Guida introduttiva alla personalizzazione tramite propensity scoring
di Tian Tan, Sam Steiny e Bryan Smith

I consumatori si aspettano sempre più di essere coinvolti in modo personalizzato. Che si tratti di un'e-mail che promuove prodotti complementari a un acquisto recente, di un banner online che annuncia sconti su articoli di una categoria visualizzata di frequente o di contenuti in linea con i propri interessi, i consumatori hanno a disposizione sempre più opzioni su dove spendere il proprio denaro e preferiscono farlo con brand che riconoscono le loro esigenze e preferenze personali.
Un recente sondaggio di McKinsey evidenzia che quasi tre quarti dei consumatori si aspetta ormai interazioni personalizzate come parte della propria esperienza di acquisto. La ricerca inclusa in questo sondaggio evidenzia che le aziende che riescono a farlo bene possono generare il 40% di entrate in più grazie a interazioni personalizzate, rendendo la personalizzazione un fattore di differenziazione chiave per i principali attori del settore retail.
Tuttavia, molti retailer faticano ancora con la personalizzazione. Un recente sondaggio di Forrester rileva che solo il 30% dei consumatori negli US e il 26% nel UK ritiene che i retailer facciano un buon lavoro nel creare esperienze rilevanti per loro. In un sondaggio separato di 3radical, solo il 18% degli intervistati ha espresso con convinzione di ricevere raccomandazioni personalizzate, mentre il 52% ha manifestato frustrazione per la ricezione di comunicazioni e offerte non pertinenti. Con i consumatori sempre più propensi a cambiare brand e punti vendita, implementare correttamente la personalizzazione è diventato una priorità per un numero crescente di aziende.
La personalizzazione è un percorso
Per un'organizzazione alle prime armi con la personalizzazione, l'idea di offrire interazioni one-to-one può sembrare scoraggiante. Come possiamo superare i silos di processi, una gestione dei dati inefficiente e le preoccupazioni sulla privacy dei dati per raccogliere le informazioni necessarie a questo approccio? Come possiamo creare contenuti e messaggi che sembrino davvero personalizzati disponendo solo di risorse di marketing limitate? Come possiamo assicurarci che i contenuti creati siano effettivamente mirati a persone con esigenze e preferenze in continua evoluzione?
Sebbene gran parte della letteratura sulla personalizzazione evidenzi approcci all'avanguardia che si distinguono per la loro novità (ma non sempre per la loro efficacia), la realtà è che la personalizzazione è un percorso. Nelle prime fasi, l'accento è posto sull'utilizzo di dati di prima parte (first-party data), dove la privacy e la fiducia dei clienti sono più facili da mantenere. Vengono applicate tecniche predittive standard per introdurre funzionalità consolidate. Man mano che il valore viene dimostrato e l'organizzazione acquisisce familiarità non solo con queste nuove tecniche, ma anche con i vari modi in cui possono essere integrate nelle proprie attività, vengono poi impiegati approcci più sofisticati.
Il propensity scoring è spesso il primo passo verso la personalizzazione
Uno dei primi passi nel percorso di personalizzazione è spesso l'esame dei dati di vendita per ottenere informazioni sulle preferenze dei singoli clienti. In un processo noto come propensity scoring, le aziende possono stimare la potenziale ricettività dei clienti verso un'offerta o un contenuto relativo a un sottoinsieme di prodotti. Utilizzando questi punteggi, i marketer possono determinare quale dei molti messaggi a loro disposizione debba essere presentato a uno specifico cliente. Allo stesso modo, questi punteggi possono essere utilizzati per identificare segmenti di clienti più o meno ricettivi a una particolare forma di interazione.
Il punto di partenza per la maggior parte delle attività di propensity scoring è il calcolo di attributi numerici (feature) a partire dalle interazioni passate. Queste feature possono includere elementi come la frequenza degli acquisti di un cliente, la percentuale di spesa associata a una particolare categoria di prodotti, i giorni trascorsi dall'ultimo acquisto e molte altre metriche derivate dai dati storici. Il periodo storico immediatamente successivo a quello da cui sono state calcolate queste feature viene quindi esaminato per individuare i comportamenti di interesse, come l'acquisto di un prodotto all'interno di una determinata categoria o il riscatto di un coupon. Se il comportamento viene osservato, alle feature viene associata un'etichetta (label) pari a 1. In caso contrario, viene assegnata un'etichetta pari a 0.
Utilizzando le feature come predittori delle etichette, i data scientist possono addestrare un modello per stimare la probabilità che si verifichi il comportamento di interesse. Applicando questo modello addestrato alle feature calcolate per il periodo più recente, i marketer possono stimare la probabilità che un cliente adotti questo comportamento nel prossimo futuro.
Con numerose offerte, promozioni, messaggi e altri contenuti a disposizione, vengono addestrati e applicati a questo stesso set di feature diversi modelli, ognuno dei quali predice un comportamento differente. Viene così compilato un profilo per singolo cliente, composto dai punteggi per ciascuno dei comportamenti di interesse, che viene poi pubblicato sui sistemi a valle per essere utilizzato dal marketing nella gestione delle varie campagne.
Databricks offre funzionalità fondamentali per il propensity scoring
Per quanto il propensity scoring possa sembrare semplice, non è privo di sfide. Nei nostri confronti con i retailer che implementano il propensity scoring, ci imbattiamo spesso nelle stesse tre domande:
- Come possiamo gestire le centinaia e a volte migliaia di feature che utilizziamo per addestrare i nostri modelli di propensione?
- Come possiamo addestrare rapidamente modelli allineati alle nuove campagne che il team di marketing desidera lanciare?
- Come possiamo reinserire rapidamente nella pipeline di scoring i modelli riaddestrati in seguito alla deriva (drift) dei pattern dei clienti?
In Databricks, il nostro obiettivo è supportare i clienti attraverso una piattaforma di analytics creata pensando alle esigenze end-to-end dell'azienda. A tal fine, abbiamo integrato nella nostra piattaforma funzionalità come Feature Store, AutoML e MLflow, che possono essere utilizzate per affrontare queste sfide nell'ambito di un solido processo di propensity scoring.
Feature Store
Il Databricks Feature Store è un repository centralizzato che consente la persistenza, l'individuazione e la condivisione delle feature tra diverse attività di addestramento dei modelli. Quando le feature vengono acquisite, vengono registrati anche la lineage e altri metadati, in modo che i data scientist che desiderano riutilizzare feature create da altri possano farlo in modo semplice e sicuro. I modelli di sicurezza standard garantiscono che solo gli utenti e i processi autorizzati possano utilizzare queste feature, assicurando che i processi di data science siano gestiti in conformità con le policy aziendali di accesso ai dati.
AutoML
Databricks AutoML consente di generare rapidamente modelli sfruttando le best practice del settore. Come soluzione "glass box" (trasparente), AutoML genera innanzitutto una raccolta di notebook che rappresentano diverse varianti di modello allineate al tuo scenario. Mentre addestra in modo iterativo i diversi modelli per determinare quale funzioni meglio con il tuo dataset, ti consente di accedere ai notebook associati a ciascuno di essi. Per molti team di data science, questi notebook diventano un punto di partenza modificabile per esplorare ulteriormente le varianti del modello, consentendo infine di arrivare a un modello addestrato in grado di soddisfare i propri obiettivi.
MLflow
MLflow è un repository di modelli di machine learning open source, gestito all'interno della piattaforma Databricks. Questo repository consente al team di data science di tracciare e analizzare le varie iterazioni dei modelli generate sia da AutoML che da cicli di addestramento personalizzati. Le sue funzionalità di gestione dei workflow consentono alle organizzazioni di spostare rapidamente i modelli addestrati dallo sviluppo alla produzione, in modo che possano avere un impatto più immediato sulle attività operative.
Se utilizzati in combinazione con il Databricks Feature Store, i modelli salvati con MLflow mantengono la traccia delle feature utilizzate durante l'addestramento. Quando i modelli vengono richiamati per l'inferenza, questa stessa informazione consente al modello di recuperare le feature rilevanti dal Feature Store, semplificando notevolmente il workflow di scoring e consentendo un deployment rapido.
Creazione di un workflow di propensity scoring
Utilizzando queste funzionalità in combinazione, molte organizzazioni implementano il propensity scoring come parte di un workflow suddiviso in tre parti. Nella prima parte, i data engineer collaborano con i data scientist per definire le feature rilevanti per l'attività di propensity scoring e salvarle nel Feature Store. Vengono quindi definiti processi di feature engineering giornalieri o persino in tempo reale per calcolare valori aggiornati delle feature all'arrivo di nuovi dati.
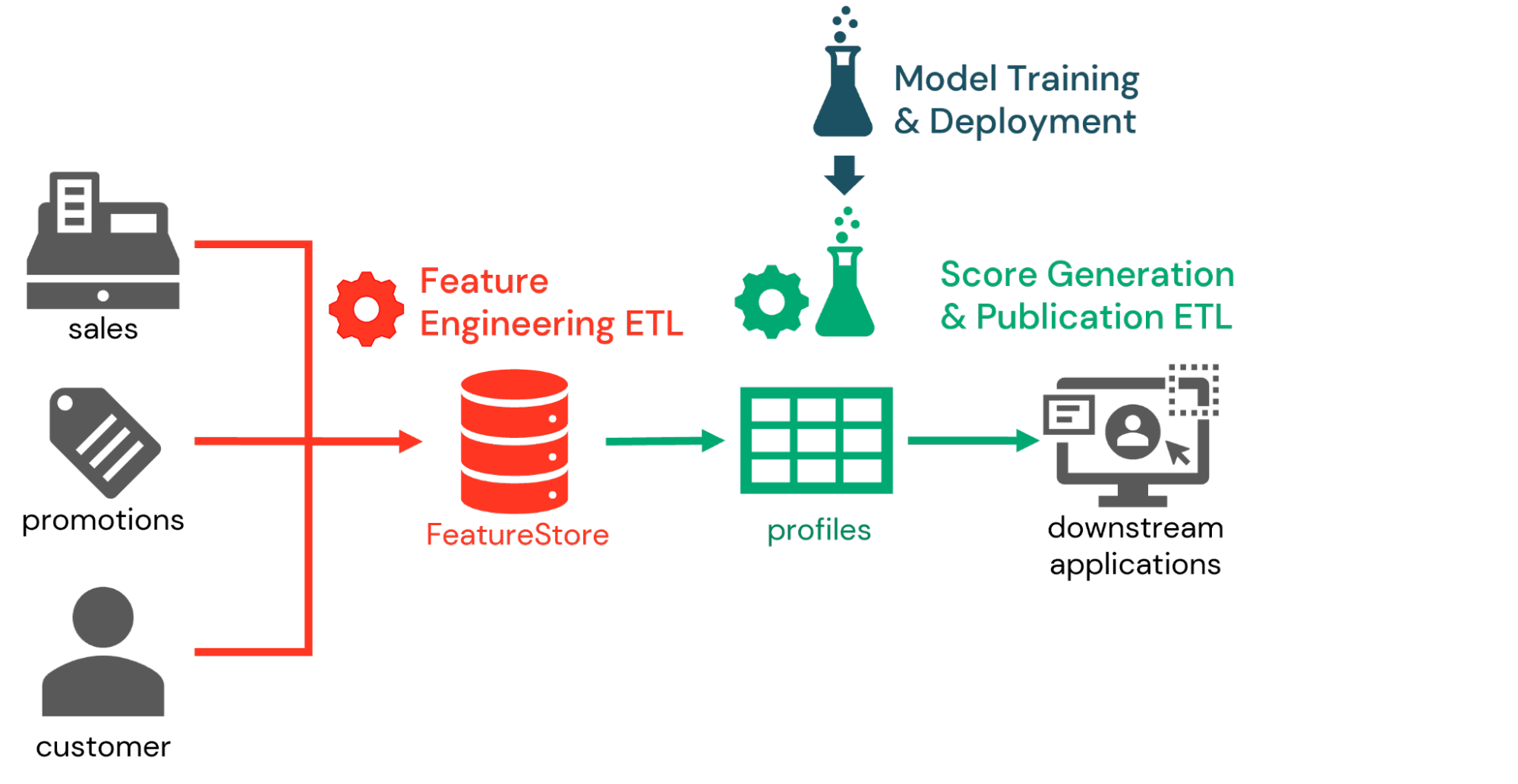
Successivamente, come parte del workflow di inferenza, gli identificativi dei clienti vengono presentati ai modelli precedentemente addestrati per generare i propensity score in base alle ultime feature disponibili. Le informazioni del Feature Store acquisite con il modello consentono ai data engineer di recuperare queste feature e generare i punteggi desiderati con relativa facilità. Questi punteggi possono essere salvati per l'analisi all'interno della piattaforma Databricks, ma più tipicamente vengono pubblicati nei sistemi di marketing a valle.
Infine, nel workflow di addestramento del modello, i data scientist riaddestrano periodicamente i modelli di propensity score per catturare i cambiamenti nei comportamenti dei clienti. Poiché questi modelli vengono salvati su MLflow, vengono impiegati processi di gestione del cambiamento per valutare i modelli e promuovere allo stato di produzione quelli che soddisfano i criteri aziendali. Nella successiva iterazione del workflow di inferenza, viene recuperata l'ultima versione di produzione di ciascun modello per generare i punteggi dei clienti.
Per dimostrare come queste funzionalità lavorano insieme, abbiamo creato un workflow end-to-end per il propensity scoring basato su un dataset disponibile pubblicamente. Questo workflow mostra le tre fasi del workflow descritto sopra e spiega come utilizzare le funzionalità chiave di Databricks per creare una pipeline di propensity scoring efficace.
Scarica gli asset qui e usali come punto di partenza per creare le tue fondamenta per la personalizzazione utilizzando la piattaforma Databricks.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.