Come Superhuman e Databricks hanno creato insieme una piattaforma di inferenza da 200K QPS
Superhuman e gli ingegneri Databricks spiegano come hanno migrato congiuntamente i carichi di lavoro di correzione ortografica e grammaticale sulla Databricks Model Serving Platform, servendo oltre 200.000 QPS, con aumenti di throughput del 60% e...
di Christoph Stüber, Wai Wu, Arjun DCunha, Amine El Helou, Tian Ouyang e Alex Coleman
- Superhuman è migrato da uno stack vLLM fai-da-te a Databricks FMAPI Provisioned Throughput, servendo ora un LLM personalizzato a oltre 200.000 QPS con latenza P99 inferiore al secondo. Ciò ha permesso al team di ingegneria di Superhuman di concentrarsi sulla creazione e sul miglioramento del proprio prodotto, delegando alla Databricks Platform la gestione della scalabilità e dell'infrastruttura.
- Le ottimizzazioni ingegneristiche congiunte hanno portato a un aumento del throughput del 60% per GPU (750 → 1.200 QPS per pod H100) e hanno ridotto i costi di serving attraverso la quantizzazione FP8, eliminando l'overhead lato CPU e ottimizzando i kernel di attenzione sull'architettura Hopper, il tutto ottenuto senza regressioni di qualità.
- Databricks FMAPI scala in modo affidabile fino a oltre 250 GPU attraverso bilanciamento del carico di livello produttivo, autoscaling e avvio rapido dei container; con test di stress di pre-produzione che garantiscono il rispetto degli obiettivi di disponibilità e latenza p99 prima che il traffico raggiunga la produzione.
Dai partner di analisi ai partner di inferenza in tempo reale
Superhuman, la piattaforma di produttività che include Superhuman, Coda, Superhuman Mail e Superhuman Go, serve oltre 40 milioni di utenti giornalieri in decine di lingue. L'assistenza alla comunicazione AI di Superhuman fornisce suggerimenti in tempo reale per correttezza, chiarezza, tono e stile su ogni superficie in cui le persone scrivono.
Databricks e Superhuman sono partner da anni. Il team di Superhuman ha storicamente utilizzato la Databricks Data Intelligence Platform come base per l'analisi. Ma l'analisi era solo metà del quadro.
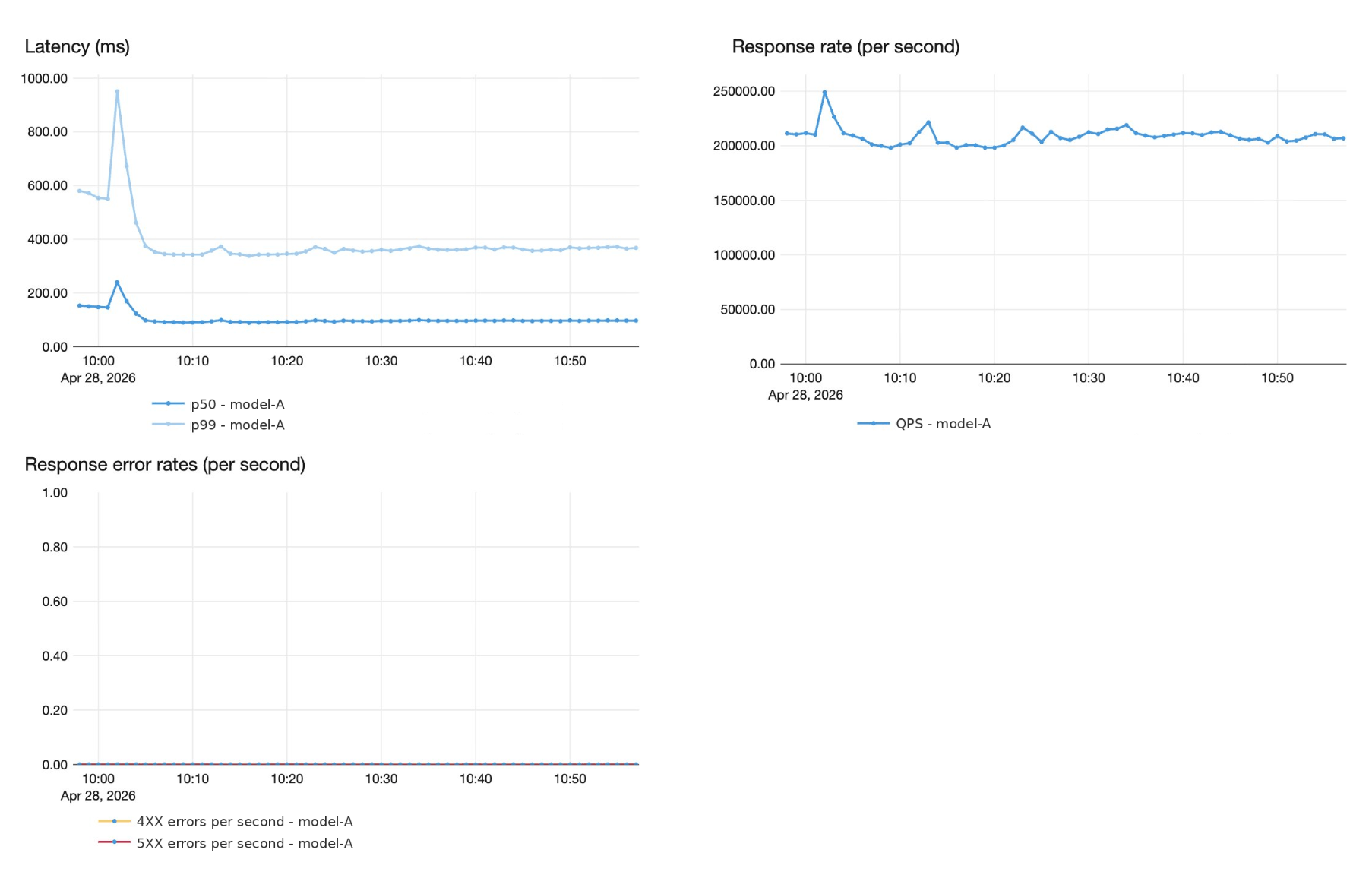
Dietro molti dei suggerimenti in tempo reale di Superhuman si cela un modello AI personalizzato altamente sofisticato, servito su larga scala. Superhuman esegue questo modello con un traffico di picco di oltre 200.000 query al secondo, con una latenza end-to-end inferiore a 1 secondo a P99 e rigorose garanzie di affidabilità 4 9. Superhuman ha modernizzato il proprio stack di serving per i modelli linguistici di grandi dimensioni sfruttando il model serving di Databricks, che ha richiesto un nuovo tipo di partnership, basata su un lavoro congiunto di prodotto e ingegneria.
Come Superhuman ha modernizzato il suo stack di serving
Prima di questa migrazione, Superhuman utilizzava uno stack di serving fai-da-te basato su vLLM, insieme a strumenti interni per l'addestramento e la gestione dei modelli. Un team interno di infrastruttura ML manteneva questo stack, che supportava una scala massiccia, ma diversi punti dolenti si stavano accumulando durante il serving di modelli linguistici di grandi dimensioni.
Il modello linguistico di grandi dimensioni personalizzato alimenta la correzione degli errori grammaticali a volumi enormi, oltre 200.000 QPS di picco con circa 50 token di input e 50 token di output per richiesta. Stava spingendo i limiti di ciò che lo stack basato su GPU L40S poteva offrire. Ogni nuova iterazione del modello richiedeva mesi di ottimizzazione manuale delle prestazioni per essere integrata. Nel frattempo, l'onere operativo stava crescendo, con la pianificazione della capacità, l'ottimizzazione delle prestazioni e l'autoscaling che consumavano tempo da un team snello che doveva concentrarsi sulla qualità del modello e sulle innovazioni di prodotto.
Superhuman necessitava di un partner di piattaforma che potesse impegnarsi a rispettare SLA di prestazioni e latenza sullo stack di serving, e che co-investisse nell'ingegneria necessaria per raggiungerli. Entrambi i team hanno definito in anticipo gli SLO di latenza in tempo reale target: latenza p99 inferiore al secondo e zero regressioni di qualità sugli harness di valutazione interni di Superhuman.
Raggiungere gli SLA in tempo reale sull'infrastruttura della piattaforma
Raggiungere gli obiettivi di latenza su un singolo pod è necessario ma non sufficiente. Servire oltre 200.000 QPS in modo affidabile richiede un'infrastruttura in grado di bilanciare il carico, scalare dinamicamente e assorbire picchi. Per ottenere questo risultato è stata necessaria una stretta collaborazione tra entrambi i team.
Ottimizzazione del bilanciamento del carico: scelte basate sulla potenza di due
Il traffico dell'endpoint di correzione grammaticale di Superhuman presenta forti schemi diurni con rapidi incrementi in determinati periodi, spesso superiori a 200.000 QPS. Sebbene il bilanciatore del carico round robin predefinito di Kubernetes sia sufficiente a bassi QPS, i nostri test hanno rivelato che le prestazioni degradano ad alti QPS, con una distribuzione non uniforme delle richieste che crea hotspot che aumentano la latenza di coda.
Al centro del nostro approccio c'è l'Endpoint Discovery Service (EDS), un control plane leggero che monitora continuamente l'API Kubernetes per le modifiche a Services ed EndpointSlices. L'EDS guida un algoritmo di bilanciamento del carico personalizzato basato sulla potenza di due scelte (citazione). Per ogni richiesta, vengono campionati due pod candidati e il traffico viene instradato a quello con meno richieste attive, prevenendo gli hotspot che il round-robin crea ad alti QPS (vedi blog).
Per mantenere la piattaforma economicamente vantaggiosa per schemi di traffico variabili, il sistema scala dinamicamente in base alla domanda dei clienti. L'autoscaler monitora request_concurrency mediato tra i pod, con obiettivi di concorrenza per pod derivati dal benchmarking del massimo RPS sostenibile per replica. La strategia di scaling è intenzionalmente asimmetrica: lo scale-up è aggressivo e reattivo, mentre lo scale-down è conservativo, per prevenire il flapping che causa picchi di latenza. Attraverso test congiunti di shadow tra Superhuman e Databricks, abbiamo individuato casi limite e risolto problemi durante l'ottimizzazione dei parametri sull'autoscaler, incluso quando scalare aggressivamente, quando mantenere la stabilità e quanto essere conservativi nello scale-down.
Ottimizzazione dell'avvio dei container tramite accelerazione delle immagini
Quando il traffico dell'endpoint di Superhuman passa da un picco all'altro, l'autoscaler deve aggiungere dozzine di pod. Se ogni pod impiega minuti per scaricare la sua immagine container e avviarsi, gli utenti sperimentano picchi di latenza durante l'aumento. Ridurre il tempo di avvio del pod si traduce direttamente in uno scale-up più rapido e una latenza più fluida durante i picchi di traffico.
Il team di Databricks model serving ha adottato il lavoro di accelerazione delle immagini originariamente creato per il calcolo serverless (blog) per evitare i cold start. L'approccio si adatta bene ai modelli relativamente piccoli che servivamo per Superhuman.
Quando si crea un'immagine container, aggiungiamo un passaggio extra per convertire il formato standard dell'immagine basato su gzip nel formato basato su block device adatto al lazy loading. Ciò consente all'immagine container di essere rappresentata come un block device ricercabile con settori da 4 MB in produzione.
Quando si scaricano le immagini container, il nostro runtime container personalizzato recupera solo i metadati necessari per impostare la directory root del container, inclusi struttura delle directory, nomi dei file e permessi, e crea un block device virtuale di conseguenza. Quindi monta il block device virtuale nel container in modo che l'applicazione possa iniziare a funzionare immediatamente.
Quando l'applicazione legge un file per la prima volta, la richiesta I/O sul block device virtuale emetterà una callback al processo di recupero dell'immagine, che recupera il contenuto effettivo del blocco dal registro container remoto. Il contenuto del blocco recuperato viene anche memorizzato nella cache localmente per evitare ripetuti round trip di rete al registro container, riducendo l'impatto della latenza di rete variabile sulle letture future.
Questo filesystem container con lazy-loading elimina la necessità di scaricare l'intera immagine container prima di avviare l'applicazione, riducendo il tempo di avvio del container da diversi minuti a pochi secondi.
Ottimizzazioni del runtime: 60% in più di throughput per pod
Con il livello della piattaforma che gestisce la scalabilità dell'intera flotta, la domanda successiva era quanti QPS ogni pod potesse supportare e a quale costo.
In questa sezione, illustriamo le ottimizzazioni che hanno aumentato il throughput per pod da 750 QPS a 1.200 QPS su GPU H100, un miglioramento del 60%, mantenendo zero regressioni di qualità.
Quantizzazione FP8
La quantizzazione FP8 è stato il singolo miglioramento del throughput più significativo, ottenendo un aumento fino al 30% dei QPS per pod.
Il team ML di Superhuman ha pre-quantizzato il checkpoint a FP8 utilizzando la libreria di quantizzazione online di vLLM, producendo un checkpoint in formato tensore compresso che Databricks ha caricato per il serving. Nella configurazione finale, le proiezioni di attenzione (Q, K, V e output) e le proiezioni MLP sono state tutte eseguite tramite il percorso FP8, mentre la quantizzazione KV-cache è stata lasciata disabilitata, poiché la quantizzazione dei pesi era dove si trovavano i vantaggi di throughput e la quantizzazione KV-cache introduceva compromessi di qualità propri che non valeva la pena perseguire per questo carico di lavoro.
Prima di definire la configurazione finale, entrambi i team hanno iterato su quali layer quantizzare. Le proiezioni MLP sono state quantizzate fin dall'inizio, e la domanda aperta era se quantizzare i layer di attenzione. Il model serving di Databricks aveva progettato il motore di serving per supportare l'inferenza a precisione ibrida fin dall'inizio, in modo che se un gruppo di layer si fosse dimostrato troppo sensibile alla qualità sotto quantizzazione, avremmo potuto mantenerlo a una precisione maggiore senza modificare l'architettura di serving complessiva. Abbiamo rilasciato un flag che ci ha permesso di attivare e disattivare la quantizzazione dell'attenzione, in modo che entrambi i team potessero misurarne direttamente l'impatto. L'esperimento è andato a buon fine, la quantizzazione delle proiezioni Q/K/V e output non ha prodotto alcuna degradazione misurabile della qualità sulle valutazioni di Superhuman.
L'altra considerazione è stata la granularità della quantizzazione. I kernel standard utilizzati la scalatura per tensore (un singolo fattore di scala FP8 per un intero tensore di pesi). I kernel di Databricks utilizzano la scalatura per canale, calcolando un fattore di scala separato per ogni canale di output di ogni layer lineare. Ciò preserva il range dinamico dove conta, mantiene l'errore di quantizzazione del layer MLP ben al di sotto della soglia in cui si manifesta nelle valutazioni. Combinata con miglioramenti a livello di kernel, la quantizzazione per canale ha eguagliato o superato altri baseline open source alla stessa velocità effettiva.
Eliminazione dei colli di bottiglia lato CPU
Per modelli piccoli e veloci, le prestazioni sono spesso limitate dalla CPU, non dalla GPU. Il team Databricks aveva già studiato l'eliminazione dei colli di bottiglia della CPU nel loro lavoro su fast PEFT serving e qui ha applicato ottimizzazioni CPU simili direttamente al carico di lavoro di Superhuman.
In particolare, il team ha introdotto un server runtime multiprocessing. Per la maggior parte dei carichi di lavoro di model serving, un singolo processo è più che sufficientemente veloce per mantenere la GPU satura, poiché la GPU è il collo di bottiglia, non la CPU. Ma con un modello piccolo e veloce, la GPU completa il suo forward pass più velocemente di quanto un singolo processo possa preparare il batch successivo, spostando il collo di bottiglia sulla CPU.
Il team ha risolto questo problema eseguendo più processi server RPC. Avendo più processi CPU che preparano e distribuiscono il lavoro alla GPU in parallelo, abbiamo eliminato il collo di bottiglia di serializzazione a processo singolo. Ciò ha fornito un ulteriore 20% di throughput aggiuntivo.
Altre ottimizzazioni lato CPU hanno migliorato le prestazioni di alcuni punti percentuali.
- Ridotto l'overhead di Python. Abbiamo sostituito lo slicing, la copia e il riempimento dei tensori a livello Python all'inizio di ogni passaggio di decodifica del grafo CUDA con una singola chiamata C++. Abbiamo anche esplorato strategie parallele (ThreadPool, OpenMP) ma il C++ single-threaded è stato ottimale a causa dell'overhead di sincronizzazione CUDA. Ciò ha ridotto leggermente l'inattività della GPU per ogni forward pass.
- Pianificazione asincrona per una migliore sovrapposizione del lavoro CPU-GPU. Abbiamo spostato il post-processing lato CPU fuori dal percorso critico in modo che venga eseguito in concorrenza con il successivo forward pass della GPU. Invece di completare tutto il post-processing per il batch N prima di avviare il batch N+1, lo scheduler distribuisce immediatamente N+1 e gestisce il post-processing di N in parallelo. Il post-processing itera anche solo sul sottoinsieme pertinente di richieste anziché sull'intero batch. Ciò ha comportato l'avvio anticipato del successivo forward pass.
Cosa succederà
Questo lavoro è la base per una partnership più ampia. Superhuman sta ora migrando modelli aggiuntivi a Databricks, che coprono diverse dimensioni di modelli, tipi di attività e requisiti di latenza, e sta adottando più ampiamente la Piattaforma AI per flussi di lavoro di training, tracciamento degli esperimenti, valutazioni (ML classico, Deep-Learning e AI Generativa/Agenti), registro di modelli e giudici (LLM) e ingestione di tracce di agenti su larga scala.
La costruzione di questa piattaforma su larga scala è stata uno sforzo aziendale da entrambe le parti e un'esperienza di apprendimento straordinaria. Un enorme ringraziamento ai team ML e infrastrutturali di Superhuman per la profonda collaborazione, la volontà di iterare apertamente su compromessi difficili e il rigore che hanno portato a ogni barra di qualità e test di carico. Il playbook di ingegneria che abbiamo costruito insieme è loro tanto quanto nostro, e siamo entusiasti di portare lo stesso livello di partnership a ogni carico di lavoro che seguirà.
Punti chiave
L'utilizzo di un servizio di inferenza gestito non significa dover rinunciare al controllo. Superhuman mantiene la piena proprietà del training del modello, della quantizzazione e degli standard di qualità, mentre Databricks mantiene le prestazioni di runtime e l'affidabilità della piattaforma. Questa divisione delle responsabilità funziona bene con SLO condivisi, validazione congiunta della qualità e test di carico progressivi durante l'onboarding sulla piattaforma Databricks.
Pronto a servire i tuoi modelli personalizzati su larga scala? Scopri come l'API Databricks Foundation Model può soddisfare i tuoi SLA di inferenza più esigenti e offrire al tuo team un vero partner di ingegneria, non solo un servizio gestito. Contattaci su https://www.databricks.com/company/contact per integrare il tuo caso d'uso di model-serving ad alto QPS.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.