Osservabilità per qualsiasi agente, ovunque: Tracciamento pronto per la produzione con OpenTelemetry e Unity Catalog su Databricks
Le tracce OpenTelemetry in Unity Catalog creano un volano di miglioramento continuo per gli agenti AI attraverso analisi, valutazioni e monitoraggio.
- Il Problema: Gli agenti AI generano volumi massicci di dati di traccia, ma gli strumenti di osservabilità tradizionali rendono tali dati costosi da conservare, difficili da governare e complessi da utilizzare nei flussi di lavoro di valutazione e analisi.\r\n* La Soluzione: Databricks ora supporta la scrittura di tracce OpenTelemetry (OTel) direttamente nelle tabelle di Unity Catalog tramite un percorso di ingestione completamente gestito e serverless.\r\n* Il Vantaggio: Depositando le tracce direttamente nel Lakehouse, i team ottengono dati di osservabilità governati e pronti per l'analisi, con conservazione a lungo termine, flussi di lavoro di valutazione e monitoraggio unificati e nessuna infrastruttura OTel da gestire.\r\n* Il Risultato: Le tracce di produzione diventano immediatamente utilizzabili per l'analisi e la valutazione, consentendo cicli di iterazione più rapidi tra l'utilizzo nel mondo reale, la valutazione del modello e il miglioramento continuo.
Perché il tracciamento AI supera l'osservabilità tradizionale
Man mano che le applicazioni AI passano in produzione, le tracce diventano uno dei modi più chiari per comprendere il comportamento effettivo degli agenti, catturando prompt, chiamate a strumenti, risposte, latenza e percorsi di esecuzione. Senza un tracciamento robusto, è difficile capire perché gli agenti si comportano in un certo modo, rendendo il debug, la valutazione e la governance molto più complessi.
Le tracce AI diventano rapidamente preziose per i flussi di lavoro di analisi, valutazione e monitoraggio, andando oltre i casi d'uso tradizionali di debug e osservabilità. I team desiderano conservarle più a lungo, analizzarle con SQL, unirle a dati aziendali e di modello e riutilizzarle per la valutazione e il monitoraggio. Quando le tracce risiedono solo all'interno dei sistemi di osservabilità, tale flessibilità è limitata, la governance diventa frammentata e lo spostamento dei dati nei flussi di lavoro di analisi richiede spesso pipeline aggiuntive e duplicazioni, specialmente quando sono coinvolti dati di prompt sensibili.
Ingestione di tracce OTel
Databricks ora supporta la scrittura di tracce OTel direttamente in Unity Catalog utilizzando il formato OpenTelemetry (OTel). In pratica, ciò significa che le tracce possono essere ingerite in tempo reale e archiviate in tabelle Delta, dove beneficiano della stessa scalabilità, governance e strumenti del resto dei tuoi dati.
Questo cambia il modo in cui i team possono utilizzare i dati di traccia:
- Ingestione in tempo reale con conservazione pratica: Le tracce possono essere scritte man mano che vengono generate con un throughput elevato e conservate a lungo termine senza la pressione dei costi tipicamente associata alle piattaforme di osservabilità.
- Analizzare e governare utilizzando il Lakehouse: Una volta che le tracce sono in tabelle, puoi trattarle come qualsiasi altro dataset: interrogarle con SQL, creare dashboard, eseguire pipeline ETL, utilizzare strumenti come Genie e applicare controlli di governance come la mascheratura PII.
- Utilizzare lo stack di valutazione completo di MLflow: MLflow semplifica la ricerca, il filtro e l'analisi approfondita delle tracce per il debug. La persistenza delle tracce in Unity Catalog rimuove i tipici vincoli degli esperimenti (come i limiti di traccia), rendendo più facile eseguire valutazioni offline su larga scala, monitorare i sistemi di produzione e migliorare continuamente la qualità man mano che i carichi di lavoro aumentano.
SaaS vs. Lakehouse
Allora perché non affidarsi interamente a uno strumento di osservabilità SaaS?
- Economia della conservazione: Gli agenti generano payload di testo massicci. L'archiviazione di questi dati in Delta Lake su object storage è spesso significativamente più conveniente rispetto ai modelli di conservazione basati su SaaS.
- L'impasse PII: L'invio di prompt grezzi a piattaforme di terze parti può creare attriti InfoSec. Mantenere le tracce all'interno di Unity Catalog aiuta a mantenere la sovranità dei dati e semplifica la governance.
- Analisi, non solo telemetria: Mentre gli strumenti SaaS sono efficaci per metriche operative come la latenza, il Lakehouse fornisce un motore di analisi. Puoi unire le tracce con dati aziendali, come entrate e conversioni, per comprendere l'impatto reale e andare oltre la salute del sistema. Inoltre, il Lakehouse ti consente di applicare l'AI direttamente alle tue tracce e di costruire framework di valutazione per migliorare continuamente la qualità del sistema.
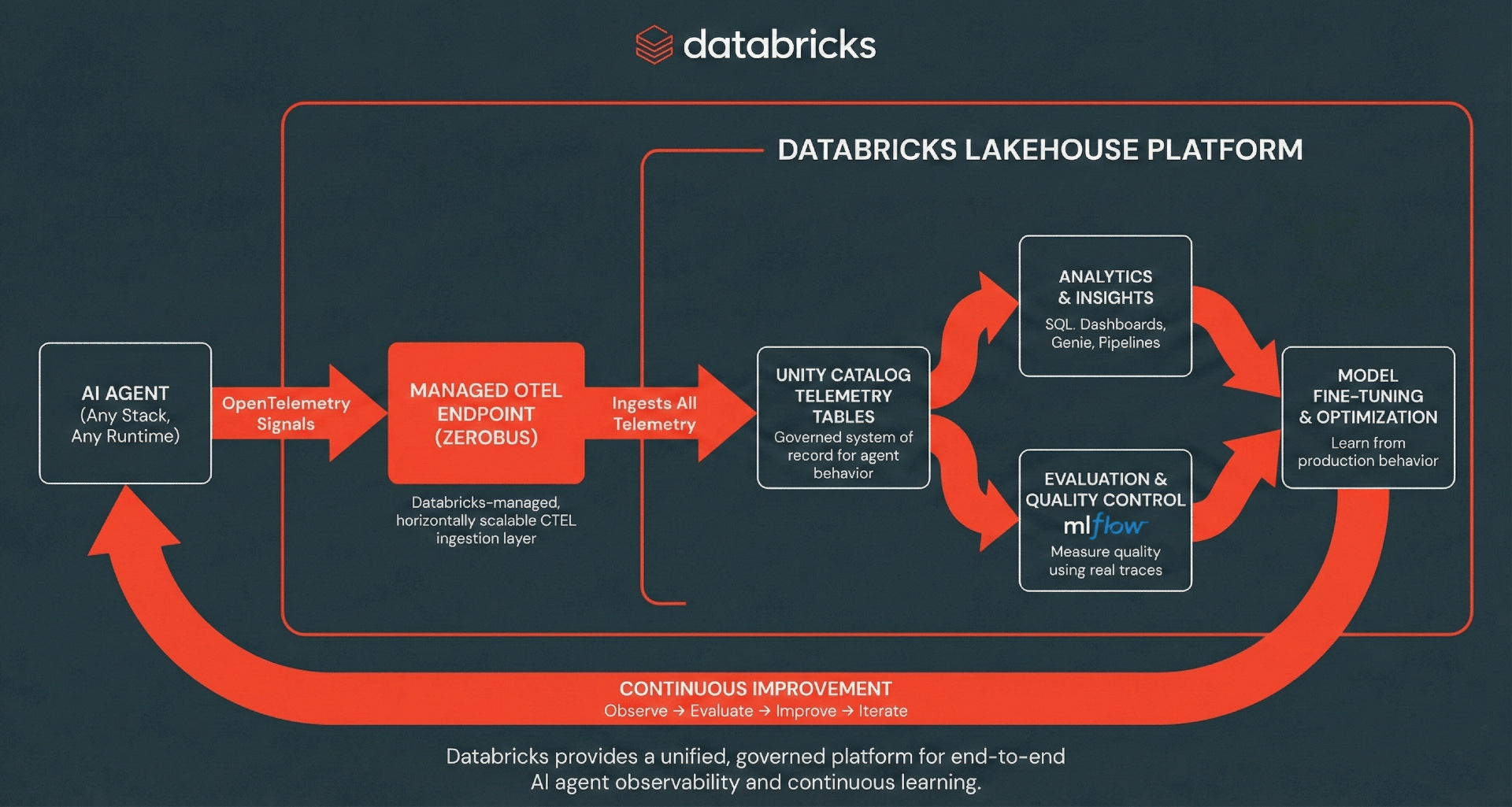
Architettura: Ingestione serverless di OpenTelemetry
Databricks supporta l'ingestione di tracce, log e metriche OpenTelemetry (OTel) direttamente nelle tabelle di Unity Catalog, utilizzando lo standard OTel per separare l'instrumentazione dall'archiviazione.
Databricks elimina la complessità operativa delle pipeline di telemetria tradizionali a più salti, fornendo un livello di ingestione gestito, alimentato in modo trasparente da Zerobus Ingest. Zerobus Ingest funge da motore di ingestione serverless completamente gestito che supporta nativamente i protocolli standard OpenTelemetry (OTLP) tramite gRPC per i collector open-source, mentre le sue capacità API REST consentono un'integrazione perfetta con framework applicativi come MLflow. Le applicazioni possono facilmente esportare span, log e metriche direttamente nelle tabelle di Unity Catalog, dove i dati sono archiviati in formato Delta. Con un'architettura a “singolo sink”, Zerobus Ingest semplifica l'osservabilità trasmettendo i dati direttamente al lakehouse. I collector esistenti compatibili con OLTP possono puntare direttamente a questo endpoint tramite gRPC, bypassando interamente i message bus intermedi come Kafka. Zerobus Ingest funge da pipeline di telemetria ad alto throughput, gestendo l'ingestione e la durabilità con zero overhead infrastrutturale. Qualsiasi client compatibile con OTel può esportare tracce a questo endpoint, inclusi i popolari framework di agenti AI in molti linguaggi di programmazione.
Da lì, tracce, log e metriche diventano dati di prima classe nel Lakehouse, alimentando analisi SQL ad-hoc, dashboard, analisi a valle e flussi di lavoro di valutazione e monitoraggio di MLflow. L'unificazione della telemetria crea un volano di miglioramento continuo in cui il comportamento in produzione alimenta la valutazione e l'analisi, che a sua volta porta a un'iterazione più rapida e a migliori prestazioni dell'agente.
Tutorial: Collegare le tracce al Lakehouse
Agente di esempio: Assistente del responsabile del supporto
Per questo blog, creeremo un semplice assistente del responsabile del supporto che possiamo utilizzare per dimostrare il tracciamento end-to-end. L'agente può essere distribuito al di fuori di Databricks, come abbiamo fatto qui, evidenziando che l'ingestione delle tracce è disaccoppiata dal luogo in cui l'agente viene eseguito.
Abbiamo creato un agente LangGraph alimentato da un modello Claude Sonnet 4.6 ospitato su Databricks per il ragionamento e la generazione di risposte. L'agente chiama uno Genie Space come strumento, che puoi distribuire qui.
Quando un utente pone una domanda basata sui dati, l'agente invoca Genie tramite l'API dello strumento MCP. Genie traduce la richiesta in SQL, la esegue sul dataset di supporto e restituisce il risultato. L'agente riassume quindi i risultati e fornisce spunti pratici per un responsabile del supporto.

Configurazione del tracciamento OTel con UC
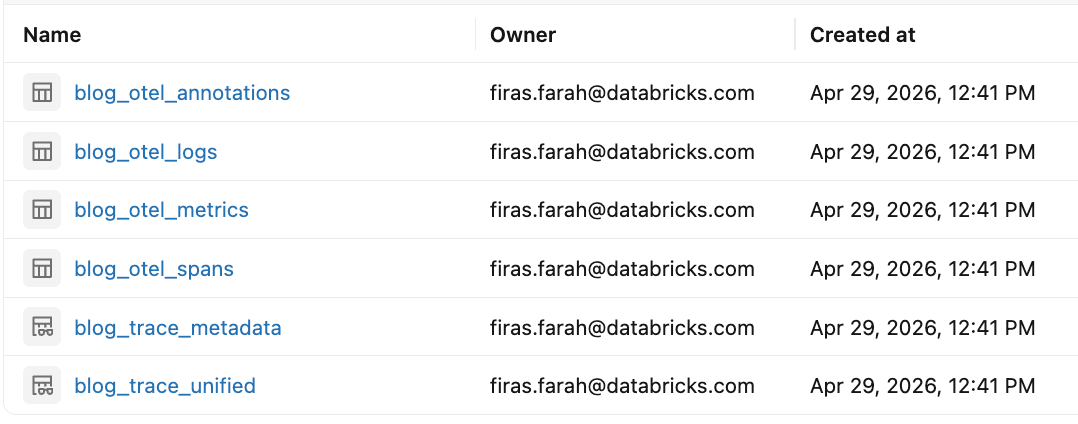
Prima di strumentare l'agente, configuriamo prima le tabelle in UC che memorizzeranno le tracce OpenTelemetry. In questo esempio, utilizziamo MLflow per creare le tabelle OpenTelemetry sottostanti in Unity Catalog e collegarle a un esperimento MLflow in modo che le tracce possano essere cercate, analizzate e annotate dall'interfaccia utente. Inizia identificando (o creando) un SQL warehouse e un esperimento MLflow, quindi utilizza la libreria Python di MLflow per predisporre le tabelle di Unity Catalog e associare lo schema all'esperimento. Per i passaggi completi, segui la documentazione qui.
Questa configurazione crea tabelle Unity Catalog per span, log e metriche OpenTelemetry. I dati sottostanti sono archiviati in formati di tabella conformi a OpenTelemetry, e il servizio MLflow crea automaticamente viste Databricks SQL accanto ad essi che trasformano i dati OpenTelemetry in un formato compatibile con MLflow per una più facile interrogazione e analisi. Questi includono:
<table_prefix>_otel_spans: dati di esecuzione dettagliati a livello di span per ogni richiesta<table_prefix>_otel_logs: dati di log/evento strutturati catturati durante l'esecuzione<table_prefix>_otel_metrics: telemetria numerica catturata durante l'esecuzione<table_prefix>_otel_annotations: dati di traccia specifici di MLflow che non sono un segnale OTel standard, inclusi metadati, tag, valutazioni/feedback, aspettative e link di esecuzione<table_prefix>_trace_unified: una vista consolidata che assembla i dati di traccia in un singolo record per traccia, inclusi i dati raw dello span e i metadati della traccia<table_prefix>_trace_metadata: Tag, metadati e valutazioni MLflow raggruppati per ID traccia; più performante della vista unificata quando si necessita solo dei metadati di traccia MLflow
Dopo aver configurato l'esperimento, la strumentazione dell'agente rimane la stessa. Qualsiasi libreria di strumentazione compatibile con OTel può esportare le tracce all'endpoint configurato. È possibile eseguire il tracciamento automatico e/o manuale come descritto qui. Nel nostro esempio, ci affidiamo a mlflow.langchain.autolog() per acquisire l'esecuzione dettagliata di LangGraph (chiamate di modello e chiamate di strumenti). Avvolgiamo anche il punto di ingresso con @MLflow.trace per stabilire uno span radice a livello di richiesta, consentendo a ogni invocazione di essere osservata come una singola esecuzione end-to-end.
Ispezione di una traccia di esempio
Ora che l'agente è strumentato e le tracce confluiscono in Unity Catalog, esaminiamo un'esecuzione reale.
Per questo esempio, abbiamo chiesto all'Assistente del Responsabile del Supporto:
"Quale ingegnere del supporto dovrei proporre per una promozione?"
L'agente ha valutato la richiesta, ha chiamato lo spazio Genie più volte per raccogliere dati di supporto e ha restituito una raccomandazione basata su metriche di performance.

Sebbene la risposta sembri semplice, la traccia rivela il percorso di esecuzione sottostante che l'ha prodotta. Nell'esperimento MLflow, possiamo vedere ciascuna delle chiamate degli strumenti, così come la logica di ragionamento del nostro modello claude sonnet. Possiamo vedere che ha chiamato lo strumento genie space tre volte prima di formulare una risposta finale.
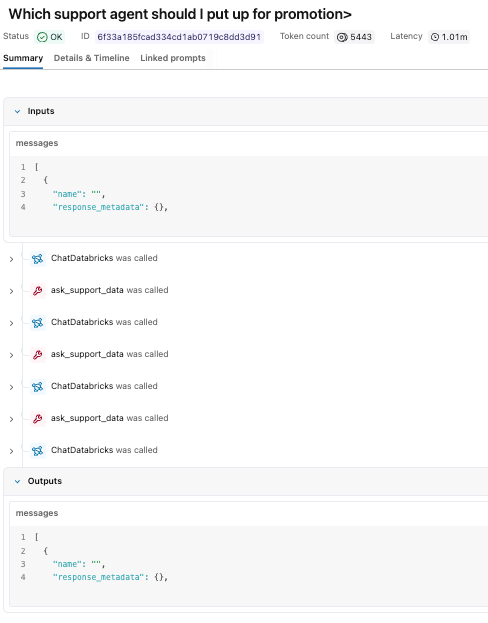
Possiamo cliccare su ciascuno dei singoli passaggi per studiare gli input e gli output.
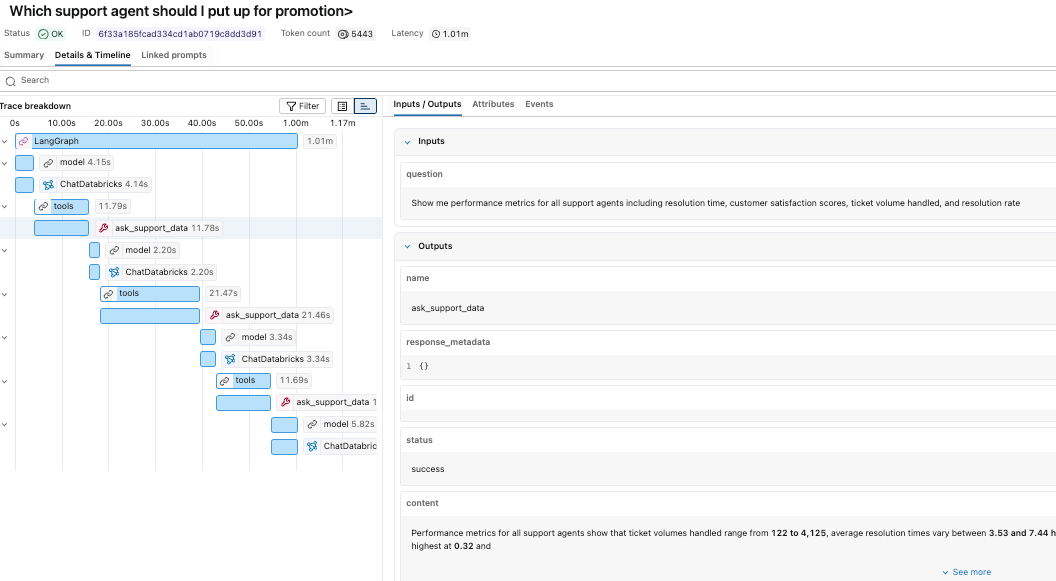
Poiché le tracce sono archiviate come tabelle Delta, possono essere interrogate come qualsiasi altro dataset. Possiamo iniziare con la vista mlflow_experiment_trace_unified, dove troveremo un record che include la richiesta, la risposta, i metadati della traccia e un array di span.
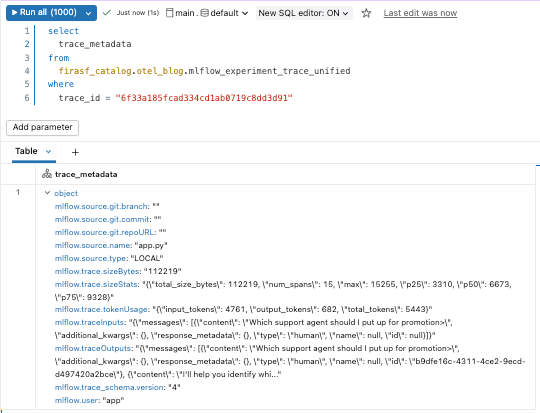
Oltre il Debugging: Analisi sui Dati di Traccia
Ora che le tracce sono archiviate in Unity Catalog, diventano immediatamente disponibili per l'analisi sia batch che in streaming.
Governance in Unity Catalog
I prompt e le risposte, tuttavia, contengono spesso informazioni sensibili, quindi trattare i dati di traccia come dati governati è fondamentale. Archiviandoli in Unity Catalog, le tracce ereditano controlli di accesso granulari, dalle autorizzazioni di catalogo e schema al mascheramento delle colonne e al filtraggio a livello di riga, consentendo analisi sicure e pronte per la produzione senza limitare la flessibilità.
Una volta stabilito l'accesso, i team possono eseguire in modo sicuro analisi ad-hoc interrogando le tabelle e le viste sottostanti con SQL, come abbiamo fatto sopra. Possiamo anche costruire pipeline ETL, oltre a dashboard e spazi Genie, per ottenere insight aziendali azionabili.
Dashboard
L'interfaccia utente dell'esperimento MLflow ora include dashboard di osservabilità native per le tracce in Unity Catalog, comprese le viste per volume di tracce, errori, latenza, utilizzo dei token e costi. Per la maggior parte dei team, questo è sufficiente per monitorare la salute quotidiana dell'agente.
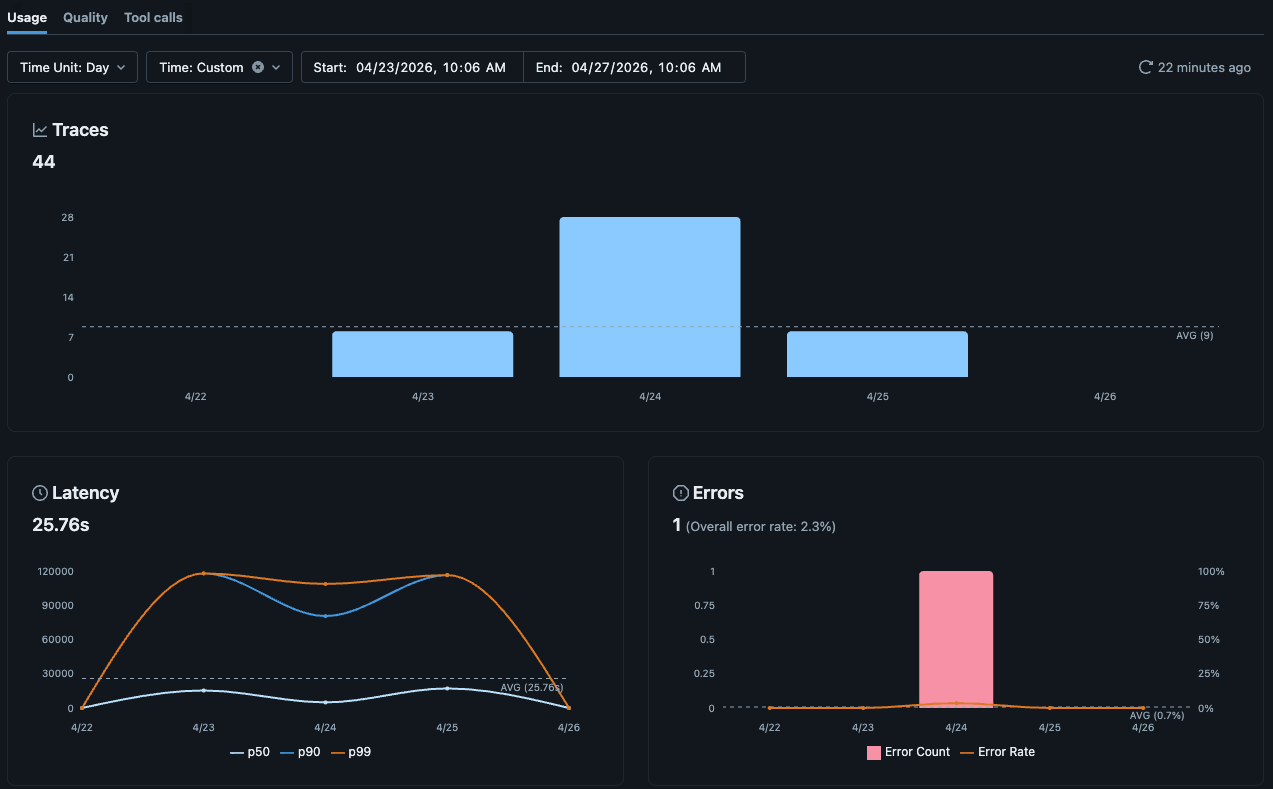
Quando hai bisogno di una vista che vada oltre le visualizzazioni native, le tabelle di traccia sono comunque solo tabelle Delta in Unity Catalog. Puoi costruire una dashboard AI/BI personalizzata su di esse e scrivere SQL standard (con l'aiuto dell'AI) per modellare ciò che il tuo team ritiene importante.
Per mostrare cosa possono aggiungere le dashboard personalizzate rispetto alle viste native, abbiamo costruito un Centro Operazioni AI sulle nostre tabelle di traccia. Di seguito sono riportate un paio di funzionalità degne di nota.
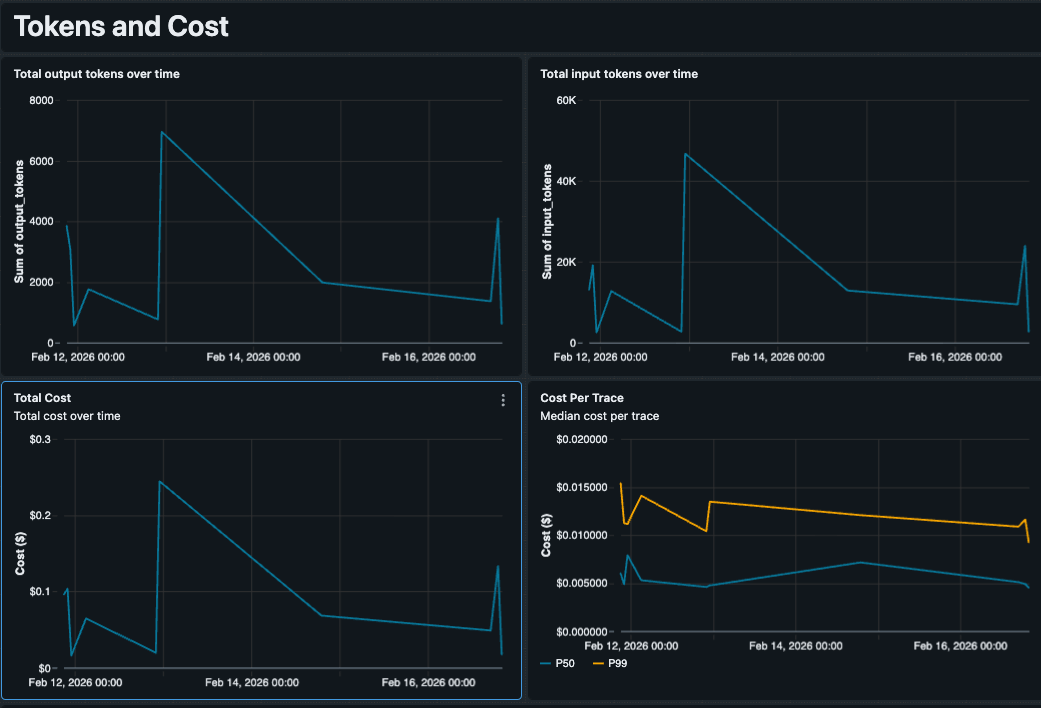
Analisi Costi Personalizzata con Prezzi Contrattuali
Le metriche di costo native si basano su prezzi di listino standard, che possono essere imprecisi per i team che hanno negoziato tariffe o eseguono modelli ottimizzati con prezzi diversi. Poiché controlliamo il SQL, abbiamo incorporato la nostra logica di prezzo direttamente nella query. La dashboard traccia l'utilizzo dei token per tipo di modello (ad esempio, GPT 5.5 vs. Claude 4.6 Sonnet) e applica le nostre tariffe contrattuali per produrre un Costo Stimato per Traccia che riflette ciò che effettivamente paghiamo. Questo rende facile individuare anomalie costose, come una singola query complessa che costa $0.50 a causa di un ciclo di recupero.
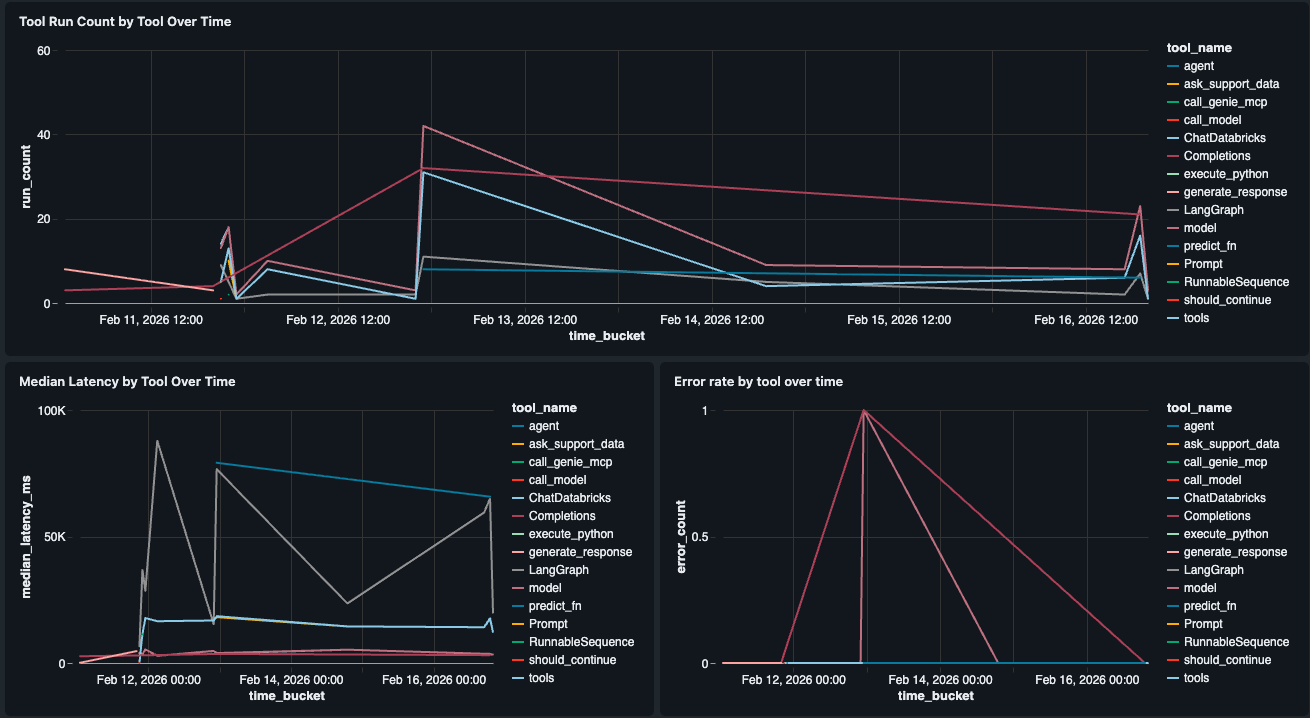
Performance a Livello di Componente
Le viste di latenza native mostrano P50/P99 a livello di traccia. Per andare più a fondo e vedere quale strumento è lento, abbiamo costruito un widget Performance Strumento che suddivide la latenza (P50, P99) e i tassi di errore per ogni singolo strumento nell'agente (ad esempio, retrieve_docs vs. generate_response). Questo ci dice se l'LLM, una chiamata allo strumento Genie o un altro passaggio è il collo di bottiglia, così possiamo individuare esattamente dove l'esperienza utente si sta degradando.
Spazi Genie
Sia gli stakeholder aziendali che quelli tecnici spesso desiderano esplorare il comportamento dell'agente senza scrivere SQL. Esporrendo le tabelle di traccia tramite Genie, i team possono abilitare l'analisi in linguaggio naturale sui loro dati di telemetria, consentendo agli utenti di porre domande direttamente su prestazioni, utilizzo degli strumenti, latenza e comportamento del modello. Nel nostro esempio, questo potrebbe includere domande come:
- Quali tipi di richieste richiedono un'escalation?
- I tentativi di strumenti stanno aumentando?
- Quali query attivano i percorsi di esecuzione più complessi?
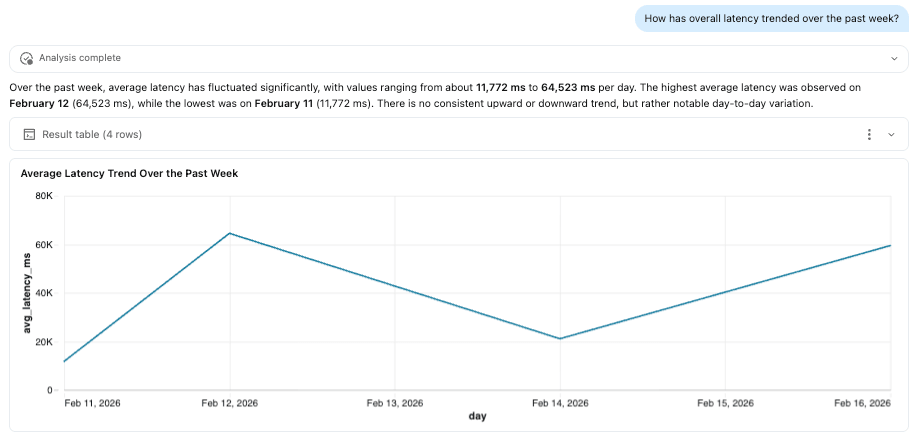
Pipeline ETL
Poiché le tracce sono archiviate come tabelle Delta, possono alimentare pipeline ETL a valle proprio come qualsiasi altro dataset. Abilitando Change Data Feed (CDF), i team possono elaborare i dati di traccia in modo incrementale, sia in batch che in streaming, senza scansionare ripetutamente intere tabelle.
Ciò rende possibile rendere operativa l'osservabilità. Ad esempio, una pipeline potrebbe monitorare i pattern di traccia e attivare avvisi quando la latenza supera le soglie definite, i fallimenti degli strumenti aumentano bruscamente o l'utilizzo dei token devia dalle baseline previste. Questi segnali possono quindi alimentare dashboard, sistemi di notifica o flussi di lavoro di remediation automatizzati.
È importante sottolineare che questo integra le protezioni in tempo reale come gli AI Guardrails. Mentre i guardrail applicano le policy al momento della richiesta, le pipeline ETL creano un ciclo di feedback, aiutando i team ad analizzare le tendenze, affinare le policy e migliorare continuamente le prestazioni dell'agente.
Chiusura del Ciclo: Dalle Tracce di Produzione alla Valutazione
Una volta disponibili, le tracce possono alimentare l'intero evaluation stack di MLflow, consentendo ai team di misurare, migliorare e mantenere la qualità delle loro applicazioni GenAI lungo l'intero ciclo di vita. La valutazione e il monitoraggio si basano direttamente sul tracciamento, permettendo che la stessa telemetria acquisita durante lo sviluppo, il testing e la produzione venga valutata utilizzando giudici LLM e metriche personalizzate.
Valutare durante lo sviluppo
MLflow ci consente di eseguire valutazioni su un dataset di valutazione, applicando giudici integrati o personalizzati per valutare la qualità della risposta. Un approccio efficace è quello di bootstrap questo dataset da tracce reali. Poiché questi prompt provengono da interazioni utente reali, rappresentano meglio gli scenari che il tuo agente deve gestire rispetto a casi di test puramente sintetici.
Di seguito, creiamo un dataset di valutazione da tracce acquisite di recente. MLflow utilizza un warehouse SQL per cercare e materializzare i record del dataset, quindi assicurati di configurare l'ID del warehouse nel tuo ambiente.
Con il dataset a disposizione, possiamo definire i giudici che valuteranno la nostra applicazione. MLflow fornisce un set di giudici integrati e ci consente anche di definire linee guida personalizzate adattate al comportamento atteso del nostro agente.
E ora possiamo vedere i risultati nell'esperimento MLflow.
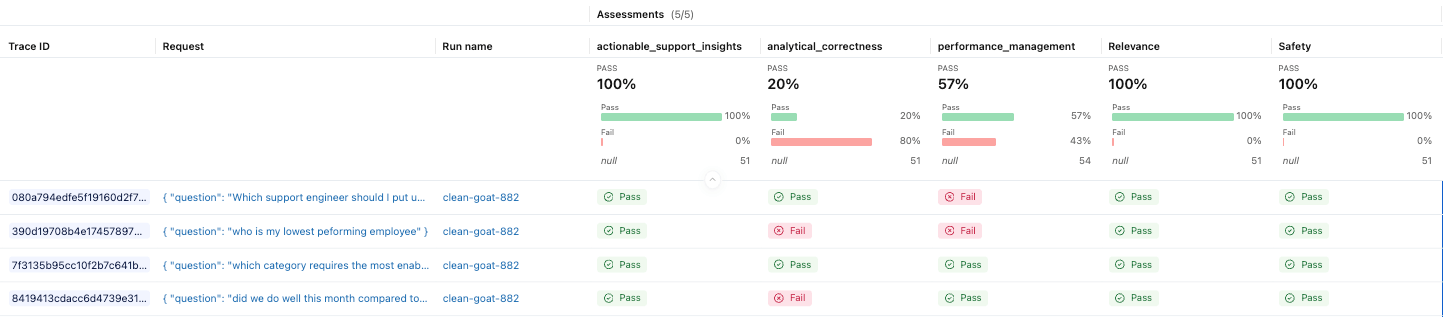
Monitoraggio della produzione
Le valutazioni di sviluppo ci aiutano a convalidare il comportamento prima del rilascio, ma il monitoraggio della produzione ci mostra come l'applicazione si comporta con gli utenti reali. MLflow può valutare automaticamente le tracce in tempo reale utilizzando gli stessi giudici, aiutandoci a rilevare rapidamente regressioni, deviazioni e modelli di errore emergenti. Ciò trasforma la valutazione da un compito una tantum a una pratica continua man mano che l'applicazione si evolve.
Clienti che utilizzano l'osservabilità AI su Databricks
Experian
La transizione al tracing di MLflow per il nostro assistente virtuale Eva e il sistema di email automatizzate Latte è stata senza soluzione di continuità. Con le Tracce in Unity Catalog, il nostro team di data science esegue centinaia di migliaia di tracce attraverso tabelle Delta governate e valuta la qualità degli agenti su larga scala, il tutto senza lasciare Databricks. Man mano che integriamo flussi di lavoro di valutazione più complessi, avere tracing e valutazioni in un'unica piattaforma governata significa non dover mantenere strumenti separati per ogni fase del ciclo di vita dell'agente.—James Lin, Responsabile dell'Innovazione AI/ML, Experian
Superhuman (Grammarly)
Stiamo standardizzando il tracing di MLflow come livello di osservabilità per tutti i nostri agenti AI in Superhuman. Preferiamo l'integrazione più ampia della piattaforma rispetto alla costruzione e alla manutenzione di una soluzione personalizzata o puntuale - il carico di manutenzione era un vero problema per i nostri team. Con le Tracce di MLflow in Unity Catalog, possiamo scalare a centinaia di migliaia di tracce al giorno, e i nostri ricercatori possono auto-servirsi ed esplorare il comportamento degli agenti direttamente nell'interfaccia utente di MLflow senza alcun supporto ingegneristico. Avere tracing, valutazione e monitoraggio tutti in un'unica piattaforma governata è esattamente ciò di cui avevamo bisogno per portare i nostri agenti in produzione con fiducia.—Martin Jewell, Responsabile dell'Infrastruttura AI MLE, Superhuman
SmartSheet
Abbiamo scelto Databricks come nostra piattaforma per la GenAI, e MLflow è il modo in cui il nostro team costruisce e valuta gli agenti AI. Durante una co-costruzione di tre giorni con Databricks, abbiamo implementato due agenti di produzione utilizzando il tracing di MLflow, le valutazioni, i giudici personalizzati e l'etichettatura - e con le tracce archiviate in Unity Catalog, possiamo eseguire decine di migliaia di valutazioni e iterare sulla qualità con fiducia man mano che scaliamo.—Kapil Ashar, VP dell'Ingegneria, Smartsheet
The Standard
The Standard aiuta i nostri clienti a raggiungere il benessere finanziario e la tranquillità. Dati e AI sono fondamentali per offrire questa esperienza su larga scala. Integrando la funzionalità degli agenti AI - come l'estrazione di informazioni chiave da documenti di sottoscrizione in entrata e presentazioni di reclami - in importanti funzioni aziendali, siamo in grado di fornire un servizio eccezionale ai nostri clienti e partner. Con il tracing e il monitoraggio della produzione, i nostri team possono comprendere rapidamente come si comportano i sistemi ed effettuare aggiornamenti affidabili. Governare le tracce in Unity Catalog insieme al resto dei nostri dati sulla Databricks Data Intelligence Platform ci permette di interrogare, monitorare e iterare in modo sicuro, senza aggiungere complessità inutile.—Porter Orr, AVP di AI e Automazione, The Standard
Domande Frequenti (FAQ)
D: Posso usarlo per agenti in esecuzione al di fuori di Databricks?
R: Sì, l'agente può essere in esecuzione ovunque. Infatti, l'esempio di agente assistente di supporto utilizzato per questo blog è distribuito localmente.
D: Quali sono i limiti di throughput e di archiviazione di questa soluzione?
R: Il limite di throughput di ingestione inizia a 200 QPS. Non ci sono limiti di archiviazione. I precedenti limiti sulle tracce per esperimento non sono più applicabili. Se hai bisogno di limiti di throughput più elevati, contatta il tuo team account Databricks.
D: Cosa posso fare per garantire che le mie query di ricerca, l'esperienza dell'esperimento MLflow e l'analisi a valle rimangano performanti?
R: Con l'ultimo aggiornamento del prodotto, le tabelle sono automaticamente raggruppate in modo liquido per mantenere i dati organizzati in modo ottimale. Per volumi di tracce maggiori, tuttavia, dovresti creare una vista materializzata sopra le viste derivate e aggiornarla incrementalmente per mantenere le prestazioni delle query.
D: Come gestisce questo le PII trovate nei prompt degli utenti?
R: Questa funzionalità non applica alcuna gestione speciale alle PII. Tuttavia, i dati sono archiviati in Unity Catalog, dove puoi sfruttare le capacità di governance, come controlli di accesso granulari, mascheramento delle colonne e filtraggio delle righe, per gestire e limitare l'accesso a valle.
Inizia
Per iniziare, segui la documentazione.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.