Come effettuiamo il debug di migliaia di database con l'IA in Databricks
Lezioni dalla creazione di una piattaforma di debug per database assistita dall'IA
- In Databricks, gestiamo migliaia di istanze OLTP in centinaia di regioni su AWS, Azure e GCP.
- Abbiamo creato una piattaforma agent-based che unifica metriche, strumenti e competenze per aiutare i nostri ingegneri a gestire i loro database su questa scala.
- Questa piattaforma agent-based è ora utilizzata a livello aziendale, riducendo il tempo di debug fino al 90% e accorciando la curva di apprendimento per la gestione della nostra infrastruttura.
In Databricks, abbiamo sostituito le operazioni manuali sui database con l'IA, riducendo il tempo dedicato al debug fino al 90%.
Il nostro agente IA interpreta, esegue e debugga recuperando metriche e log chiave e correlando automaticamente i segnali. Opera su una flotta di database distribuiti su ogni cloud principale e in quasi ogni regione cloud.
Questa nuova capacità agentiva ha permesso agli ingegneri di rispondere regolarmente a domande in linguaggio naturale sulla salute e le prestazioni del loro servizio senza dover contattare gli ingegneri di turno nei team di storage.
Ciò che è iniziato come un piccolo progetto di hackathon per semplificare il flusso di indagine si è evoluto in una piattaforma intelligente con adozione a livello aziendale. Questo è il nostro percorso.
Prima dell'IA: Tutto Funzionava, ma Niente Funzionava Insieme
Durante una tipica indagine su un incidente MySQL, un ingegnere spesso
- Controllava le metriche in Grafana
- Passava a una dashboard Databricks per comprendere il carico di lavoro del client
- Eseguiva comandi CLI per ispezionare lo stato di InnoDB, uno snapshot dello stato interno di MySQL che contiene informazioni come la cronologia delle transazioni, le operazioni di I/O e i dettagli dei deadlock
- Accedeva a una console cloud per scaricare i log delle query lente
Ogni strumento funzionava bene da solo, ma insieme non riuscivano a formare un flusso di lavoro coeso o a fornire insight end-to-end. Un ingegnere MySQL esperto poteva mettere insieme un'ipotesi saltando tra schede e comandi nella sequenza giusta; tuttavia, questo consumava prezioso budget SLO e tempo nel processo. Un ingegnere più giovane spesso non sapeva da dove iniziare.
Ironicamente, questa frammentazione nei nostri strumenti interni rifletteva la sfida che Databricks aiuta i nostri clienti a superare.
La Databricks Data Intelligence Platform unifica dati, governance e IA, consentendo agli utenti autorizzati di comprendere i propri dati e agire su di essi. Internamente, i nostri ingegneri richiedono la stessa cosa: una piattaforma unificata che consolidi i dati e i flussi di lavoro che supportano la nostra infrastruttura. Con tale base, possiamo applicare l'intelligenza utilizzando l'IA per interpretare i dati e guidare gli ingegneri verso il passo successivo corretto.
Il Nostro Percorso: Dall'Hackathon agli Agenti Intelligenti
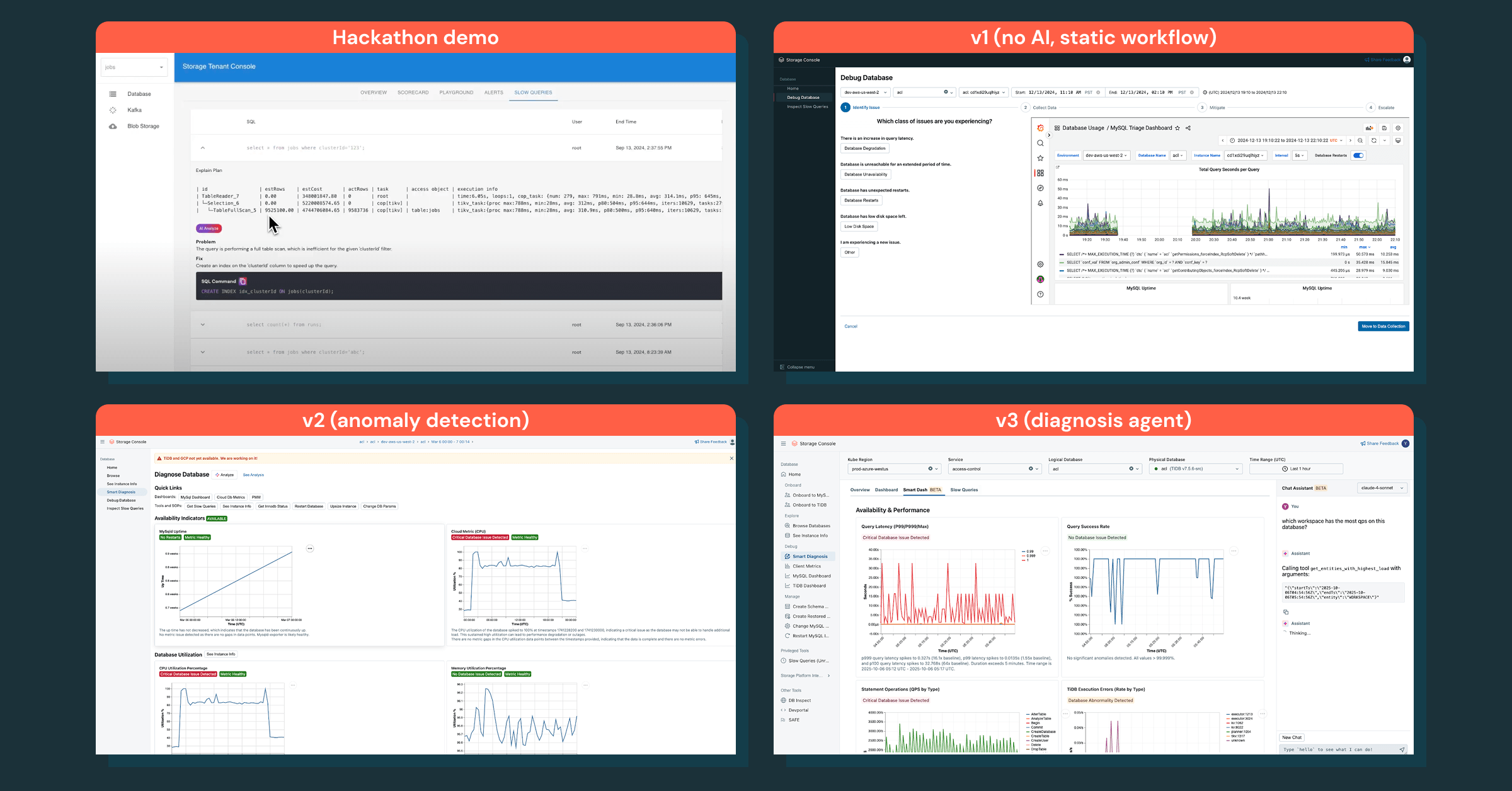
Non abbiamo iniziato con un'iniziativa ampia e pluriennale. Invece, abbiamo testato l'idea durante un hackathon aziendale. In due giorni, abbiamo creato un semplice prototipo che ha unificato alcune metriche e dashboard di database fondamentali in una singola vista. Non era rifinito, ma ha immediatamente migliorato i flussi di lavoro di indagine di base. Questo ha stabilito il nostro principio guida: muoversi velocemente e rimanere ossessionati dal cliente.
Costruire Piattaforme con Ossessione per il Cliente
Prima di scrivere altro codice, abbiamo intervistato i team di servizio per comprendere i loro punti dolenti nel debug. I temi erano coerenti: i giovani ingegneri non sapevano da dove iniziare e gli ingegneri senior trovavano gli strumenti frammentati e ingombranti.
Per vedere il problema in prima persona, abbiamo affiancato le sessioni di reperibilità e osservato gli ingegneri eseguire il debug dei problemi in tempo reale. Sono emersi tre schemi:
- Strumenti frammentati
Gli ingegneri gestivano dashboard, CLI e passaggi manuali per indagini e operazioni come riavvii o ripristini. Ogni strumento funzionava in isolamento, ma la mancanza di integrazione rendeva il flusso di lavoro lento e soggetto a errori. - Tempo sprecato a raccogliere contesto
La maggior parte del lavoro consisteva nello scoprire cosa era cambiato, come appariva la normalità e chi avesse il contesto giusto per aiutare, ma non nel mitigare effettivamente l'incidente. - Guida poco chiara sulla mitigazione sicura
Durante gli incidenti, gli ingegneri spesso non erano sicuri di quali azioni fossero sicure o efficaci. Senza runbook chiari o automazione, si affidavano a lunghe indagini o aspettavano gli esperti.
Guardando indietro, i postmortem raramente esponevano questa lacuna: i team non mancavano di dati o strumenti; mancavano di debugging intelligente per interpretare il flusso di segnali e guidarli verso azioni sicure ed efficaci.
Iterare Verso l'Intelligenza
Abbiamo iniziato in piccolo, con l'indagine sui database come primo caso d'uso. La nostra v1 era un flusso di lavoro agentivo statico che seguiva una SOP di debug, ma non era efficace: gli ingegneri volevano un report diagnostico con insight immediati, non una checklist manuale.
Abbiamo spostato la nostra attenzione sull'ottenimento dei dati giusti e sulla stratificazione dell'intelligenza sopra di essi. Questa strategia ha portato al rilevamento delle anomalie, che ha fatto emergere le anomalie giuste, ma non ha ancora fornito chiari passi successivi.
La vera svolta è arrivata con un assistente di chat che codifica la conoscenza di debug, risponde alle domande di follow-up e trasforma le indagini in un processo interattivo. Questo ha trasformato il modo in cui gli ingegneri eseguono il debug degli incidenti end-to-end.
Una Base: Astrazione e Centralizzazione
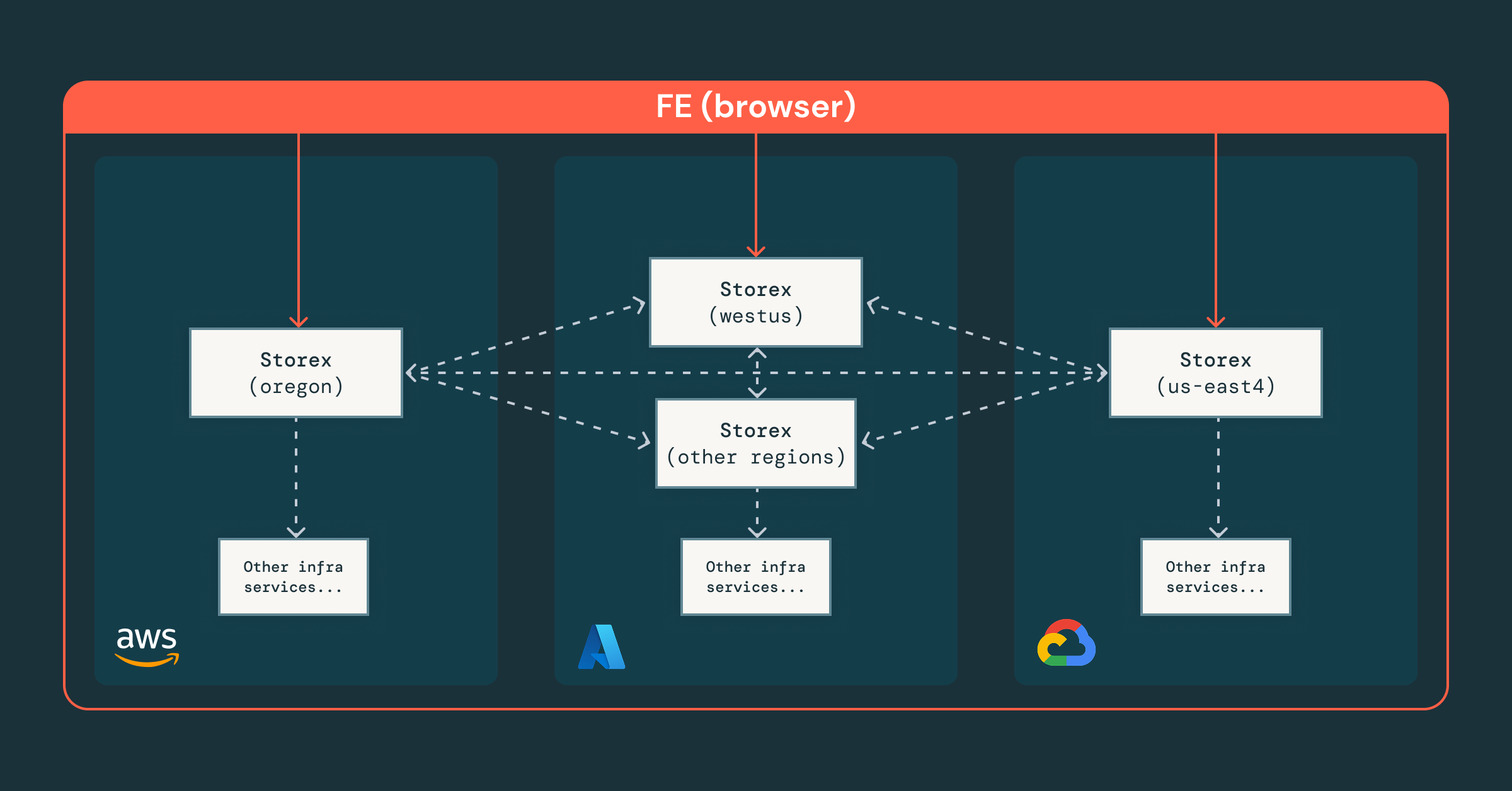
Facendo un passo indietro, ci siamo resi conto che, sebbene il nostro framework esistente potesse unificare flussi di lavoro e dati in un'unica interfaccia, il nostro ecosistema non era costruito per consentire all'IA di ragionare sul nostro panorama operativo. Qualsiasi agente dovrebbe gestire la logica specifica della regione e del cloud. E senza controlli di accesso centralizzati, diventerebbe o troppo restrittivo per essere utile o troppo permissivo per essere sicuro.
Questi problemi sono particolarmente difficili da risolvere in Databricks, poiché gestiamo migliaia di istanze di database in centinaia di regioni, otto domini normativi e tre cloud. Senza una solida base che astragga le differenze cloud e normative, l'integrazione dell'IA si imbatterebbe rapidamente in una serie di ostacoli inevitabili:
- Frammentazione del contesto: I dati di debug risiedevano in luoghi diversi, rendendo difficile per un agente costruire un quadro coerente.
- Confini di governance poco chiari: Senza autorizzazione centralizzata e applicazione delle policy, diventa difficile garantire che l'agente (e gli ingegneri) rimangano entro le autorizzazioni corrette.
- Lenti cicli di iterazione: Astrazioni incoerenti rendono difficile testare ed evolvere il comportamento dell'IA, rallentando gravemente l'iterazione nel tempo.
Per rendere lo sviluppo dell'IA sicuro e scalabile, ci siamo concentrati sul rafforzamento delle fondamenta della piattaforma attorno a tre principi:
- Architettura sharded centralizzata, in cui un'istanza globale di Storex coordina gli shard regionali, fornendo un'unica interfaccia mantenendo i dati sensibili locali e conformi.
- Controllo degli accessi granulare, applicato a livello di team, risorsa e RPC, garantendo che ingegneri e agenti operino in sicurezza entro le autorizzazioni corrette.
- Orchestrazione unificata, in cui la nostra piattaforma integra i servizi di infrastruttura esistenti, consentendo astrazioni coerenti tra cloud e regioni.
Con dati e contesto centralizzati, il passo successivo è diventato chiaro: come potevamo rendere la piattaforma non solo unificata, ma intelligente?
Dalla Visibilità all'Intelligenza
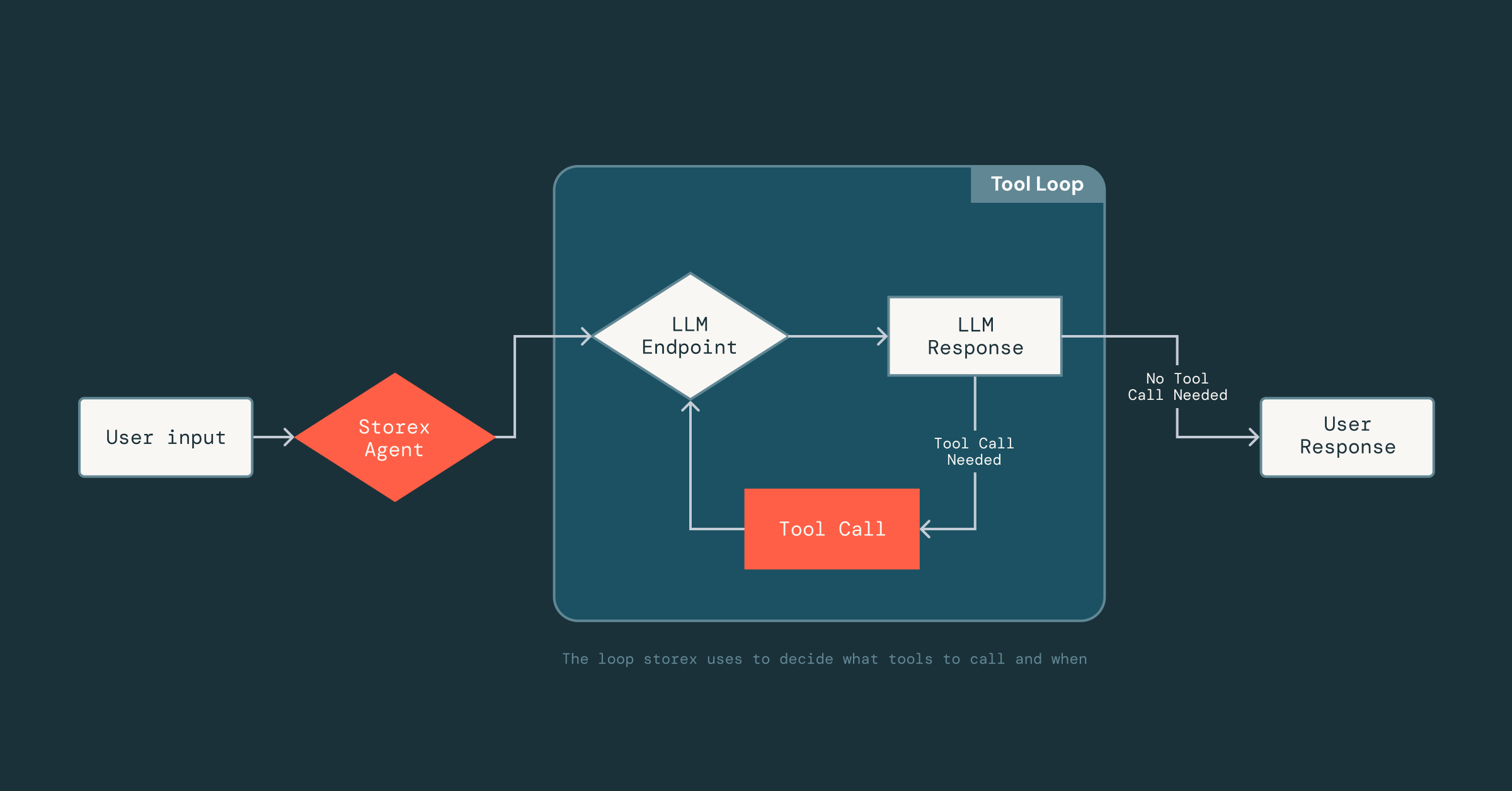
Con una base unificata in atto, implementare ed esporre funzionalità come il recupero di schemi di database, metriche o log di query lente all'agente IA è stato semplice. Nel giro di poche settimane, abbiamo creato un agente in grado di aggregare informazioni di base sul database, ragionare su di esse e presentarle all'utente.
Ora la parte difficile era rendere l'agente affidabile: dato che gli LLM sono non deterministici, non sapevamo come avrebbe risposto agli strumenti, ai dati e ai prompt a cui aveva accesso. Ottenere questo risultato ha richiesto molta sperimentazione per capire quali strumenti fossero efficaci e quale contesto includere (o escludere) nei prompt.
Per abilitare questa rapida iterazione, abbiamo creato un framework leggero ispirato alle tecnologie di ottimizzazione dei prompt di MLflow che sfrutta DsPy, che disaccoppia il prompting dall'implementazione degli strumenti. Gli ingegneri possono definire gli strumenti come normali classi Scala e firme di funzioni, e semplicemente aggiungere una breve docstring che descrive lo strumento. Da lì, l'LLM può dedurre il formato di input dello strumento, la struttura di output e come interpretare i risultati. Questo disaccoppiamento ci consente di muoverci velocemente: possiamo iterare sui prompt o scambiare strumenti dentro e fuori dall'agente senza cambiare costantemente l'infrastruttura sottostante che gestisce il parsing, le connessioni LLM o lo stato della conversazione.
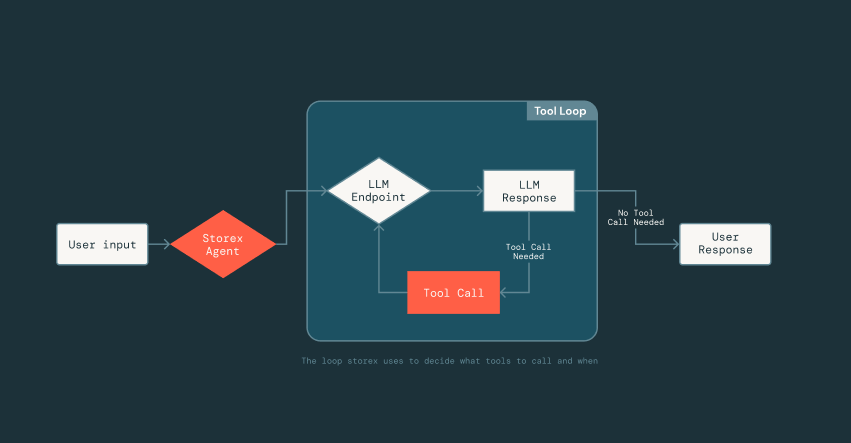{kind=link}
Mentre iteriamo, come dimostriamo che l'agente sta migliorando senza introdurre regressioni? Per affrontare questo problema, abbiamo creato un framework di validazione che cattura snapshot dello stato di produzione e li riproduce attraverso l'agente, utilizzando un LLM "giudice" separato per valutare le risposte in termini di accuratezza e utilità mentre modifichiamo i prompt e gli strumenti.
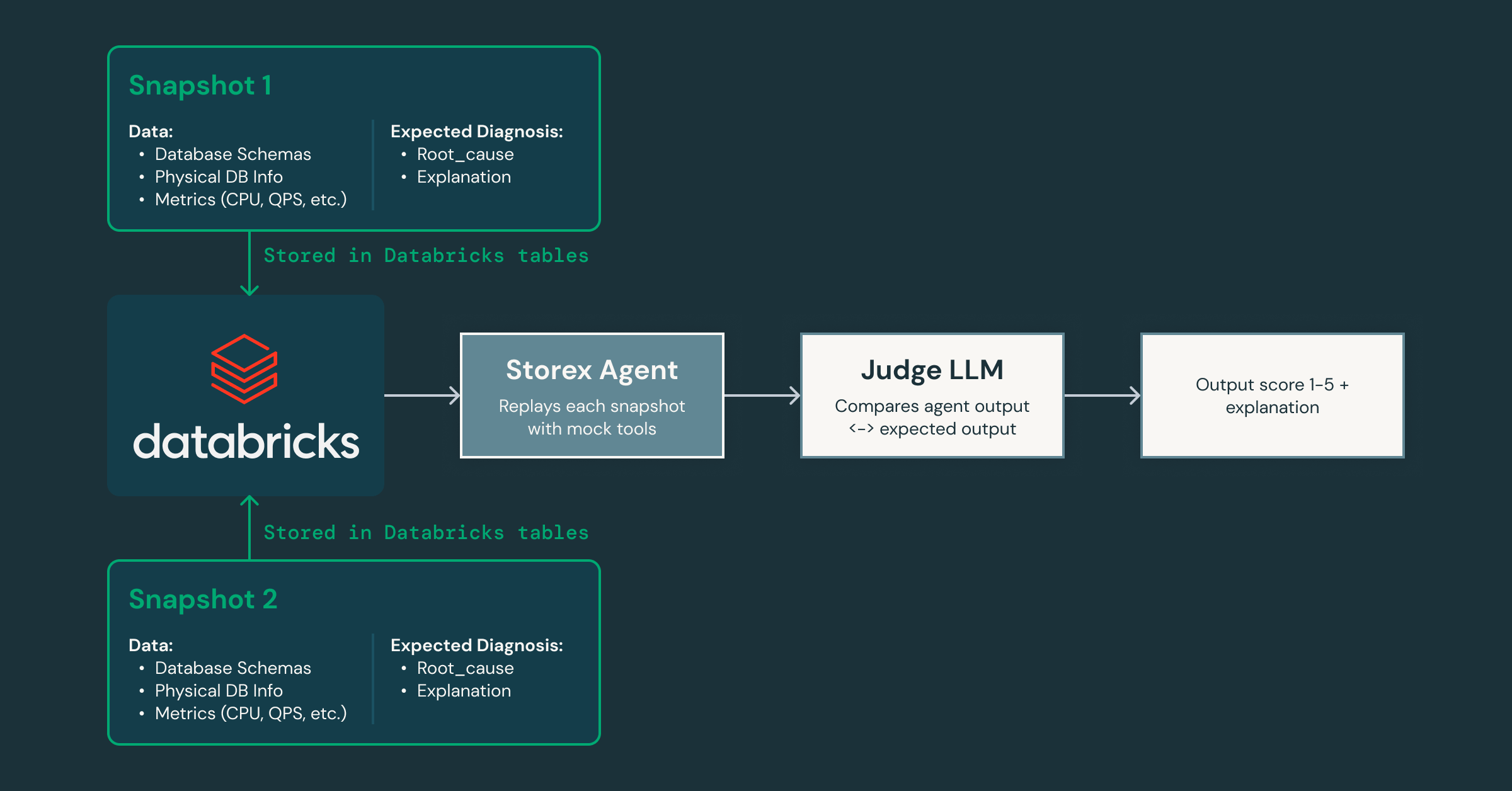
Poiché questo framework ci consente di iterare rapidamente, possiamo facilmente creare agenti specializzati per diversi domini: uno focalizzato su problemi di sistema e database, un altro su pattern di traffico lato client, e così via. Questa scomposizione consente a ciascun agente di acquisire una profonda competenza nella propria area, collaborando al contempo con altri per fornire un'analisi delle cause profonde più completa. Apre anche la strada all'integrazione di agenti AI in altre parti della nostra infrastruttura, estendendosi oltre i database.
Con conoscenze esperte e contesto operativo codificati nel suo ragionamento, il nostro agente può estrarre insight significativi e guidare attivamente gli ingegneri attraverso le indagini. In pochi minuti, individua log e metriche pertinenti che gli ingegneri potrebbero non aver considerato di esaminare. Collega sintomi tra i livelli, come l'identificazione del workspace che genera un carico imprevisto e la correlazione dei picchi di IOPS con recenti migrazioni di schema. Spiega persino la causa e l'effetto sottostanti e raccomanda i prossimi passi per la mitigazione.
Insieme, questi pezzi segnano il nostro passaggio dalla visibilità all'intelligenza. Siamo andati oltre la visibilità da strumenti e metriche a un livello di ragionamento che comprende i nostri sistemi, applica conoscenze esperte e guida gli ingegneri verso mitigazioni sicure ed efficaci. È una base su cui possiamo continuare a costruire non solo per i database, ma anche per il modo in cui operiamo l'infrastruttura nel suo complesso.
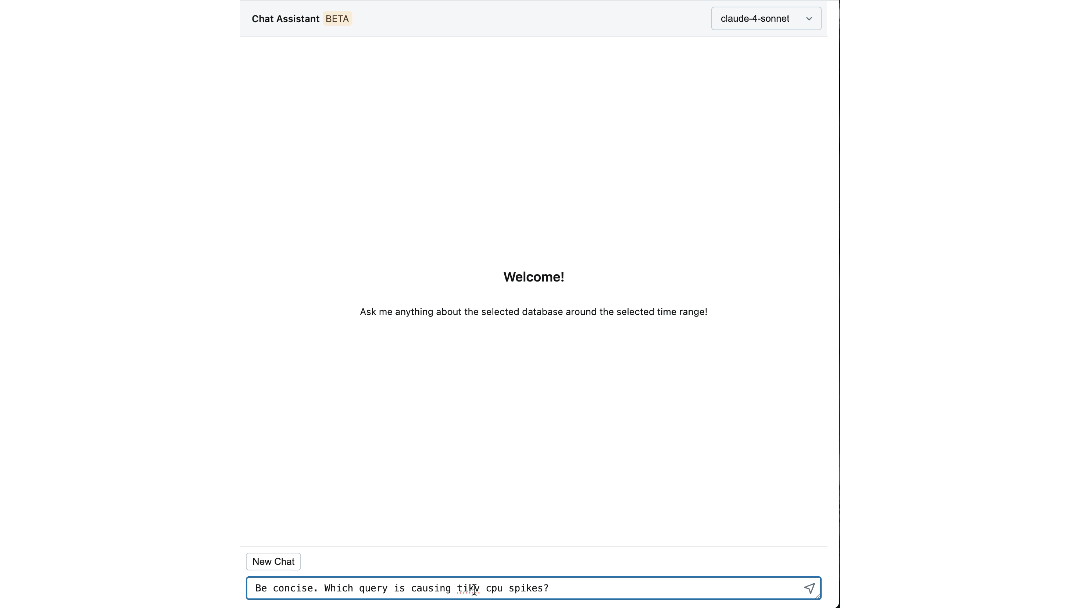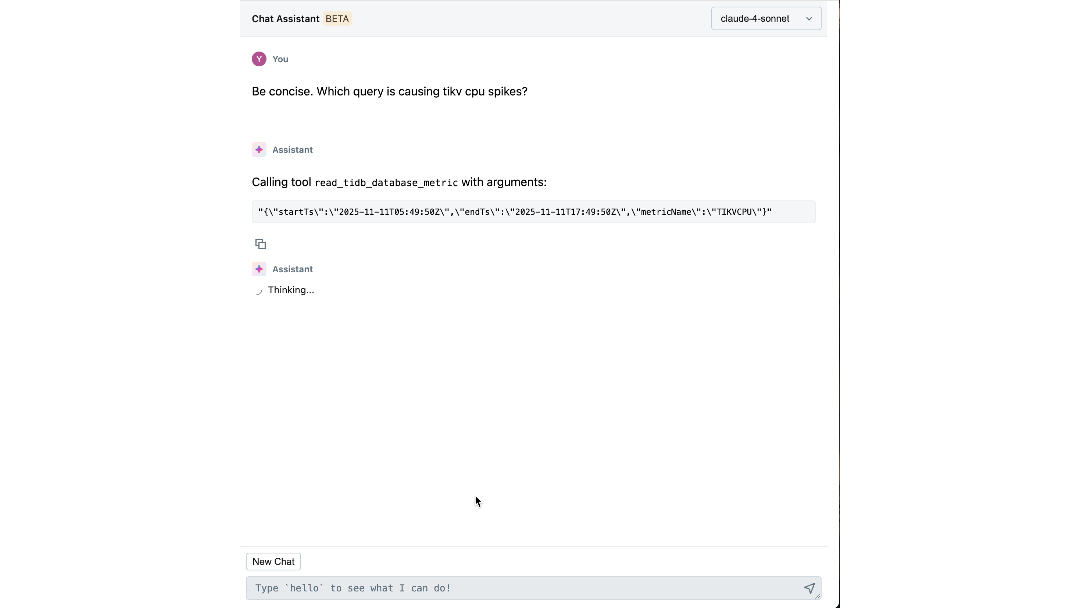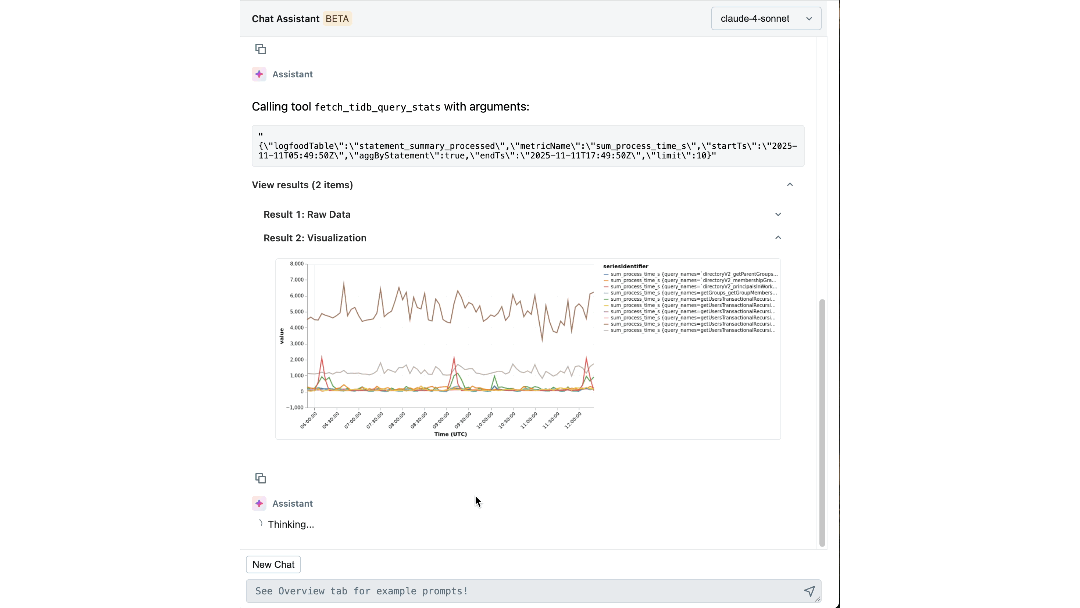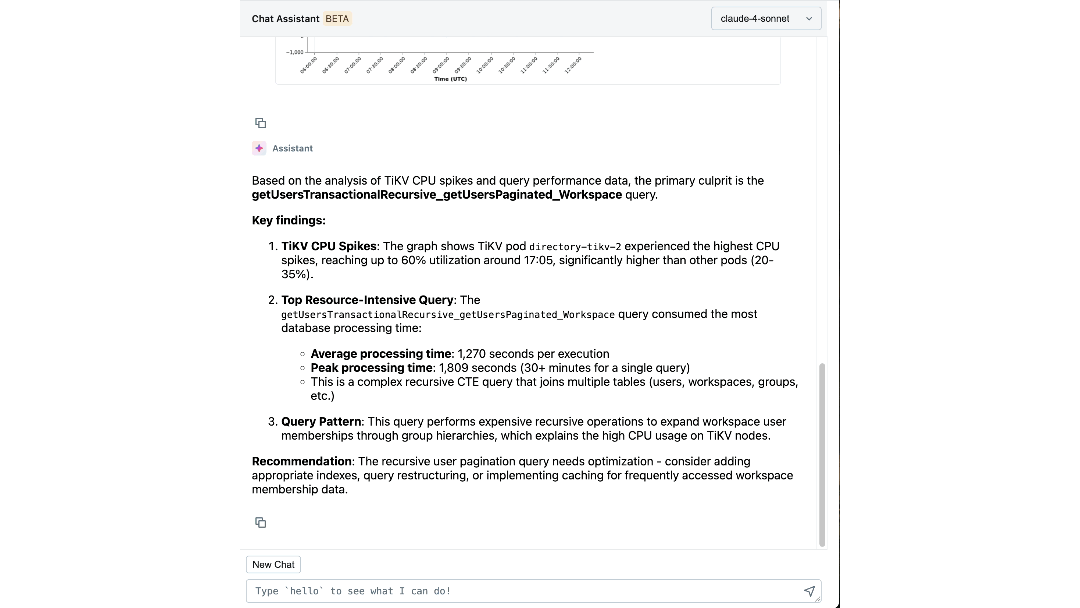
L'impatto: Ridefinire Come Costruiamo e Operiamo su Scala
La piattaforma ha cambiato il modo in cui gli ingegneri Databricks interagiscono con la loro infrastruttura. Singoli passaggi che una volta richiedevano il passaggio tra dashboard, CLI e SOP possono ora essere facilmente risolti dal nostro assistente di chat, riducendo il tempo impiegato fino al 90%.
Anche la curva di apprendimento per la nostra infrastruttura tra i nuovi ingegneri è diminuita drasticamente. I nuovi assunti senza alcun contesto possono ora avviare un'indagine sul database in meno di 5 minuti, cosa che prima sarebbe stata quasi impossibile. E abbiamo ricevuto ottimi feedback dal lancio di questa piattaforma:
L'assistente database mi fa davvero risparmiare un sacco di tempo, così non devo ricordare dove si trovano tutte le mie dashboard di query. Posso semplicemente chiedergli quale workspace sta generando il carico. Il miglior strumento di sempre!—Yuchen Huo, Staff Engineer
Sono un utente assiduo e non riesco a credere che vivessimo nella sua assenza. Il livello di raffinatezza e utilità è molto impressionante. Grazie team, è un cambio di passo nell'esperienza dello sviluppatore.—Dmitriy Kunitskiy, Staff Engineer
Amo particolarmente come stiamo portando insight basati sull'AI per il debug dei problemi di infrastruttura. Apprezzo quanto sia lungimirante il team nel progettare questa console fin dall'inizio tenendone conto.—Ankit Mathur, Senior Staff Engineer
Architettonicamente, la piattaforma pone le basi per la prossima evoluzione: operazioni di produzione assistite dall'AI. Con dati, contesto e guardrail unificati, possiamo ora esplorare come l'agente può aiutare con ripristini, query di produzione e aggiornamenti di configurazione: il prossimo passo verso un flusso di lavoro operativo assistito dall'AI.
Ma l'impatto più significativo non è stato solo la riduzione del lavoro manuale o un onboarding più rapido: è stato un cambio di mentalità. La nostra attenzione si è spostata dall'architettura tecnica ai percorsi utente critici (CUJ) che definiscono come gli ingegneri vivono i nostri sistemi. Questo approccio incentrato sull'utente è ciò che consente ai nostri team di infrastruttura di creare piattaforme su cui i nostri ingegneri possono costruire prodotti vincenti nella categoria.
Punti Chiave
Alla fine, il nostro viaggio si è ridotto a tre punti chiave:
- La rapida iterazione è essenziale per lo sviluppo degli agenti: gli agenti migliorano attraverso la sperimentazione rapida, la validazione e il perfezionamento. Il nostro framework ispirato a DsPy lo ha reso possibile permettendoci di evolvere rapidamente prompt e strumenti.
- La velocità di iterazione è limitata dalla base sottostante: dati unificati, astrazioni coerenti e controllo degli accessi granulare hanno rimosso i nostri maggiori colli di bottiglia, rendendo la piattaforma affidabile, scalabile e pronta per l'AI.
- La velocità conta solo quando ha la direzione corretta: non ci siamo prefissati di costruire una piattaforma di agenti. Ogni iterazione ha semplicemente seguito il feedback degli utenti e ci ha avvicinato alla soluzione di cui gli ingegneri avevano bisogno.
Costruire piattaforme interne è ingannevolmente difficile. Anche all'interno della stessa azienda, i team di prodotto e di piattaforma operano con vincoli molto diversi. In Databricks, stiamo colmando questo divario costruendo con ossessione per il cliente, semplificando attraverso astrazioni ed elevando con intelligenza, trattando i nostri clienti interni con la stessa cura e rigore che riserviamo ai nostri clienti esterni.
Unisciti a Noi
Guardando al futuro, siamo entusiasti di continuare a spingere i confini di come l'AI può plasmare i sistemi di produzione e far sembrare l'infrastruttura complessa senza sforzo. Se sei appassionato nel costruire la prossima generazione di piattaforme interne basate sull'AI, unisciti a noi!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.