Ingestione della Via Lattea: su scala petabyte con Zerobus Ingest
Un'analisi approfondita dell'architettura che consente di raggiungere 12 GB/s per tabella — e possibilità illimitate
di Aleksandar Tomić, Victoria Bukta, Nikola Obradović, Danilo Najkov, Branko Grbić e Milos Milovanovic
- Databricks Zerobus Ingest è un'API di streaming serverless che consente ai team di distribuire istantaneamente pipeline di dati su scala petabyte senza gestione manuale dell'infrastruttura.
- L'architettura di Zerobus si basa sul partizionamento dinamico per scalare automaticamente le risorse di calcolo, gestendo in modo efficiente volumi di dati imprevedibili senza complesse attività di tuning.
- Questo framework zero-setup elabora facilmente enormi carichi di lavoro, dimostrando la capacità di sostenere un throughput superiore a 12 GB/s su una singola tabella durante benchmark di 24 ore.
I dati di telemetria sono ovunque. Sensori IoT nei reparti di produzione. Sistemi satellitari che scansionano l'atmosfera. I veicoli autonomi registrano migliaia di eventi al secondo. Ognuno di questi sistemi presenta lo stesso problema di fondo: un flusso continuo e ad alto volume di osservazioni di serie temporali che deve confluire in una destinazione interrogabile. Deve essere veloce, affidabile e non deve richiedere che un team di ingegneri passi settimane a ottimizzare e gestire l'infrastruttura, come invece avviene tipicamente per i carichi di lavoro basati su Kafka.
Questo è il problema che Zerobus Ingest è stato progettato per risolvere. Zerobus è il servizio di streaming ingest serverless e completamente gestito di Databricks. Si tratta di un'API push-based che accetta dati da qualsiasi producer e li scrive direttamente nelle tabelle Delta, con la governance di Unity Catalog.
- Nessuna infrastruttura da configurare.
- Nessuna pipeline di connettori da gestire.
- Nessuna partizione o processo decisionale del broker.
Invece, basta creare una tabella e inviare i dati. I dati arrivano nel tuo lakehouse, pronti per essere interrogati in pochi secondi. Non è più necessario utilizzare Kafka come canale di transito quando la destinazione è il lakehouse.
Abbiamo utilizzato il dataset NEOWISE della NASA, che rappresenta 200 miliardi di punti dati nell'arco di 11 anni, per testare le prestazioni di Zerobus Ingest, eseguendo l'ingestion di 1 petabyte in meno di 24 ore, con zero preconfigurazioni e una latenza stabile.
Con l'ingestion di 1 PB in 24 ore, dimostriamo la capacità di Zerobus di mantenere un throughput continuo di 12 GB/s su una singola tabella! 🚀
Ora disponibile su scala Petabyte: streaming della Via Lattea (12 GB/sec per tabella)
Per saperne di più su come eseguire tu stesso il benchmark, leggi questo blog di approfondimento sulla Databricks Community.
Questo post illustra tre delle scelte di progettazione che hanno reso possibile tutto questo.
- Progettazione di un sistema con scalabilità automatica tramite partizionamento dinamico.
- Sviluppo di un decoder protobuf personalizzato con tecnologia zero-copy.
- Implementazione di un write-ahead log ottimizzato per la latenza prima della pubblicazione dei dati nel lakehouse.
Le nostre principali scelte di progettazione
La nostra ambizione era costruire un sistema di streaming in grado di supportare la scala dei petabyte e di scalare automaticamente per gestire pattern di ingestion fluttuanti.
Le architetture di streaming tradizionali richiedono di decidere di quanti broker e partizioni ha bisogno un determinato carico di lavoro. Ciò richiede la conoscenza del carico di picco e dei vincoli di ingestion dei consumer, oltre a previsioni e a una comprensione approfondita della pipeline end-to-end.
Partendo dai principi fondamentali, abbiamo progettato e costruito un sistema che scala per gestire carichi di lavoro nell'ordine dei petabyte per i producer di dati in modo "magico".
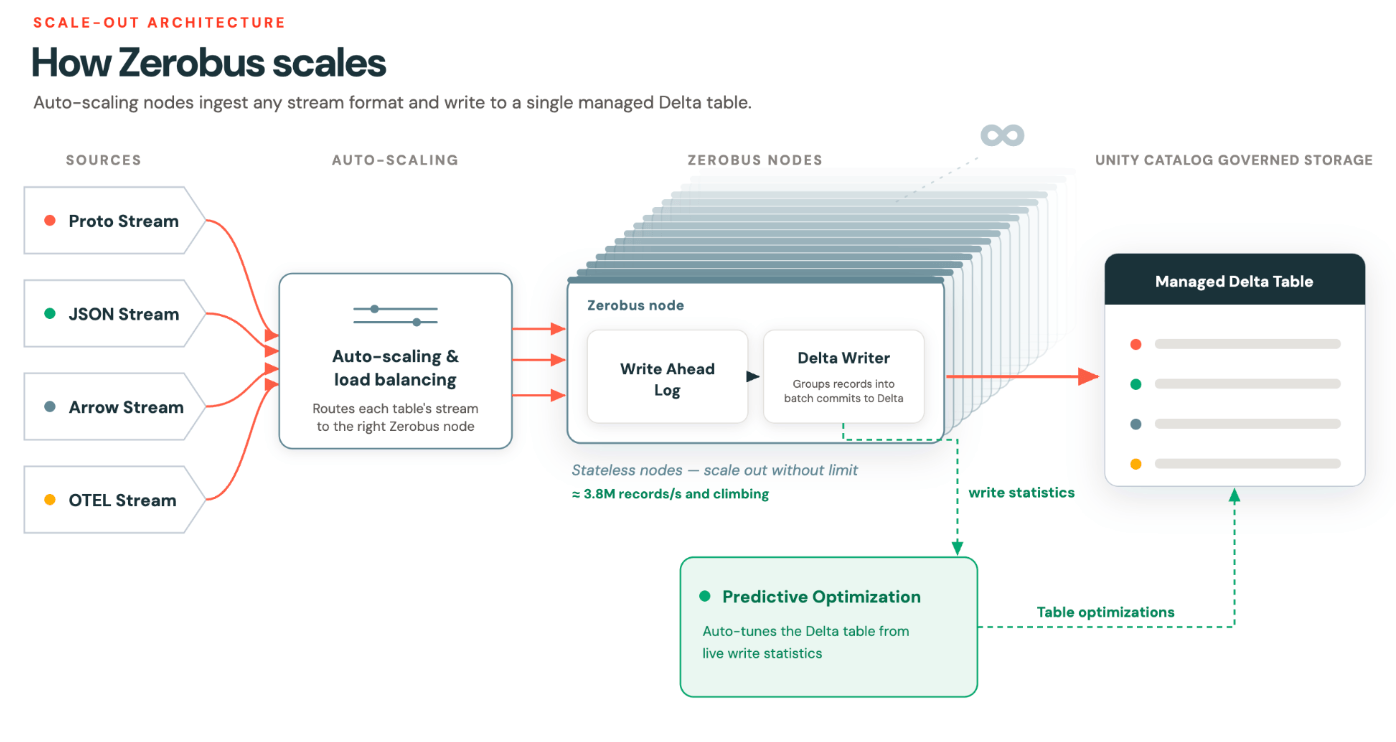
Scalabilità automatica grazie al partizionamento dinamico
Il problema che cercavamo di risolvere era come ottenere una scalabilità automatica efficiente per raggiungere una scalabilità elastica "senza limiti".
La nostra tesi era che, allontanandoci dal partizionamento statico e muovendoci verso l'unità logica di un flusso/connessione, avremmo potuto sbloccare una vera scalabilità automatica e un ribilanciamento, mantenendo al contempo le garanzie di ordinamento, fondamentali per i carichi di lavoro di consumo.
Il problema del partizionamento statico
Nelle architetture message bus, le partizioni sono l'unità sia del parallelismo che dell'ordinamento. Questo accoppiamento crea un vincolo che può risultare problematico quando si hanno consumer che dipendono da esso.
L'ordinamento è in genere una garanzia per partizione, non per producer. Il numero di partizioni e la distribuzione dei dati tra di esse influiscono sulla capacità del consumer di tenere il passo con l'ingestion. Ciò significa che:
- Se il numero di partizioni cambia, la funzione di routing che mappa i messaggi di un producer a una partizione potrebbe ora inviarli a una partizione diversa. Il consumer deve quindi riconciliare questa variazione.
- In pratica, la maggior parte dei team considera la topologia delle partizioni come immutabile. Si effettua il provisioning per il carico di picco e si mantiene tale infrastruttura per sempre. È possibile aggiungere partizioni, ma in genere non è possibile ridurle in sicurezza.
- La soluzione alternativa standard consiste in una chiave di routing della partizione derivata da un campo nel messaggio. Questo aiuta con la coerenza dell'ordinamento, ma non risolve comunque il problema del ridimensionamento verso il basso.
Abbiamo spostato la garanzia di ordinamento sulla connessione del flusso
Nei sistemi tradizionali, l'ordinamento è una garanzia a livello di partizione. In Zerobus Ingest, l'ordinamento è una garanzia a livello di connessione del flusso.
Quando un producer apre un flusso con Zerobus (una connessione al nostro server), registra un'identità logica con il servizio. Per tutta la durata di tale connessione, i suoi dati arrivano in ordine, indipendentemente da quale pod di "partizione" li elabori.
"Il tuo flusso è ordinato", non "la tua partizione è ordinata". Questo è il contratto.
Hot routing e vera scalabilità automatica
Internamente, Zerobus Ingest distribuisce i flussi su un pool di pod. Il routing si basa su euristica: se un pod è sovraccarico, i nuovi flussi in entrata vengono instradati a un pod diverso. Il producer non se ne accorge e la sua garanzia di ordinamento rimane inalterata.
L'ordinamento risiede a livello di flusso, il che significa che i pod possono essere aggiunti quando la domanda aumenta e rimossi quando la domanda diminuisce. I flussi esistenti si esauriscono gradualmente e i nuovi flussi smettono di essere instradati lì. Il pool si riduce, mantenendo efficiente l'utilizzo delle risorse di calcolo.
Questa è la vera scalabilità automatica. L'unità di granularità è la connessione del flusso, non l'assegnazione della partizione.
Il nostro design di partizionamento dinamico consente a Zerobus di scalare automaticamente fino a un throughput di oltre 12 GB al secondo per una tabella, rimanendo al contempo conveniente in termini di costi.
Gestione dei dati ad alte prestazioni con tecnologia zero-copy
L'obiettivo principale di Zerobus è consentire un trasferimento efficiente, riga per riga, di flussi di dati di qualsiasi volume. Per raggiungere questo obiettivo, dovevamo evitare completamente qualsiasi copia e allocazione di memoria non necessaria, dai formati di input che i client inviano a Zerobus, ai formati interni che garantiscono la durabilità e ai formati Delta aperti.
Zerobus attualmente supporta i seguenti formati di messaggio.
Tra le molte ottimizzazioni che abbiamo apportato, illustreremo l'approccio zero-copy attraverso ZeroParser, il nostro decoder protobuf personalizzato.
I decoder protobuf standard costringono a scegliere tra velocità e flessibilità. Di solito, i decoder protobuf si basano sulla generazione di codice in fase di compilazione (codegen) o sulla riflessione a runtime.
- La generazione di codice è veloce, ma richiede descrittori in fase di compilazione. Zerobus riceve i descrittori in modo dinamico a runtime, da schemi utente arbitrari. La codegen non è un'opzione.
- La riflessione a runtime risolve il problema della flessibilità, ma ne crea uno di prestazioni. I decoder protobuf dinamici sono lenti e richiedono la creazione di un grafo di oggetti in memoria a runtime, il che comporta molte piccole allocazioni di memoria.
Nessuno dei due approcci era accettabile. Avevamo bisogno del supporto per i descrittori dinamici con il profilo prestazionale della codegen.
Il risultato è stato lo sviluppo di zeroparser: colmiamo questo divario utilizzando il parsing a passaggio singolo con zero allocazioni di memoria, consentendo di sostenere throughput di parsing protobuf di ~1 GB/s per core CPU anche con descrittori dinamici e schemi complessi.
Zeroparser consente il parsing diretto del formato wire senza decostruzione degli oggetti in entrata, che comporterebbe la copia e l'allocazione della memoria. Con questo approccio, Zerobus può ottenere prestazioni migliori rispetto alle soluzioni di parsing protobuf esistenti basate sulla generazione di codice, pur mantenendo la totale flessibilità di fornire dinamicamente i descrittori protobuf.
Il sistema di lifetime di Rust è stato fondamentale per la progettazione di Zeroparser: garantisce la sicurezza in fase di compilazione durante il parsing del protocollo, mantenendo i byte wire grezzi sotto la proprietà esclusiva della rete, eliminando copie di dati non necessarie.
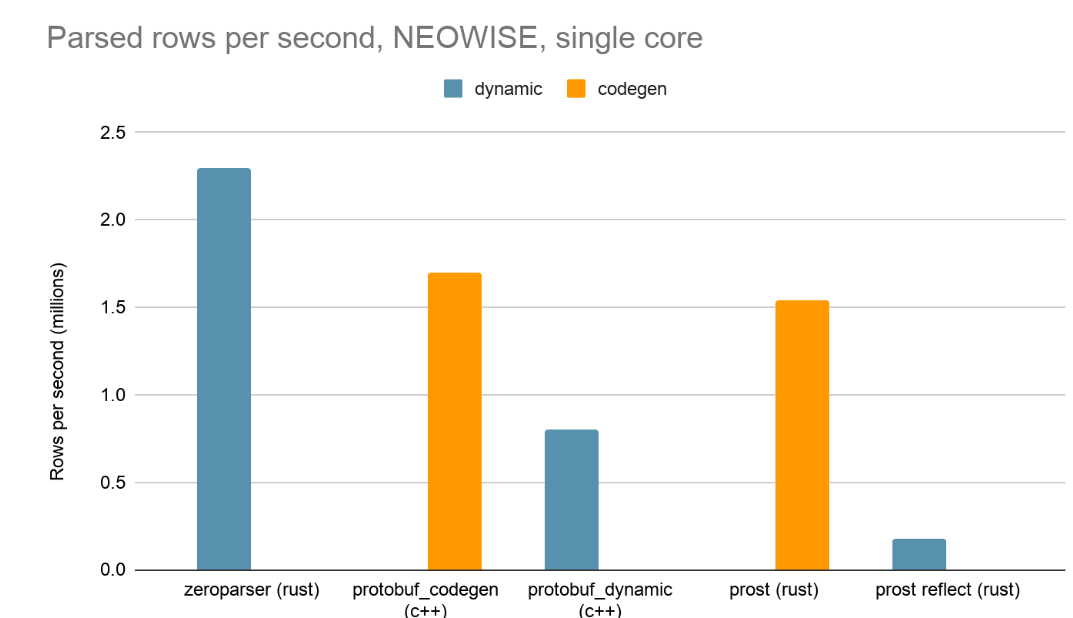
I risultati mostrano che Zeroparser, pur facendo parte del gruppo dinamico, ha superato due implementazioni standard del settore basate su codegen.
Zeroparser è open source come parte di Zerobus SDK disponibile qui.
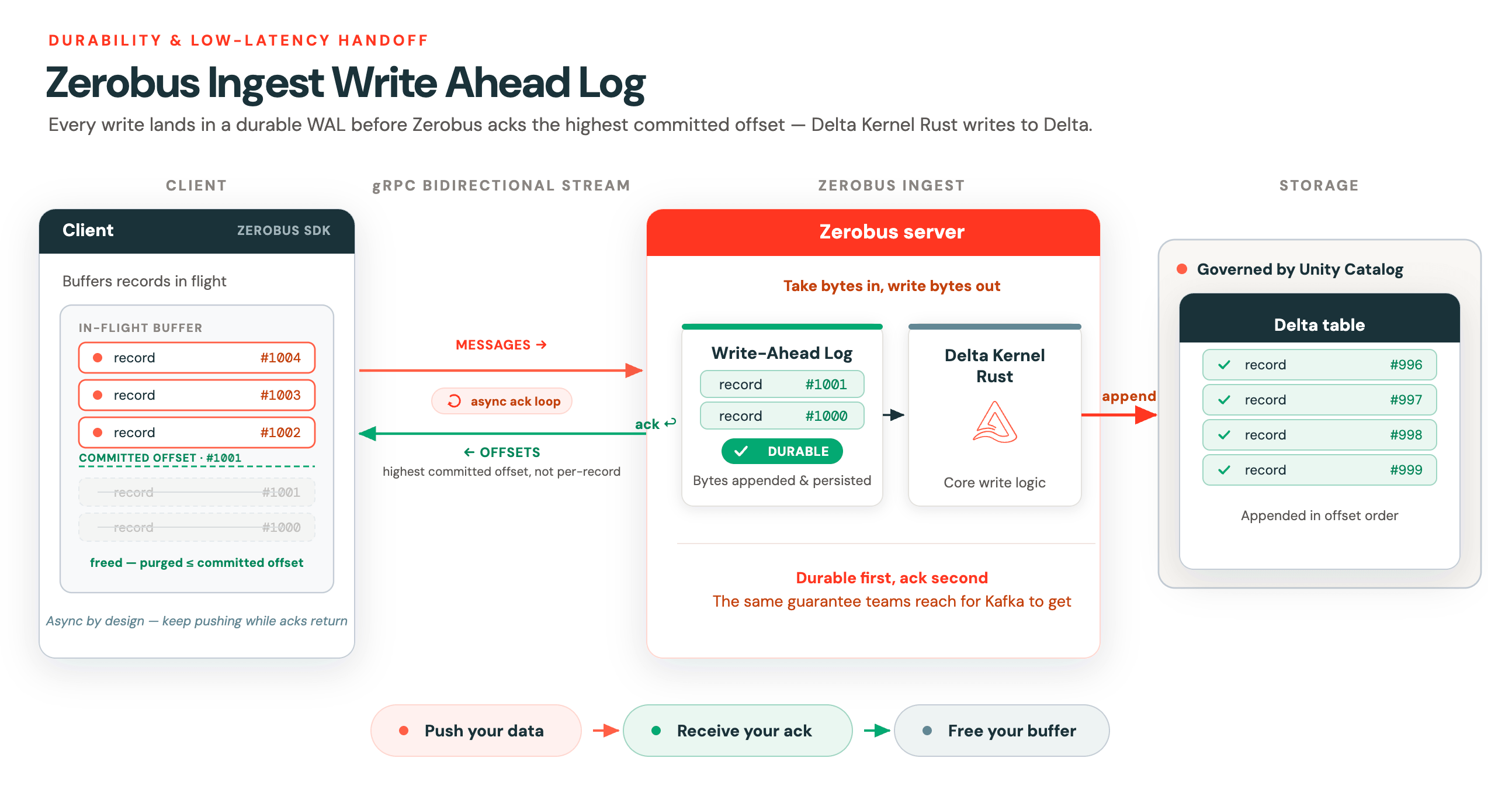
Write Ahead Log
Lo streaming non consiste solo nella capacità di gestire carichi di lavoro a throughput elevato. Per essere un vero servizio di streaming, è necessario supportare anche il passaggio dei messaggi il più rapidamente possibile. Questa bassa latenza nel passaggio dei dati è ciò che distingue veramente i carichi di lavoro di streaming da quelli batch.
Per supportare questo passaggio a bassa latenza con una garanzia di durabilità, Zerobus implementa un write-ahead log (WAL) ottimizzato per la latenza. Una volta che i messaggi sono durevoli, Zerobus invia una conferma (acknowledgement) al client. Invece di confermare ogni singolo record, il server restituisce l'offset confermato più alto sullo stream. Il risultato è questo loop di ack asincrono. Delta Kernel Rust viene quindi utilizzato per la logica principale di scrittura su Delta.
Questo design asincrono è fondamentale per i client che memorizzano i dati in transito nel buffer. Zerobus utilizza lo streaming bidirezionale gRPC, in cui ogni stream Zerobus ha due linee di comunicazione:
- Una per l'invio dei messaggi
- L'altra per la ricezione delle conferme degli offset.
Una volta che il client riceve tale offset, può eliminare in sicurezza tutto ciò che precede dal suo buffer locale in transito. Tutto questo viene gestito automaticamente dagli SDK di Zerobus.
Il WAL è ciò che mantiene snelli i client. Invia i dati, ricevi l'ack, libera il buffer. Questo passaggio a bassa latenza e alta durabilità è da sempre il motivo per cui i team scelgono Kafka. Zerobus offre la stessa garanzia.
La prova: Ingestione della Via Lattea
La chiave per valutare le prestazioni di un sistema consiste nel comprendere come verrebbe utilizzato in un ambiente di produzione, per poi emularne il comportamento e l'utilizzo. Ecco perché, per mettere sotto sforzo Zerobus Ingest, abbiamo scelto il dataset NEOWISE della NASA e abbiamo utilizzato Locust per emulare i pattern di fan-in del mondo reale.
Perché Locust? Il problema del fan-in
Zerobus Ingest è progettato per aggregare stream provenienti da molti produttori indipendenti in un'unica tabella di destinazione. Il suo throughput scala con il numero di stream aperti simultaneamente. Ciò significa che non è possibile metterlo alla prova in modo equo da una singola macchina o da un piccolo cluster. Un singolo host potente saturerebbe la propria larghezza di banda o la CPU prima di esercitare una pressione significativa sul nostro servizio, finendo per valutare le prestazioni del produttore anziché di Zerobus.
Per simulare un pattern di fan-in del mondo reale, utilizziamo Locust per coordinare l'apertura di stream separati da parte dei pod per testare l'ingestione su larga scala.
L'autoscaling di Zerobus risponde quindi al numero di stream e al throughput per gestire la velocità di ingestione.
Configurazione del test
Il nostro benchmark è stato distribuito su Kubernetes con un master Locust e una flotta di worker Locust, ciascuno in esecuzione come pod separato. Parametri chiave:
Ogni worker riceve un elenco univoco di file Parquet da acquisire. Un worker trasmette il proprio slice in streaming e non ripete le righe.
I risultati
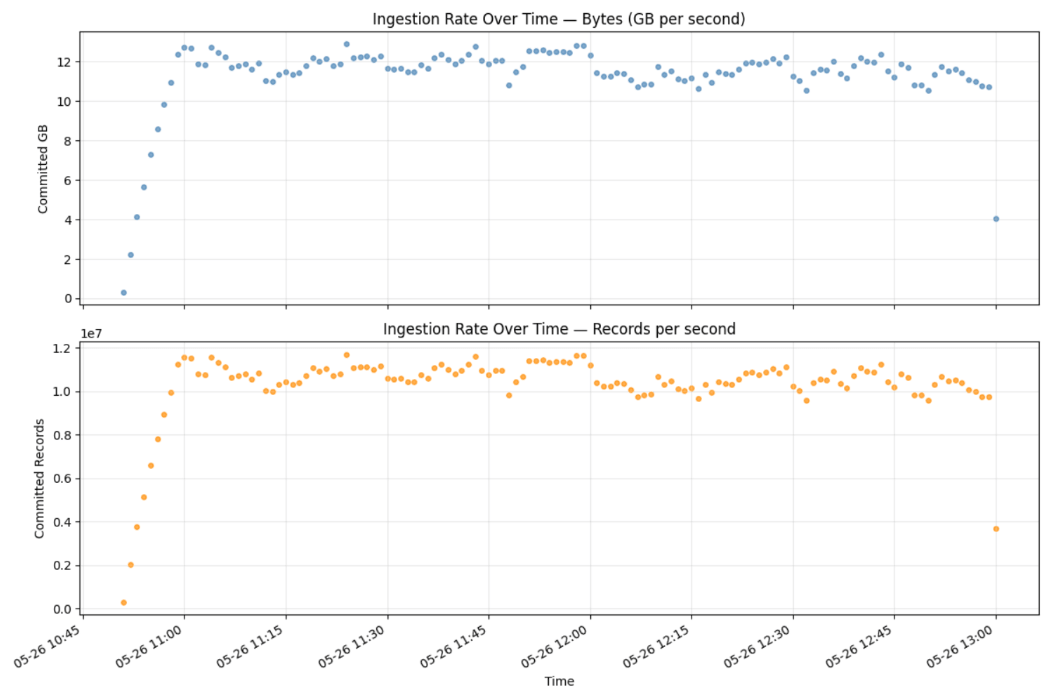
I risultati dei nostri test hanno dimostrato la capacità di Zerobus Ingest di sostenere 12 GB/s su una singola tabella nell'arco di 24 ore da 2.048 worker simultanei. In questo periodo, Zerobus ha acquisito oltre mille miliardi di record.
L'aggregazione in intervalli di 5 secondi sulla colonna client_ts_ms fornisce una vista precisa e confermata dal server delle righe sottoposte a commit e dei byte ricevuti:
Questa query viene eseguita sulla tabella Unity Catalog attiva. I numeri riflettono le righe per cui è stato eseguito completamente il commit nello storage Delta.
Vuoi eseguirlo tu stesso?
La suite di benchmark completa con la preparazione del dataset, il codice del producer e le istruzioni per l'esecuzione sul tuo endpoint Zerobus. Scoprila qui.
I prossimi passi
Zerobus Ingest è ora generalmente disponibile su Databricks e pronto per tutti i tuoi carichi di lavoro di produzione.
Le nostre metriche di performance di 12 GB/s su una tabella sono ciò che ottieni fin da subito con Zerobus Ingest. Le quote possono essere incrementate contattando il team del tuo account.
Nella roadmap:
- Supporto per l'API Kafka Producer
- Supporto per l'API MQTT
- Colonna di recupero
- Colonna dei metadati di sistema
- Supporto per Avro
Facci sapere quali novità vorresti vedere in Zerobus! Quale pensi che sarà la prossima frontiera dello streaming? Inviaci i tuoi commenti sul nostro blog associato della Databricks Community.
Se sei pronto a iniziare con Zerobus Ingest, consulta la nostra documentazione tecnica, l'Zerobus Ingest SDK o dai un'occhiata alla repository GitHub con il benchmark Neowise.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.