Attribuzione granulare dell'utilizzo per le pipeline dbt con i tag di query
Tagga, traccia e ottimizza ogni modello dbt — dall'attribuzione dei costi e dal debug delle prestazioni al monitoraggio dell'ambiente — con una singola riga di configurazione o Genie.
- Tagga ogni query dbt con team, centro di costo, progetto e ambiente — zero modifiche al codice dei tuoi modelli SQL
- Interroga system.query.history per vedere esattamente quali modelli dbt costano di più e dove viene impiegato il tempo di calcolo
- Distribuisci un progetto di riferimento completo con i Declarative Automation Bundles: pipeline dbt, dashboard di analisi dei Query Tag e job pianificato — tutto da un unico repository GitHub
Il tuo progetto dbt esegue 80 modelli ogni notte. La fattura del warehouse è raddoppiata nell'ultimo trimestre. Le prestazioni dei modelli variano notevolmente e gli effetti delle ottimizzazioni più recenti non sono chiari. Il team Finance chiede quale sia il team responsabile. Apri la cronologia delle query e vedi... 80 righe identiche con l'etichetta 'Databricks Dbt'. Buona fortuna.
Con Query Tags (ora in Public Preview), i team di dati possono ora beneficiare di tag inseriti automaticamente pronti all'uso, come dbt_model_name, che arricchiscono ogni esecuzione. Puoi anche associare i tuoi tag personalizzati (team, centro di costo, ambiente, qualsiasi cosa) a ogni query generata dalla tua pipeline.
I tag vengono registrati in system.query.history, rendendo l'attribuzione dei costi, il debug delle prestazioni e il monitoraggio del carico di lavoro semplici quanto una query SQL (tutti i dettagli nella documentazione).
Questo blog illustra un progetto dbt open-source completo che mostra i Query Tags end-to-end: dalla configurazione ai dashboard di attribuzione dei costi. Tutto ciò che è descritto qui è disponibile come repository GitHub che puoi clonare e distribuire nel tuo workspace, oppure puoi semplicemente chiedere a Genie.
Come dbt-databricks si integra con i Query Tags
L'adattatore dbt-databricks (versione 1.11+) supporta i Query Tags in modo nativo. I tag possono essere applicati a tre livelli, ognuno dei quali si basa sul precedente:
Tag inseriti automaticamente
Oltre ai tuoi tag personalizzati, dbt-databricks inserisce automaticamente i metadati relativi all'esecuzione di ciascun modello:
Tag | Valore di esempio | Descrizione |
@@dbt_model_name | fct_daily_usage_by_sku | Il modello dbt in fase di esecuzione |
@@dbt_materialized | table | Strategia di materializzazione (table, view, incremental, metric_view) |
@@dbt_core_version | 1.11.6 | dbt-core versione |
@@dbt_databricks_version | 1.12.0a1 | dbt-databricks versione dell'adattatore |
Questi tag automatici ti consentono di ottenere visibilità per singolo modello con zero configurazione: l'adattatore fa tutto al posto tuo.
Tag a livello di profilo
L'approccio più semplice: aggiungi un campo query_tags a una destinazione specifica nel tuo profilo dbt. Ogni query nel progetto erediterà automaticamente questi tag.
Ad esempio, questa singola riga contrassegna ogni query con quattro dimensioni: chi ne è il proprietario (team), a chi è addebitato il costo (cost_center), a quale pipeline appartiene (project_name) e in quale ambiente viene eseguita (env).
Tag a livello di modello
Per un'attribuzione più granulare, puoi fornire tag su modelli specifici in dbt_project.yml o nella configurazione del modello nella sua definizione sql.
I tag a livello di modello si uniscono ai tag a livello di profilo. Se entrambi definiscono la stessa chiave, il valore a livello di modello ha la priorità.
Dove appaiono i tag: system.query.history
Dopo aver eseguito dbt run, ogni istruzione SQL appare in system.query.history con la colonna query_tags popolata come MAP. Puoi interrogarla utilizzando la sintassi standard di accesso alle mappe:
Questo restituisce ogni query contrassegnata degli ultimi 7 giorni, con i tag personalizzati e inseriti automaticamente estratti in singole colonne, pronti per l'aggregazione.
Puoi anche trovare i Query Tags per la query eseguita nell'interfaccia utente della cronologia delle query o nell'interfaccia utente di monitoraggio del SQL Warehouse.

In basso a destra del Query Profile, vedrai i Query Tags che hai definito, fornendoti tutte le informazioni necessarie a colpo d'occhio.

Attribuzione dei costi con i Query Tags
I Query Tags consentono di determinare un'attribuzione granulare dell'utilizzo direttamente tramite query SQL, eliminando la necessità di analisi manuali dei log o di divisione delle risorse del warehouse.
Quali modelli dbt consumano più risorse del warehouse?
Puoi rispondere in due modi: chiedi a Genie in linguaggio naturale per un'esplorazione ad hoc o scrivi tu stesso il codice SQL per un risultato ripetibile e pronto per il dashboard. Entrambi leggono dagli stessi dati di system.query.history .
Opzione 1: Genie

Genie scrive ed esegue la query equivalente, e tu puoi continuare a fare domande di approfondimento senza toccare alcun codice SQL.
Opzione 2: SQL
Entrambi i percorsi restituiscono lo stesso quadro. Nel nostro progetto di riferimento, le quattro tabelle mart (materializzate come table) dominano il tempo di calcolo, mentre le viste di staging e le viste metriche sono quasi istantanee. Questo ti dice immediatamente dove dovrebbero concentrarsi gli sforzi di ottimizzazione.

Creazione di un dashboard di automonitoraggio
Il nostro progetto di riferimento include un dashboard AI/BI che interroga system.query.history filtrato in base ai tag di query del progetto stesso. Il risultato: la pipeline che analizza i dati di fatturazione tiene traccia anche dei propri costi, facendo dogfooding dei Query Tags su se stessa.
Il dashboard include:
- KPI: Query totali contrassegnate, secondi di calcolo totali, modelli dbt distinti
- Attività giornaliera: Numero di query e tempo di calcolo al giorno, suddivisi per ambiente
- Suddivisione per modello: Tempo di calcolo per modello, colorato per tipo di materializzazione
- Suddivisione della materializzazione: Grafico a torta che mostra come si distribuisce il calcolo tra table, view e metric_view
- Tabella dei dettagli delle query: Ogni query taggata con modello, durata, ambiente ed esecutore
Nel nostro progetto di riferimento, i quattro modelli mart rappresentavano il 92% del tempo di calcolo — senza i Query Tag, questa informazione sarebbe stata invisibile.
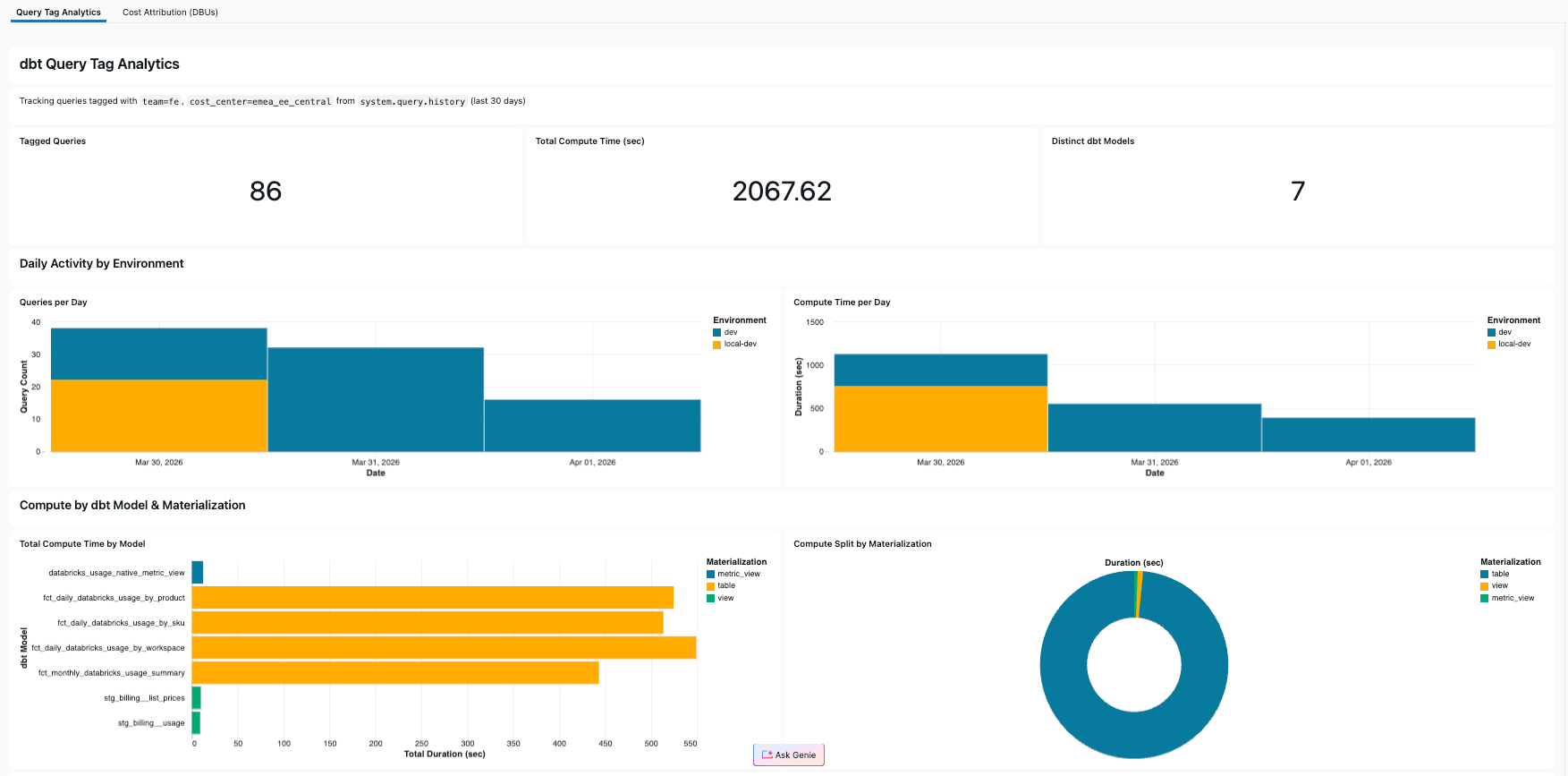
Creare questa dashboard richiede solo pochi minuti con Genie Code: chiedigli il tempo di calcolo per modello dbt da system.query.history filtrato per i tuoi tag di query, ed esso scriverà il codice SQL e genererà i grafici. Se preferisci passare direttamente al risultato finale, la dashboard è inclusa anche nel progetto di riferimento e si distribuisce con un singolo databricks bundle deploy insieme al job dbt (vedi il repository GitHub per la guida dettagliata).
Taggare le metric view
Le metric view di Databricks (disponibili con dbt-databricks 1.12+) sono un nuovo tipo di materializzazione che definisce semantiche aziendali riutilizzabili sotto forma di dimensioni e misure direttamente in Unity Catalog (vedi la documentazione completa). Possono contenere Query Tag proprio come qualsiasi altro modello, utilizzando il parametro di configurazione query_tags:
Nota la distinzione: i query_tags sono associati alle query SQL che creano o aggiornano la metric view (tracciate in system.query.history), mentre i databricks_tags sono tag di Unity Catalog sull'oggetto stesso (per la governance e la discovery). I primi servono per il tracciamento a livello di query, mentre i secondi sono a livello di oggetto di Unity Catalog per la rintracciabilità complessiva dei dati.
Best practice per il tagging dei progetti dbt
In questo articolo, abbiamo descritto il processo olistico per creare una solida pratica di FinOps in cui i Query Tag sono fondamentali per l'attribuzione dei costi. Ecco cosa abbiamo imparato creando il progetto di riferimento e parlando con i power user di dbt:
- Usa una gerarchia di tag coerente. Definisci i tag a livello aziendale nel profilo (team, cost_center, project_name, env) e riserva i tag a livello di modello per i casi eccezionali. In questo modo i tag rimangono prevedibili ed eviti la proliferazione di configurazioni per singolo modello.
- Tagga sempre l'ambiente. Usa valori di env diversi per lo sviluppo locale (local-dev) e per i job distribuiti (dev, staging, prod). Questo ti consente di separare le query di sviluppo ad-hoc dalle esecuzioni di produzione pianificate nelle tue analisi. Nel nostro progetto di riferimento, il profilo locale imposta "env": "local-dev", mentre il profilo distribuito imposta "env": "dev".
- Usa `project_name` per distinguere le pipeline. Quando più progetti dbt condividono un warehouse, project_name ti consente di attribuire i costi per pipeline senza dover suddividere i warehouse. In combinazione con il tag inserito automaticamente @@dbt_model_name, ottieni una tracciabilità completa: progetto → modello → materializzazione.
- Non esagerare con i tag. I tag inseriti automaticamente coprono già il nome del modello, il tipo di materializzazione e le versioni dell'adapter. Raramente avrai bisogno di duplicare queste informazioni nei tag personalizzati. Concentra i tag personalizzati sul contesto aziendale che dbt non può dedurre: titolarità del team, centro di costo, identità del progetto.
- Tagga esplicitamente le metric view. Poiché le metric view sono una materializzazione più recente, è utile taggarle con una chiave di funzionalità (ad es., "feature": "metric_view") in modo da poter filtrare facilmente le query di creazione delle metric view nella tua analisi dei costi.
Prova tu stesso
Il progetto di riferimento completo è disponibile su GitHub: github.com/databricks-solutions/dbt-query-tags
Per iniziare:
- Clona il repository
- Crea un ambiente virtuale Python 3.12 e installa le dipendenze: pip install dbt-databricks>=1.12.0a1
- Aggiorna profiles.yml con l'host del tuo workspace, il percorso HTTP del SQL warehouse, il catalogo e i tag di query personalizzati
- Esegui dbt deps && dbt run --profiles-dir . per eseguire la pipeline
- Interroga system.query.history per vedere i tuoi tag in azione
- Aggiorna dbt_profiles/profiles.yml e databricks.yml per fare riferimento alla configurazione corretta.
- Esegui il deploy con databricks bundle deploy per le esecuzioni pianificate e la dashboard di analisi
Sostituisci i valori con quelli del tuo team e del tuo centro di costo. Questo pattern funziona per qualsiasi progetto dbt su Databricks.
Clona il repository oggi stesso! Basta una sola riga nel tuo profilo per sbloccare la visibilità dell'attribuzione dell'utilizzo a livello di modello in tutto il tuo warehouse.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.