Avanzamento di Apache Iceberg su Databricks: Iceberg v3 GA, Condivisione Aperta e Governance Unificata
Il catalogo più completo e aperto per Apache Iceberg
*Unity Catalog è ora il catalogo Apache Iceberg più completo, interoperabile e pronto per la produzione, con Managed Iceberg, Iceberg v3 e Foreign Iceberg che raggiungono la disponibilità generale (GA).
*Cinque funzionalità lo distinguono: API aperte, federazione del catalogo, controllo degli accessi cross-engine, condivisione sicura zero-copy e ottimizzazione basata sull'IA.
*Guardando al futuro, Iceberg v4 e Delta 5.0 convergeranno su una struttura di metadati unificata, ponendo fine al compromesso tra interoperabilità e prestazioni pronte per la produzione.
La prossima fase dell'open lakehouse sarà definita dal catalogo. I formati di tabella aperti hanno reso possibile a molti motori di lavorare sugli stessi dati, ma il catalogo determina se tali dati possono essere governati, ottimizzati e condivisi in modo coerente tra i sistemi. Poiché sempre più carichi di lavoro, incluse le applicazioni AI e agentive, dipendono dall'accesso governato ai dati in molti sistemi, le aziende necessitano di un catalogo Iceberg in grado di fornire interoperabilità, prestazioni elevate e governance pronta per l'impresa.
Ecco perché oggi annunciamo il set più completo di funzionalità Iceberg disponibili su qualsiasi catalogo lakehouse. In questo blog, discuteremo i nuovi miglioramenti per il supporto Iceberg in Unity Catalog e analizzeremo 5 aspetti che rendono Unity Catalog il catalogo Iceberg più interoperabile sul mercato oggi.
Novità: funzionalità Iceberg in sintesi
Abbiamo reso disponibili in General Availability e Preview un'ampia gamma di funzionalità Iceberg su Databricks e Unity Catalog per garantire che ogni motore, ogni catalogo e ogni team possano lavorare insieme senza problemi.
- Managed Iceberg (GA): Crea, leggi, scrivi, ottimizza, governa e condividi tabelle Iceberg direttamente in Unity Catalog, con Predictive Optimization e Liquid Clustering che eliminano il lavoro manuale necessario per mantenere le tabelle performanti.
- Iceberg v3 (GA): Supporto nativo per vettori di cancellazione, tracciamento delle righe e il nuovo tipo VARIANT su tabelle gestite, esterne e abilitate a UniForm.
- Foreign Iceberg (GA) & Credential Vending per Foreign Iceberg (GA): Registra, governa e interroga in modo sicuro tabelle Iceberg gestite in cataloghi esterni.
- Condivisione esterna con client Iceberg (GA): Condividi dati live con qualsiasi client compatibile con Iceberg REST utilizzando il protocollo aperto DeltaSharing.
- Condivisione esterna di tabelle Foreign Iceberg (Public Preview): Condividi tabelle Iceberg gestite al di fuori di Databricks nativamente in Databricks e nell'ecosistema Delta Sharing.
- Viste materializzate compatibili con Iceberg (Gated Public Preview): Crea viste materializzate ad alte prestazioni in Databricks ed esponile downstream come tabelle Iceberg native.
- Controllo degli accessi basato sugli attributi cross-engine (Beta): Applica criteri di governance granulari per motori Iceberg esterni tramite le API di scansione del catalogo REST di Iceberg.
- Nuovi connettori per la federazione di cataloghi (Preview): Espansione del supporto per la federazione di cataloghi di Unity Catalog oltre AWS Glue, Snowflake Horizon, Hive Metastore, e Salesforce Data Cloud per includere Google Cloud Lakehouse e Palantir, rendendo Unity Catalog il tuo pannello di controllo unico.
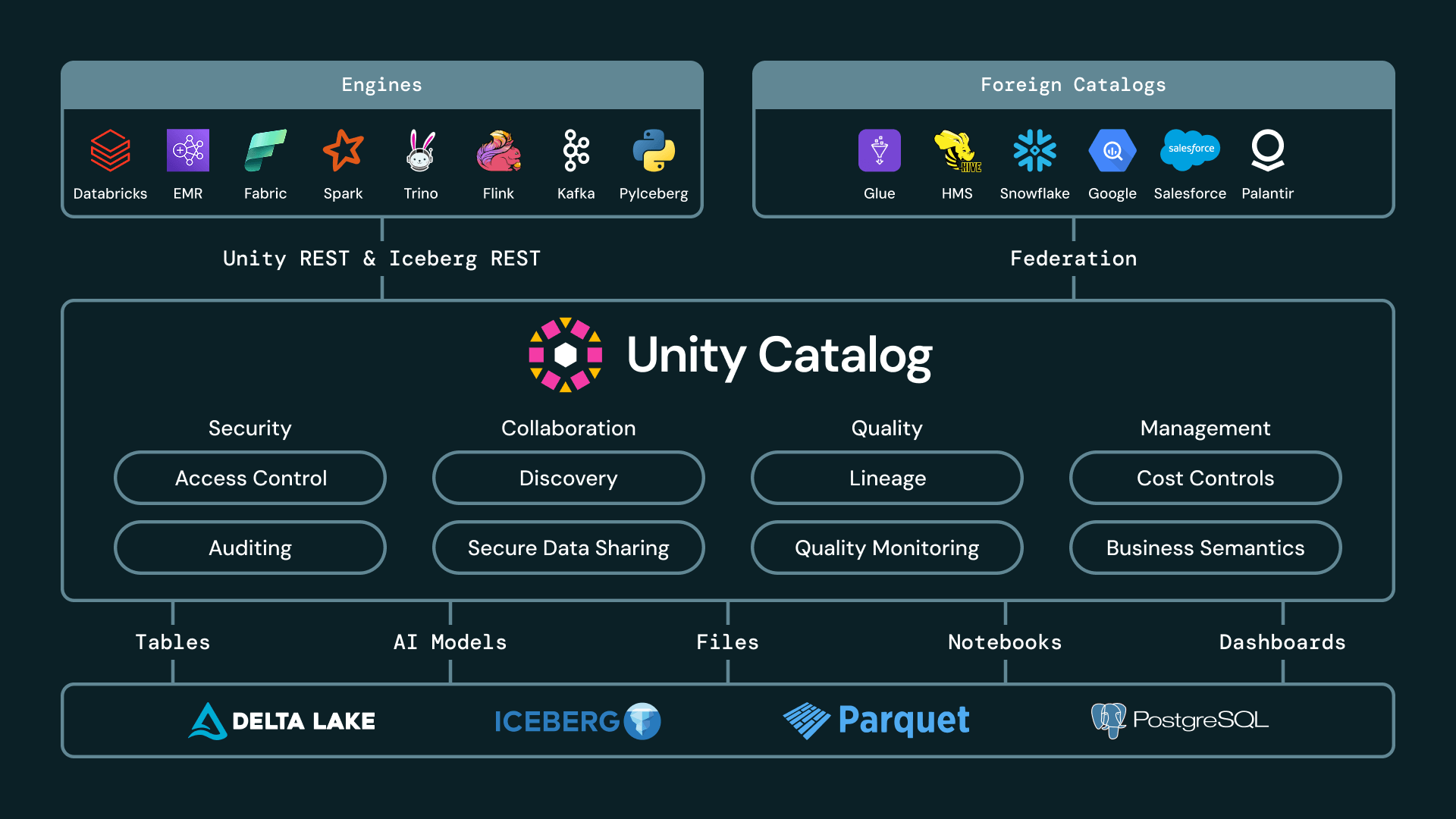
Cinque aspetti che rendono Unity Catalog il catalogo Iceberg più interoperabile
Per offrire un lakehouse completamente aperto, un catalogo Iceberg deve andare oltre il semplice tracciamento dei metadati. Deve offrirti flessibilità assoluta tra diversi motori, fornitori e modelli di governance. Riteniamo che la valutazione di un catalogo Iceberg aperto dipenda da quanto bene affronta cinque requisiti operativi fondamentali: fornire API aperte, federare attraverso ambienti esterni, applicare la governance cross-engine, abilitare la condivisione sicura e aperta, e innovazione continua su prestazioni e formato.
Unity Catalog è l'unico catalogo che soddisfa tutti e cinque i requisiti.

1. API aperte e credential vending
I clienti dovrebbero essere in grado di utilizzare il motore più adatto al carico di lavoro, che si tratti di Spark, Trino, Flink, Snowflake, DuckDB, pandas o un altro client compatibile con Iceberg, senza copiare i dati o concedere a ogni motore ampie autorizzazioni di archiviazione.
Con Managed Iceberg ora generalmente disponibile su Databricks, i clienti possono creare, leggere e scrivere tabelle Iceberg in Unity Catalog da qualsiasi motore utilizzando le API del catalogo REST Iceberg di UC.
Le API del catalogo REST Iceberg di UC ora si estendono anche oltre le tabelle Managed Iceberg. UC fornisce anche credenziali per tabelle Iceberg federate, offrendo accesso sicuro tramite API aperte anche a tabelle gestite in cataloghi esterni. E, attualmente in Gated Public Preview, i clienti possono creare viste materializzate in Databricks ed esporle come tabelle Iceberg ai consumatori downstream. Con una disponibilità più ampia nelle prossime settimane, i clienti potranno creare viste materializzate compatibili con Iceberg direttamente con CREATE MATERIALIZED VIEW my_mv USING ICEBERG.
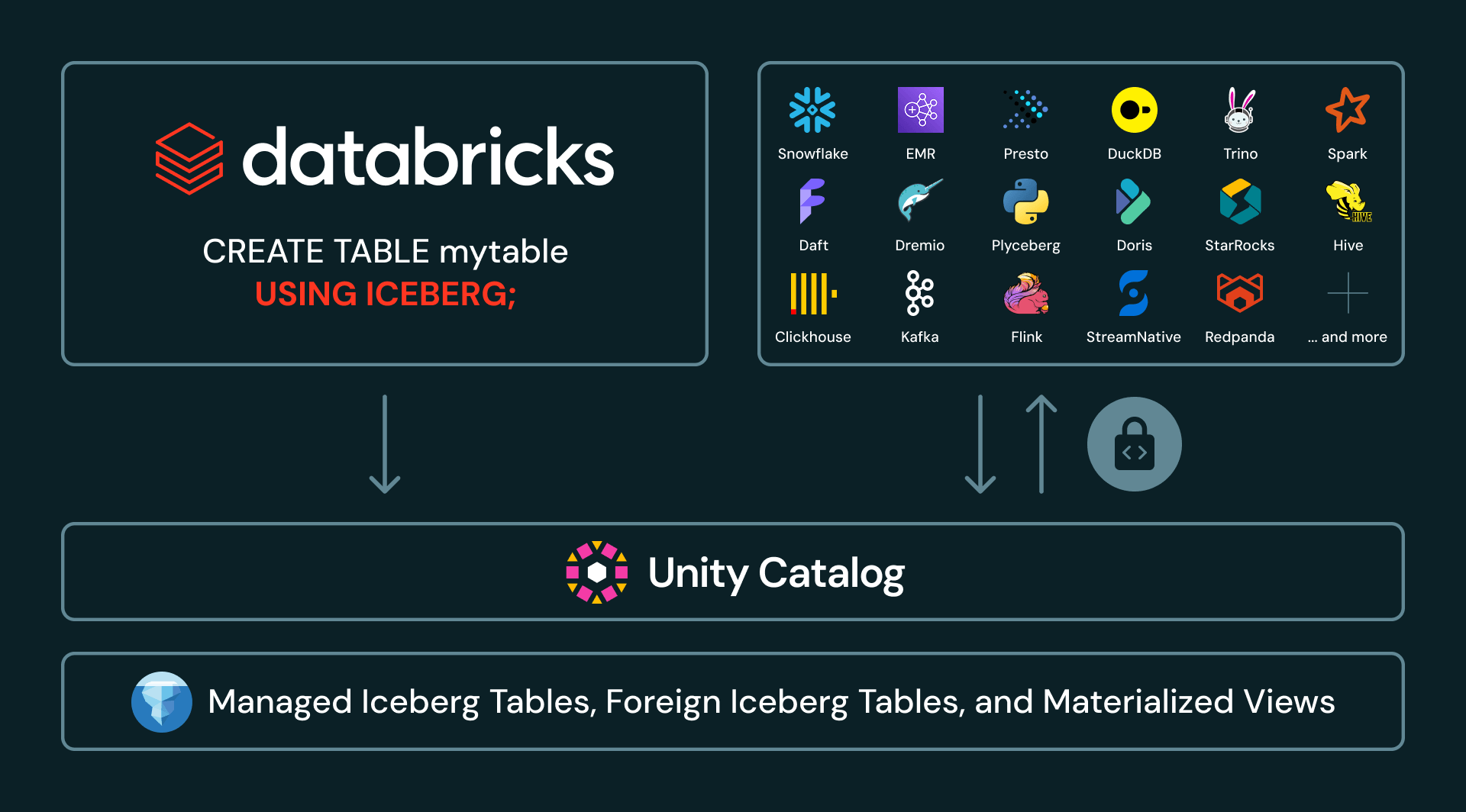
2. Federazione dei cataloghi: l'intero patrimonio Iceberg in un'unica vista
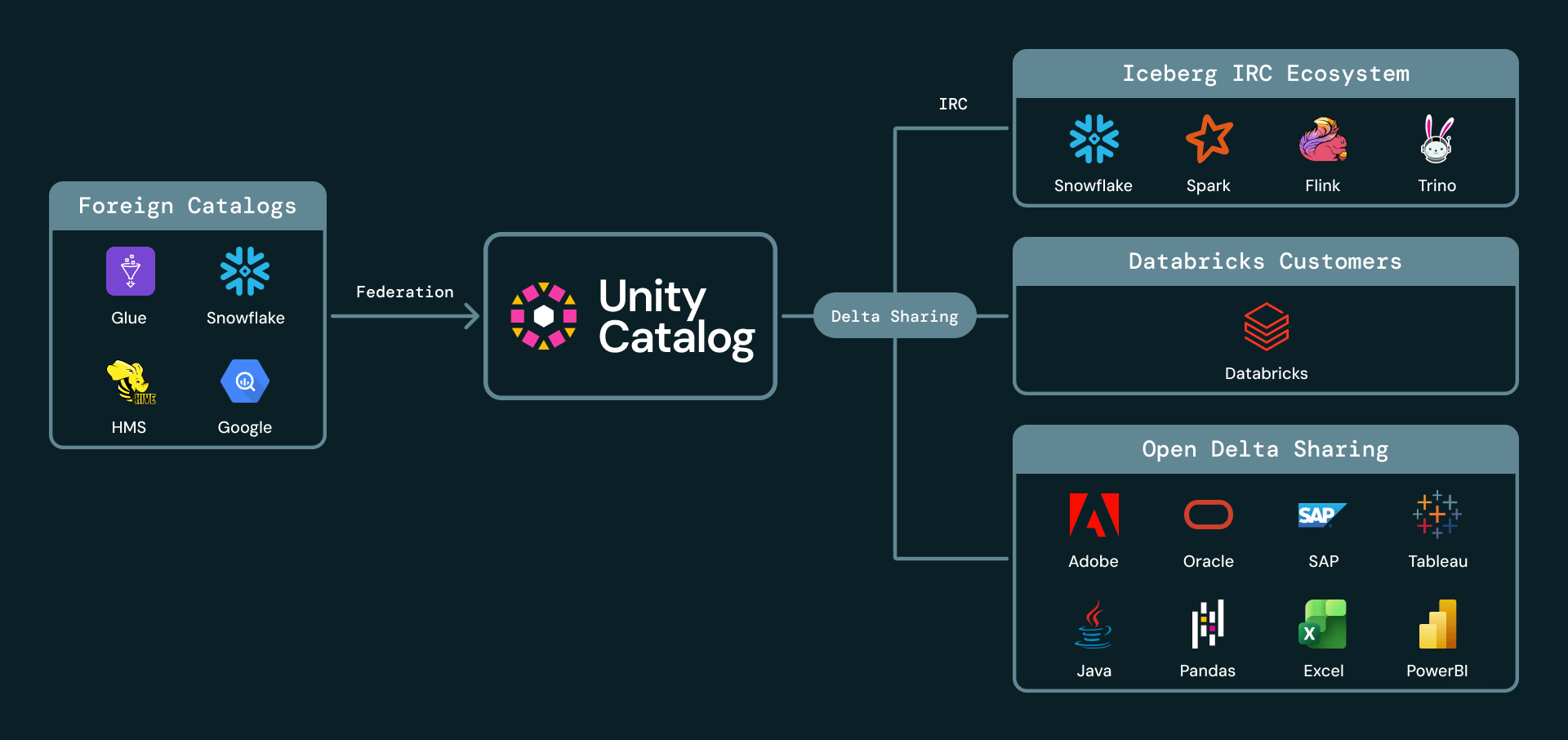
Molte grandi imprese hanno più cataloghi nel loro lakehouse. Ad esempio, potrebbero avere dati distribuiti tra Unity Catalog, AWS Glue, Snowflake Horizon e Hive Metastore. Con Foreign Iceberg ora generalmente disponibile, Unity Catalog può governare tabelle Iceberg gestite in altri cataloghi. I clienti possono scoprire, proteggere, interrogare e condividere tabelle Iceberg esterne tramite Databricks, lasciando i dati e il catalogo di origine al loro posto.
Unity Catalog ora supporta un set ampio e in crescita di integrazioni di cataloghi Iceberg, tra cui AWS Glue, Google Cloud Lakehouse Runtime Catalog, Snowflake Horizon, Palantir, Salesforce e Workday. Queste integrazioni consentono alle aziende di trattare Unity Catalog come il pannello di controllo unico per il loro patrimonio Iceberg, anche quando i dati vengono prodotti o gestiti altrove.
3. Controllo degli accessi basato sugli attributi cross-engine
Storicamente, i controlli a livello di riga e colonna venivano applicati all'interno di un singolo motore. Nell'open lakehouse, la stessa tabella può essere accessibile da molti motori. Ciò ha introdotto un problema difficile: la governance deve funzionare ovunque i dati siano accessibili.
Con i controlli di accesso basati sugli attributi (ABAC) cross-engine ora in Beta, Unity Catalog estende il controllo degli accessi basato sugli attributi ai client Iceberg utilizzando le API REST Catalog Scan di Iceberg.
Come funziona: gli amministratori definiscono le policy una volta in UC, incluse maschere di colonna, filtri di riga e policy basate su tag. Quando un motore Iceberg esterno richiede l'accesso, UC valuta le policy applicabili durante la pianificazione della scansione lato server. UC restituisce quindi un piano di scansione filtrato in modo che il motore legga solo i dati autorizzati durante l'elaborazione della query.
Ciò porta una governance granulare ai motori Iceberg esterni utilizzando standard aperti. Qualsiasi motore, come Apache Spark o DuckDB, che implementa il client di pianificazione della scansione del catalogo REST Iceberg (aggiunto nella release Iceberg 1.11) può accedere ai dati con ABAC applicato. I clienti possono utilizzare il miglior motore per ogni carico di lavoro mantenendo un unico modello di governance in tutto il lakehouse.
Unity Catalog e Iceberg gestito ci offrono il meglio di entrambi i mondi: prestazioni native per le nostre pipeline AI e ML e interoperabilità aperta per ogni consumer downstream. Un percorso di scrittura, zero duplicazioni e un livello di governance che ogni motore rispetta, inclusi i prodotti guidati dall'IA che stiamo costruendo per il Data Cloud di Rippling.—Tae Lee, Staff Engineer, Data Platform presso Rippling
4. Condivisione sicura senza copia per collaborazioni esterne e cross-domain
La condivisione cross-domain spesso costringe i provider di dati a compromessi difficili: copiare i dati su un'altra piattaforma, creare complessi meccanismi di autenticazione esterni o richiedere a ogni destinatario di utilizzare lo stesso ecosistema di fornitori. Databricks è stato pioniere nella condivisione sicura di dati aperti con Delta Sharing, il protocollo open source più diffuso per la condivisione di dati e IA, che supporta sia la condivisione Databricks-to-Databricks che Databricks-to-Open.
Siamo entusiasti di annunciare che Iceberg è ora un cittadino di prima classe in Databricks Delta Sharing sia come formato di origine che come destinazione. Con la condivisione con i client Iceberg ora generalmente disponibile, i clienti Databricks possono condividere dati live esternamente con qualsiasi destinatario che supporti l'API REST Catalog di Iceberg. I destinatari possono interrogare i dati condivisi da client compatibili con Iceberg come Snowflake, Trino, Flink e Spark, senza ingestione manuale o copie. I provider continuano a gestire l'accesso, il controllo e la governance tramite Unity Catalog.
Annunciamo anche l'anteprima pubblica della condivisione di tabelle Iceberg esterne. I clienti possono condividere tabelle Iceberg gestite o catalogate al di fuori di Databricks ma registrate e governate in Unity Catalog. Ciò significa che UC può fungere da livello di condivisione per tabelle Iceberg gestite ed esterne, mantenendo i dati in loco e la governance centralizzata.
5. Innovazione di prestazioni e formato: tabelle aperte più veloci senza ottimizzazione manuale
L'interoperabilità aperta funziona solo se le tabelle rimangono performanti su scala di produzione. Unity Catalog è l'unico catalogo che utilizza l'IA per ottimizzare le tue tabelle per query più veloci e un minor overhead operativo. Predictive Optimization determina quali tabelle necessitano di manutenzione, quali ottimizzazioni eseguire e con quale frequenza eseguirle, e adatta il layout dei dati della tua tabella in base ai pattern di carico di lavoro. Ciò riduce il lavoro operativo necessario per mantenere le tabelle Iceberg veloci ed economiche al variare dell'utilizzo, e queste ottimizzazioni vanno a beneficio di tutti i motori, ad esempio le tecniche di ottimizzazione del layout dei dati migliorano lo skipping dei dati per le query eseguite al di fuori di Databricks, come in Apache Spark. Stiamo costantemente innovando l'esperienza del cliente e siamo l'unico catalogo in grado di selezionare in modo intelligente le chiavi di clustering per prestazioni ottimali o aggiornare automaticamente le tabelle aperte con le ultime innovazioni in base ai pattern di accesso precedenti.
Databricks sta anche facendo progredire lo standard Iceberg stesso. Con Iceberg v3 ora generalmente disponibile su Databricks, i clienti ottengono il supporto per vettori di cancellazione, tracciamento delle righe e VARIANT su tabelle Iceberg gestite, tabelle Iceberg esterne e tabelle gestite con UniForm abilitato. Queste funzionalità colmano importanti lacune tra prestazioni e interoperabilità: i vettori di cancellazione accelerano aggiornamenti, merge ed eliminazioni; il tracciamento delle righe supporta un'elaborazione incrementale più efficiente; e VARIANT fornisce una rappresentazione standard per dati semi-strutturati. Queste funzionalità funzionano anche in modo impeccabile sia su tabelle Delta che Iceberg, abilitando l'interoperabilità senza riscrivere i dati.
Questi investimenti puntano allo stesso obiettivo: tabelle aperte che non costringono i clienti a scegliere tra l'interoperabilità dell'ecosistema e le capacità di prestazioni richieste per i carichi di lavoro di produzione.
Unity Catalog ci offre un unico posto per governare i dati tra team e sistemi, mentre Iceberg gestito offre le prestazioni di cui abbiamo bisogno alla nostra scala.—Kayvon Raphael, Head of Data Engineering, Magnite
Nel complesso, queste cinque funzionalità rendono Unity Catalog il miglior catalogo per Apache Iceberg. UC offre ai clienti accesso aperto alle tabelle Iceberg, una vista unificata tra i cataloghi, governance granulare tra i motori, condivisione sicura tra domini e ottimizzazione automatica per i carichi di lavoro di produzione.
La prossima frontiera: Iceberg v4
Con Iceberg v4, stiamo ripensando la struttura dei metadati di base da zero per migliori prestazioni, scalabilità e interoperabilità. Il nostro obiettivo è innalzare continuamente il livello di prestazioni e innovazione delle funzionalità, e farlo in un modo che avvicini Iceberg e Delta Lake. Questo è il motivo per cui stiamo anche proponendo che la prossima versione di Delta, Delta 5.0, adotti la struttura dei metadati ad albero adattivo.
Il risultato è semplice: tutte le tabelle gestite sono automaticamente ottimizzate in Unity Catalog, governate tramite API aperte e disponibili per qualsiasi motore. Mentre altre piattaforme ti costringono a scegliere tra interoperabilità e prestazioni avanzate e funzionalità. Con Unity Catalog, ottieni entrambi.
Scopri di più al Data + AI Summit
Unisciti a noi al Data + AI Summit per saperne di più su Apache Iceberg, Unity Catalog, condivisione aperta, federazione e la prossima fase di unificazione dei formati Delta e Iceberg.
- Evoluzione Co-Evoluzione dei Formati: Come Iceberg v4 e Delta 5.0 Condividono Metadati Unificati Approfondisci l'albero dei metadati adattivo di Iceberg v4 e come Delta 5.0 adotta la stessa struttura dei metadati di contenuto abilitando migliori prestazioni e interoperabilità in un ecosistema unificato.
- La Tua Guida ai Formati di Tabella Aperti: Delta, Iceberg, Best Practice e Cosa C'è Dopo Scopri le novità di Delta Lake e Apache Iceberg, incluse le best practice per lavorare oggi tra i formati e uno sguardo anticipato alla nostra roadmap futura per servire meglio i carichi di lavoro AI/ML.
- Il Percorso di Interoperabilità di Magnite su un Petabyte di Dati Iceberg Scopri come Magnite ha centralizzato l'accesso con Unity Catalog migliorando le prestazioni tra i motori, inclusi Apache Spark, DuckDB e Snowflake.
- Come Accedere in Sicurezza ai Dati con Lakehouse Federation su AWS Glue, Snowflake, BigQuery e Fabric Scopri come Unity Catalog può fungere da catalogo dei cataloghi per governare, proteggere e interrogare dati su sistemi esterni senza copiare i dati.
- Interoperabilità Apache Iceberg™: Supporto Aperto di Prima Classe in Databricks Delta Sharing
Scopri il supporto di prima classe per Iceberg in Delta Sharing, incluso come Foot Locker utilizza la condivisione aperta di Databricks per l'interoperabilità Iceberg cross-platform.
(Questo post sul blog è stato tradotto utilizzando strumenti basati sull'intelligenza artificiale) Post originale
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.