Delta UniForm: un formato universale per l'interoperabilità del lakehouse
di Bilal Obeidat, Sirui Sun, Adam Wasserman, Susan Pierce, Fred Liu, Ryan Johnson e Himanshu Raja
Aggiornamento: BigQuery ora offre il supporto nativo per Delta Lake tramite BigLake. Consulta la documentazione per maggiori informazioni.
Una delle sfide principali che le organizzazioni devono affrontare nell'adozione dell'open data lakehouse è la scelta del formato ottimale per i propri dati. Tra le opzioni disponibili, Linux Foundation Delta Lake, Apache Iceberg e Apache Hudi sono tutti eccellenti formati di archiviazione che abilitano la democratizzazione e l'interoperabilità dei dati. Qualsiasi di questi formati è migliore rispetto all'inserimento dei dati in un formato proprietario. Tuttavia, scegliere un singolo formato di archiviazione su cui standardizzare può essere un compito arduo, che può portare a affaticamento decisionale e paura di conseguenze irreversibili.
Delta UniForm (abbreviazione di Delta Lake Universal Format) offre un'unificazione semplice, facile da implementare e senza interruzioni dei formati di tabella senza creare copie di dati o silos aggiuntivi. In questo blog, tratteremo i seguenti argomenti:
- Un'introduzione a Delta UniForm e ai suoi vantaggi
- Lettura di Delta UniForm come tabelle Iceberg utilizzando
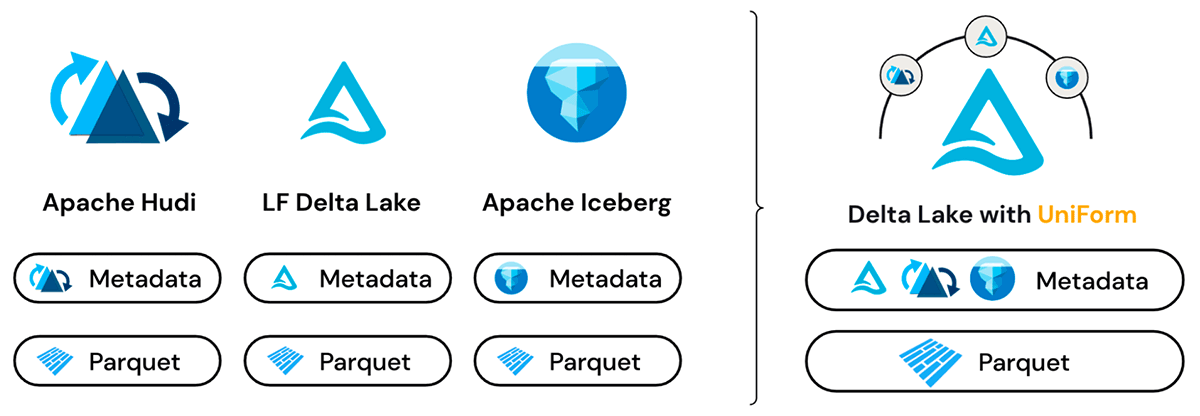
Formati multipli, singola copia dei dati
Delta UniForm sfrutta il fatto che Delta Lake, Iceberg e Hudi sono tutti basati su file di dati Apache Parquet. La differenza principale tra i formati risiede nel livello dei metadati e, anche in questo caso, le differenze sono sottili. I metadati per tutti e tre i formati servono allo stesso scopo e contengono set di informazioni sovrapposti.
Prima del rilascio di Delta UniForm, i modi per passare da un formato di tabella aperto all'altro si basavano sulla copia o sulla conversione e fornivano solo una visione dei dati al momento della conversione. Al contrario, Delta UniForm risolve le esigenze di interoperabilità in modo più elegante fornendo una visione live dei dati per tutti i lettori, indipendentemente dal formato.
Sotto il cofano, Delta UniForm funziona generando automaticamente i metadati per Iceberg e Hudi insieme a Delta Lake, il tutto su una singola copia dei dati Parquet. Di conseguenza, i team possono utilizzare lo strumento più adatto per ogni carico di lavoro dati e operare tutti su una singola origine dati, con perfetta interoperabilità tra i tre diversi ecosistemi.
Configurazione rapida, overhead minimo
Delta UniForm è estremamente facile da configurare e, una volta abilitato, funziona in modo fluido e automatico.
Per iniziare, creiamo una tabella Delta UniForm per generare i metadati Iceberg:
Con le tabelle Delta UniForm, i metadati per i formati aggiuntivi vengono creati automaticamente al momento della creazione della tabella e aggiornati ogni volta che la tabella viene modificata. Ciò significa che non è necessario eseguire comandi di aggiornamento manuali o utilizzare risorse computazionali non necessarie per tradurre i formati delle tabelle. Ad esempio, scriviamo una riga in questa tabella:
Questo comando attiva un commit di Delta Lake, che quindi genera automaticamente e in modo asincrono i metadati Iceberg per questa tabella. In questo modo, Delta UniForm garantisce che le pipeline di dati non vengano interrotte, consentendo un accesso fluido alle informazioni più aggiornate per tutti i lettori.
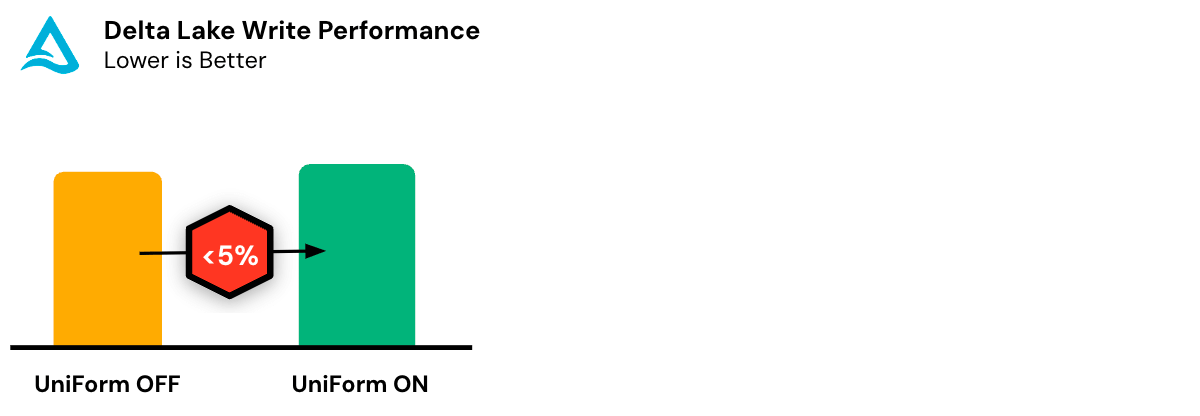
Delta UniForm ha un overhead di prestazioni e risorse trascurabile, garantendo un utilizzo ottimale delle risorse computazionali. Anche per tabelle su scala petabyte, i metadati rappresentano tipicamente una piccola frazione della dimensione dei file di dati. Inoltre, Delta UniForm è in grado di generare in modo incrementale i metadati limitati solo alle modifiche dall'ultimo commit.
Lettura di Delta UniForm come Iceberg
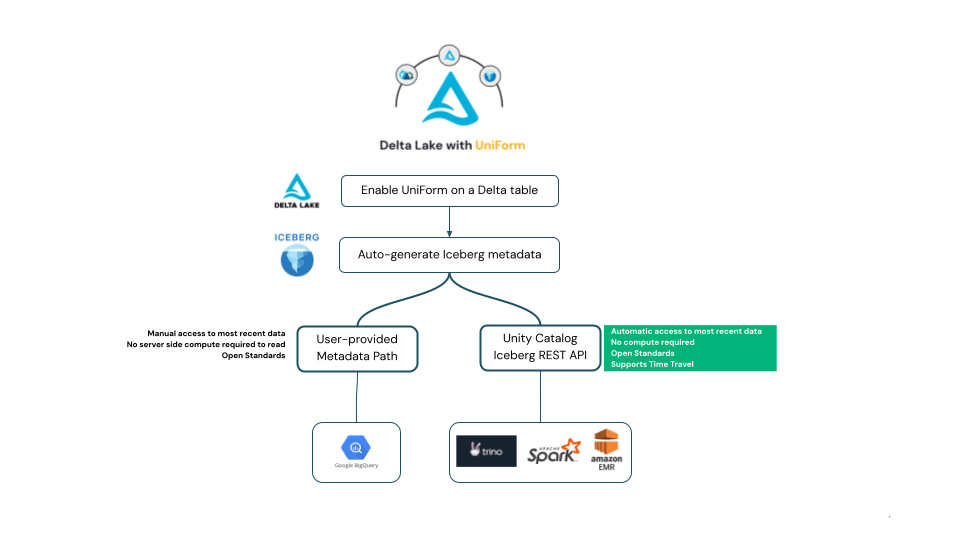
Delta UniForm genera metadati Iceberg in conformità con la specifica Apache Iceberg, il che significa che quando i dati vengono scritti in una tabella Delta UniForm, la tabella può essere letta come Iceberg da qualsiasi client nell'ecosistema Iceberg che aderisce alla specifica open source Iceberg.
Secondo la specifica Iceberg, i client di lettura devono determinare quali metadati Iceberg rappresentano la versione più recente e aggiornata della tabella Iceberg. Nell'ecosistema Iceberg, abbiamo visto i client adottare due approcci diversi a questo, entrambi supportati da UniForm. Spiegheremo le differenze qui e poi forniremo esempi nella sezione successiva.
Alcuni lettori Iceberg richiedono agli utenti di fornire il percorso a un file di metadati che rappresenta l'ultimo snapshot della tabella Iceberg. Questo approccio può essere complicato per i clienti poiché richiede agli utenti di fornire percorsi aggiornati ai file di metadati ogni volta che la tabella cambia.
In alternativa, la community Iceberg consiglia di utilizzare l'API REST del catalogo. Il client comunica con il catalogo per ottenere lo stato più recente della tabella, consentendo agli utenti di leggere lo stato più recente di una tabella Iceberg senza aggiornamenti manuali o preoccupazioni sui percorsi dei metadati.
Unity Catalog implementa ora l'API REST aperta del catalogo Iceberg in conformità con la specifica Apache Iceberg. Questo è in linea con l'impegno di Unity Catalog nel supportare API aperte, e si basa sullo slancio del supporto dell'API HMS di Unity Catalog. L'API REST Iceberg di Unity Catalog offre accesso aperto alle tabelle UniForm in formato Iceberg senza costi aggiuntivi per il calcolo Databricks, consentendo al contempo interoperabilità e supporto di aggiornamento automatico per l'accesso ai dati più recenti. Come sottoprodotto, ciò dovrebbe consentire ad altri cataloghi di federarsi a Unity Catalog e supportare le tabelle Delta UniForm.
Le librerie client Apache Iceberg sono pre-confezionate con la capacità di interfacciarsi con il catalogo API REST Iceberg, il che significa che qualsiasi client che implementa completamente lo standard Apache Iceberg e supporta la configurazione degli endpoint del catalogo dovrebbe essere in grado di accedere facilmente al catalogo API REST Iceberg di Unity Catalog e recuperare i metadati più recenti per le proprie tabelle. Questo elimina il compito di gestire i metadati delle tabelle.
Nella prossima sezione, esamineremo esempi del supporto di Delta UniForm per entrambi gli approcci: percorso dei metadati e API REST del catalogo Iceberg.
Esempio: lettura di Delta Lake come Iceberg in BigQuery fornendo la posizione dei metadati
Quando legge Iceberg in un catalogo esistente, BigQuery richiede di fornire un puntatore al file JSON che rappresenta l'ultimo snapshot Iceberg (documentazione BigQuery), come il seguente:
In BigQuery:
Delta UniForm con Unity Catalog semplifica la ricerca del percorso del file di metadati Iceberg richiesto. Unity Catalog espone diverse proprietà della tabella Delta Lake, incluso questo percorso. È possibile recuperare la posizione dei metadati per la propria tabella Delta UniForm tramite UI o API.
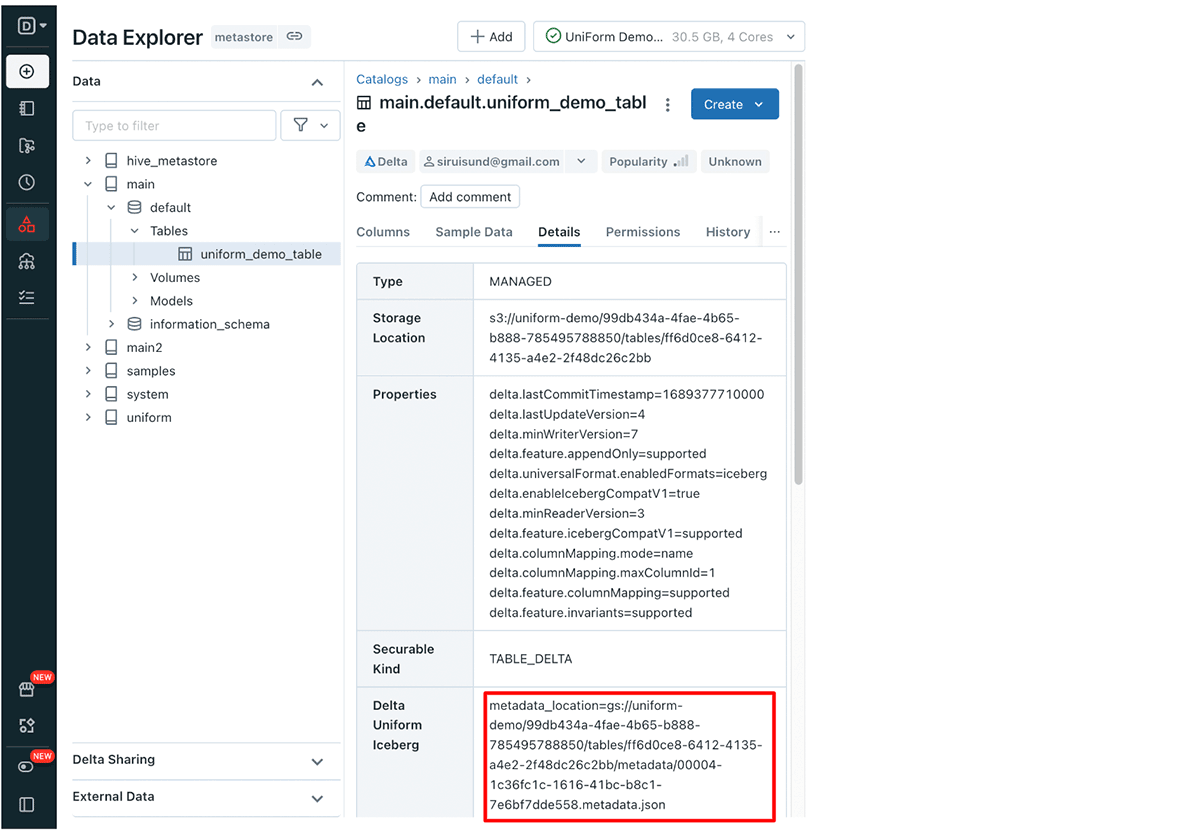
Recupero del percorso dei metadati Iceberg di Delta UniForm tramite UI:
Naviga alla tua tabella Delta UniForm nel Databricks Data Explorer, quindi fai clic sulla scheda Dettagli. Qui troverai la riga Delta UniForm Iceberg contenente il percorso dei metadati.
In Databricks:
Recupero della posizione dei metadati Iceberg di Delta UniForm tramite API:
Da uno strumento a tua scelta, invia la seguente richiesta GET per recuperare la posizione dei metadati Iceberg della tua tabella Delta UniForm.
Il campo delta_uniform_iceberg.metadata_location nella risposta contiene la posizione dei metadati per l'ultimo snapshot Iceberg.
Basta incollare la posizione dall'interfaccia utente o dai metodi API descritti in precedenza nel comando BigQuery menzionato, e BigQuery leggerà lo snapshot come Iceberg.
Se la tua tabella viene aggiornata, dovrai fornire a BigQuery la posizione dei metadati aggiornati per leggere i dati più recenti. Per i casi d'uso di produzione, dovresti aggiungere un passaggio nella tua pipeline di ingestione che aggiorni BigQuery con i percorsi dei metadati Iceberg più recenti ogni volta che scrivi sulla tabella Delta UniForm. Nota che la necessità di aggiornare i percorsi dei metadati è una limitazione generale di questo approccio e non è specifica di UniForm.
Esempio: Leggere Delta Lake come Iceberg in Trino tramite l'API REST Catalog
Leggiamo ora la stessa tabella Delta UniForm creata in precedenza tramite Trino utilizzando l'API REST Catalog Iceberg di Unity Catalog.
Nota: UniForm non è necessario per leggere le tabelle Delta con Trino poiché Trino supporta direttamente le tabelle Delta. Questo serve solo a illustrare come UniForm espande ulteriormente l'interoperabilità nell'ecosistema open source.
Dopo aver configurato Trino, puoi regolare le proprietà di Iceberg aggiornando il file etc/catalog/iceberg.properties per configurare Trino affinché utilizzi l'endpoint del catalogo API REST Iceberg di Unity Catalog:
Dove:
- UNITY_CATALOG_ICEBERG_URL - l'URL dell'endpoint API REST Iceberg di Unity Catalog - assume la forma: https://{DATABRICKS_WORKSPACE_URL}/api/2.1/unity-catalog/iceberg
- DATABRICKS_WORKSPACE_URL - l'URL del tuo workspace Databricks, che puoi trovare navigando nel tuo workspace Databricks in un browser web; assume la forma: mydatabricksworkspace.cloud.databricks.com/?o=1231231231231231
- PERSONAL_ACCESS_TOKEN - un token di accesso personale Databricks che può essere generato in un workspace Databricks secondo queste istruzioni
Una volta configurato il file delle proprietà, puoi eseguire la CLI di Trino ed emettere una query Iceberg sulla tabella Delta UniForm:
Poiché Trino implementa l'API REST Catalog di Apache Iceberg, non abbiamo creato alcuna tabella esterna, né abbiamo dovuto fornire il percorso ai file di metadati Iceberg più recenti. Trino recupera automaticamente i metadati Iceberg più recenti da UC e quindi legge i dati più recenti nella tabella Delta UniForm.
È importante notare che, dal punto di vista di Trino, non sta succedendo nulla di specifico di Delta UniForm. Sta leggendo una tabella Iceberg, i cui metadati sono stati generati secondo le specifiche, e recupera tali metadati con una chiamata API REST standard a un catalogo Iceberg.
Questa è la semplicità di Delta UniForm. Per gli scrittori e i lettori di Delta Lake, la tabella Delta UniForm è una tabella Delta Lake. Per i lettori Iceberg, la tabella Delta UniForm è una tabella Iceberg, il tutto su un unico set di file di dati senza copie non necessarie di dati e tabelle.
Impatto di Delta UniForm
Durante la sua anteprima, abbiamo già aiutato molti clienti ad accelerare verso l'interoperabilità open data lakehouse con Delta UniForm. Le organizzazioni possono scrivere una volta su Delta Lake e quindi accedere a questi dati in qualsiasi modo, ottenendo prestazioni ottimali, efficienza dei costi e flessibilità dei dati in vari carichi di lavoro come ETL, BI e AI, il tutto senza l'onere di migrazioni costose e complesse.
"Alla Instacart, la nostra visione è avere un data lakehouse aperto con una singola copia dei dati che sia interoperabile con tutte le piattaforme di calcolo. Delta UniForm è fondamentale per questo obiettivo. Con Delta UniForm, possiamo generare rapidamente e facilmente tabelle che possono essere lette come Delta Lake o Iceberg, sbloccando l'interoperabilità con tutti gli strumenti nel nostro ecosistema." —Doug Hyde, Sr. Staff Software Engineer presso Instacart, ha condiviso la sua esperienza con Delta UniForm
La missione di Databricks è aiutare i team di dati a risolvere i problemi più difficili del mondo, e questo inizia con la possibilità di utilizzare lo strumento giusto per il lavoro giusto senza dover creare copie dei propri dati. Siamo entusiasti dei miglioramenti nell'interoperabilità che Delta UniForm offre e continueremo a investire in quest'area per gli anni a venire.
Delta UniForm è disponibile come parte del release candidate in anteprima per Delta Lake 3.0. I clienti Databricks possono anche provare in anteprima Delta UniForm con Databricks Runtime versione 13.2 o il canale di anteprima Databricks SQL 2023.35.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.