Fine-tuning efficiente con LoRA: una guida alla selezione ottimale dei parametri per modelli linguistici di grandi dimensioni
Con il rapido avanzamento delle tecniche basate su reti neurali e della ricerca sui modelli linguistici di grandi dimensioni (LLM), le aziende sono sempre più interessate alle applicazioni di IA per la generazione di valore. Impiegano vari approcci di machine learning, sia generativi che non generativi, per affrontare sfide relative al testo come classificazione, riassunto, attività sequence-to-sequence e generazione di testo controllata. Le organizzazioni possono optare per API di terze parti, ma il fine-tuning dei modelli con dati proprietari offre risultati specifici del dominio e pertinenti, consentendo soluzioni economiche e indipendenti distribuibili in diversi ambienti in modo sicuro.
Garantire un utilizzo efficiente delle risorse e un buon rapporto costo-efficacia è fondamentale quando si sceglie una strategia di fine-tuning. Questo blog esplora quella che è probabilmente la variante più popolare ed efficace di tali metodi efficienti in termini di parametri, Low Rank Adaptation (LoRA), con particolare enfasi su QLoRA (una variante ancora più efficiente di LoRA). L'approccio qui sarà quello di prendere un modello linguistico di grandi dimensioni open source e affinarlo per generare descrizioni di prodotti fittizie quando viene richiesto un nome di prodotto e una categoria. Il modello scelto per questo esercizio è OpenLLaMA-3b-v2, un modello linguistico di grandi dimensioni open source con una licenza permissiva (Apache 2.0), e il set di dati scelto è Red Dot Design Award Product Descriptions, entrambi scaricabili dall'HuggingFace Hub ai link forniti.
Fine-Tuning, LoRA e QLoRA
Nel campo dei modelli linguistici, il fine-tuning di un modello linguistico esistente per eseguire un'attività specifica su dati specifici è una pratica comune. Ciò comporta l'aggiunta di una testa specifica per l'attività, se necessario, e l'aggiornamento dei pesi della rete neurale tramite backpropagation durante il processo di addestramento. È importante notare la distinzione tra questo processo di fine-tuning e l'addestramento da zero. In quest'ultimo scenario, i pesi del modello vengono inizializzati casualmente, mentre nel fine-tuning, i pesi sono già ottimizzati in una certa misura durante la fase di pre-addestramento. La decisione su quali pesi ottimizzare o aggiornare, e quali mantenere congelati, dipende dalla tecnica scelta.
Il fine-tuning completo comporta l'ottimizzazione o l'addestramento di tutti i layer della rete neurale. Sebbene questo approccio produca generalmente i migliori risultati, è anche il più dispendioso in termini di risorse e tempo.
Fortunatamente, esistono approcci efficienti in termini di parametri per il fine-tuning che si sono dimostrati efficaci. Sebbene la maggior parte di tali approcci abbia prodotto prestazioni inferiori, Low Rank Adaptation (LoRA) ha invertito questa tendenza superando persino il fine-tuning completo in alcuni casi, come conseguenza dell'evitare l'oblio catastrofico (un fenomeno che si verifica quando la conoscenza del modello pre-addestrato viene persa durante il processo di fine-tuning).
LoRA è un metodo di fine-tuning migliorato in cui, invece di affinare tutti i pesi che costituiscono la matrice dei pesi del modello linguistico di grandi dimensioni pre-addestrato, vengono affinate due matrici più piccole che approssimano questa matrice più grande. Queste matrici costituiscono l'adattatore LoRA. Questo adattatore affinato viene quindi caricato sul modello pre-addestrato e utilizzato per l'inferenza.
QLoRA è una versione ancora più efficiente in termini di memoria di LoRA in cui il modello pre-addestrato viene caricato nella memoria della GPU come pesi quantizzati a 4 bit (rispetto agli 8 bit nel caso di LoRA), preservando un'efficacia simile a LoRA. L'analisi di questo metodo, il confronto dei due metodi quando necessario e la determinazione della migliore combinazione di iperparametri QLoRA per ottenere prestazioni ottimali con il tempo di addestramento più rapido saranno il focus qui.
LoRA è implementato nella libreria Hugging Face Parameter Efficient Fine-Tuning (PEFT), offrendo facilità d'uso e QLoRA può essere sfruttato utilizzando bitsandbytes e PEFT insieme. La libreria HuggingFace Transformer Reinforcement Learning (TRL) offre un trainer conveniente per il fine-tuning supervisionato con integrazione trasparente per LoRA. Queste tre librerie forniranno gli strumenti necessari per affinare il modello pre-addestrato scelto per generare descrizioni di prodotti coerenti e convincenti una volta richiesto con un'istruzione che indica gli attributi desiderati.
Preparazione dei dati per il fine-tuning supervisionato
Per analizzare l'efficacia di QLoRA per il fine-tuning di un modello per il seguimento delle istruzioni, è essenziale trasformare i dati in un formato adatto al fine-tuning supervisionato. Il fine-tuning supervisionato, in sostanza, addestra ulteriormente un modello pre-addestrato a generare testo condizionato da un prompt fornito. È supervisionato in quanto il modello viene affinato su un set di dati che presenta coppie prompt-risposta formattate in modo coerente.
Un esempio di osservazione dal nostro set di dati scelto dall'hub Hugging Face appare come segue:
|
prodotto |
categoria |
descrizione |
testo |
|
"Biamp Rack Products" |
"Digital Audio Processors" |
"“Alto valore di riconoscimento, estetica uniforme e scalabilità pratica – questo è stato ottenuto in modo impressionante con il linguaggio del marchio Biamp…”" |
"Nome Prodotto: Biamp Rack Products; Categoria Prodotto: Digital Audio Processors; Descrizione Prodotto: “Alto valore di riconoscimento, estetica uniforme e scalabilità pratica – questo è stato ottenuto in modo impressionante con il linguaggio del marchio Biamp…”
|
Per quanto utile sia questo set di dati, non è ben formattato per il fine-tuning di un modello linguistico per il seguimento delle istruzioni nel modo descritto sopra.
Il seguente snippet di codice carica il set di dati dall'hub Hugging Face in memoria, trasforma i campi necessari in una stringa formattata in modo coerente che rappresenta il prompt, e inserisce la risposta (cioè la descrizione), subito dopo. Questo formato è noto come 'formato Alpaca' nei circoli di ricerca sui modelli linguistici di grandi dimensioni poiché era il formato utilizzato per affinare il modello LLaMA originale di Meta per ottenere il modello Alpaca, uno dei primi modelli linguistici di grandi dimensioni per il seguimento delle istruzioni ampiamente distribuiti (sebbene non concesso in licenza per uso commerciale).
I prompt risultanti vengono quindi caricati in un set di dati Hugging Face per il fine-tuning supervisionato. Ciascun prompt di questo tipo ha il seguente formato.
Per facilitare la sperimentazione rapida, ogni esercizio di fine-tuning verrà eseguito su un sottoinsieme di 5000 osservazioni di questi dati.
Test delle prestazioni del modello prima del fine-tuning
Prima di qualsiasi fine-tuning, è una buona idea verificare le prestazioni del modello senza alcun fine-tuning per ottenere una baseline delle prestazioni del modello pre-addestrato.
Il modello può essere caricato in 8 bit come segue e interrogato con il formato specificato nella scheda del modello su Hugging Face.
L'output ottenuto non è esattamente quello che vogliamo.
La prima parte del risultato è in realtà soddisfacente, ma il resto è più un miscuglio confuso.
Allo stesso modo, se al modello viene fornito il testo di input nel 'formato Alpaca' come discusso in precedenza, l'output dovrebbe essere altrettanto sub-ottimale:
E infatti, lo è:
Il modello fa ciò per cui è stato addestrato, predice il token successivo più probabile. Lo scopo del fine-tuning supervisionato in questo contesto è generare il testo desiderato in modo controllabile. Si noti che negli esperimenti successivi, mentre QLoRA sfrutta un modello caricato in 4 bit con i pesi congelati, il processo di inferenza per esaminare la qualità dell'output viene eseguito una volta che il modello è stato caricato in 8 bit come mostrato sopra per coerenza.
Le manopole regolabili
Quando si utilizza PEFT per addestrare un modello con LoRA o QLoRA (si noti che, come menzionato in precedenza, la differenza principale tra i due è che in quest'ultimo, i modelli pre-addestrati sono congelati in 4 bit durante il processo di fine-tuning), gli iperparametri del processo di adattamento a basso rango possono essere definiti in una configurazione LoRA come mostrato di seguito:
Due di questi iperparametri, r e target_modules, hanno dimostrato empiricamente di influenzare significativamente la qualità dell'adattamento e saranno al centro dei test che seguiranno. Gli altri iperparametri vengono mantenuti costanti ai valori indicati sopra per semplicità.
r rappresenta il rango delle matrici a basso rango apprese durante il processo di fine-tuning. All'aumentare di questo valore, aumenta il numero di parametri necessari per essere aggiornati durante l'adattamento a basso rango. Intuitivamente, un r inferiore può portare a un processo di addestramento più rapido e meno intensivo dal punto di vista computazionale, ma può influire sulla qualità del modello prodotto. Tuttavia, aumentare r oltre un certo valore potrebbe non produrre alcun aumento discernibile nella qualità dell'output del modello. Come il valore di r influenzi la qualità dell'adattamento (fine-tuning) verrà messo alla prova a breve.
Quando si esegue il fine-tuning con LoRA, è possibile mirare a moduli specifici nell'architettura del modello. Il processo di adattamento prenderà di mira questi moduli e applicherà loro le matrici di aggiornamento. Similmente alla situazione con "r", il targeting di più moduli durante l'adattamento LoRA comporta un aumento del tempo di addestramento e una maggiore richiesta di risorse computazionali. Pertanto, è pratica comune mirare solo ai blocchi di attenzione del trasformatore. Tuttavia, lavori recenti come mostrato nel paper QLoRA di Dettmers et al. suggerisce che il targeting di tutti i layer lineari porta a una migliore qualità di adattamento. Questo verrà esplorato anche qui.
I nomi dei layer lineari del modello possono essere comodamente aggiunti a una lista con il seguente snippet di codice:
Ottimizzazione del fine-tuning con LoRA
L'esperienza dello sviluppatore nel fine-tuning di modelli linguistici di grandi dimensioni in generale è migliorata notevolmente nell'ultimo anno circa. L'ultima astrazione di alto livello di Hugging Face è la classe SFTTrainer nella libreria TRL. Per eseguire QLoRA, tutto ciò che serve è quanto segue:
1. Caricare il modello nella memoria della GPU in 4 bit (bitsandbytes abilita questo processo).
2. Definire la configurazione LoRA come discusso sopra.
3. Definire gli split di addestramento e test dei dati di istruzione preparati in oggetti Dataset di Hugging Face.
4. Definire gli argomenti di addestramento. Questi includono il numero di epoche, la dimensione del batch e altri iperparametri di addestramento che verranno mantenuti costanti durante questo esercizio.
5. Passare questi argomenti a un'istanza di SFTTrainer.
Questi passaggi sono chiaramente indicati nel file sorgente nel repository associato a questo blog.
La logica di addestramento effettiva è ben astratta come segue:
Se l'autologging di MLFlow è abilitato nell'area di lavoro Databricks, cosa altamente raccomandata, tutti i parametri e le metriche di addestramento vengono tracciati e registrati automaticamente con il server di tracciamento MLFlow. Questa funzionalità è inestimabile per monitorare le attività di addestramento di lunga durata. Inutile dire che il processo di fine-tuning viene eseguito utilizzando un cluster di calcolo (in questo caso, un singolo nodo con una singola GPU A100) creato utilizzando il più recente runtime Databricks Machine con supporto GPU.
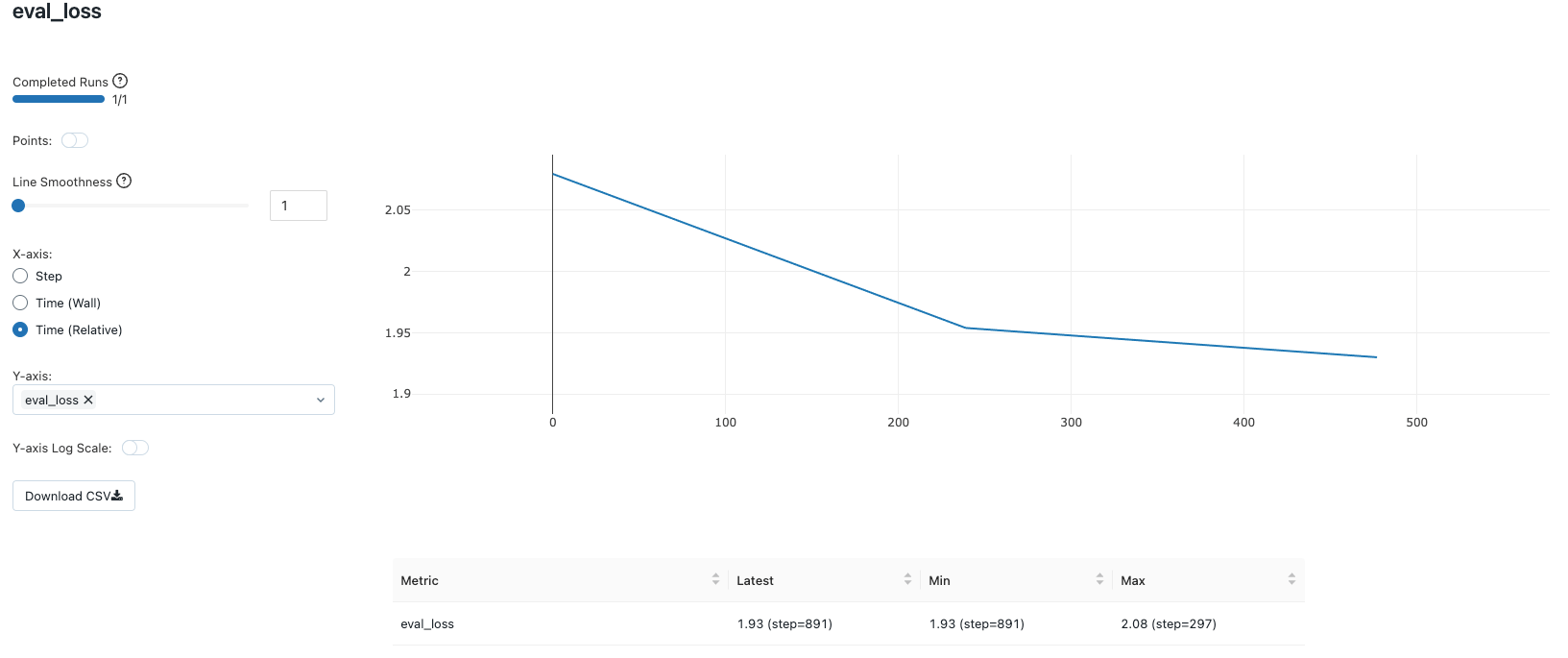
Combinazione di iperparametri n. 1: QLoRA con r=8 e targeting di “q_proj”, “v_proj”
La prima combinazione di iperparametri QLoRA tentata è r=8 e si rivolge solo ai blocchi di attenzione, ovvero “q_proj” e “v_proj” per l'adattamento.
I seguenti snippet di codice mostrano il numero di parametri addestrabili:
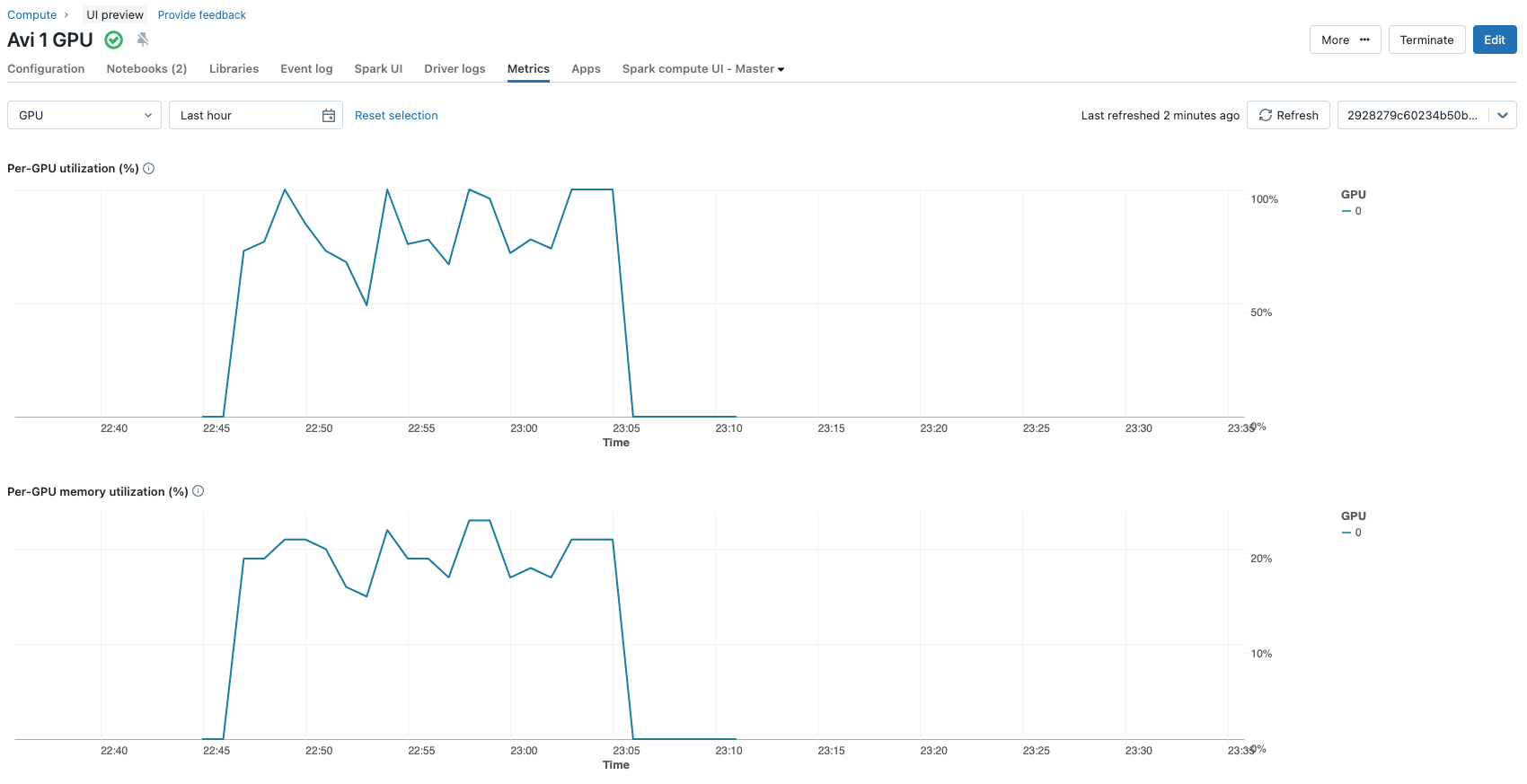
Queste scelte comportano l'aggiornamento di 2.662.400 parametri durante il processo di fine-tuning (~2,6 milioni) da un totale di ~3,2 miliardi di parametri di cui il modello è composto. Si tratta di meno dello 0,1% dei parametri del modello. L'intero processo di fine-tuning su una singola Nvidia A100 con 80 GB di GPU per 3 epoch richiede solo circa 12 minuti. Le metriche di utilizzo della GPU possono essere visualizzate comodamente nella scheda metriche delle configurazioni del cluster.
Alla fine del processo di addestramento, il modello fine-tuned si ottiene caricando i pesi dell'adattatore al modello pre-addestrato come segue:
Questo modello può ora essere utilizzato per l'inferenza come qualsiasi altro modello.
Valutazione Qualitativa
Di seguito sono riportate alcune coppie di prompt-risposta di esempio
Prompt (passato al modello nel formato Alpaca, non mostrato per brevità qui):
Crea una descrizione dettagliata per il seguente prodotto: Corelogic Smooth Mouse, appartenente alla categoria: Mouse Ottico
Risposta:
Prompt:
Crea una descrizione dettagliata per il seguente prodotto: Hoover Lightspeed, appartenente alla categoria: Aspirapolvere Senza Fili
Risposta:
Il modello è stato chiaramente adattato per generare descrizioni più coerenti. Tuttavia, la risposta al primo prompt sul mouse ottico è piuttosto breve e la frase seguente “L'aspirapolvere è dotato di un contenitore per la polvere che può essere svuotato tramite un contenitore per la polvere” è logicamente errata.
Combinazione di Iperparametri #2: QLoRA con r=16 e targeting di tutti i layer lineari
Sicuramente, le cose possono essere migliorate qui. Vale la pena esplorare l'aumento del rango delle matrici a basso rango apprese durante l'adattamento a 16, cioè raddoppiare il valore di r a 16 e mantenere tutto il resto invariato. Ciò raddoppia il numero di parametri addestrabili a 5.324.800 (~5,3 milioni).
Valutazione Qualitativa
La qualità dell'output, tuttavia, rimane invariata per gli stessi identici prompt.
Prompt:
Crea una descrizione dettagliata per il seguente prodotto: Corelogic Smooth Mouse, appartenente alla categoria: Mouse Ottico
Risposta:
Prompt:
Crea una descrizione dettagliata per il seguente prodotto: Hoover Lightspeed, appartenente alla categoria: Aspirapolvere Senza Fili
Risposta:
Persiste la stessa mancanza di dettaglio e gli stessi errori logici nei dettagli dove i dettagli sono disponibili. Se questo modello fine-tuned viene utilizzato per la generazione di descrizioni di prodotti in uno scenario reale, questo non è un output accettabile.
Combinazione di Iperparametri #3: QLoRA con r=8 e targeting di tutti i layer lineari
Dato che raddoppiare r non sembra portare a un aumento percepibile della qualità dell'output, vale la pena cambiare l'altro parametro importante. cioè, puntare a tutti i layer lineari invece che solo ai blocchi di attenzione. Qui, gli iperparametri LoRA sono r=8 e i target_layers sono 'q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj' e 'lm_head'. Ciò aumenta il numero di parametri aggiornati a 12.994.560 e aumenta il tempo di addestramento a circa 15,5 minuti.
Valutazione Qualitativa
Il prompting del modello con gli stessi prompt produce quanto segue:
Prompt:
Crea una descrizione dettagliata per il seguente prodotto: Corelogic Smooth Mouse, appartenente alla categoria: Mouse Ottico
Risposta:
Prompt:
Crea una descrizione dettagliata per il seguente prodotto: Hoover Lightspeed, appartenente alla categoria: Aspirapolvere Senza Fili
Risposta:
Ora è possibile vedere una descrizione alquanto più lunga e coerente del fittizio mouse ottico e non ci sono errori logici nella descrizione dell'aspirapolvere. Le descrizioni dei prodotti non sono solo logiche, ma pertinenti. Solo per ricordare, questi risultati di qualità relativamente elevata si ottengono tramite il fine-tuning di meno dell'1% dei pesi del modello con un dataset totale di 5000 coppie prompt-descrizione formattate in modo coerente.
Combinazione di Iperparametri #4: LoRA con r=8 e targeting di tutti i layer lineari del trasformatore
Vale anche la pena esplorare se la qualità dell'output del modello migliora se il modello pre-addestrato viene congelato in 8-bit invece che in 4-bit. In altre parole, replicare l'esatto processo di fine-tuning utilizzando LoRA invece di QLoRA. Qui, gli iperparametri LoRA vengono mantenuti uguali a prima, nella nuova configurazione ottimale trovata, cioè r=8 e targeting di tutti i layer lineari del trasformatore durante il processo di adattamento.
Valutazione Qualitativa
I risultati per i due prompt utilizzati nell'articolo sono i seguenti:
Prompt:
Crea una descrizione dettagliata per il seguente prodotto: Corelogic Smooth Mouse, appartenente alla categoria: Mouse Ottico
Risposta:
Prompt:
Crea una descrizione dettagliata per il seguente prodotto: Hoover Lightspeed, appartenente alla categoria: Aspirapolvere Senza Fili
Risposta:
Anche in questo caso, non c'è stato un grande miglioramento nella qualità del testo di output.
Osservazioni Chiave
Sulla base della serie di prove sopra riportate, e di ulteriori prove dettagliate nell'eccellente pubblicazione che presenta QLoRA, si può dedurre che il valore di r (il rango delle matrici aggiornate durante l'adattamento) non migliora la qualità dell'adattamento oltre un certo punto. Il miglioramento maggiore si osserva nel targeting di tutti i layer lineari nel processo di adattamento, rispetto ai soli blocchi di attenzione, come comunemente documentato nella letteratura tecnica che descrive LoRA e QLoRA. Le prove eseguite sopra e altre evidenze empiriche suggeriscono che QLoRA non soffre di alcuna riduzione apprezzabile nella qualità del testo generato, rispetto a LoRA.
Ulteriori Considerazioni per l'utilizzo di adattatori LoRA nel deployment
È importante ottimizzare l'uso degli adapter e comprendere i limiti della tecnica. La dimensione dell'adapter LoRA ottenuta tramite il fine-tuning è tipicamente di pochi megabyte, mentre il modello base pre-addestrato può occupare diversi gigabyte in memoria e su disco. Durante l'inferenza, sia l'adapter che il LLM pre-addestrato devono essere caricati, quindi il requisito di memoria rimane simile.
Inoltre, se i pesi del LLM pre-addestrato e dell'adapter non vengono uniti, ci sarà un leggero aumento della latenza di inferenza. Fortunatamente, con la libreria PEFT, il processo di unione dei pesi con l'adapter può essere eseguito con una singola riga di codice, come mostrato qui:
La figura seguente delinea il processo dal fine-tuning di un adapter al deployment del modello.

Sebbene il pattern dell'adapter offra vantaggi significativi, l'unione degli adapter non è una soluzione universale. Un vantaggio del pattern dell'adapter è la possibilità di distribuire un singolo modello pre-addestrato di grandi dimensioni con adapter specifici per il task. Ciò consente un'inferenza efficiente utilizzando il modello pre-addestrato come backbone per diversi task. Tuttavia, l'unione dei pesi rende questo approccio impossibile. La decisione di unire i pesi dipende dal caso d'uso specifico e dalla latenza di inferenza accettabile. Ciononostante, LoRA/QLoRA continua ad essere un metodo altamente efficace per il fine-tuning efficiente dei parametri ed è ampiamente utilizzato.
Conclusione
Low Rank Adaptation è una potente tecnica di fine-tuning che può produrre ottimi risultati se utilizzata con la configurazione corretta. La scelta del valore corretto del rank e dei layer dell'architettura della rete neurale da targettizzare durante l'adattamento può decidere la qualità dell'output dal modello fine-tuned. QLoRA consente ulteriori risparmi di memoria preservando la qualità dell'adattamento. Anche quando viene eseguito il fine-tuning, ci sono diverse importanti considerazioni ingegneristiche per garantire che il modello adattato venga distribuito nel modo corretto.
In sintesi, una tabella concisa che indica le diverse combinazioni di parametri LoRA tentati, la qualità del testo in output e il numero di parametri aggiornati durante il fine-tuning di OpenLLaMA-3b-v2 per 3 epoch su 5000 osservazioni su un singolo A100 è mostrata di seguito.
|
r |
target_modules |
Pesi del modello base |
Qualità dell'output |
Numero di parametri aggiornati (in milioni) |
|
8 |
Blocchi di attenzione |
4 |
bassa |
2.662 |
|
16 |
Blocchi di attenzione |
4 |
bassa |
5.324 |
|
8 |
Tutti i layer lineari |
4 |
alta |
12.995 |
|
8 |
Tutti i layer lineari |
8 |
alta |
12.995 |
Prova questo su Databricks! Clona il repository GitHub associato al blog in un Repo di Databricks per iniziare. Esempi più dettagliati per il fine-tuning di modelli su Databricks sono disponibili qui.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.