Come leggere le tabelle di Unity Catalog in Snowflake, in 3 semplici passaggi
Unity Catalog ora funziona con Snowflake, Dremio, Starburst, EMR e altri ancora, per aiutarti a unificare dati e AI
di Aniruth Narayanan, Randy Pitcher, Susan Pierce e Ryan Johnson
Scopri come connetterti alle API REST Iceberg di Unity Catalog da Snowflake per leggere un singolo file di dati sorgente come Iceberg.
Aggiornamento: Questo blog è stato aggiornato per riflettere il supporto di Snowflake per le credenziali fornite dal catalogo.
Databricks ha aperto la strada all'architettura del data lakehouse ed è all'avanguardia nell'interoperabilità dei formati. Siamo entusiasti di vedere più piattaforme adottare l'architettura lakehouse e iniziare a utilizzare formati e standard interoperabili. L'interoperabilità consente ai clienti di ridurre la costosa duplicazione dei dati utilizzando una singola copia dei dati con la loro scelta di strumenti di analisi e IA per i loro carichi di lavoro. In particolare, un modello comune per i nostri clienti è utilizzare le prestazioni/prezzo ETL best-in-class di Databricks per i dati upstream, accedendovi da strumenti di BI e analisi, come Snowflake.
Unity Catalog è una soluzione di governance unificata e aperta per asset di dati e IA. Una funzionalità chiave di Unity Catalog è la sua implementazione delle API Iceberg REST Catalog. Ciò semplifica l'utilizzo di un lettore compatibile con Iceberg senza dover aggiornare manualmente la posizione dei metadati.
In questo post del blog, spiegheremo perché l'Iceberg REST Catalog è utile e illustreremo un esempio di come leggere le tabelle di Unity Catalog in Snowflake.
Nota: Questa funzionalità è disponibile su tutti i provider cloud. Le istruzioni seguenti sono specifiche per AWS S3, ma è possibile utilizzare altre piattaforme di object storage come Azure Data Lake Storage (ADLS) o Google Cloud Storage (GCS).
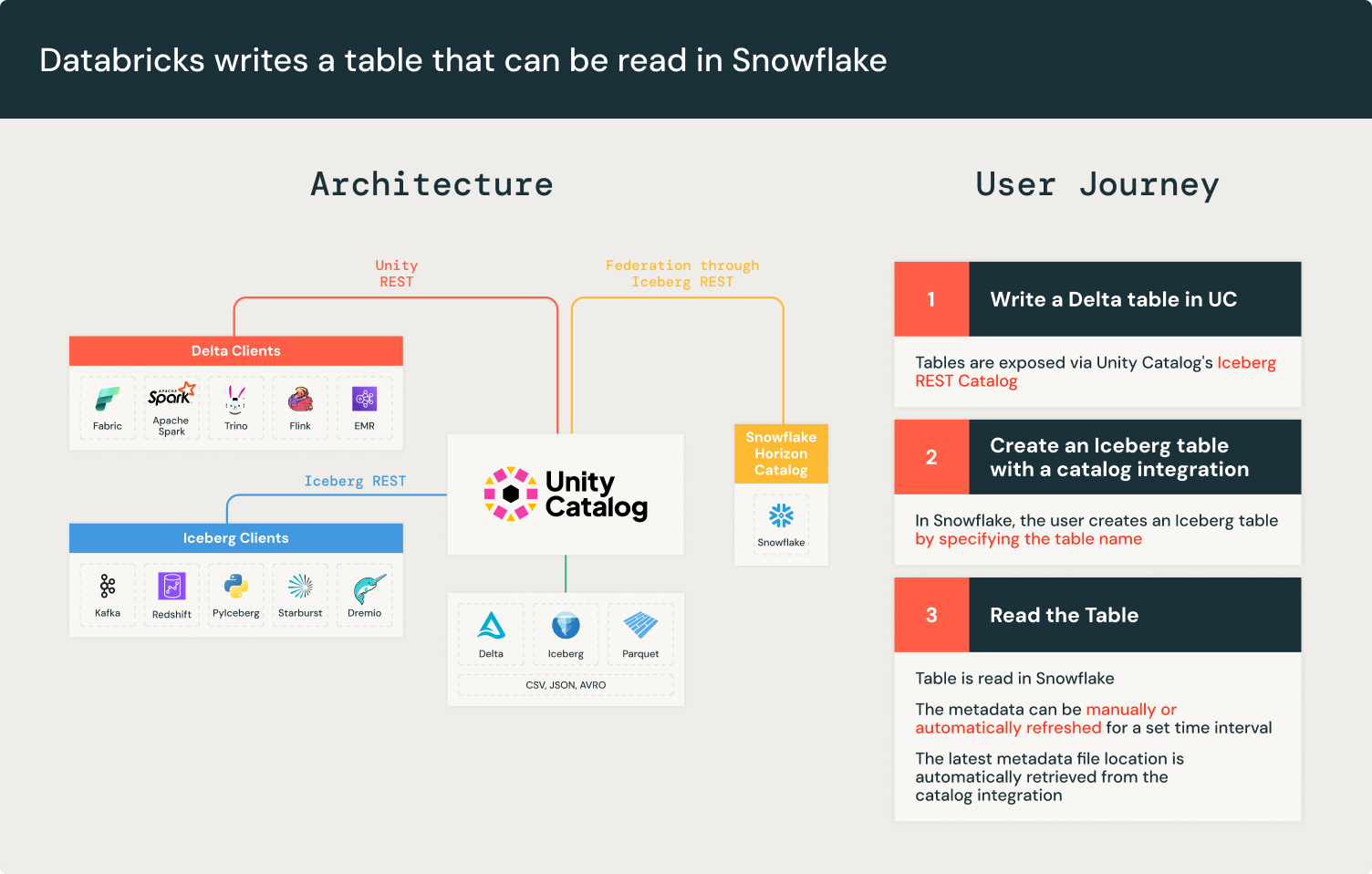
Integrazione del catalogo Iceberg REST API
Apache Iceberg™ mantiene atomicità e coerenza creando nuovi file di metadati per ogni modifica della tabella. Ciò garantisce che le scritture incomplete non danneggino un file di metadati esistente. Il catalogo Iceberg tiene traccia dei nuovi metadati per ogni scrittura. Tuttavia, non tutti i motori possono connettersi a ogni catalogo Iceberg, costringendo i clienti a tenere traccia manualmente della posizione del nuovo file di metadati.
Iceberg risolve l'interoperabilità tra motori e cataloghi con l'API Iceberg REST Catalog. L'Iceberg REST catalog è una specifica API standardizzata e aperta che è un'interfaccia unificata per i cataloghi Iceberg, disaccoppiando le implementazioni del catalogo dai client.
Unity Catalog implementa le API Iceberg REST Catalog fin dal lancio di Universal Format (UniForm) nel 2023. Unity Catalog espone i metadati delle tabelle più recenti, garantendo l'interoperabilità con qualsiasi client Iceberg compatibile con l'Iceberg REST Catalog come Apache Spark™, Apache Trino e Snowflake. Gli endpoint Iceberg REST Catalog di Unity Catalog consentono ai sistemi esterni di accedere alle tabelle e beneficiare di miglioramenti delle prestazioni come Liquid Clustering e Predictive Optimization, mentre i carichi di lavoro Databricks continuano a beneficiare delle funzionalità avanzate di Unity Catalog come Change Data Feed. Inoltre, gli endpoint Iceberg REST Catalog di Unity Catalog estendono la governance tramite credenziali fornite.
L'integrazione del catalogo API REST di Snowflake consente di connettersi alle API Iceberg REST di Unity Catalog per recuperare la posizione del file di metadati più recente. Ciò significa che con Unity Catalog, è possibile leggere le tabelle direttamente in Snowflake.
Nota: Al momento della scrittura, il supporto di Snowflake per l'Iceberg REST Catalog è in anteprima pubblica. Tuttavia, le API Iceberg REST di Unity Catalog sono generalmente disponibili.
Ci sono 3 passaggi per creare un'integrazione del catalogo REST in Snowflake:
- Abilitare UniForm su una tabella Delta Lake in Databricks per generare metadati Iceberg
- Registrare Unity Catalog in Snowflake come catalogo
- Creare una tabella Iceberg in Snowflake per poter interrogare i dati
Iniziare
Inizieremo in Databricks, con la nostra tabella gestita da Unity Catalog, e ci assicureremo che possa essere letta come Iceberg. Quindi, passeremo a Snowflake per completare i passaggi rimanenti.
Prima di iniziare, sono necessari alcuni componenti:
- Un account Databricks con Unity Catalog (abilitato per impostazione predefinita per i nuovi workspace)
- Un bucket AWS S3 e privilegi IAM
- Un account Snowflake in grado di accedere alla tua istanza Databricks e S3
I namespace di Unity Catalog seguono un formato nome_catalogo.nome_schema.nome_tabella. Nell'esempio seguente, useremo uc_catalog_name.uc_schema_name.uc_table_name per la nostra tabella Databricks.
Passaggio 1: Abilitare UniForm su una tabella Delta in Databricks
In Databricks, è possibile abilitare UniForm su una tabella Delta Lake. Per impostazione predefinita, le nuove tabelle sono gestite da Unity Catalog. Le istruzioni complete sono disponibili nella documentazione UniForm, ma sono incluse anche di seguito.
Per una nuova tabella, è possibile abilitare UniForm durante la creazione della tabella nel proprio workspace:
Se si dispone di una tabella esistente, è possibile farlo tramite un comando ALTER TABLE:
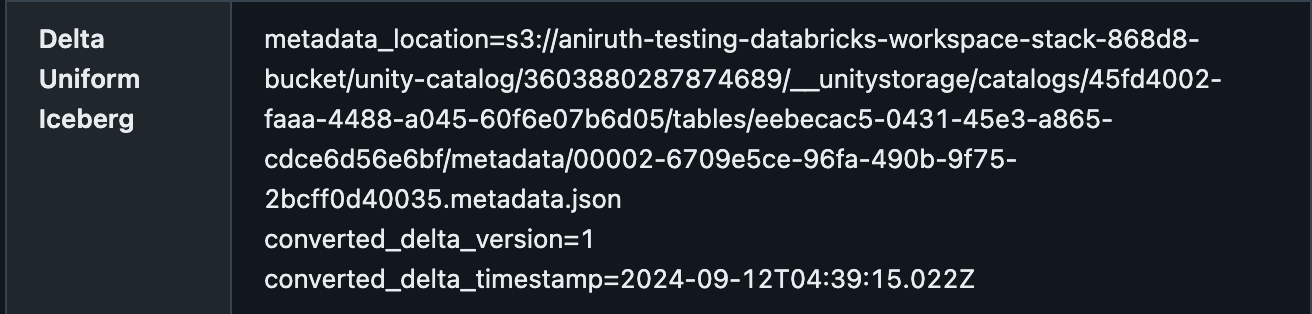
È possibile confermare che una tabella Delta abbia UniForm abilitato in Catalog Explorer, nella scheda Dettagli, con la posizione dei metadati. Dovrebbe apparire simile a questo:
Passaggio 2: Registrare Unity Catalog in Snowflake
Ancora in Databricks, creare un service principal dalle impostazioni dell'amministratore del workspace e generare il segreto e l'ID client associati. Invece di un service principal, è anche possibile autenticarsi con token personali per scopi di debug e test. Si consiglia di utilizzare un service principal per i carichi di lavoro di sviluppo e produzione. Per questo passaggio, sarà necessario il proprio <deployment-name> e i valori per il proprio <client-id> e <secret> OAuth per poter autenticare l'integrazione in Snowflake.
Ora passa al tuo account Snowflake.
Nota: Ci sono alcune differenze di denominazione tra Databricks e Snowflake che potrebbero creare confusione:
- Un “catalogo” in Databricks è un “warehouse” nella configurazione dell'integrazione del catalogo Iceberg di Snowflake.
- Uno “schema” in Databricks è un “catalog_namespace” nell'integrazione del catalogo Iceberg di Snowflake.
Si vedrà nell'esempio seguente che il valore CATALOG_NAMESPACE è uc_schema_name dalla nostra tabella Unity Catalog.
In Snowflake, creare un'integrazione del catalogo per i cataloghi REST Iceberg. Seguendo questo processo, creerai un'integrazione del catalogo come segue:
L'integrazione del catalogo REST API sblocca anche le credenziali fornite e il refresh automatico basato sul tempo.
Le credenziali fornite includono sia la posizione di archiviazione di una tabella sia una credenziale di accesso temporanea per accedere a tale posizione. Ciò consente ai client di accedere alle tabelle tramite il catalogo senza configurare l'accesso diretto del client alla posizione di archiviazione della tabella. Consigliamo di utilizzare le credenziali fornite per semplificare e centralizzare la governance nel catalogo. Nell'esempio precedente, configuriamo Snowflake per utilizzare le credenziali fornite da Unity Catalog con il parametro ACCESS_DELEGATION_MODE = VENDED_CREDENTIALS nell'oggetto REST_CONFIG.
Attualmente, Snowflake supporta solo le credenziali fornite per le tabelle in AWS S3. Per le tabelle in Azure Data Lake Storage (ADLS) o Google Cloud Storage (GCS), Snowflake richiede l'accesso diretto alla posizione di archiviazione della tabella con un volume esterno.
Con il refresh automatico, Snowflake interrogherà la posizione dei metadati più recente da Unity Catalog a intervalli di tempo definiti per l'integrazione del catalogo. Tuttavia, il refresh automatico è incompatibile con il refresh manuale, richiedendo agli utenti di attendere fino all'intervallo di tempo dopo un aggiornamento della tabella. Il parametro REFRESH_INTERVAL_SECONDS configurato sull'integrazione del catalogo si applica a tutte le tabelle Snowflake Iceberg create con questa integrazione. Non è personalizzabile per tabella.
Passaggio 3: Creare una tabella Apache Iceberg™ in Snowflake
In Snowflake, crea una tabella Iceberg con l'integrazione del catalogo creata in precedenza per connettersi alla tabella Delta Lake. Puoi scegliere il nome per la tua tabella Iceberg in Snowflake; non è necessario che corrisponda alla tabella Delta Lake in Databricks.
Nota: La mappatura corretta per CATALOG_TABLE_NAME in Snowflake è il nome della tabella Databricks. Nel nostro esempio, questo è uc_table_name. Non è necessario specificare il catalogo o lo schema in questo passaggio, poiché erano già specificati nell'integrazione del catalogo.
Facoltativamente, puoi abilitare il refresh automatico utilizzando l'intervallo di tempo dell'integrazione del catalogo aggiungendo AUTO_REFRESH = TRUE al comando. Nota che se il refresh automatico è abilitato, il refresh manuale è disabilitato.
Ora hai letto correttamente la tabella Delta Lake in Snowflake.
Completamento: Testare la connessione
In Databricks, aggiorna i dati della tabella Delta inserendo una nuova riga.
Se in precedenza hai abilitato il refresh automatico, la tabella si aggiornerà automaticamente all'intervallo di tempo specificato. Se non l'hai fatto, puoi eseguire manualmente il refresh eseguendo ALTER ICEBERG TABLE <snowflake_table_name> REFRESH.
Nota: se in precedenza hai abilitato il refresh automatico, non puoi eseguire il comando di refresh manuale e dovrai attendere il completamento dell'intervallo di refresh automatico per aggiornare la tabella.
Siamo entusiasti del continuo supporto per l'architettura lakehouse. I clienti non devono più duplicare i dati, riducendo costi e complessità. Questa architettura consente inoltre ai clienti di scegliere lo strumento giusto per il carico di lavoro giusto.
La chiave per un lakehouse aperto è archiviare i dati in un formato aperto come Delta Lake o Iceberg. I formati proprietari bloccano i clienti in un motore, ma i formati aperti offrono flessibilità e portabilità. Indipendentemente dalla piattaforma, incoraggiamo i clienti a possedere sempre i propri dati come primo passo verso l'interoperabilità. Nei prossimi mesi, continueremo a sviluppare funzionalità che semplificheranno la gestione di un data lakehouse aperto con Unity Catalog.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.