Introduzione alla Previsione di Serie Temporali con IA Generativa
Un'introduzione alla previsione delle serie storiche con l'IA generativa
La previsione delle serie storiche è stata una pietra miliare della pianificazione delle risorse aziendali per decenni. Le previsioni sulla domanda futura guidano decisioni critiche come il numero di unità da immagazzinare, il personale da assumere, gli investimenti di capitale in infrastrutture di produzione e distribuzione e la definizione dei prezzi di beni e servizi. Previsioni accurate della domanda sono essenziali per queste e molte altre decisioni aziendali.
Tuttavia, le previsioni sono raramente perfette, se mai lo sono. A metà degli anni 2010, molte organizzazioni che affrontavano limitazioni computazionali e accesso limitato a capacità di previsione avanzate riportavano accuratezze di previsione di solo il 50-60%. Ma con una maggiore adozione del cloud, l'introduzione di tecnologie molto più accessibili e una migliore accessibilità a fonti di dati esterne come dati meteorologici ed eventi, le organizzazioni stanno iniziando a vedere miglioramenti.
Entrando nell'era dell'IA generativa, una nuova classe di modelli denominata transformer per serie storiche sembra in grado di aiutare le organizzazioni a ottenere ulteriori miglioramenti. Similmente ai modelli linguistici di grandi dimensioni (come ChatGPT) che eccellono nel prevedere la parola successiva in una frase, i transformer per serie storiche prevedono il valore successivo in una sequenza numerica. Con l'esposizione a grandi volumi di dati di serie storiche, questi modelli diventano esperti nell'individuare sottili schemi di relazioni tra i valori in queste serie con successo dimostrato in una varietà di domini.
In questo blog, forniremo un'introduzione di alto livello a questa classe di modelli di previsione, destinata ad aiutare manager, analisti e data scientist a sviluppare una comprensione di base di come funzionano. Forniremo quindi l'accesso a una serie di notebook basati su set di dati disponibili pubblicamente che dimostrano come le organizzazioni che ospitano i propri dati in Databricks possano facilmente sfruttare diversi dei modelli più popolari per le proprie esigenze di previsione. Speriamo che ciò aiuti le organizzazioni a sfruttare il potenziale dell'IA generativa per ottenere migliori accuratezze di previsione.
Comprendere i Transformer per Serie Storiche
I modelli di IA generativa sono una forma di rete neurale profonda, un complesso modello di machine learning all'interno del quale un gran numero di input viene combinato in vari modi per arrivare a un valore previsto. La meccanica di come il modello apprende a combinare gli input per arrivare a una previsione accurata è definita architettura di un modello.
La svolta nelle reti neurali profonde che ha dato origine all'IA generativa è stata la progettazione di un'architettura di modello specializzata chiamata transformer. Sebbene i dettagli esatti di come i transformer differiscano da altre architetture di reti neurali profonde siano piuttosto complessi, la semplice questione è che il transformer è molto bravo a cogliere le complesse relazioni tra i valori in lunghe sequenze.
Per addestrare un transformer per serie storiche, una rete neurale profonda opportunamente architettata viene esposta a un grande volume di dati di serie storiche. Dopo aver avuto l'opportunità di addestrarsi su milioni, se non miliardi, di valori di serie storiche, apprende i complessi schemi di relazioni trovati in questi set di dati. Quando viene quindi esposto a una serie storica precedentemente non vista, può utilizzare questa conoscenza fondamentale per identificare dove esistono schemi di relazioni simili all'interno della serie storica e prevedere nuovi valori nella sequenza.
Questo processo di apprendimento delle relazioni da grandi volumi di dati è definito pre-addestramento. Poiché la conoscenza acquisita dal modello durante il pre-addestramento è altamente generalizzabile, i modelli pre-addestrati definiti modelli foundation possono essere impiegati su serie storiche precedentemente non viste senza addestramento aggiuntivo. Detto questo, un addestramento aggiuntivo sui dati proprietari di un'organizzazione, un processo definito fine-tuning, può in alcuni casi aiutare l'organizzazione a ottenere un'accuratezza di previsione ancora migliore. In ogni caso, una volta che il modello è ritenuto in uno stato soddisfacente, l'organizzazione deve semplicemente presentargli una serie storica e chiedere: cosa viene dopo?
Affrontare le Sfide Comuni delle Serie Storiche
Sebbene questa comprensione di alto livello di un transformer per serie storiche possa avere senso, la maggior parte dei professionisti delle previsioni avrà probabilmente tre domande immediate. Primo, mentre due serie storiche possono seguire uno schema simile, possono operare su scale completamente diverse, come fa un transformer a superare questo problema? Secondo, all'interno della maggior parte dei modelli di serie storiche ci sono schemi di stagionalità giornalieri, settimanali e annuali che devono essere considerati, come fanno i modelli a sapere di cercare questi schemi? Terzo, molte serie storiche sono influenzate da fattori esterni, come possono questi dati essere incorporati nel processo di generazione delle previsioni?
La prima di queste sfide viene affrontata standardizzando matematicamente tutti i dati delle serie storiche utilizzando una serie di tecniche definite scaling. La meccanica di questo è interna all'architettura di ciascun modello, ma essenzialmente i valori in ingresso della serie storica vengono convertiti in una scala standard che consente al modello di riconoscere schemi nei dati in base alla sua conoscenza fondamentale. Le previsioni vengono effettuate e tali previsioni vengono quindi restituite alla scala originale dei dati originali.
Per quanto riguarda gli schemi stagionali, al centro dell'architettura transformer c'è un processo chiamato self-attention. Sebbene questo processo sia piuttosto complesso, fondamentalmente questo meccanismo consente al modello di apprendere il grado in cui specifici valori precedenti influenzano un dato valore futuro.
Sebbene ciò sembri la soluzione per la stagionalità, è importante capire che i modelli differiscono nella loro capacità di cogliere schemi di stagionalità di basso livello in base a come dividono gli input delle serie storiche. Attraverso un processo chiamato tokenization, i valori in una serie storica vengono divisi in unità chiamate token. Un token può essere un singolo valore di serie storica o una breve sequenza di valori (spesso definita patch).
La dimensione del token determina il livello più basso di granularità a cui possono essere rilevati gli schemi stagionali. (La tokenizzazione definisce anche la logica per gestire i valori mancanti.) Quando si esplora un particolare modello, è importante leggere le informazioni, a volte tecniche, sulla tokenizzazione per capire se il modello è appropriato per i propri dati.
Infine, per quanto riguarda le variabili esterne, i transformer per serie storiche impiegano una varietà di approcci. In alcuni, i modelli vengono addestrati sia su dati di serie storiche che su variabili esterne correlate. In altri, i modelli sono architettati per comprendere che una singola serie storica può essere composta da più sequenze parallele e correlate. Indipendentemente dalla tecnica precisa impiegata, con questi modelli è possibile trovare un supporto limitato per le variabili esterne.
Una Breve Panoramica di Quattro Popolari Transformer per Serie Storiche
Con una comprensione di alto livello dei transformer per serie storiche, prendiamoci un momento per esaminare quattro popolari modelli transformer foundation per serie storiche:
Chronos
Chronos è una famiglia di modelli open-source pre-addestrati per la previsione delle serie storiche di Amazon. Questi modelli adottano un approccio relativamente ingenuo alla previsione interpretando una serie storica come un linguaggio specializzato con i propri schemi di relazioni tra i token. Nonostante questo approccio relativamente semplicistico che include il supporto per i valori mancanti ma non per le variabili esterne, la famiglia di modelli Chronos ha dimostrato risultati impressionanti come soluzione di previsione per scopi generali (Figura 1).

Figura 1. Metriche di valutazione per Chronos e vari altri modelli di previsione applicati a 27 set di dati di benchmarking (da https://github.com/amazon-science/chronos-forecasting)
TimesFM
TimesFM è un modello foundation open-source sviluppato da Google Research, pre-addestrato su oltre 100 miliardi di punti di serie storiche reali. A differenza di Chronos, TimesFM include meccanismi specifici per le serie storiche nella sua architettura che consentono all'utente di esercitare un controllo granulare su come vengono organizzati input e output. Ciò ha un impatto sul modo in cui vengono rilevati gli schemi stagionali, ma anche sui tempi di calcolo associati al modello. TimesFM si è dimostrato uno strumento di previsione delle serie storiche molto potente e flessibile (Figura 2).
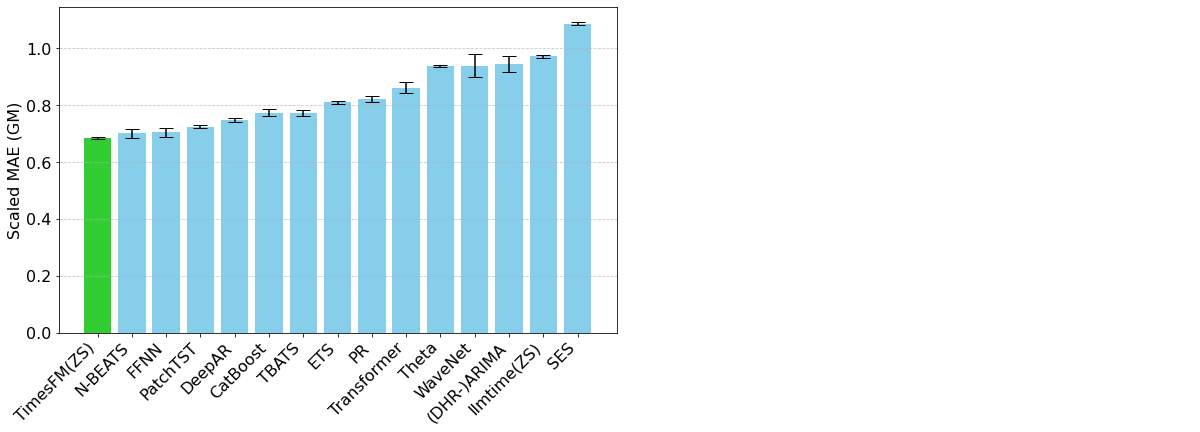
Figura 2. Metriche di valutazione per TimesFM e vari altri modelli rispetto al dataset Monash Forecasting Archive (da https://research.google/blog/a-decoder-only-foundation-model-for-time-series-forecasting/)
Moirai
Moirai, sviluppato da Salesforce AI Research, è un altro modello foundation open-source per la previsione di serie temporali. Addestrato su "27 miliardi di osservazioni distribuite su 9 domini distinti", Moirai è presentato come un previsore universale in grado di supportare sia valori mancanti che variabili esterne. Le dimensioni variabili delle patch consentono alle organizzazioni di ottimizzare il modello in base ai pattern stagionali nei loro dataset e, se applicate correttamente, hanno dimostrato di performare piuttosto bene rispetto ad altri modelli (Figura 3).

Figura 3. Metriche di valutazione per Moirai e vari altri modelli rispetto al Monash Time Series Forecasting Benchmark (da https://blog.salesforceairesearch.com/moirai/)
TimeGPT
TimeGPT è un modello proprietario con supporto per variabili esterne (esogene) ma non per valori mancanti. Focalizzato sulla facilità d'uso, TimeGPT è ospitato tramite un'API pubblica che consente alle organizzazioni di generare previsioni con una sola riga di codice. Nel benchmarking del modello rispetto a 300.000 serie uniche a diversi livelli di granularità temporale, il modello ha prodotto risultati impressionanti con una latenza di previsione molto bassa (Figura 4).
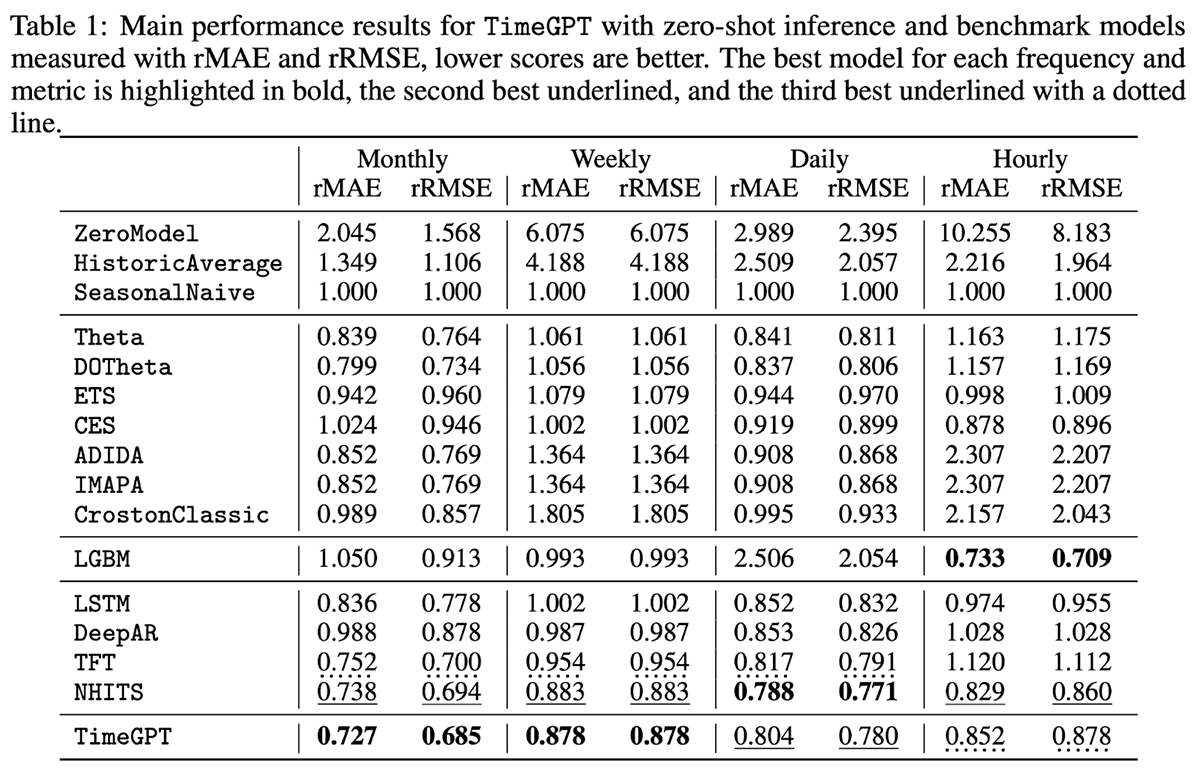
Figura 4. Metriche di valutazione per TimeGPT e vari altri modelli rispetto a 300.000 serie uniche (da https://arxiv.org/pdf/2310.03589)
Iniziare con Transformer Forecasting su Databricks
Con così tante opzioni di modelli e altre ancora in arrivo, la domanda chiave per la maggior parte delle organizzazioni è: come iniziare a valutare questi modelli utilizzando i propri dati proprietari? Come per qualsiasi altro approccio di previsione, le organizzazioni che utilizzano modelli di previsione di serie temporali devono presentare i propri dati storici al modello per creare previsioni, e tali previsioni devono essere attentamente valutate ed eventualmente distribuite a sistemi downstream per renderle attuabili.
Grazie alla scalabilità di Databricks e all'uso efficiente delle risorse cloud, molte organizzazioni lo utilizzano da tempo come base per il loro lavoro di previsione, producendo decine di milioni di previsioni su base giornaliera o anche più frequente per gestire le loro operazioni aziendali. L'introduzione di una nuova classe di modelli di previsione non cambia la natura di questo lavoro, fornisce semplicemente a queste organizzazioni più opzioni per farlo all'interno di questo ambiente.
Ciò non significa che non ci siano alcune novità con questi modelli. Costruiti su un'architettura di deep neural network, molti di questi modelli performano al meglio quando impiegati su una GPU e, nel caso di TimeGPT, potrebbero richiedere chiamate API a un'infrastruttura esterna come parte del processo di generazione delle previsioni. Ma fondamentalmente, il modello di archiviazione dei dati storici di serie temporali di un'organizzazione, presentazione di tali dati a un modello e acquisizione dell'output in una tabella interrogabile rimane invariato.
Per aiutare le organizzazioni a capire come possono utilizzare questi modelli all'interno di un ambiente Databricks, abbiamo assemblato una serie di notebook che dimostrano come generare previsioni con ciascuno dei quattro modelli descritti sopra. I professionisti possono scaricare liberamente questi notebook e impiegarli nel loro ambiente Databricks per acquisire familiarità con il loro utilizzo. Il codice presentato può quindi essere adattato ad altri modelli simili, fornendo alle organizzazioni che utilizzano Databricks come base per i loro sforzi di previsione ulteriori opzioni per utilizzare l'IA generativa nei loro processi di pianificazione delle risorse.
Inizia oggi stesso con Databricks per la modellazione predittiva con questa serie di notebook.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.