DSPy su Databricks
Un Framework per la Programmazione di RAG e altri Sistemi AI Composti
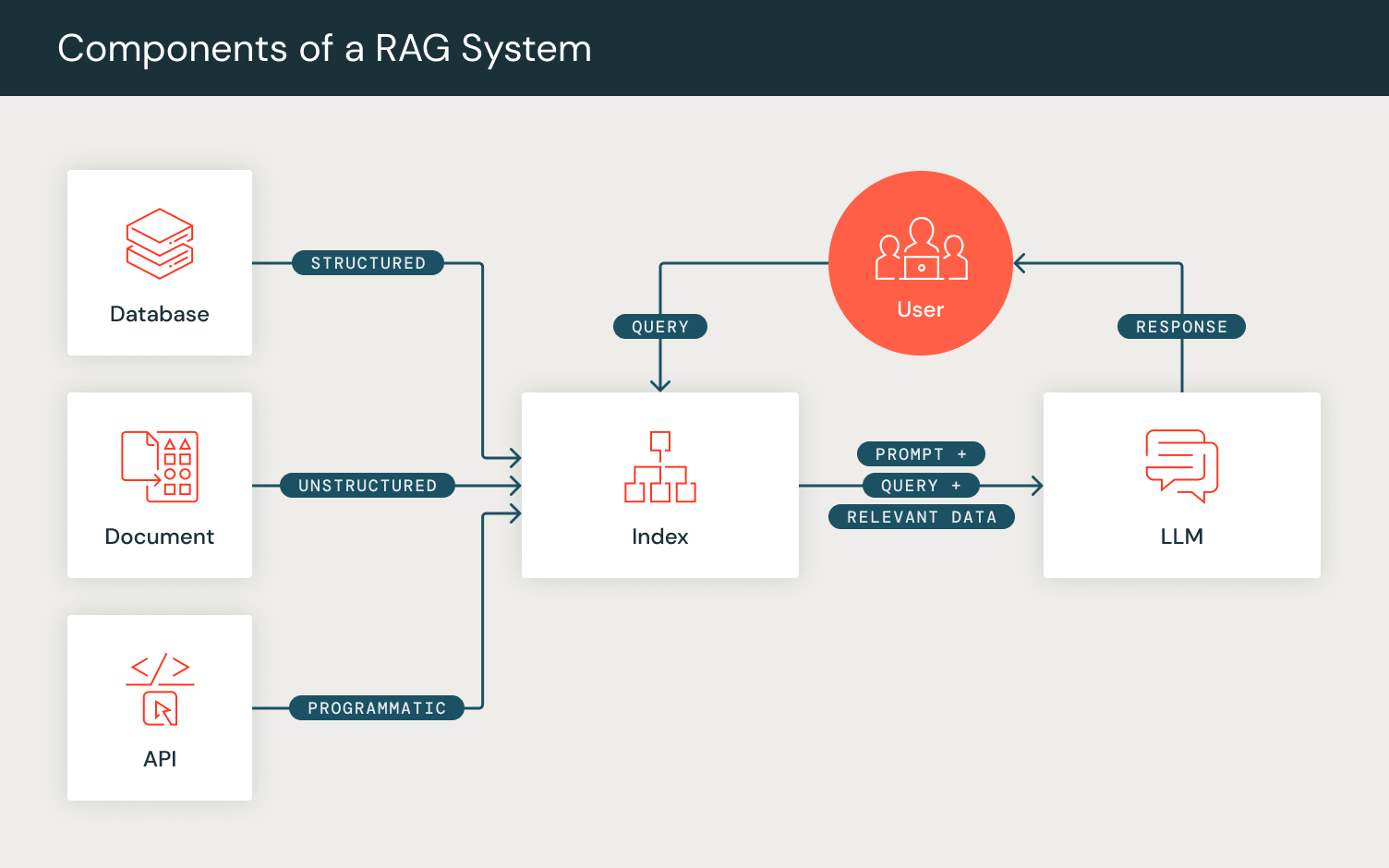
I modelli linguistici di grandi dimensioni (LLM) hanno suscitato interesse nell'interazione uomo-IA efficace attraverso l'ottimizzazione delle tecniche di prompting. "Prompt engineering" è una metodologia in crescita per personalizzare gli output dei modelli, mentre tecniche avanzate come Retrieval Augmented Generation (RAG) migliorano le capacità generative degli LLM recuperando e rispondendo con informazioni pertinenti.
DSPy, sviluppato dallo Stanford NLP Group, è emerso come un framework per la creazione di sistemi AI composti attraverso "programmazione, non prompting, di modelli fondazionali". DSPy ora supporta integrazioni con gli endpoint per sviluppatori Databricks per Model Serving e AI Search.
Ingegnerizzazione di AI Composti
Queste tecniche di prompting segnalano uno spostamento verso "pipeline di prompting" complesse in cui gli sviluppatori AI incorporano LLM, modelli di recupero (RM) e altri componenti durante lo sviluppo di sistemi AI composti.
Programmazione non Prompting: DSPy
DSPy ottimizza le prestazioni dei sistemi guidati dall'IA componendo chiamate LLM insieme ad altri strumenti computazionali verso metriche di task downstream. A differenza del tradizionale "prompt engineering", DSPy automatizza l'ottimizzazione dei prompt traducendo le firme in linguaggio naturale definite dall'utente in istruzioni complete ed esempi few-shot. Rispecchiando l'ottimizzazione di pipeline end-to-end come in PyTorch, DSPy consente agli utenti di definire e comporre sistemi AI strato per strato ottimizzando per l'obiettivo desiderato.
I programmi in DSPy hanno due metodi principali:
- Inizializzazione: Gli utenti possono definire i componenti delle loro pipeline di prompting come layer DSPy. Ad esempio, per tenere conto dei passaggi coinvolti in RAG, definiamo un layer di recupero e un layer di generazione.
- Definiamo un layer di recupero `dspy.Retrieve` che utilizza l'RM configurato dall'utente per recuperare un set di passaggi/documenti pertinenti per una query di ricerca inserita.
- Inizializziamo quindi il nostro layer di generazione, per il quale utilizziamo il modulo `dspy.Predict`, che prepara internamente il prompt per la generazione. Per configurare questo layer di generazione, definiamo il nostro task RAG in un formato di firma in linguaggio naturale, specificato da un set di campi di input ("context, query") e dal campo di output atteso ("answer"). Questo modulo formatta internamente il prompt per corrispondere a questa formattazione definita, e quindi restituisce la generazione dall'LM configurato dall'utente.
- Forward: Simile ai forward pass di PyTorch, la funzione forward del programma DSPy consente la composizione da parte dell'utente della logica della pipeline di prompting. Utilizzando i layer che abbiamo inizializzato, impostiamo il flusso computazionale di RAG recuperando un set di passaggi data una query e quindi utilizzando questi passaggi come contesto insieme alla query per generare una risposta, restituendo l'output atteso in un oggetto dizionario DSPy.
Diamo un'occhiata a RAG in azione utilizzando il programma DSPy e la generazione di DBRX.
Per questo esempio, utilizziamo una domanda di esempio dal dataset HotPotQA che include domande che richiedono più passaggi per dedurre la risposta corretta.
Configuriamo innanzitutto il nostro LM e RM in DSPy. DSPy offre una varietà di integrazioni di modelli linguistici e di recupero, e gli utenti possono impostare questi parametri per garantire che qualsiasi programma definito da DSPy venga eseguito attraverso queste configurazioni.
Dichiariamo ora il nostro programma DSPy RAG definito e passiamo semplicemente la domanda come input.
Durante il passaggio di recupero, la query viene passata al layer self.retrieve che restituisce i primi 3 passaggi pertinenti, che sono formattati internamente come segue:
Con questi passaggi recuperati, possiamo passarli insieme alla nostra query al modulo dspy.Predict self.generate_answer, corrispondendo ai campi di input della firma in linguaggio naturale "context, query". Questo applica internamente una formattazione e una formulazione di base, e ti consente di dirigere il modello con la descrizione esatta del tuo task senza dover fare il prompt engineering dell'LLM.
Una volta dichiarata la formattazione, i campi di input "context" e "query" vengono popolati e il prompt finale viene inviato a DBRX:
DBRX genera una risposta che viene popolata nel campo Answer:, e possiamo osservare questa generazione di prompt chiamando:
Questo restituisce l'ultima generazione di prompt dall'LM con la risposta generata "Steve Yzerman", che è la risposta corretta!
DSPy è stato ampiamente utilizzato in vari task di modelli linguistici come fine-tuning, in-context learning, estrazione di informazioni, auto-affinamento, e numerosi altri. Questo approccio automatizzato supera il prompting few-shot standard con dimostrazioni scritte da esseri umani fino al 46% per GPT-3.5 e al 65% per Llama2-13b-chat su task di linguaggio naturale come RAG multi-hop e benchmark matematici come GSM8K.
DSPy su Databricks
DSPy ora supporta integrazioni con endpoint di sviluppo Databricks per Model Serving e AI Search. Gli utenti possono configurare API di modelli foundation ospitati da Databricks tramite l'SDK OpenAI tramite dspy.Databricks. Ciò garantisce che gli utenti possano valutare le loro pipeline DSPy end-to-end su modelli ospitati da Databricks. Attualmente, questo supporta modelli sugli endpoint di Model Serving: chat (DBRX Instruct, Mixtral-8x7B Instruct, Llama 2 70B Chat), completion (MPT 7B Instruct) e embedding (BGE Large (En)).
Modelli Chat
Modelli di Completamento
Modelli di Embedding
Modelli Retriever/AI Search
Inoltre, gli utenti possono configurare modelli retriever tramite Databricks AI Search. Dopo la creazione di un indice e di un endpoint AI Search, gli utenti possono specificare i parametri RM corrispondenti tramite dspy.DatabricksRM:
Gli utenti possono configurarlo globalmente impostando LM e RM sugli endpoint Databricks corrispondenti ed eseguendo programmi DSPy.
Con questa integrazione, gli utenti possono costruire e valutare applicazioni DSPy end-to-end, come RAG, utilizzando gli endpoint Databricks!
Dai un'occhiata al repository GitHub ufficiale di DSPy, alla documentazione e a Discord per saperne di più su come trasformare i task di IA generativa in pipeline DSPy versatili con Databricks!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.