Cluster condivisi in Unity Catalog per vincere: introduzione alle librerie di cluster, UDF Python, Scala, Machine Learning e altro ancora
di Jakob Mund, Stefania Leone, Martin Grund, Herman van Hövell, Andrew Li e Sven Wagner-Boysen
Siamo entusiasti di annunciare che puoi eseguire ancora più carichi di lavoro sui cluster multi-utente altamente efficienti di Databricks grazie alle nuove funzionalità di sicurezza e governance in Unity Catalog. I team di dati possono ora sviluppare ed eseguire carichi di lavoro SQL, Python e Scala in modo sicuro su risorse di calcolo condivise. Con ciò, Databricks è l'unica piattaforma nel settore che offre un controllo degli accessi granulare sul calcolo condiviso per carichi di lavoro Scala, Python e SQL Spark.
A partire da Databricks Runtime 13.3 LTS, puoi spostare senza problemi i tuoi carichi di lavoro su cluster condivisi, grazie alle seguenti funzionalità disponibili sui cluster condivisi:
- Librerie cluster e script di inizializzazione: Semplifica la configurazione del cluster installando librerie cluster ed eseguendo script di inizializzazione all'avvio, con sicurezza e governance avanzate per definire chi può installare cosa.
- Scala: Esegui in modo sicuro carichi di lavoro Scala multi-utente insieme a Python e SQL, con isolamento completo del codice utente tra utenti concorrenti e applicando le autorizzazioni di Unity Catalog.
- Python e Pandas UDF: Esegui in modo sicuro UDF Python e (scalari) Pandas, con isolamento completo del codice utente tra utenti concorrenti.
- Machine Learning su singolo nodo: Esegui scikit-learn, XGBoost, prophet e altre librerie ML popolari utilizzando il nodo driver Spark, e usa MLflow per gestire il ciclo di vita del machine learning end-to-end.
- Structured Streaming: Sviluppa soluzioni di elaborazione e analisi dati in tempo reale utilizzando structured streaming.
Accesso ai dati semplificato in Unity Catalog
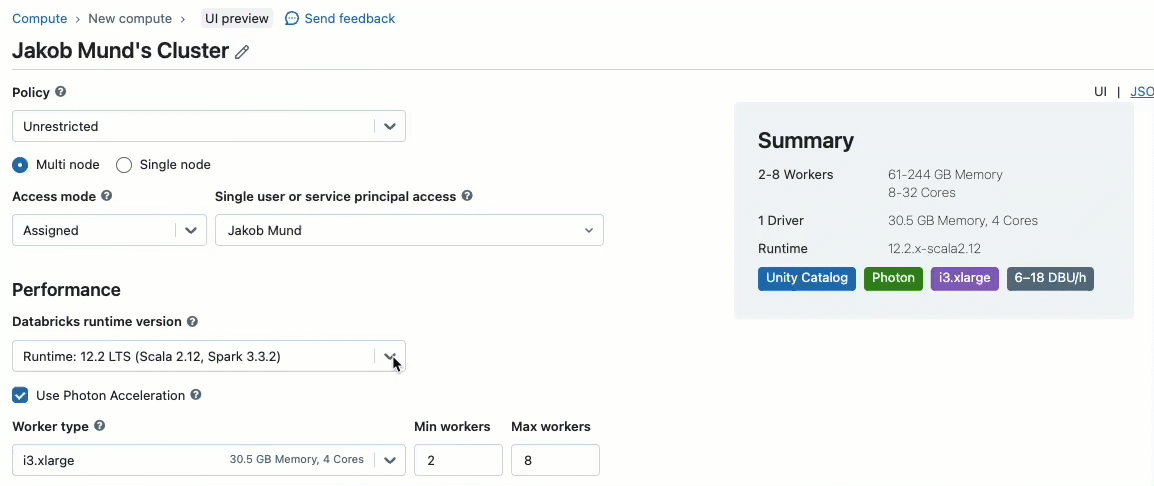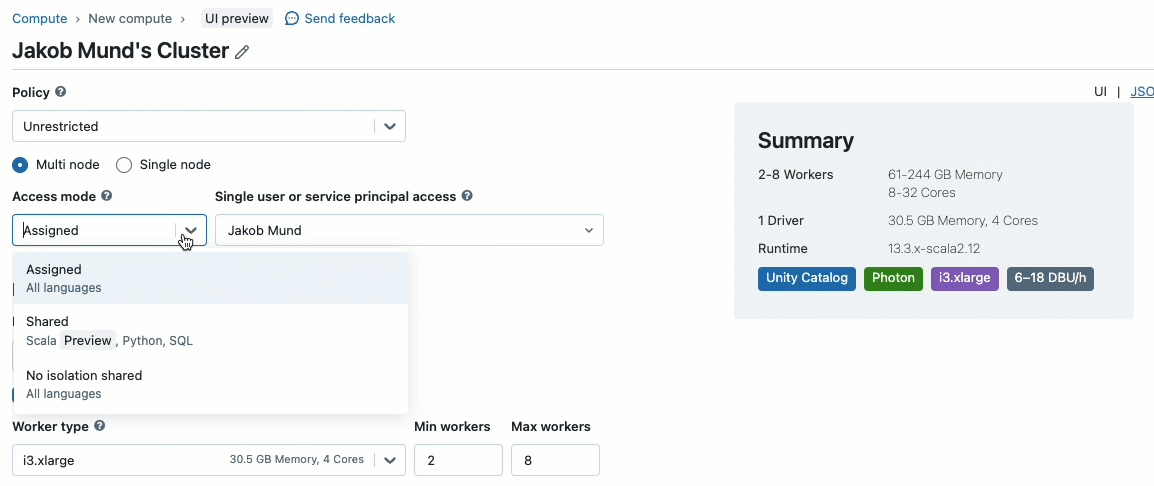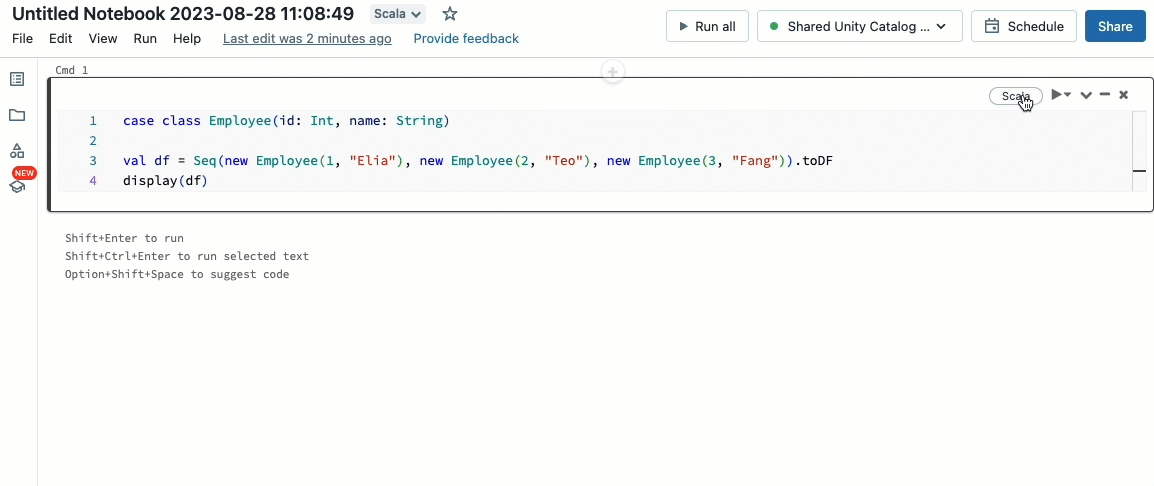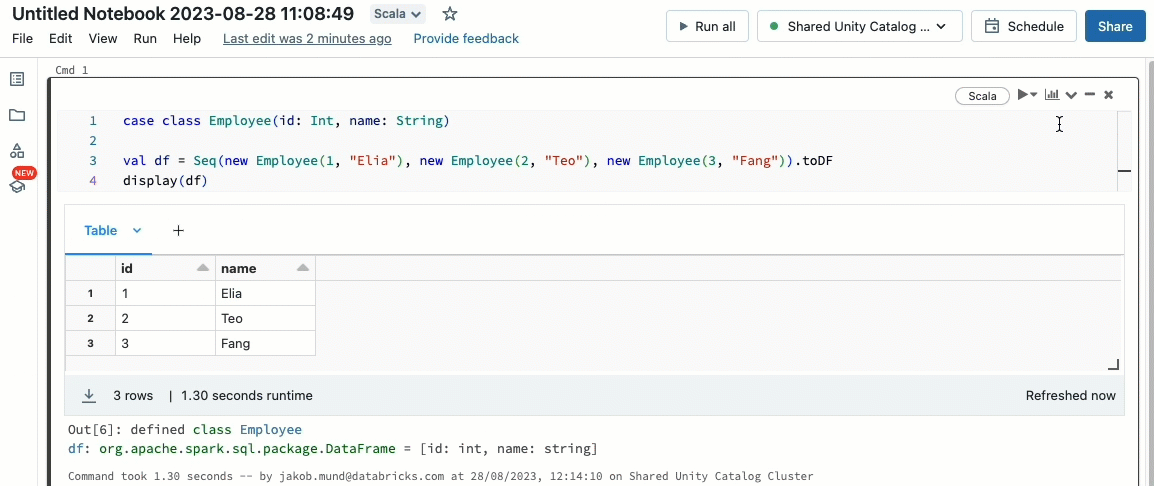
Quando crei un cluster per lavorare con dati governati da Unity Catalog, puoi scegliere tra due modalità di accesso:
- Cluster in modalità di accesso condiviso – o semplicemente cluster condivisi – sono le opzioni di calcolo raccomandate per la maggior parte dei carichi di lavoro. I cluster condivisi consentono a qualsiasi numero di utenti di collegarsi ed eseguire contemporaneamente carichi di lavoro sulla stessa risorsa di calcolo, consentendo significativi risparmi sui costi, una gestione semplificata dei cluster e una governance olistica dei dati, incluso il controllo degli accessi granulare. Ciò si ottiene tramite l'isolamento dei carichi di lavoro utente di Unity Catalog che esegue qualsiasi codice utente SQL, Python e Scala in completo isolamento senza accesso a risorse di livello inferiore.
- Cluster in modalità di accesso singolo utente sono raccomandati per carichi di lavoro che richiedono accesso privilegiato alla macchina o utilizzano API RDD, ML distribuito, GPU, Databricks Container Service o R.
Mentre i cluster a singolo utente seguono l'architettura Spark tradizionale, in cui il codice utente viene eseguito su Spark con accesso privilegiato alla macchina sottostante, i cluster condivisi garantiscono l'isolamento del codice utente. La figura seguente illustra l'architettura e i primitivi di isolamento unici per i cluster condivisi: qualsiasi codice utente lato client (Python, Scala) viene eseguito in completo isolamento e le UDF in esecuzione sui driver Spark vengono eseguite in ambienti isolati. Con questa architettura, possiamo multiplexare in modo sicuro i carichi di lavoro sulle stesse risorse di calcolo e offrire contemporaneamente una soluzione collaborativa, efficiente in termini di costi e sicura.
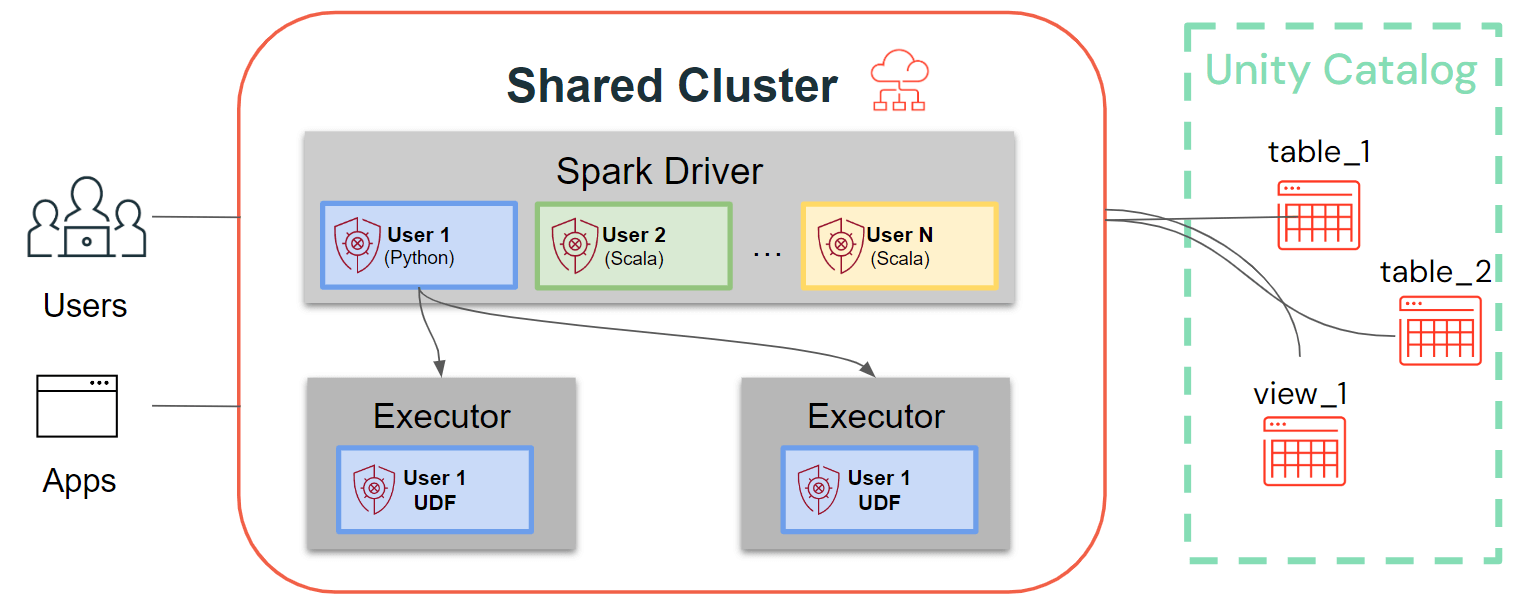
Ultimi miglioramenti per i cluster condivisi: librerie cluster, script di inizializzazione, UDF Python, Scala, ML e supporto per lo streaming
Configura il tuo cluster condiviso utilizzando librerie cluster e script di inizializzazione
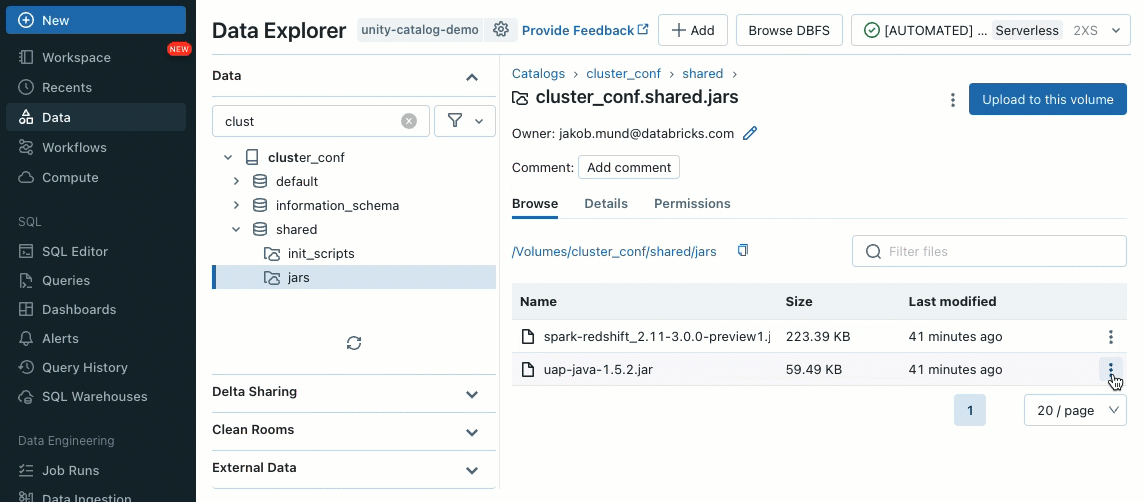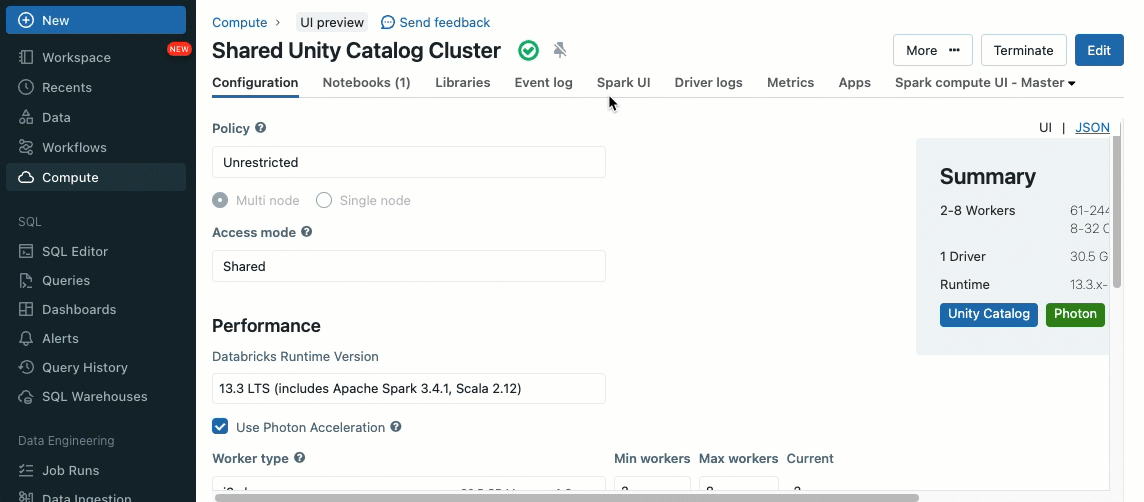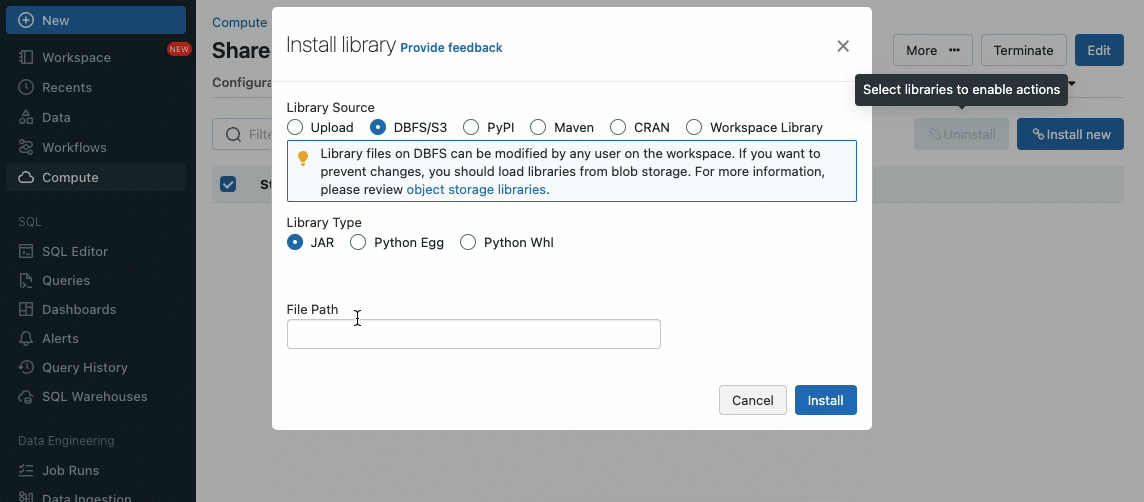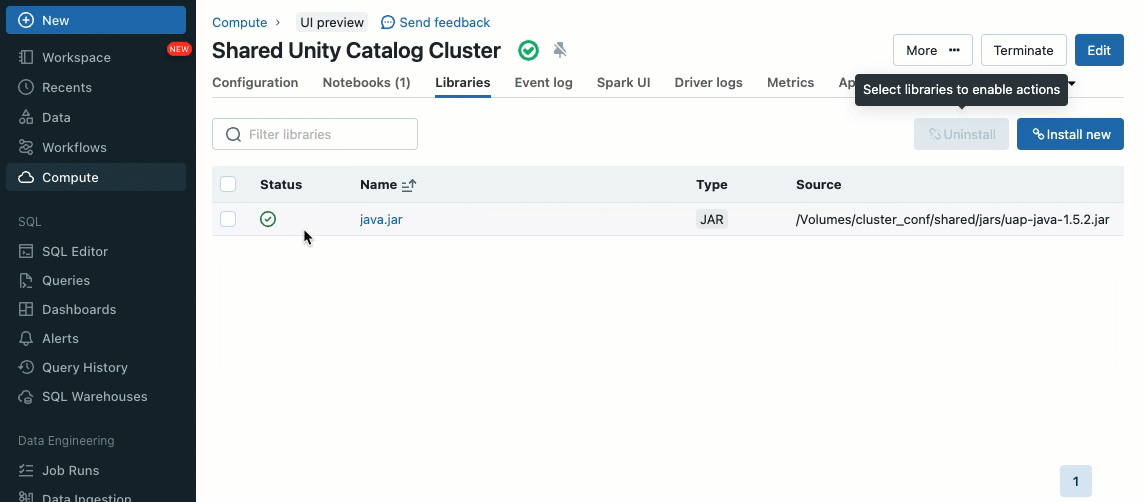
Le librerie cluster ti consentono di condividere e gestire facilmente le librerie per un cluster o anche tra più cluster, garantendo versioni coerenti e riducendo la necessità di installazioni ripetitive. Sia che tu debba incorporare framework di machine learning, connettori di database o altri componenti essenziali nei tuoi cluster, le librerie cluster forniscono una soluzione centralizzata e senza sforzo ora disponibile sui cluster condivisi.
Le librerie possono essere installate da volumi Unity Catalog (AWS, Azure, GCP), file Workspace (AWS, Azure, GCP), PyPI/Maven e posizioni di archiviazione cloud, utilizzando l'interfaccia utente o l'API del cluster esistente.
Utilizzando gli script di inizializzazione, in qualità di amministratore del cluster, puoi eseguire script personalizzati durante il processo di creazione del cluster per automatizzare attività come l'impostazione di meccanismi di autenticazione, la configurazione delle impostazioni di rete o l'inizializzazione delle origini dati.
Gli script di inizializzazione possono essere installati su cluster condivisi, sia direttamente durante la creazione del cluster sia per una flotta di cluster utilizzando le policy dei cluster (AWS, Azure, GCP). Per la massima flessibilità, puoi scegliere se utilizzare uno script di inizializzazione da volumi Unity Catalog (AWS, Azure, GCP) o archiviazione cloud.
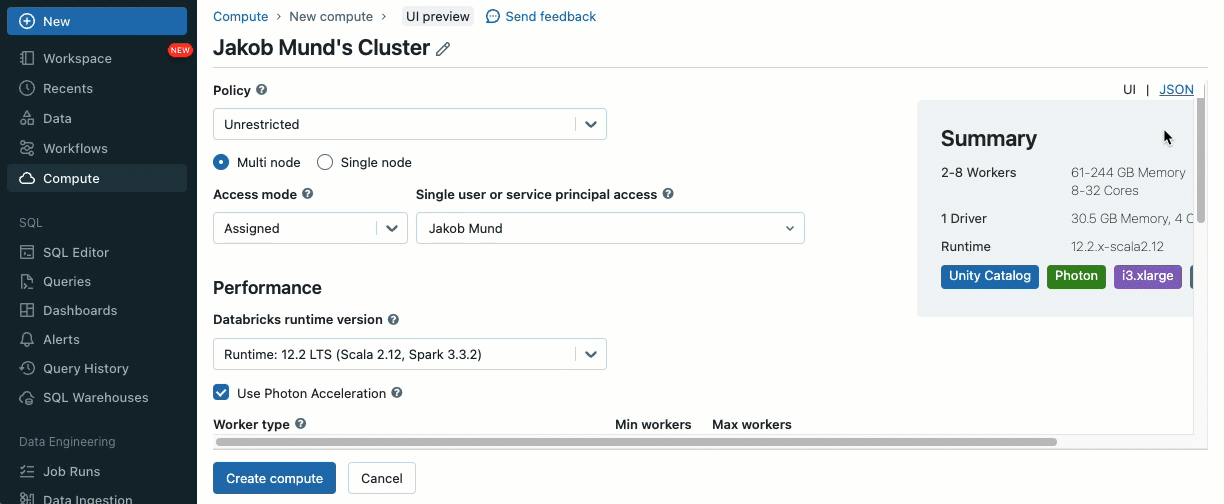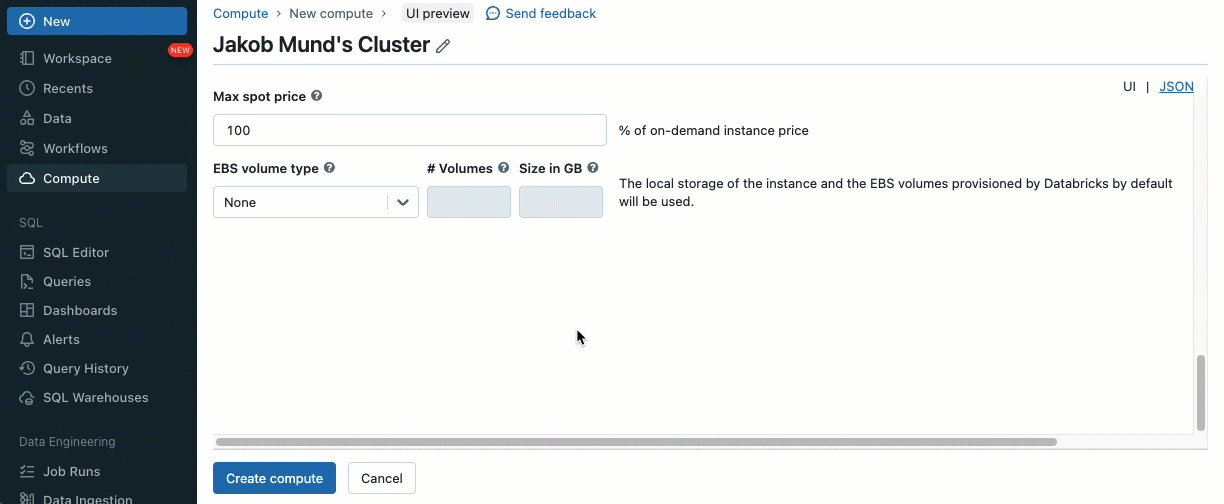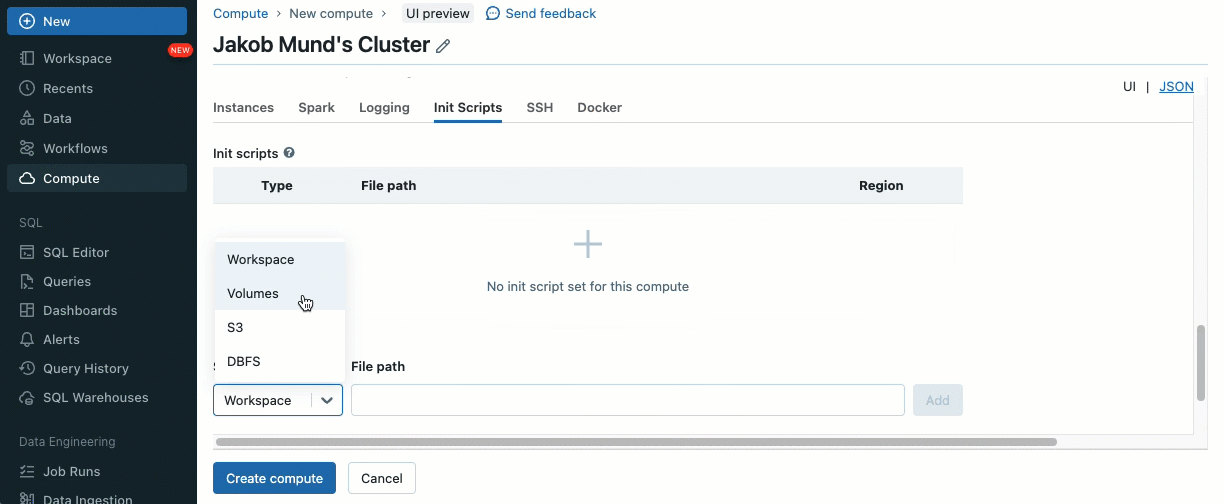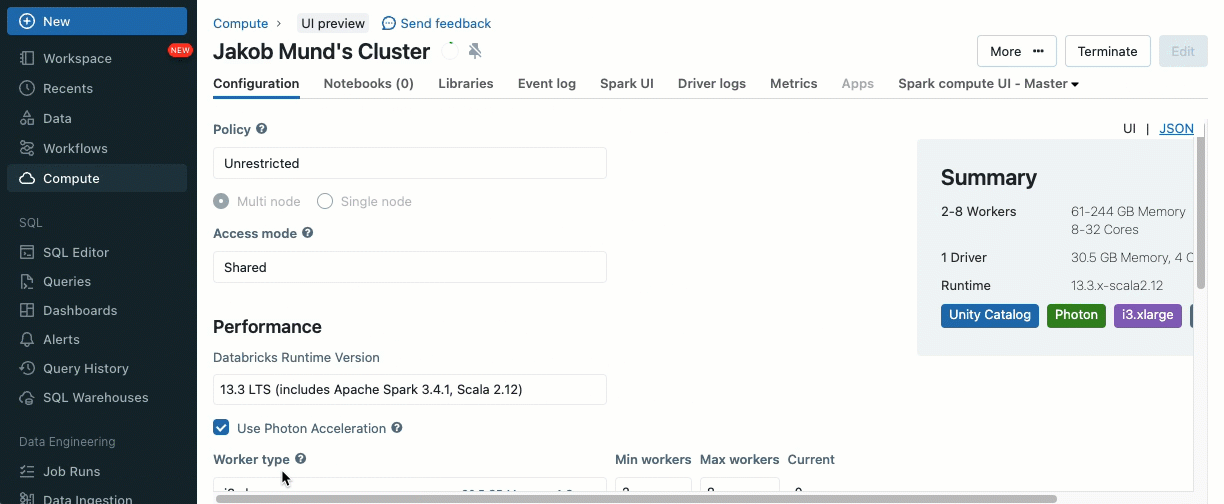
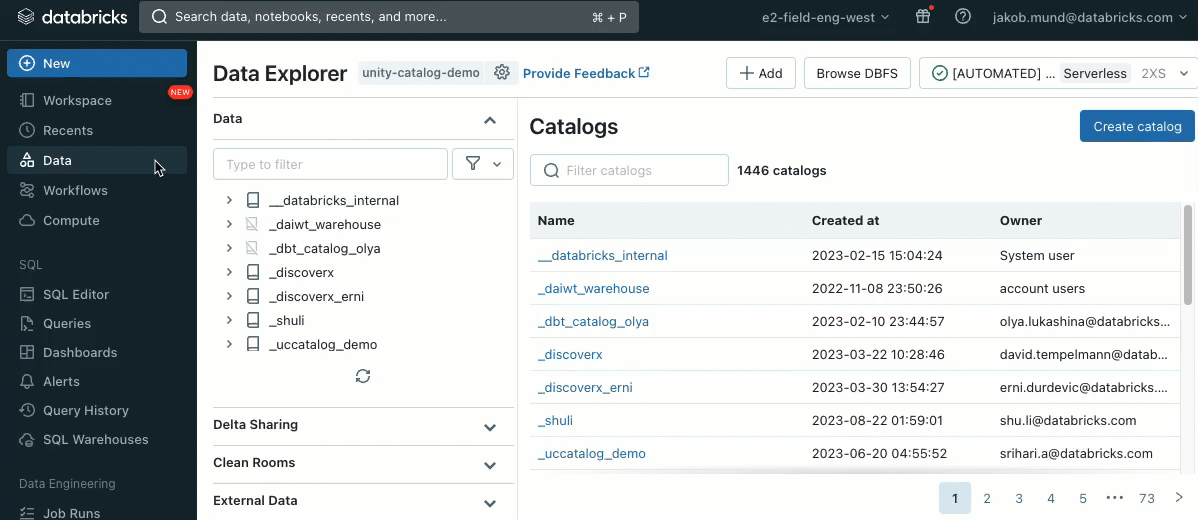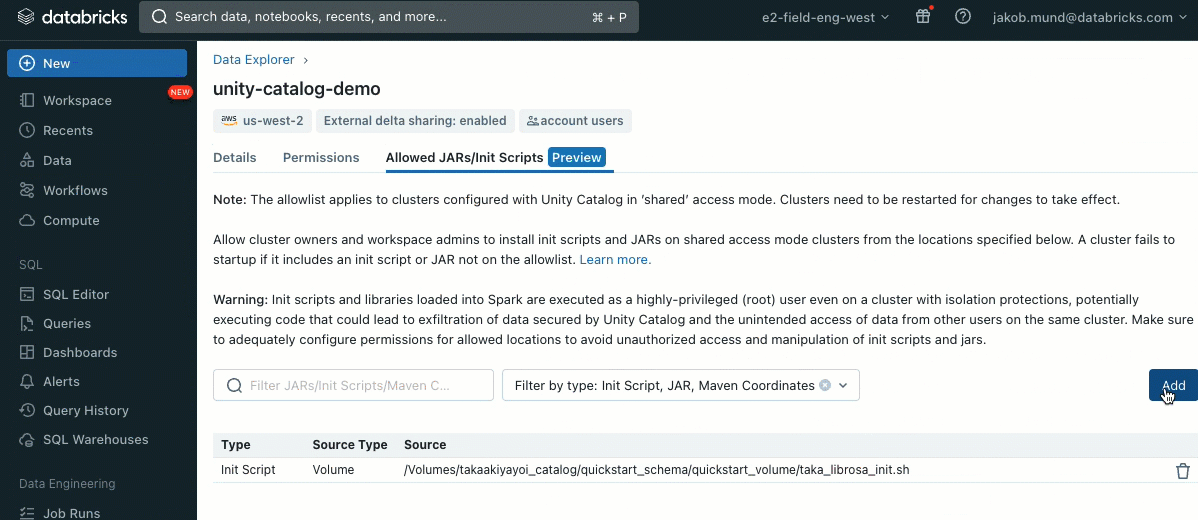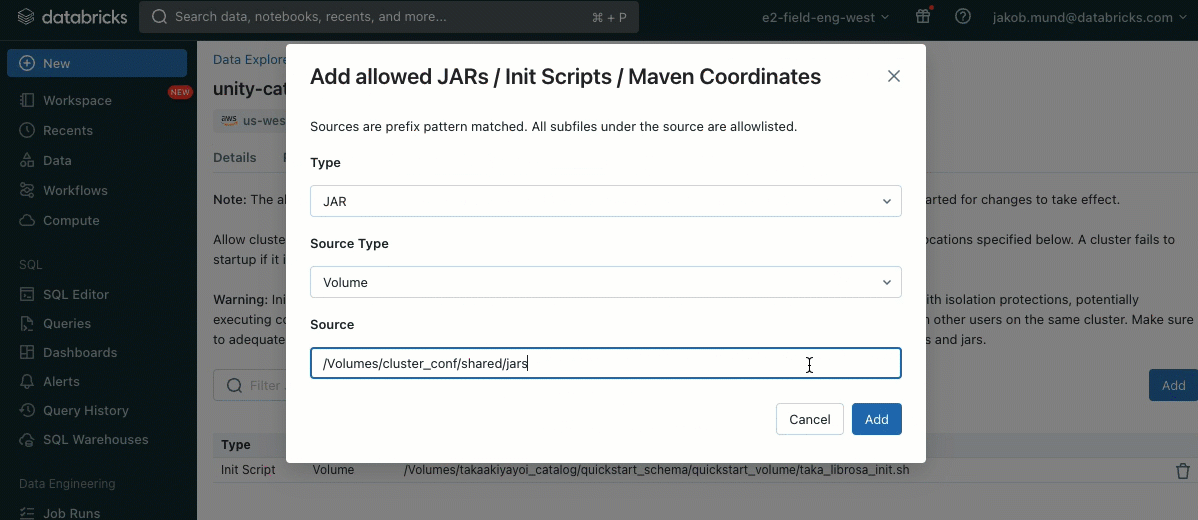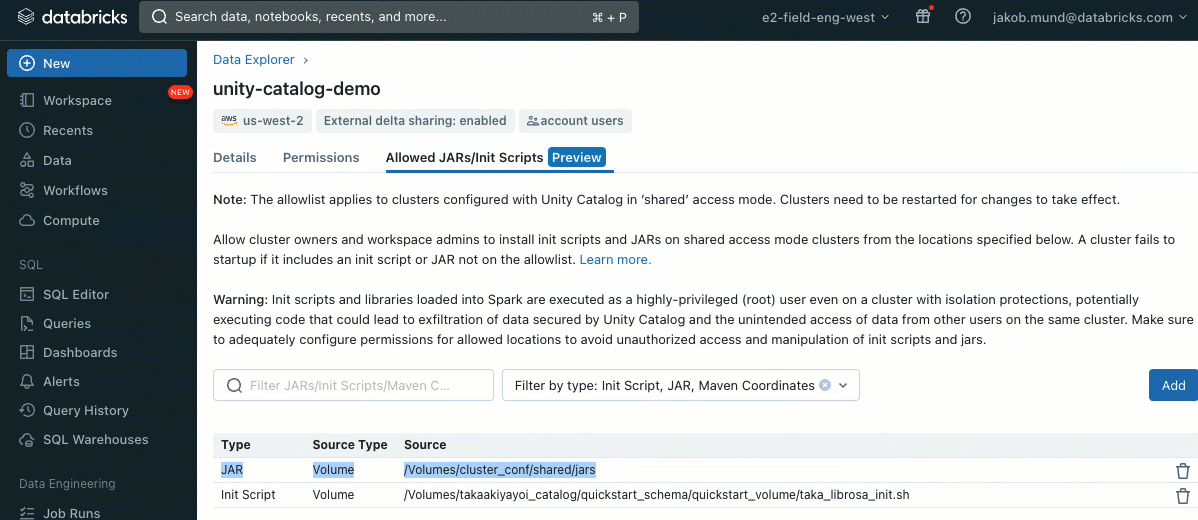
Come ulteriore livello di sicurezza, introduciamo una lista consentita (AWS, Azure, GCP) che governa l'installazione di librerie cluster (jar) e script di inizializzazione. Ciò consente agli amministratori di gestirli sui cluster condivisi. Per ogni metastore, l'amministratore del metastore può configurare i volumi e le posizioni di archiviazione cloud da cui possono essere installate librerie (jar) e script di inizializzazione, fornendo così un repository centralizzato di risorse attendibili e prevenendo installazioni non autorizzate. Ciò consente un controllo più granulare sulle configurazioni dei cluster e aiuta a mantenere la coerenza nei flussi di lavoro dei dati della tua organizzazione.
Porta i tuoi carichi di lavoro Scala
Scala è ora supportato sui cluster condivisi governati da Unity Catalog. Gli ingegneri dei dati possono sfruttare la flessibilità e le prestazioni di Scala per gestire ogni tipo di sfida legata ai big data, collaborativamente sullo stesso cluster e sfruttando il modello di governance di Unity Catalog.
Integrare Scala nel tuo flusso di lavoro Databricks esistente è un gioco da ragazzi. Seleziona semplicemente Databricks runtime 13.3 LTS o versioni successive quando crei un cluster condiviso, e sarai pronto a scrivere ed eseguire codice Scala insieme ad altri linguaggi supportati.
Sfrutta User-Defined Functions (UDF), Machine Learning e Structured Streaming
Non è tutto! Siamo lieti di svelare altri avanzamenti rivoluzionari per i cluster condivisi.
Supporto per User Defined Functions (UDF) Python e Pandas: Ora puoi sfruttare la potenza delle UDF Python e (scalari) Pandas anche sui cluster condivisi. Porta semplicemente i tuoi carichi di lavoro sui cluster condivisi senza problemi: non sono necessarie modifiche al codice. Isolando l'esecuzione del codice utente delle UDF sui driver Spark in un ambiente sandbox, i cluster condivisi forniscono un ulteriore livello di protezione per i tuoi dati, prevenendo accessi non autorizzati e potenziali violazioni.
Supporto per tutte le librerie ML popolari utilizzando il nodo driver Spark e MLflow: Che tu stia lavorando con Scikit-learn, XGBoost, prophet e altre librerie ML popolari, ora puoi creare, addestrare e distribuire modelli di machine learning direttamente sui cluster condivisi. Per installare librerie ML per tutti gli utenti, puoi utilizzare le nuove librerie cluster. Con il supporto integrato per MLflow (2.2.0 o versioni successive), la gestione del ciclo di vita del machine learning end-to-end non è mai stata così facile.
Structured Streaming è ora disponibile anche sui Cluster Condivisi governati da Unity Catalog. Questa aggiunta trasformativa abilita l'elaborazione e l'analisi dei dati in tempo reale, rivoluzionando il modo in cui i tuoi team di dati gestiscono i carichi di lavoro in streaming in modo collaborativo.
Inizia oggi, altre novità in arrivo
Scopri la potenza di Scala, delle librerie di cluster, delle UDF Python, dell'ML a nodo singolo e dello streaming su cluster condivisi oggi stesso, semplicemente utilizzando Databricks Runtime 13.3 LTS o versioni successive. Fai riferimento alle guide introduttive (AWS, Azure, GCP) per saperne di più e iniziare il tuo percorso verso l'eccellenza dei dati.
Nelle prossime settimane e mesi, continueremo a unificare l'architettura di calcolo di Unity Catalog e a semplificare ulteriormente il lavoro con Unity Catalog!
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.