I tipi di nodi flessibili sono ora generalmente disponibili
Migliora l'affidabilità dell'avvio dei cluster e riduci i costi di calcolo con il fallback automatico delle istanze
di Kelsey Ge, Andrew Bagshaw, Tianyi Zhang, Vedaant Shah, Rishan Girish e Hugh March
- Proteggi i carichi di lavoro dagli errori di capacità: quando il tipo di VM preferito non è disponibile, Databricks esegue automaticamente il fallback ad alternative compatibili in modo che i cluster possano comunque essere avviati.
- Ottieni flessibilità in stile Fleet su ogni cloud: i tipi di nodo flessibili portano il fallback automatico del tipo di istanza su Azure, GCP e AWS. Goditi un'attivazione più semplice "con un solo clic" a livello di workspace, con una chiara visibilità delle risorse acquisite e un ordine di fallback facoltativamente configurabile.
- Riduci la spesa senza sacrificare l'affidabilità: dai la priorità alle istanze Spot scontate quando disponibili ed esegui il fallback solo quando necessario per garantire il corretto avvio.
Garantire una capacità di compute specifica può essere difficile, specialmente durante i periodi di traffico elevato (e di forte pressione). I Data Engineer e gli amministratori di piattaforma conoscono fin troppo bene la frustrazione causata dagli errori di capacità insufficiente, o di "esaurimento", che si verificano quando l'avvio di un cluster non riesce perché un provider cloud non è in grado di soddisfare una richiesta per un tipo di istanza specifico.
Che si tratti di:
AWS_INSUFFICIENT_INSTANCE_CAPACITY_FAILURECLOUD_PROVIDER_RESOURCE_STOCKOUTsu Azure, oGCP_INSUFFICIENT_CAPACITY,
Questi errori interrompono i carichi di lavoro critici, soprattutto durante i periodi critici per il business, quando l'uptime è della massima importanza.
Cosa sono i tipi di nodo flessibili?
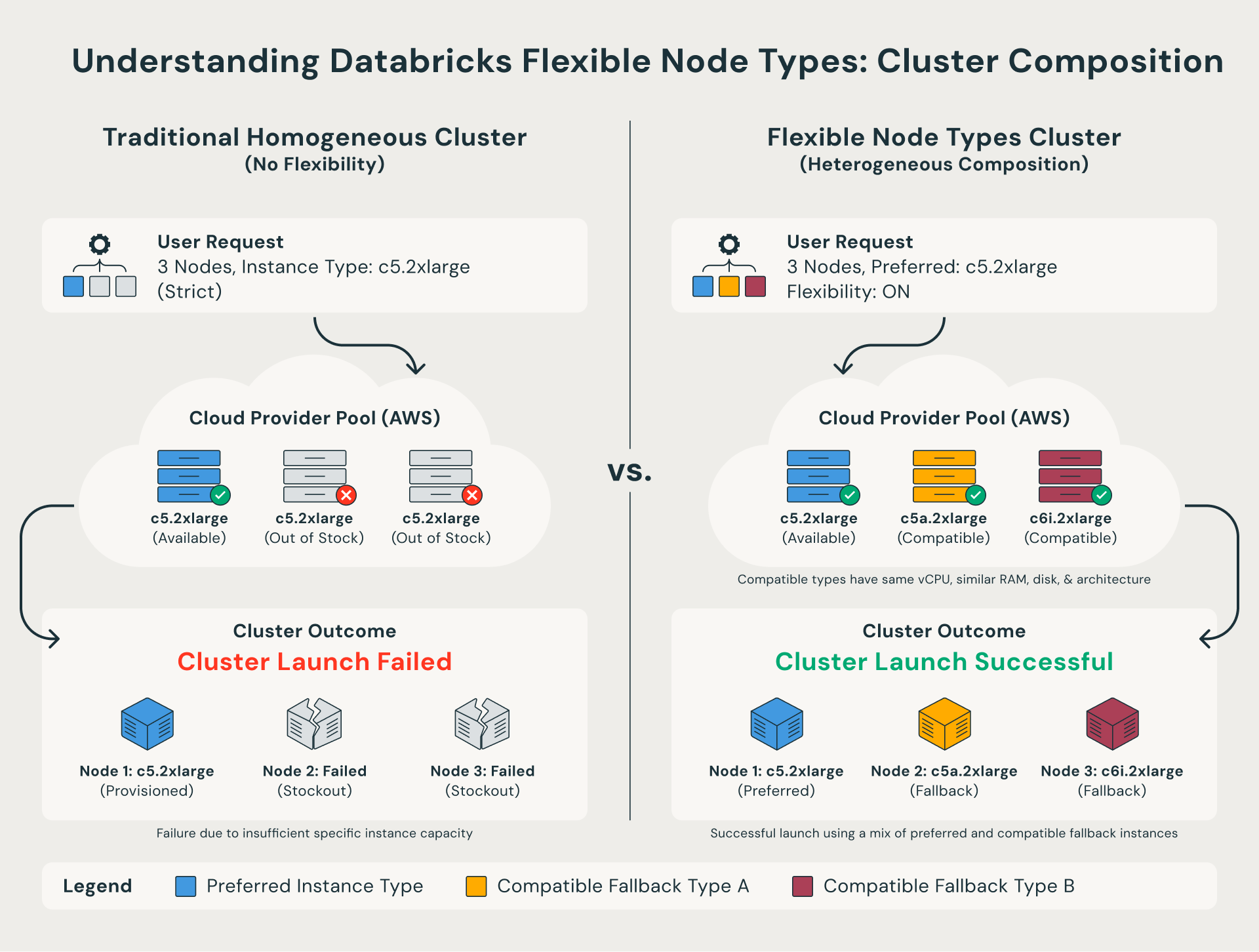
Tradizionalmente, i clusters Databricks richiedevano che ogni nodo fosse dell'esatto tipo di istanza specificato nella configurazione. Se quel tipo specifico non fosse disponibile, l'avvio del cluster fallirebbe.
I tipi di nodo flessibili rimuovono questo vincolo. Quando un tipo di istanza preferito non è disponibile, Databricks esegue automaticamente il fallback a un'alternativa compatibile che condivide la stessa configurazione di compute. In altre parole, il cluster viene avviato correttamente utilizzando un mix di tipi di istanza simili, anziché avere un esito completamente negativo.
I team che necessitano di maggiore controllo possono anche definire una lista di fallback personalizzata tramite API, indicando quali tipi di istanza provare e in quale ordine.
Vantaggi chiave
Meno avvii di cluster non riusciti durante i picchi di domanda
I tipi di nodi flessibili riducono la frequenza e la gravità degli errori legati alla capacità. Quando un provider cloud non è in grado di soddisfare il tipo di istanza preferito, Databricks esegue automaticamente il fallback su alternative compatibili, consentendo l'avvio dei cluster anziché la generazione di un errore.
Utilizzo ottimizzato delle istanze Spot
Per i cluster configurati con Spot con fallback, i tipi di nodi flessibili tentano di acquisire la capacità Spot nell'intero elenco di fallback prima di tornare alle istanze on-demand. Questo aumenta la porzione del cluster in esecuzione su Spot, contribuendo a ridurre i costi di calcolo e continuando a dare priorità agli avvii riusciti.
Visibilità chiara e controllo preciso
I team possono ispezionare esattamente quali tipi di nodi vengono acquisiti utilizzando la tabella di sistema node_timeline. Inoltre, è possibile definire un ordine di fallback personalizzato tramite l'API, consentendo un controllo preciso sul comportamento in termini di costi e prestazioni.
COMINCIA SUBITO
Gli amministratori del Workspace possono abilitare facilmente la funzionalità nelle impostazioni di amministrazione (Documentazione: AWS, Azure, GCP). Da quel momento, la funzionalità si applica immediatamente a tutti i nuovi avvii di cluster. I cluster a esecuzione prolungata adotteranno la funzionalità al prossimo riavvio e i futuri cluster di processi creati per i processi esistenti utilizzeranno automaticamente la funzionalità.
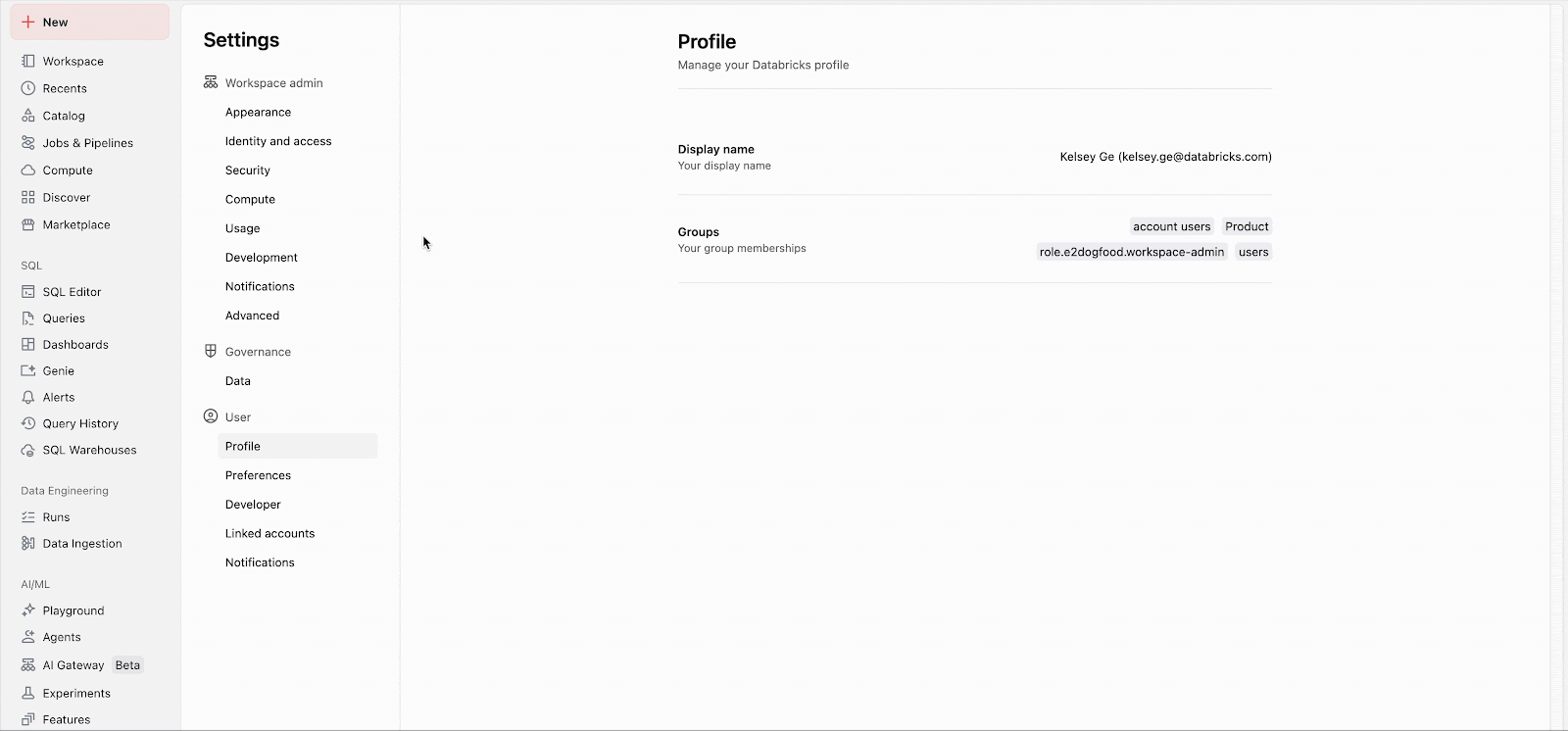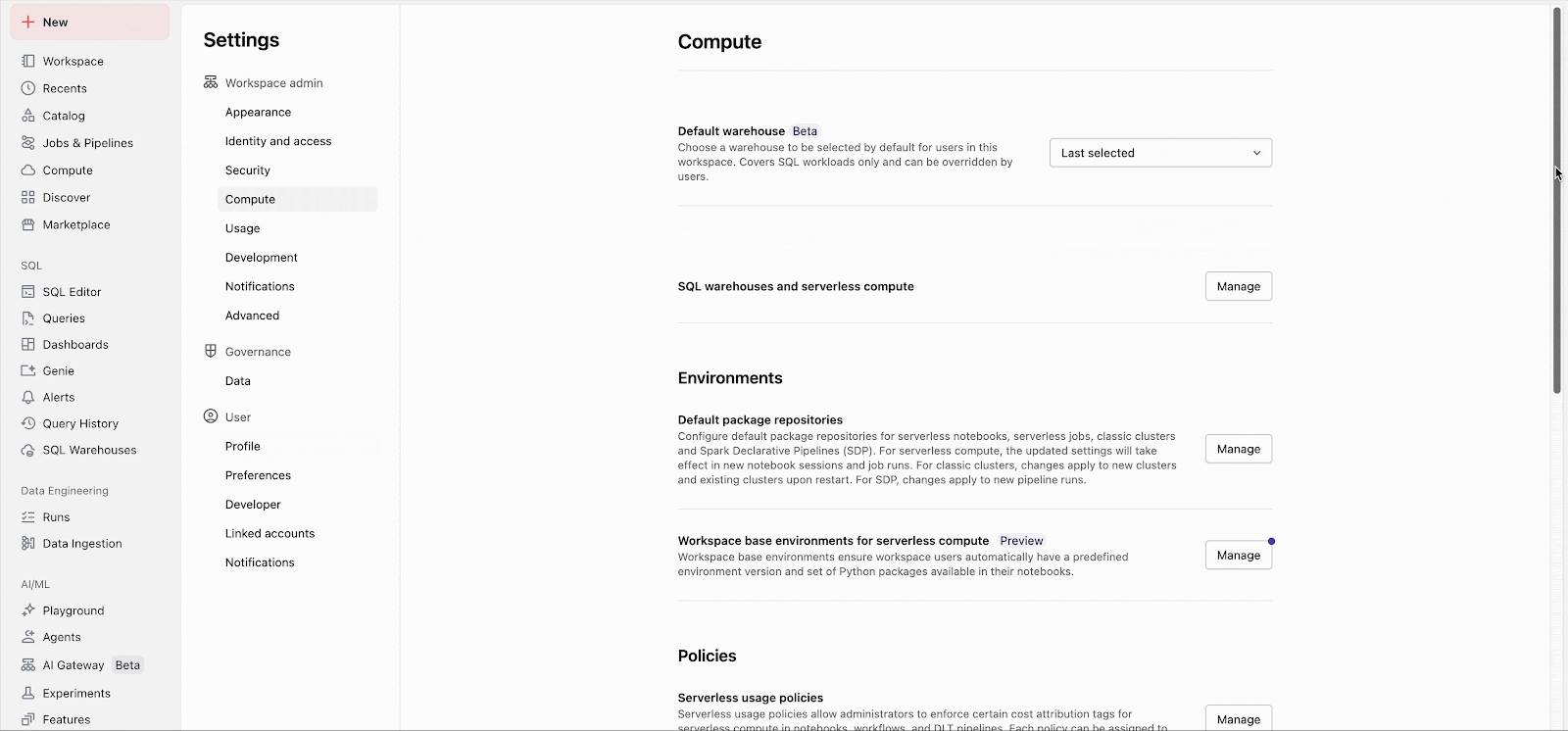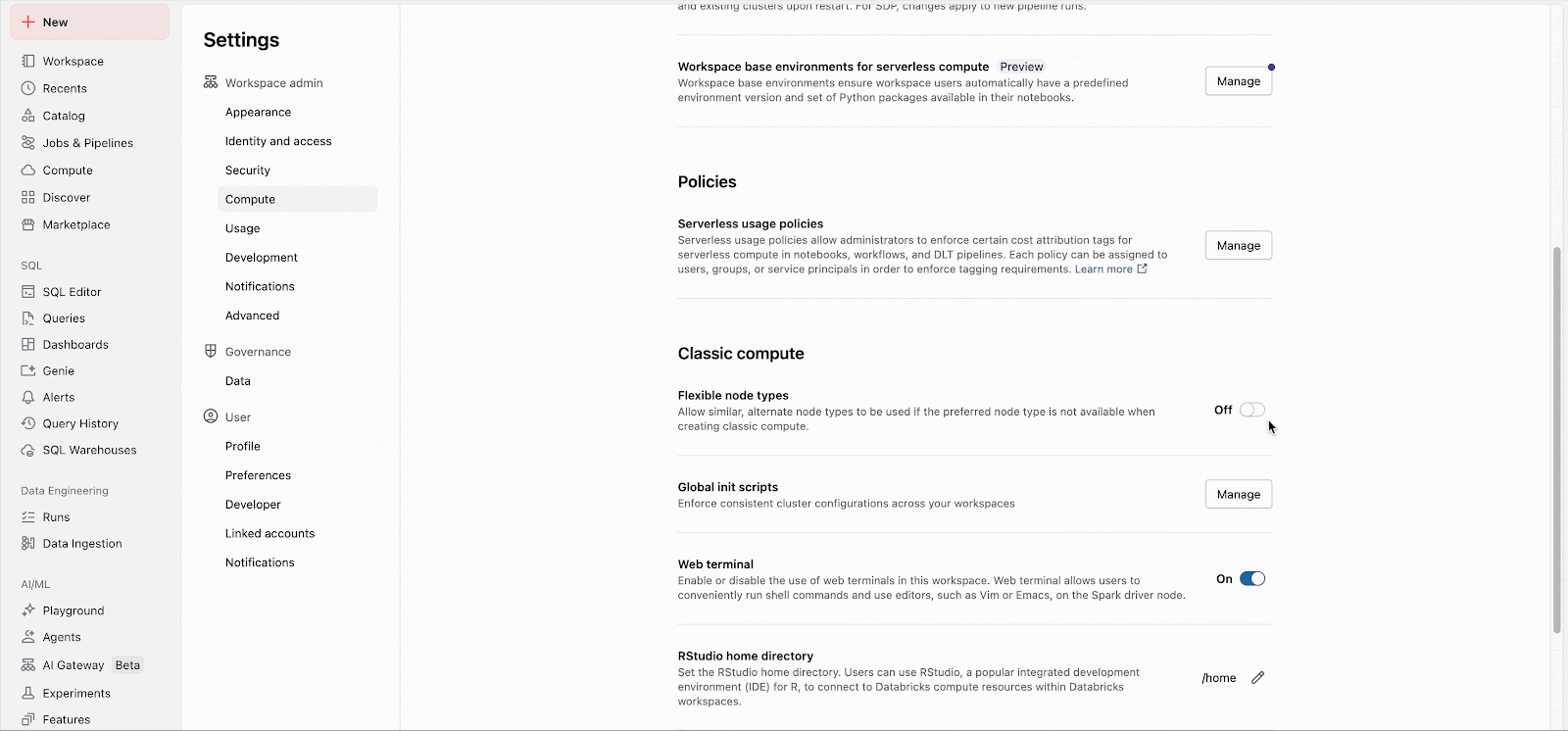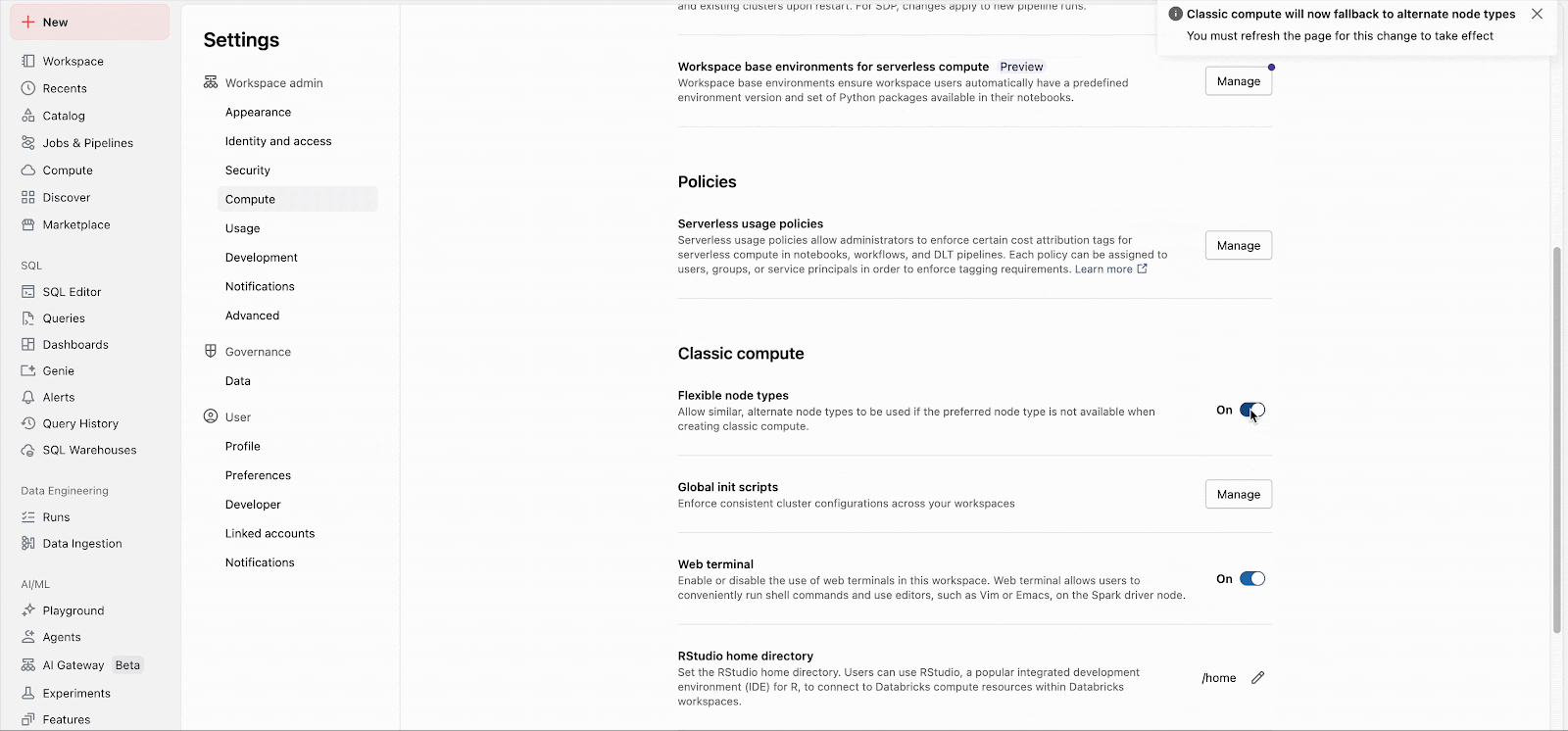
Gli elenchi di fallback personalizzati possono essere configurati tramite l'API, indipendentemente dall'impostazione dell'area di lavoro.
Dettagli aggiuntivi
Consultare la documentazione per ulteriori dettagli sulla configurazione dei tipi di nodi flessibili con pool di istanze, fatturazione, quote per tipo di nodo e abilitazione/disabilitazione selettiva (Documentazione: AWS, Azure, GCP).
I tipi di nodi flessibili sono progettati per rendere la tua piattaforma dati più resiliente ed economicamente vantaggiosa. Gli amministratori possono abilitare questa funzionalità con un clic già da oggi nelle impostazioni di amministrazione del workspace, seguendo le istruzioni riportate nella documentazione.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.