta sia al modello che al suo traffico in tempo reale, mantenendo bassa la latenza e alta la scalabilità, riducendo al contempo i costi.
I primi due elementi mantengono rapida la singola richiesta; il terzo mantiene veloce ed efficiente l'intero sistema al variare dei modelli e del traffico. La maggior parte di questa sezione riguarda il terzo elemento.
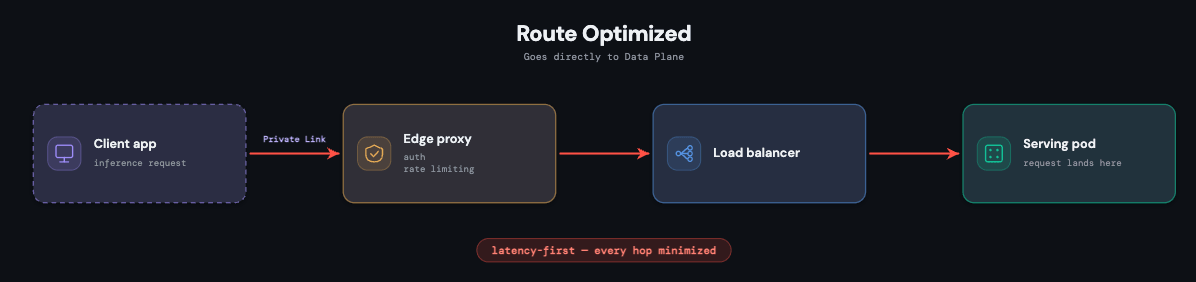
Percorso di richiesta breve e isolato
Ogni endpoint di serving è un deployment Kubernetes completamente isolato con i propri pod e un'immagine container specifica per la versione del modello. Questo isolamento è intenzionale: il traffico, i guasti o la pressione sulle risorse di un endpoint non possono influire su un altro, garantendo la sicurezza dei carichi di lavoro personalizzati.
Il percorso stesso è ridotto al minimo, perché la latenza è un vincolo di primaria importanza a ogni livello. Una richiesta arriva tramite un proxy PoP; una volta autenticata, passa attraverso un load balancer condiviso per la gestione delle connessioni e arriva immediatamente sul pod che la serve. Ogni pod esegue anche un sidecar di osservabilità che esporta metriche, log, log dei payload e tracce, sia per il monitoraggio della piattaforma che per le dashboard rivolte ai clienti.
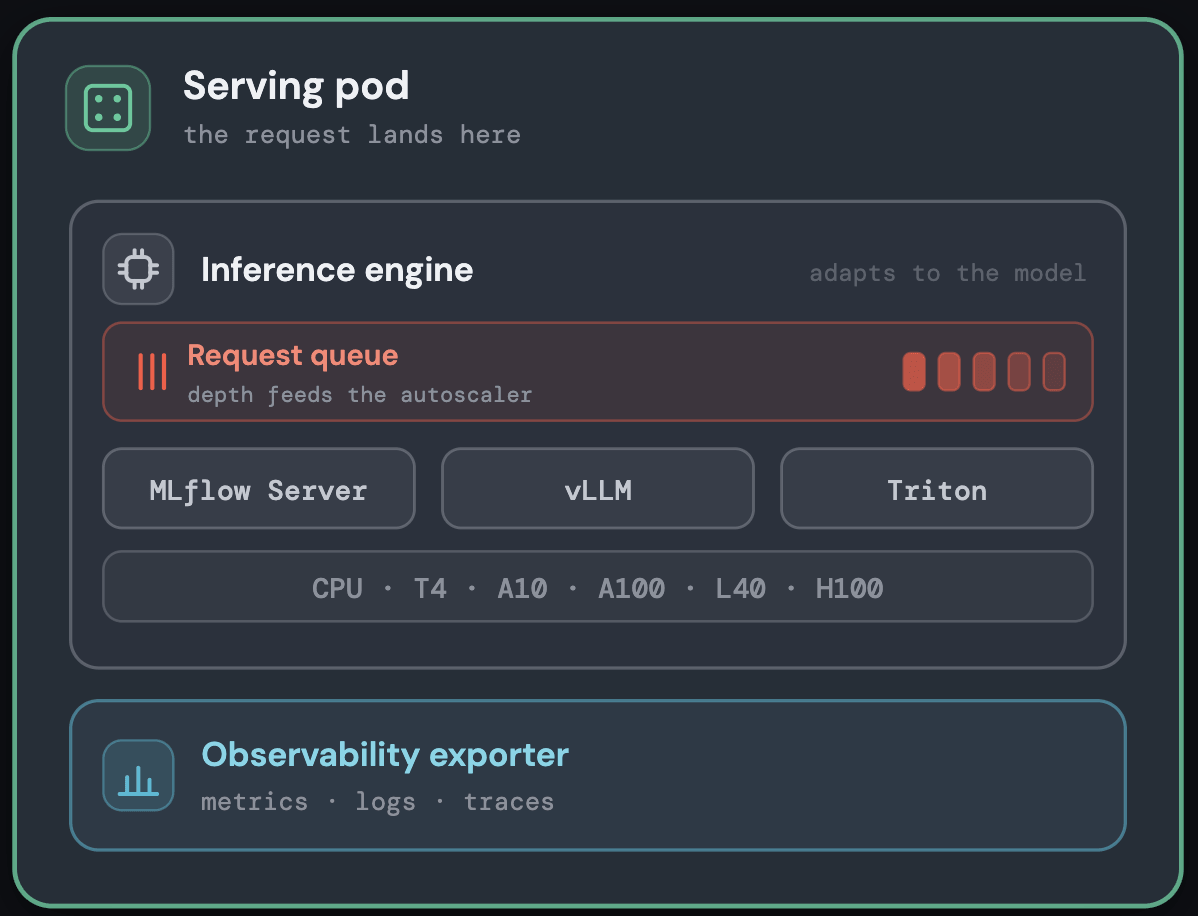
Selezione efficiente del runtime del modello
All'interno di ciascun pod, il modello viene eseguito sul motore di inferenza più adatto al suo tipo: un server MLflow Gunicorn asincrono per i modelli ML classici e motori ottimizzati per GPU per modelli di grandi dimensioni con supporto per vLLM, Triton o il runtime personalizzato del cliente, il tutto dietro un'unica interfaccia di serving uniforme.
L'abbinamento di ciascun modello al runtime corretto mantiene basso l'overhead per richiesta senza necessità di ottimizzazione manuale; i dettagli sono mostrati nel diagramma seguente.
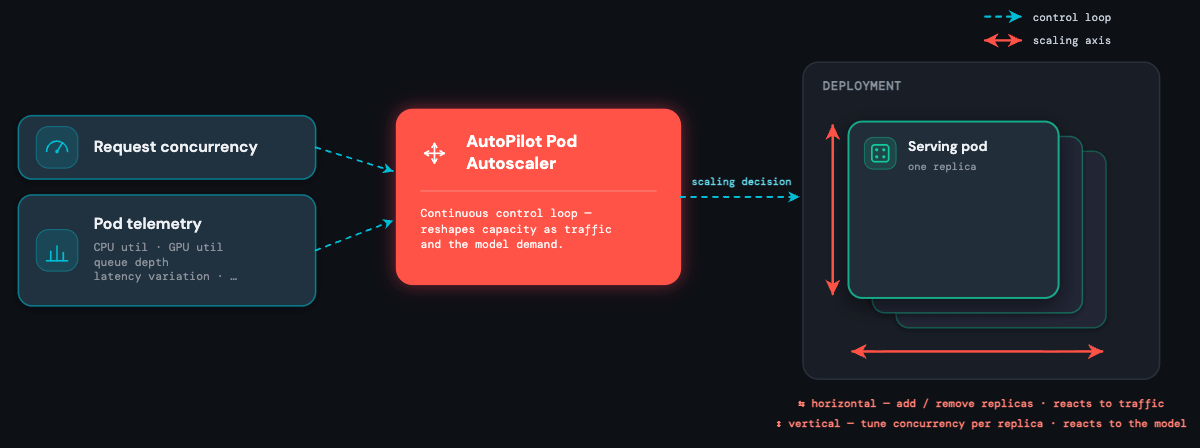
L'autoscaler: adattamento al modello e al traffico
Un controller Kubernetes personalizzato che abbiamo sviluppato, l'AutoPilot Pod Autoscaler (APA), si trova al centro della piattaforma. Raccoglie continuamente segnali dal load balancer (concorrenza attiva, profondità della coda) e dai pod stessi (utilizzo della CPU, utilizzo della GPU, memoria della GPU e molti altri), trasformandoli in decisioni di scalabilità.
L'autoscaler esiste per assorbire contemporaneamente due tipi di imprevedibilità:
- Il modello è imprevedibile. Non si conosce in anticipo il profilo delle risorse di un modello personalizzato. Un modello xgboost ad alto consumo di CPU potrebbe servire solo 1 richiesta per core, un agente può eseguire centinaia di richieste per core, mentre un LLM da 13B ottimizzato tramite fine-tuning trae vantaggio da più richieste raggruppate in batch. L'APA apprende il limite di ciascun modello a runtime e ottimizza il numero di richieste che ogni replica deve accettare: scaling verticale basato sul modello (model-aware).
- Il traffico è imprevedibile. Presenta picchi, improvvise impennate e scende a zero senza preavviso. Un endpoint per il rilevamento delle frodi può aumentare di 10 volte in pochi secondi all'inizio di un saldo; un caso d'uso specifico per una regione può attivarsi intensamente per un'ora e poi rimanere inattivo durante la notte. L'APA reagisce all'istante al variare della domanda: scaling orizzontale basato sulle richieste (request-based).
Ecco perché l'autoscaler è il cuore del sistema: è l'unico componente che gestisce contemporaneamente tutti e tre i vincoli (latenza, scalabilità e costi) per ogni modello sulla piattaforma.
Due assi di elasticità
Gli autoscaler tradizionali eseguono uno scaling basato sulle richieste o sulle risorse, ma ognuno presenta un punto debole. Lo scaling basato sulle richieste reagisce rapidamente ma è inefficiente: tratta ogni richiesta allo stesso modo, indipendentemente dal carico di ciascuna replica, con il rischio di sovradimensionare le risorse o causare continue oscillazioni nel numero di repliche. Lo scaling basato sulle risorse (utilizzo di CPU, GPU) è efficiente ma lento: le metriche di utilizzo seguono il traffico in ritardo, quindi quando l'autoscaler si attiva, il danno al p99 è già fatto.
L'APA utilizza entrambi i segnali contemporaneamente, sfruttando i punti di forza di ciascuno: ed è esattamente questo il ruolo dei due assi.
La scalabilità verticale model-aware reagisce alle caratteristiche del modello. Periodicamente, l'autoscaler analizza un insieme di metriche per determinare quanto carico una singola replica sia effettivamente in grado di gestire e adegua di conseguenza il parametro target_concurrency nella formula precedente. Questo approccio è fondamentalmente diverso dalla scalabilità verticale tradizionale, che modifica il tipo di hardware. In questo caso l'hardware rimane lo stesso: a cambiare è il numero di richieste simultanee accettate da ciascun pod, ottimizzato in base al profilo di risorse del modello in esecuzione su di esso.
Le metriche su cui ci basiamo includono, tra le altre:
- Metriche hardware — utilizzo di CPU e GPU, utilizzo della memoria, attesa I/O
- Latenza corrente e profilo della profondità della coda
- Metriche specifiche per le GPU — larghezza di banda della memoria, utilizzo di FLOPS FP16/BF16
Misure di salvaguardia. Le variazioni della concorrenza per nodo sono delicate e fluttuazioni ampie o frequenti possono compromettere le prestazioni del sistema. Le metriche dei pod possono oscillare a causa di brevi variazioni del traffico o quando il costo per richiesta varia notevolmente per un modello. Ci proteggiamo da questo rumore di fondo delle metriche. Un breve picco di CPU non dovrebbe ridurre immediatamente il limite di concorrenza per poi espanderlo di nuovo pochi secondi dopo. Per evitare questo problema, adottiamo tre accorgimenti:
La concorrenza viene regolata solo quando una metrica supera una soglia stabile, e le soglie sono ottimizzate per ciascuna metrica.
- Poniamo un limite alla variazione massima della concorrenza per ciclo decisionale
- Applichiamo sempre limiti minimi/massimi di concorrenza per un carico di lavoro
- Le variazioni di concorrenza avvengono con una frequenza inferiore (ogni 30 secondi) rispetto alla scalabilità orizzontale. Questo è importante anche perché si basano su metriche storiche anziché sul traffico corrente come l'HPA.
I due assi sono accoppiati: l'output di concorrenza della scalabilità verticale alimenta il calcolo della scalabilità orizzontale attraverso il denominatore target_concurrency. La scalabilità orizzontale garantisce disponibilità e bassa latenza nel momento in cui il traffico varia. La scalabilità verticale model-aware assicura che ogni nodo venga utilizzato in modo efficiente, dimensionando correttamente la concorrenza man mano che il comportamento del modello si evolve. Insieme, evitano la falsa scelta tra un sistema veloce ma dispendioso e uno efficiente ma lento.
Soglie di scale-up e scale-down
La formula HPA grezza non è sufficiente da sola: non è resiliente ai picchi improvvisi di traffico. Un breve picco di 10 volte calcola un aumento di 10 volte delle repliche; un breve calo del 95% calcola una riduzione del 95%. Entrambi gli scenari sono pericolosi, sia in termini di costi che di latenza e disponibilità.
Lo scale-up orizzontale è aggressivo In produzione, un'elevata latenza può avere un impatto aziendale fortemente negativo. Molti casi d'uso presentano per loro natura pattern di traffico con picchi improvvisi che è fondamentale supportare. Per gestire questi picchi, monitoriamo le richieste in arrivo ogni secondo e l'APA prende una decisione di upscaling ogni 5 secondi in base al traffico degli ultimi 20 secondi. Questo riduce significativamente le code e gli errori 429 durante i picchi — molti clienti hanno riscontrato una differenza fino a 5 volte. Limitiamo inoltre l'entità dello scale-up in un singolo ciclo rispetto al carico corrente. Complessivamente, possiamo passare da 10 a 10K qps in meno di 60 secondi (a seconda del tempo di caricamento del modello)
Lo scale-down è conservativo. Un picco spesso segnala l'arrivo di ulteriore traffico. Per lo scale-down, l'APA decide comunque ogni 5 secondi, ma considera il traffico degli ultimi ~5 minuti prima di rimuovere le repliche.
L'asimmetria è intenzionale. I picchi sono improvvisi; i cali sono spesso temporanei. Il costo di uno scale-down prematuro (un cold start nel peggior momento possibile) supera di gran lunga il costo del mantenimento temporaneo di alcune repliche inattive.
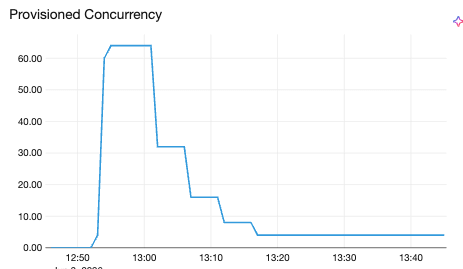
Scale-up e scale-down della concorrenza verticale. La stessa filosofia asimmetrica si applica alla scalabilità verticale: agire rapidamente per ridurre la concorrenza quando un pod mostra segni di sovraccarico (reindirizzare meno richieste a una replica già carica protegge la latenza), ma mai al di sotto di un valore minimo. Queste decisioni vengono eseguite a intervalli di 30 secondi, più lentamente rispetto al ciclo orizzontale di 5 secondi. Questo è intenzionale: la scalabilità verticale è un'ottimizzazione dello stato stazionario che si adatta al profilo di risorse di un modello nel tempo, non una reazione in tempo reale ai picchi.
Minimizzare i tempi di cold start
Un cold start è il peggior evento di latenza in un sistema di serving; non è possibile risolverlo con l'ottimizzazione una volta che si sta già verificando. Lo affrontiamo su due fronti: mantenere il più possibile pre-riscaldato (pre-warmed) e rendere le parti inevitabili il più veloci possibile.
Pool di nodi warm. Un algoritmo predittivo mantiene un pool di nodi pre-provisionati per ciascun cluster Databricks, precaricati con l'immagine di runtime di base. Quando l'autoscaler aggiunge una replica, attinge da questo pool: il nodo è già attivo, l'immagine di base è già stata scaricata e l'unico lavoro rimanente è il download del modello. Non addebitiamo ai clienti i costi per la capacità del pool warm; si tratta di un valore diretto che ottengono da Databricks.
Download rapido del modello. Le immagini dei container dei modelli sono memorizzate in un livello di cache calda (hot cache) nello storage cloud e scaricate in blocchi paralleli all'avvio del pod, riducendo significativamente il tempo di download dell'immagine per i container di modelli di grandi dimensioni. Le modifiche alla configurazione che non influiscono sul modello o sulle sue dipendenze (aggiornamenti dei metadati dell'endpoint, modifiche alle regole di routing) vengono applicate senza riavviare affatto il pod, poiché un riavvio evitato è il miglior avvio possibile.
Concorrenza allocata (provisioned concurrency). Per gli endpoint critici per la latenza che non possono tollerare alcun cold start, gli utenti configurano un livello minimo di concorrenza. Questo mantiene una base di pod completamente pronti con il modello caricato e pronti a rispondere immediatamente, senza code alla prima richiesta.
Aggiornamenti e manutenzione senza tempi di inattività (zero-downtime). Gli aggiornamenti e la manutenzione sono completamente a zero-downtime. Tutti i pod con la nuova versione del modello sono attivi e pronti prima che il traffico venga spostato dai vecchi pod.
Cosa abbiamo imparato in produzione
I clienti hanno riscontrato vantaggi sotto ogni aspetto:
- Costi: abbiamo clienti che hanno ottenuto risparmi sui costi superiori al 90% rispetto ai loro carichi di lavoro DIY.
- Latenza: la latenza p99 e p50 è migliorata fino a 2 volte per molti clienti.
- Scalabilità: i clienti hanno raggiunto oltre 100K QPS in produzione con una manutenzione minima o nulla.
- Garantiamo una disponibilità del 99,99% in produzione.
L'autoscaling a due assi si generalizza a tutti i tipi di modello. Non eravamo certi che l'approccio orizzontale + verticale avrebbe funzionato per qualsiasi cosa, dai classificatori CPU ai modelli LLM su GPU. E invece funziona: l'asse orizzontale gestisce il traffico allo stesso modo per ogni modello, mentre l'asse verticale si assesta su una concorrenza più elevata per i modelli leggeri e più bassa per quelli ad alto consumo di GPU. Stesso controller, stessa logica, il comportamento corretto per ciascuno.
La maggior parte dei modelli è omogenea. Pensavamo che i limiti di concorrenza avrebbero oscillato costantemente con il traffico; in pratica, il profilo di risorse di un modello sotto lo stesso carico rimane per lo più simile. L'asse verticale dimostra il suo valore durante la fase iniziale (onboarding), per poi stabilizzarsi.
Non è possibile eliminare del tutto i cold start con l'ottimizzazione. Ci aspettavamo che i pool warm, i download paralleli delle immagini e il riutilizzo dei deployment riducessero i cold start quasi a zero. Aiutano enormemente, ma la fisica ha un limite invalicabile: l'attivazione di un pod richiede un tempo che cresce con le dimensioni del modello, arrivando a diversi minuti per i modelli GPU di grandi dimensioni. Oltre questo limite, l'unica soluzione è mantenere una capacità minima completamente pronta, che è esattamente il motivo per cui esiste la concorrenza allocata (provisioned concurrency) minima.
Il traffico è più prevedibile di quanto sembri. Il minimo corretto non è statico: le app B2C registrano un calo di attività durante la notte, le pipeline batch si avviano secondo pianificazioni precise. Questi pattern possono essere appresi, e stiamo sviluppando funzionalità di previsione del traffico per aumentare la concorrenza minima prima che si verifichi la domanda, anziché rincorrerla. Continuate a seguirci per saperne di più.
Conclusione
Ci siamo prefissati di eliminare la ML Stack Tax: la continua ricalibrazione e la necessità di un team di serving dedicato. Per l'intera gamma di modelli attualmente in esecuzione su Custom Model Serving, l'autoscaler a due assi, i pool warm e i deployment a zero-downtime fanno esattamente questo. L'infrastruttura si adatta al modello, anziché il contrario. È sufficiente fornire un modello, impostare un intervallo di concorrenza e la piattaforma gestirà tutto il resto.
Tuttavia, il model serving non è ancora un campo del tutto risolto. Modelli più grandi, nuovo hardware e carichi di lavoro agentici continuano a spingere la scalabilità e la complessità oltre i limiti per cui è stata concepita l'infrastruttura di serving tradizionale. I problemi aperti sono reali e l'ambizione è alta: tempi di cold start inferiori, previsione del traffico per una scalabilità predittiva, oltre 1M QPS per endpoint e oltre 10M QPS per cluster, un bin-packing più intelligente dei carichi di lavoro GPU eterogenei e la riduzione della latenza p99 al di sotto dei 5 ms.
E questo è un problema che Databricks è in una posizione unica per risolvere. Adattare l'infrastruttura a un modello significa conoscere il modello: come è stato addestrato, da cosa dipende e come si comporta sotto carico. Su Databricks tutto questo vive in un'unica piattaforma governata: dati e feature, addestramento, packaging MLflow, serving, agenti e la telemetria che li monitora. Un livello di serving autonomo vede un container; noi vediamo l'intero ciclo di vita. Questo contesto è ciò che consente alla piattaforma di adattarsi a ogni modello, ed è il motivo per cui nessun prodotto di serving aggiuntivo può eliminare altrettanto bene la ML Stack Tax.
Se questo tipo di problemi infrastrutturali ti interessa, stiamo assumendo.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.