Come l'architettura lakehouse rimane resiliente ai guasti del cloud
di Jasraj Dange e Hans Norheim
- I carichi di lavoro degli agenti stanno rimodellando i requisiti di affidabilità del cloud. Gli agenti creano database 4 volte più velocemente degli esseri umani, richiedono infrastrutture serverless e auto-scalabili e trattano le operazioni del piano di controllo (come l'avvio di un database) come lavoro critico del piano dati. In Lakebase, avviamo ora decine di milioni di database al giorno.
- L'architettura Lakebase è costruita per la resilienza, non rattoppata per essa. Il calcolo Postgres stateless su storage a ridondanza di zona significa che le istanze possono essere sostituite istantaneamente senza hot standby o ripristino da crash. Stiamo separando le operazioni del piano di controllo hot-path in un servizio dedicato, minimizzando le dipendenze dal provider cloud e compartimentando ogni regione in celle autonome.
- Dimostriamo l'affidabilità attraverso test e misurazioni, non promesse. Ogni rilascio viene sottoposto a test di caos con iniezione di guasti a livello di processo, nodo e zona di disponibilità, convalidato rispetto a strumenti open-source come SqlLancer. Monitoriamo la disponibilità per database (non medie della flotta) rispetto a un obiettivo mensile del 99,99%, con il raggiungimento pubblicato in modo trasparente.
Nell'ultimo anno, gli agenti hanno spinto al limite l'infrastruttura cloud con nuovi modelli di utilizzo:
- Maggiore throughput delle operazioni del piano di controllo: gli agenti creano e gestiscono programmaticamente database, storage, compute e altri componenti infrastrutturali a velocità molto più elevate rispetto agli esseri umani. In Databricks Lakebase, gli agenti creano 4 volte più database degli esseri umani.
- Maggiore richiesta on-demand: l'infrastruttura serverless, autoscaling e auto-suspend è la nuova normalità. Se l'agente va in standby, perché pagare per l'infrastruttura provisionata?
- Collo di bottiglia della capacità: la domanda di compute, GPU e infrastruttura cloud è in aumento. La nozione di capacità "infinita" del cloud sta mostrando crepe.
Questa situazione è impegnativa sia per i costruttori di piattaforme che per i provider cloud. I piani di controllo stanno assistendo a significativi aumenti nel volume di richieste per la creazione, la gestione e il ridimensionamento dell'infrastruttura, mettendo a dura prova l'affidabilità. L'allocazione di nuova capacità cloud non sempre avrà successo. Allo stesso tempo, i carichi di lavoro agentici richiedono affidabilità a livello di data plane per le operazioni critiche del piano di controllo come parte dei loro flussi operativi. Negli ultimi mesi, abbiamo visto gli agenti guidare un aumento esponenziale nell'avvio di database, e ora stiamo avviando decine di milioni di database ogni giorno.
La conseguente serie di fallimenti e incidenti tra i servizi cloud ci ha insegnato lezioni che informano la nostra roadmap di affidabilità, e vogliamo condividere come stiamo rendendo l'architettura e il design del lakebase più resilienti ai fallimenti del cloud. Alcune voci sono già in produzione, altre sono in corso.
Architettura ad alta disponibilità
Alla base c'è la nostra architettura di compute e storage separati, dove l'Alta Disponibilità (HA) è un principio di progettazione fondamentale del sistema e non un'aggiunta.
Compute Postgres stateless
A differenza di molte configurazioni di servizi di database Postgres nel cloud che sono monolitiche e hanno compute stateful, Postgres nell'architettura lakebase è stateless. Tutti i dati durevoli risiedono in un servizio di storage remoto, quindi il processo di compute non detiene stato durevole sul disco locale. Se Postgres o l'hardware su cui è in esecuzione fallisce, può essere sostituito istantaneamente senza replicare i dati a uno standby attivo o eseguire il normale recupero da crash di Postgres. Uno standby attivo in una configurazione monolitica richiede una copia completa dei dati (non gratuita), mentre il recupero da crash deve riprodurre il write-ahead log dall'ultimo checkpoint, che scala con il tasso di scrittura al momento del crash e può richiedere 10 minuti, a seconda della configurazione. Poiché i contenuti del database sono archiviati nel nostro servizio di storage resiliente alle zone, un'istanza Postgres a compute singolo in Lakebase ha una disponibilità significativamente migliorata rispetto a un'istanza Postgres stateful singola, senza il costo di un'istanza di compute standby attiva aggiuntiva.
Per i database che richiedono i massimi livelli di disponibilità, è possibile configurare l'alta disponibilità. Questo provisiona compute dedicati attraverso più zone di disponibilità per il tuo database, garantendo che il tuo database rimanga disponibile anche se il provider cloud esaurisce la capacità durante (o a seguito di) l'evento di fallimento. Questi compute possono inoltre essere utilizzati per scalare le letture.
Storage ridondante per zona per tutti
Le configurazioni Postgres monolitiche sono solitamente supportate da dispositivi a blocchi locali che raramente sono ridondanti per zona. Ciò richiede la replica fisica e costose repliche standby attive attraverso più zone di disponibilità. In Lakebase e Neon, tutti i database, indipendentemente dal livello e dalla configurazione, sono supportati da storage distribuito, ridondante per zona e altamente disponibile. I dati sono archiviati in storage a oggetti altamente durevole e ridondante per zona, e le prestazioni sono accelerate da cache NVMe SSD attraverso più zone di disponibilità senza costi aggiuntivi per te.
Il piano di controllo è il nuovo data plane
Nell'architettura monolitica dei servizi di database cloud, il data plane è la parte critica del servizio. È progettato per una disponibilità del 99,99+% e stabilità statica. Il piano di controllo è importante "solo" per le operazioni di gestione. Con i carichi di lavoro agentici e on-demand, la parte del piano di controllo che avvia i database è effettivamente il data plane. Questo ha cambiato il modo in cui pensiamo alla nostra architettura. Attualmente, il nostro piano di controllo gestisce tutto, dall'avvio dei database alla fatturazione. Il primo è chiaramente più critico. Abbiamo avuto interruzioni in cui le operazioni di manutenzione in background hanno esaurito le risorse per gli avvii di database on-demand, il che chiaramente non va bene.
Stiamo attualmente lavorando duramente per separare le parti critiche del piano di controllo in un servizio di controller del data plane che gestisce solo le operazioni hot-path (avvio/sospensione). Questo servizio ha meno logica di business, un set rigoroso e minimo di dipendenze esterne (vedi la sezione successiva), ed è progettato da zero con la resilienza, il degrado graduale e la difesa in profondità come priorità principali.
Per illustrare quanto sia centrale il piano di controllo per il traffico dei database, possiamo analizzare la durata delle sessioni di compute (il tempo dall'auto-ripresa dovuta a una connessione in arrivo allo spegnimento per inattività). In Neon, il 90% delle sessioni di compute per i database con sospensione automatica dura meno di 10 minuti.
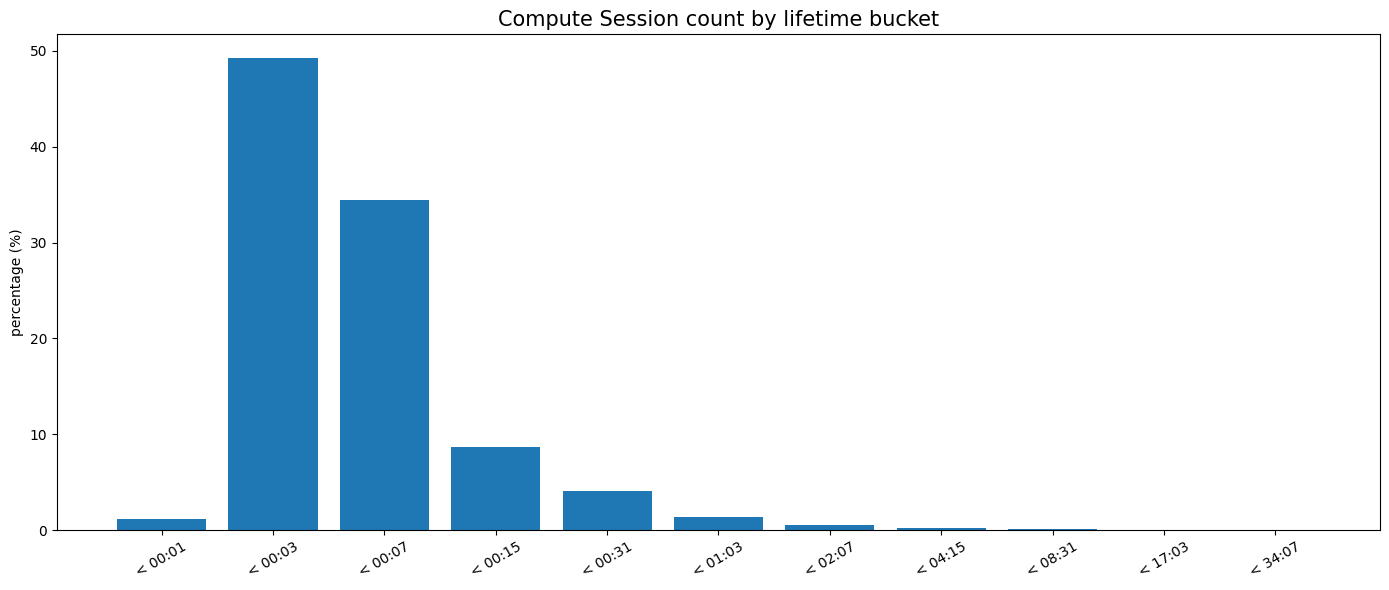
Considerare attentamente le dipendenze del percorso critico, inclusi i piani di controllo dei provider cloud
Servire i carichi di lavoro agentici significa che la creazione e la ripresa dei database devono essere altamente affidabili. L'affidabilità è fortemente correlata alla catena di dipendenze e alla quantità di macchinari coinvolti nel flusso. In una configurazione tradizionale con Postgres su VM di provider cloud, questo va ben oltre il data plane:
- Piano di controllo del compute del provider cloud per il provisioning delle VM
- Capacità VM disponibile (dove il provider cloud controlla la policy di chi la ottiene)
- Piano di controllo dello storage a blocchi del provider cloud per il provisioning dello storage locale
- Piano di controllo di rete del provider cloud per allocare IP, configurare firewall e instradamenti di rete alla nuova VM
- Se si utilizza Kubernetes (K8s) - una dipendenza aggiuntiva dai servizi di sistema K8s.
In Lakebase, adottiamo un approccio diverso che riduce drasticamente la quantità di macchinari del piano di controllo coinvolti nei flussi critici del database:
- Allocchiamo un pool di istanze grandi (spesso bare metal) dal provider cloud. Manteniamo buffer per sostenere interruzioni di provisioning del provider cloud.
- Abbiamo costruito il nostro layer di virtualizzazione autoscaling verticale che pianifica più istanze Postgres su quelle istanze cloud.
- Non ci affidiamo ai dispositivi di storage a blocchi del cloud, ma archiviamo i dati nel nostro storage resiliente alle zone che è in ultima analisi supportato da object store come S3 o Azure Blob storage.
Molti altri servizi in Databricks sperimentano le stesse sfide di affidabilità. È qui che Lakebase beneficia dall'essere parte di Databricks: Databricks ha i mezzi e sta investendo pesantemente nella costruzione di una piattaforma comune per aumentare l'affidabilità di tutti i prodotti su tutti e tre i principali cloud.
Compartimentalizzare e contenere il raggio d'azione
Invece di eseguire un'unica distribuzione regionale monolitica, Lakebase compone una regione da una o più celle identiche. Una cella è una porzione completa e autonoma dello stack Neon e Lakebase: Kubernetes, piano di controllo, calcolo e archiviazione.
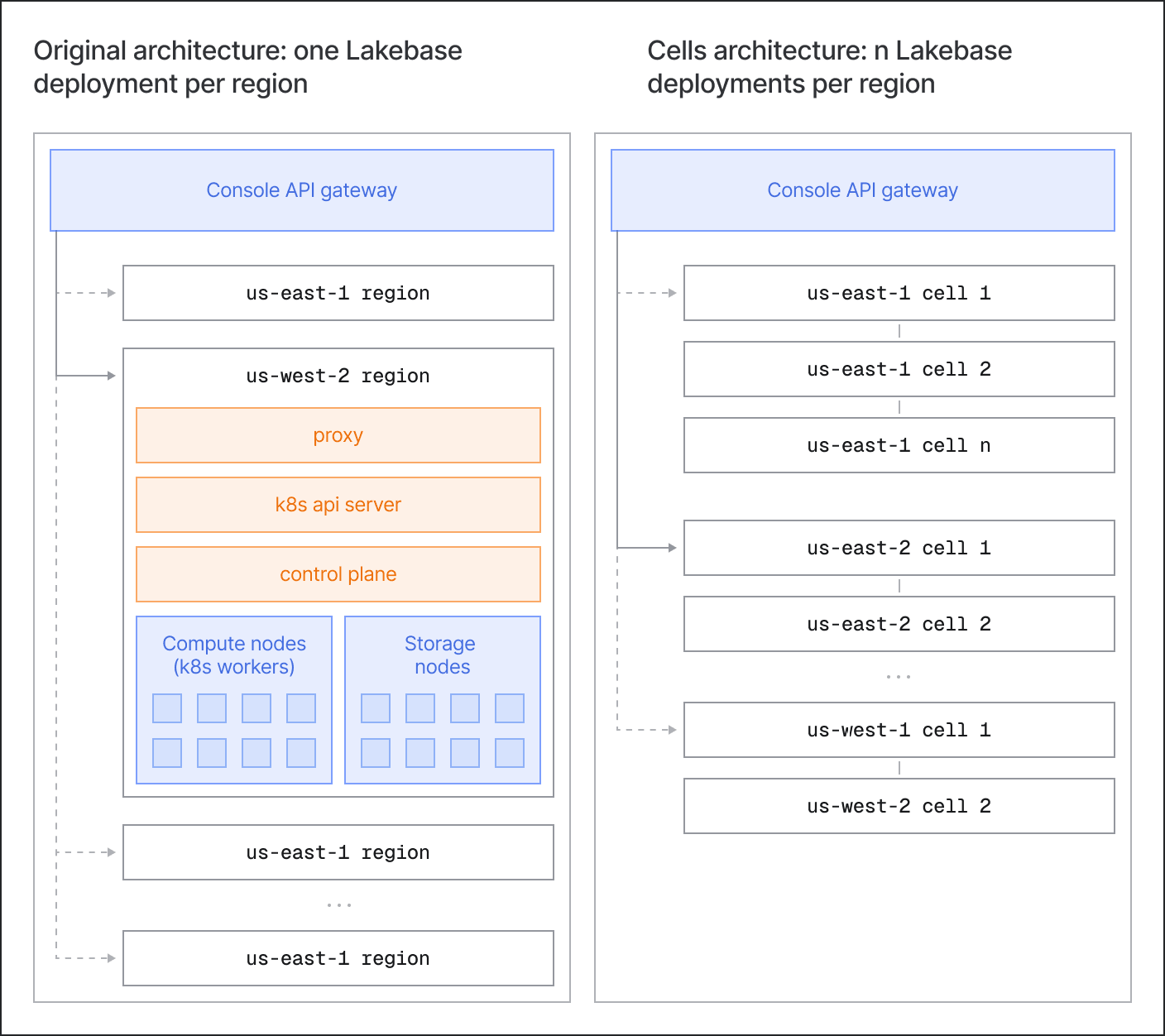
Ciò aiuta in due modi:
- Scalabilità: Per espandere una regione, aggiungiamo un'altra cella. Quando una cella esistente si avvicina ai limiti di scalabilità di Kubernetes e del piano di controllo, la creazione di nuovi progetti viene indirizzata a una cella appena predisposta. Le celle vengono attivate rapidamente man mano che la domanda cresce.
- Contenimento del raggio d'impatto: Anche con test approfonditi e protezioni integrate, le cose possono ancora andare storte in produzione: problemi al piano di controllo/servizi di sistema di Kubernetes, regressioni di codice o configurazione, situazioni di DoS, ecc. Il confine della cella isola i guasti e impedisce che la situazione si diffonda, lasciando che le altre celle nella regione continuino a servire traffico normalmente.
Insieme, ciò consente alla nostra piattaforma di scalare una regione in modo elastico, limitando al contempo il raggio d'impatto di qualsiasi singolo guasto. Durante un incidente l'8 maggio 2026, quando AWS ha riscontrato problemi con una zona di disponibilità in us-east-1, una delle celle ha avuto problemi nel failover su nodi sani. L'impatto è stato contenuto a quella cella. Le altre sette celle nella regione hanno eseguito correttamente il failover, quindi l'incidente ha interessato solo circa il 13% dei database nella regione. In questo caso, l'architettura basata su celle ha ridotto l'impatto di circa un ordine di grandezza.
Simulazione e iniezione di guasti
L'architettura di ridondanza e i principi non valgono molto se non funzionano in pratica. Si possono analizzare tutte le possibili modalità di guasto, ma la Legge di Murphy è viva e vegeta, e i sistemi complessi trovano sempre un modo per sorprenderti. Ogni rilascio di Lakebase viene sottoposto a iniezione di guasti e test di caos prima di andare in produzione. Distribuiamo il rilascio su un cluster reale, lo gestiamo con un mix di carichi di lavoro OLTP e OLAP agenti e non agenti a livello di stress e concorrenza, e poi iniziamo a rompere le cose sottostanti. Uccidiamo processi, abbattiamo nodi, iniettiamo guasti di rete, cancelliamo contenuti del disco e riavviamo componenti in loop, il tutto mentre il carico di lavoro continua a funzionare. Utilizziamo generosamente i failpoint nel nostro codice per iniettare errori difficili da riprodurre, come un crash nel momento peggiore possibile. Questo è guidato da un framework interno di iniezione di guasti che può mirare a un singolo processo o coordinare guasti a livello di cluster in un'intera cella.
Il nostro standard di superamento è più rigoroso di "il test non ha generato errori". Utilizziamo strumenti open source come SqlLancer e SqlSmith, insieme a strumenti interni simili, per verificare il corretto comportamento di Postgres. Mentre l'iniezione di guasti è in esecuzione, convalidiamo la coerenza interna dei dati, che nessuna transazione confermata sia persa e che ogni componente recuperi uno stato coerente autonomamente.
Ora stiamo portando questo un livello più su, dal caos a livello di componente alle simulazioni di interruzione di intere AZ. In un cluster reale con carichi di lavoro in esecuzione, disconnettiamo programmaticamente la rete di una zona di disponibilità dal resto del cluster e osserviamo come reagisce il sistema: quanto velocemente l'archiviazione passa a repliche sopravvissute, quanto velocemente i calcoli vengono sottoposti a failover a AZ sane, come il livello proxy reindirizza le connessioni e quanto tempo un singolo database vede un'interruzione. Il nostro obiettivo è che nessun carico di lavoro debba essere inattivo per più di 30 secondi.
Misurare, misurare, misurare
Lord Kelvin disse, “Se non puoi misurarlo, non è scienza”. Incarniamo lo stesso principio e facciamo una scienza della misurazione della disponibilità e dell'affidabilità. Lo stato visibile all'utente che vedi su https://neonstatus.com/ è una visione di alto livello. Internamente, misuriamo gli Indicatori di Livello di Servizio (SLI) e stabiliamo obiettivi (SLO) per tutti i componenti di sistema e le operazioni principali, specialmente quelle rivolte all'utente. Ad esempio, misuriamo:
- Disponibilità del database: Quanti punti percentuali del tempo ogni singolo database è disponibile. Non misuriamo solo la disponibilità aggregata della flotta, perché un singolo cliente non si preoccupa se la flotta ha avuto un'ottima disponibilità se il suo database era inattivo.
- Tempo di avvio del database: Quanto velocemente un database sospeso diventa disponibile quando ti connetti, o quanto velocemente un database nuovo di zecca si avvia.
- Switchover/failover del database: Frequenza e latenza. Il più raramente possibile e il più velocemente possibile quando accade.
- Archiviazione: Disponibilità e latenza delle letture di pagine e delle scritture durevoli da Postgres all'archiviazione. Questi ci dicono se il tuo carico di lavoro ottiene ciò di cui ha bisogno.
- API del piano di controllo: Tassi di successo e latenza di operazioni importanti come il branching.
Il nostro obiettivo è che ogni database superi il 99,99% di disponibilità ogni mese. Misuriamo quanto siamo vicini a quell'obiettivo con l'attainment: Quanti % dei database della flotta hanno raggiunto l'obiettivo. Di seguito è riportato l'attainment di disponibilità di Neon finora nel 2026 per i database attivi mensilmente.
Mese | Database che hanno raggiunto il 99,95% | Database che hanno raggiunto il 99,99% |
2026-01 | 99,96% | 99,85% |
2026-02 | 99,95% | 99,84% |
2026-03 | 99,96% | 99,81% |
2026-04 | 99,93% | 99,75% |
L'affidabilità e la disponibilità di prim'ordine sono di massima importanza nei sistemi operativi. Stiamo lavorando sodo per costruire la tua fiducia nel nostro servizio di database.
Il Team
Il lavoro di affidabilità sopra descritto è guidato da persone che hanno dedicato la loro carriera alla creazione e gestione di database relazionali. Alcuni di loro:
- Jasraj Dange - Leader dell'ingegneria per Lakebase, in precedenza ha guidato il lavoro su Azure SQL Database Performance, Scalabilità e ha reso Azure SQL Database una piattaforma robusta per le applicazioni.
- Hans Norheim - Si occupa della disponibilità e affidabilità di Lakebase, ha trascorso 13 anni in Microsoft su SQL Server e Azure SQL Database, inclusa la tecnologia di hot patching che consente di aggiornare SQL Server senza tempi di inattività e l'orchestrazione degli aggiornamenti che mantiene Azure SQL Database al suo SLA di uptime del 99,995%.
- Stas Kelvich - Ora lavora su Lakebase dopo aver co-fondato Neon. Prima di Neon, ha lavorato su interni di Postgres presso Postgres Professional per cinque anni, inclusa la replica multi-master tollerante ai guasti con commit di quorum, l'isolamento dello snapshot tra nodi utilizzando clock non perfettamente sincronizzati e miglioramenti al two-phase commit e alla replica logica.
- John Spray - Guida Lakebase Storage. In precedenza ha guidato lo storage e il calcolo apportando miglioramenti chiave alla scala come lo sharding. Prima di ciò, ha lavorato su storage e sistemi distribuiti presso Redpanda, Red Hat (Ceph) e Intel.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.