Fornire contenuti di marketing generativi ai clienti
Combinare i dati dei clienti e l'AI generativa per connettersi meglio con i clienti, Parte 2
di Camden Clark, Joyce Gordon, Ally Hepp, Alex Rees, Tristen Wentling e Bryan Smith
- Personalizzazione scalabile: l'AI generativa automatizza la creazione di contenuti di marketing personalizzati utilizzando i dati dei clienti provenienti da Databricks e Amperity.
- Integrazione fluida: Amperity sincronizza i dati del pubblico con Braze, consentendo una distribuzione precisa dei contenuti tramite Cloud Data Ingestion.
- Consegna dinamica delle e-mail: i template Liquid in Braze personalizzano l'oggetto e il corpo delle e-mail, migliorando il coinvolgimento e le conversioni.

I marketer sognano da tempo un coinvolgimento personalizzato uno a uno, ma creare il volume di messaggi necessario per una personalizzazione a questo livello è sempre stata una grande sfida. Sebbene molte organizzazioni puntino a un marketing più personalizzato, spesso si rivolgono a vasti gruppi di migliaia o milioni di clienti, all'interno dei quali esiste ancora una grande diversità. Anche se questo è meglio di un approccio generico e uguale per tutti, le organizzazioni preferirebbero essere più precise, se solo avessero le risorse per interagire a un livello più granulare.
Come accennato nel nostro blog precedente, l'AI generativa può aiutare a semplificare la creazione di contenuti di marketing altamente personalizzati. Sebbene raggiungere un vero coinvolgimento uno a uno possa essere ancora difficile a causa di alcune limitazioni della tecnologia allo stato attuale, combinare i dettagli dei clienti con contenuti di esempio e un prompt engineering intelligente può essere utile per creare in modo economico un volume gestibile di varianti personalizzate. L'applicazione di modelli indipendenti per valutare il contenuto generato prima che passi alla revisione finale da parte di un marketer esperto può contribuire notevolmente a garantire che questo contenuto più granulare soddisfi gli standard aziendali e sia allineato in modo più preciso alle esigenze e alle preferenze di uno specifico sottosegmento.
Ma come possiamo trasformare tutto questo in un workflow affidabile? E, soprattutto, come facciamo a far arrivare concretamente tutte queste varianti di contenuto ai clienti target utilizzando le nostre tecnologie di marketing esistenti? In questo post, continuiamo a sviluppare lo scenario della guida ai regali di Natale introdotto nel blog precedente e mostriamo un workflow end-to-end per la distribuzione di contenuti via email con Amperity e Braze, due piattaforme ampiamente adottate nello stack MarTech aziendale.
Generazione dei contenuti
Nel nostro blog precedente, abbiamo visto come creare un prompt in grado di attivare un modello di AI generativa per creare un'email di marketing personalizzata in base agli interessi di un sottosegmento di pubblico. Il prompt utilizzava un'email di esempio come guida e poi richiedeva al modello di modificare il contenuto per farlo risuonare meglio con un pubblico con specifiche sensibilità al prezzo e preferenze di attività (Figura 1).
Figura 1. Il prompt sviluppato per la creazione di una guida ai regali di Natale personalizzata
Per applicare questo prompt su scala, dobbiamo rimuovere gli elementi specifici del cliente (come la sottocategoria di prodotto e le preferenze di prezzo in questo esempio) e inserire dei segnaposto in cui questi elementi possano essere inseriti all'occorrenza, creando un modello di prompt. I dettagli specifici del cliente possono quindi essere inseriti nel prompt basato su modello (ospitato nell'ambiente Databricks) insieme ai dettagli del cliente memorizzati nella customer data platform (CDP).
Poiché per la nostra dimostrazione utilizziamo Amperity come CDP, l'integrazione è un processo piuttosto semplice. Utilizzando la funzionalità Amperity Bridge, creata utilizzando il protocollo open source Delta Sharing supportato dall'ambiente Databricks, creiamo semplicemente una connessione tra le due piattaforme ed esponiamo le informazioni appropriate (Figura 2). (I passaggi dettagliati per la configurazione della connessione bridge sono disponibili qui.)
Figura 2. Una video guida su come connettersi a Databricks tramite Amperity Bridge
Il passaggio successivo consiste nell'interrogare i dati memorizzati nella CDP, accessibili all'interno di Databricks, per raccogliere i dettagli di ciascun sottosegmento. Una volta definiti, possiamo passare le informazioni associate a ciascuno di essi nel nostro prompt per generare messaggi personalizzati. Una volta salvati, possiamo quindi iterare sull'output, valutando ogni messaggio generato in base a vari criteri prima che il contenuto e i risultati della valutazione vengano presentati a un marketer per la revisione finale e l'approvazione (Figura 3).
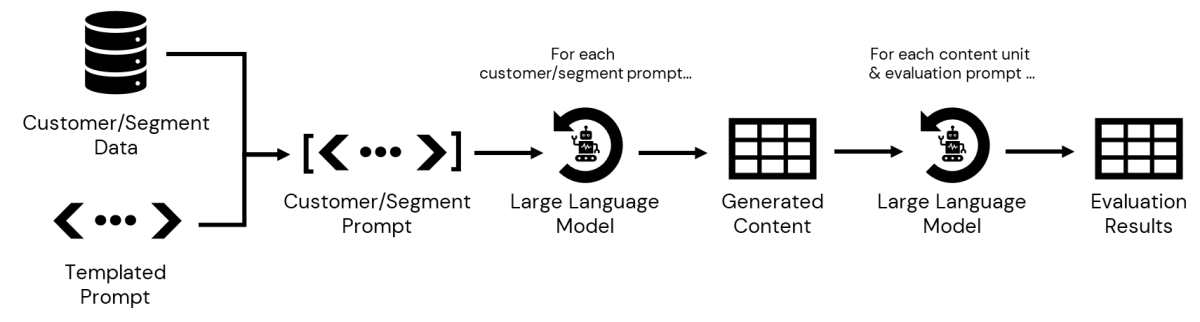
{kind=link}
Il risultato finale di questo processo è una tabella di varianti di contenuto, una per ogni combinazione di fascia di prezzo preferita e sottocategoria di prodotto, insieme a una tabella di output di valutazione per ogni fase di valutazione. I dati sono ora pronti per la revisione da parte del marketer.
NOTA Per un'implementazione tecnica dettagliata del workflow della Figura 3, consulta questo notebook.
Distribuzione dei contenuti
Una volta create le varianti di contenuto, possiamo dedicarci alla distribuzione. I dettagli esatti su come procedere in questa fase dipendono dalla specifica piattaforma di distribuzione utilizzata. Per la nostra dimostrazione, vedremo come distribuire questo contenuto utilizzando Braze, una piattaforma di Customer Engagement leader del settore e ampiamente adottata dalle organizzazioni di marketing.
A livello generale, i passaggi necessari per distribuire questo contenuto tramite Braze sono i seguenti:
- Inviare le varianti di contenuto a Braze
- Identificare i membri del pubblico che devono ricevere il contenuto
- Collegare i membri del pubblico a specifiche varianti di contenuto
Inviare le varianti di contenuto a Braze
All'interno di Braze, il contenuto utilizzato come parte di una campagna viene definito come un Braze Catalog. Utilizzando Braze Cloud Data Ingestion, questo contenuto può essere letto da Databricks, a condizione che sia presentato all'interno di una tabella o vista contenente un identificatore univoco (ID), un campo datetime che indica l'ultimo aggiornamento del contenuto (UPDATED_AT) e un payload JSON (PAYLOAD) con elementi titolo e corpo che verranno utilizzati per creare il contenuto distribuito.
Per illustrare come potremmo costruire questo dataset, ipotizziamo che l'output del nostro workflow di generazione dei contenuti (come illustrato nella Figura 4) abbia prodotto una tabella di contenuti con la seguente struttura, in cui preferred_price_point e holiday_preferred_subcategory rappresentano i dettagli del sottosegmento univoci per ogni record della tabella:
Possiamo definire una vista su questa tabella per strutturarla per la distribuzione come Braze Catalog nel modo seguente:
All'interno di Braze, ora possiamo definire un catalogo per questo contenuto (Figura 3).
Figura 3. Il Braze Catalog destinato a ospitare i nostri contenuti generati
Configuriamo quindi una sincronizzazione Cloud Data Ingestion (CDI), collegando la vista Databricks alla struttura del Braze Catalog e la configuriamo per la sincronizzazione, assicurandoci che rimanga aggiornata (Figura 4).
Figura 4. La sincronizzazione Cloud Data Ingestion (CDI) che mappa il Braze Catalog sulla vista dei contenuti Databricks
Identificare i membri del pubblico
Ora abbiamo bisogno dei dettagli delle persone a cui intendiamo inviare questo contenuto. Poiché il nostro obiettivo è inviare questo contenuto via e-mail, avremo bisogno degli indirizzi e-mail dei destinatari target. Potrebbero essere necessari anche elementi come il nome e il cognome, in modo che il contenuto possa essere indirizzato al destinatario in modo più personalizzato. Inoltre, avremo bisogno di dettagli su come le persone sono allineate con le preferenze relative alla sottocategoria di prodotto e al prezzo. Quest'ultimo elemento sarà essenziale per collegare i membri del pubblico alle specifiche varianti di contenuto ospitate nel Braze Catalog.
Poiché utilizziamo Amperity como CDP, inviare queste informazioni a Braze è semplicissimo: basta definire il gruppo di destinatari come pubblico e utilizzare il connettore Amperity per trasmettere questi dettagli (Figura 5).
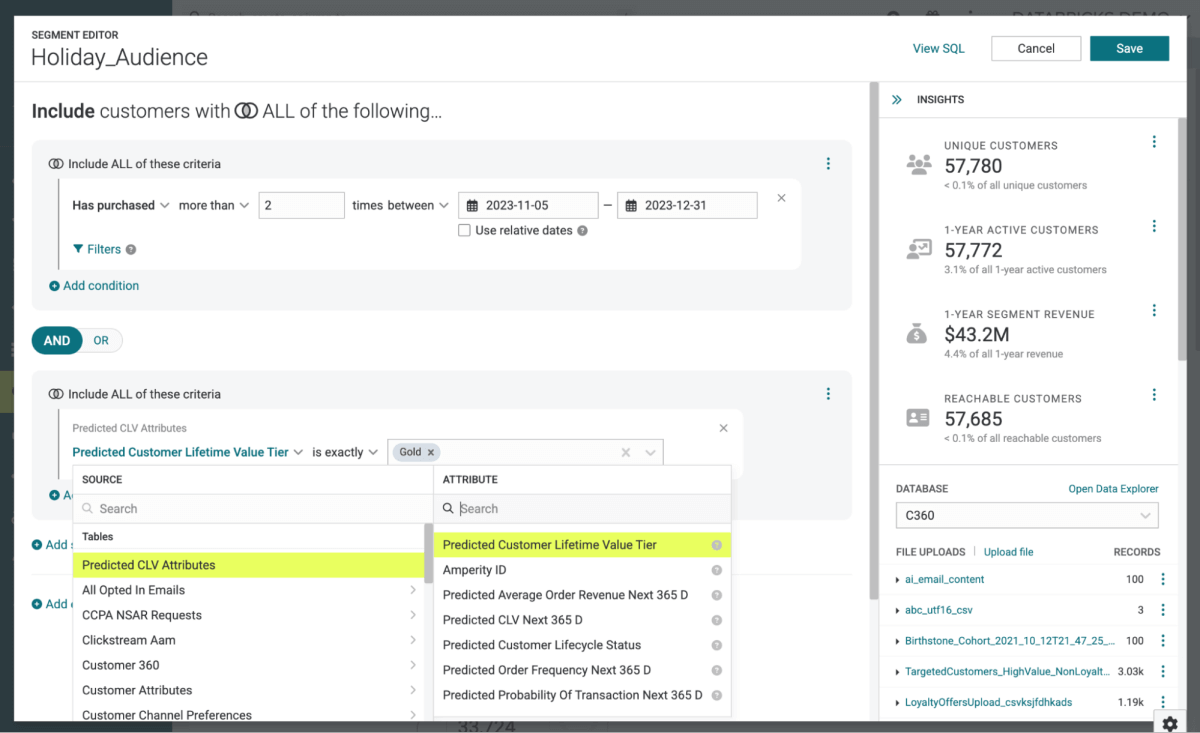
{kind=link}
Collegare i membri del pubblico alle varianti di contenuto
Con tutti gli elementi al loro posto all'interno di Braze, ora possiamo collegare i membri del pubblico a specifiche varianti di contenuto e programmare l'invio. Questo viene fatto all'interno di Braze utilizzando il templating Liquid, un linguaggio di template open source sviluppato da Shopify e scritto in Ruby. Questo linguaggio è altamente accessibile ai professionisti del marketing e consente loro di definire contenuti personalizzabili per la distribuzione su larga scala.
Per iniziare
Databricks viene utilizzato sempre più spesso all'interno delle aziende come hub centrale per le funzionalità di dati e analytics. Grazie alle funzionalità di AI generativa integrate e altamente estensibili, nonché alla profonda integrazione con una varietà di piattaforme complementari come la CDP Amperity e la Customer Engagement Platform di Braze, le organizzazioni stanno creando un'ampia gamma di applicazioni, come quella dimostrata in questo blog, con Databricks al centro.
Se desideri saperne di più su come utilizzare Databricks per aiutare i tuoi team di marketing a creare e offrire contenuti più personalizzati ai tuoi clienti, contattaci per discutere le numerose opzioni disponibili per lo sviluppo di soluzioni che utilizzano la piattaforma.
Questo processo sfrutta diversi componenti chiave e utilizza il seguente workflow:
- Struttura e importazione dei contenuti
- Viene creata una vista dalla tabella delle varianti di contenuto, strutturata per l'uso da parte di Braze Cloud Data Ingestion
- Viene creato un Braze Catalog come repository per le varianti di contenuto
- Viene configurata una sincronizzazione Cloud Data Ingestion e Braze sincronizza le varianti di contenuto dalla vista al catalogo
- Attivazione del pubblico Amperity - Amperity sincronizza il pubblico di utenti per i quali è stato creato il contenuto su Braze per un targeting preciso.
- Costruzione della campagna e templating Liquid
- Il linguaggio di templating Liquid viene utilizzato per fare riferimento alla riga corrispondente nel catalogo delle varianti di contenuto.
- Liquid popola dinamicamente l'oggetto e il corpo dell'e-mail, personalizzati per ciascun utente.
Passo 3: Costruzione della campagna e templating Liquid
La fase finale prevede la creazione della campagna Braze.
Il templating Liquid svolge un ruolo fondamentale in questo contesto, consentendo l'inserimento dinamico del contenuto generato in base agli attributi dell'utente memorizzati nei profili Braze. A questi attributi, sincronizzati tramite l'attivazione di Amperity, viene fatto riferimento per creare un ID riga del catalogo corrispondente. Questo ID viene quindi utilizzato per recuperare e inserire l'oggetto e il corpo del testo generati nell'e-mail.
3a. Email Subject LineUsing Liquid filters, we combine the `preferred_price_point` and `holiday_preferred_subcategory` attributes, separated by an underscore, to create a local `identifier` variable:
Questo `identifier` generato dinamicamente viene quindi utilizzato per fare riferimento all'ID corrispondente nel catalogo HolidayGenAI:
Figura 5. Screenshot delle impostazioni di invio con Liquid
Per un utente con un `preferred_price_point` pari a high e `holiday_preferred_subcategory` pari a Hiking, l'output Liquid risultante nell'oggetto dell'e-mail sarà derivato dal titolo dell'elemento del catalogo corrispondente:
Figura 6. Elemento del catalogo che mostra la riga pertinente
3b. Corpo del testo dell'e-mail
Possiamo seguire lo stesso approccio per inserire il contenuto generato nel corpo dell'e-mail.
Il risultato finale è un'e-mail che estrae dinamicamente il contenuto generativo dell'e-mail, personalizzato in base alla fascia di prezzo e alla sottocategoria preferite di ciascun utente, favorendo un migliore coinvolgimento e tassi di conversione più elevati.
Figura 7. Screenshot dell'e-mail
Questo caso d'uso potrebbe essere ulteriormente esteso per includere l'aggiunta di immagini generative o persino l'utilizzo di Connected Content per interrogare direttamente un endpoint Databricks al momento dell'invio.
Per un'implementazione tecnica dettagliata del workflow nella Figura 3, consulta questo notebook.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.