Cosa sono gli Hash Bucket?
Una tecnica di ingegneria delle funzionalità che mappa variabili categoriali ad alta cardinalità in vettori di dimensioni fisse utilizzando funzioni hash per un utilizzo efficiente della memoria ML
- Applica funzioni hash (come MurmurHash3) per convertire le caratteristiche categoriali in bucket di dimensione fissa, evitando l'esplosione di memoria della codifica one-hot per variabili ad alta cardinalità.
- Accetta collisioni hash in cui più valori vengono mappati sullo stesso bucket, sacrificando una certa accuratezza in cambio di una notevole efficienza di memoria e di calcolo nello streaming e nell'apprendimento su larga scala.
- Comunemente utilizzato nel filtraggio dello spam, nei sistemi di raccomandazione e nella previsione del CTR, dove gli spazi delle caratteristiche possono avere milioni di valori univoci che rendono la codifica tradizionale impraticabile.
In informatica, una tabella hash [mappa hash] è una struttura di dati che offre un accesso virtualmente diretto a oggetti sulla base di una chiave [una stringa o un numero intero unico]. Una tabella hash usa una funzione hash per calcolare un indice in una serie di bucket o slot, da cui può essere ricavato il valore desiderato. Le caratteristiche principali della chiave utilizzata sono le seguenti:
- la chiave utilizzata può essere il numero della propria tessera sanitaria, del proprio telefono o conto corrente ecc.;
- deve avere chiavi uniche;
- ogni chiave è associata (mappata) a un valore.
Il playbook sull'AI agentiva per l'enterprise

Gli hash bucket vengono utilizzati per distribuire dati per scopi di ordinamento o ricerca. Lo scopo è indebolire le liste collegate, in modo che la ricerca di un elemento specifico risulti accessibile in un tempo più breve. 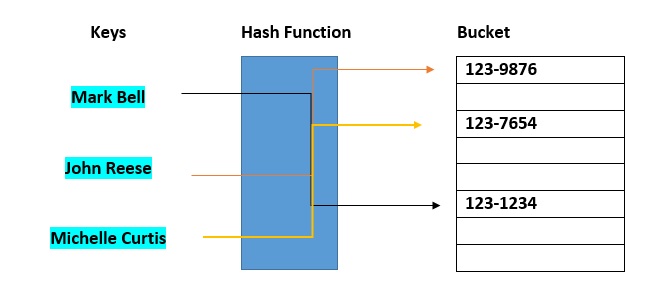 Una tabella hash che usa bucket è sostanzialmente una combinazione di un array e una lista collegata. Ogni elemento dell'array [la tabella hash] è l'intestazione di una lista collegata. Tutti gli elementi che fanno riferimento alla stessa posizione verranno memorizzati nella lista. La funzione hash assegna ogni record al primo slot all'interno di uno dei bucket. Qualora lo slot risulti occupato, gli slot dei bucket verranno passati in sequenza fino a trovare uno slot aperto. Nel caso in cui un bucket risulti completamente pieno, il record verrà memorizzato in un bucket di overflow con capacità infinita alla fine della tabella. Tutti i bucket condividono lo stesso bucket di overflow. Tuttavia, una buona implementazione utilizzerà una funzione hash che distribuisce i record uniformemente fra i bucket, in modo che nel bucket di overflow finisca il minor numero possibile di record.
Una tabella hash che usa bucket è sostanzialmente una combinazione di un array e una lista collegata. Ogni elemento dell'array [la tabella hash] è l'intestazione di una lista collegata. Tutti gli elementi che fanno riferimento alla stessa posizione verranno memorizzati nella lista. La funzione hash assegna ogni record al primo slot all'interno di uno dei bucket. Qualora lo slot risulti occupato, gli slot dei bucket verranno passati in sequenza fino a trovare uno slot aperto. Nel caso in cui un bucket risulti completamente pieno, il record verrà memorizzato in un bucket di overflow con capacità infinita alla fine della tabella. Tutti i bucket condividono lo stesso bucket di overflow. Tuttavia, una buona implementazione utilizzerà una funzione hash che distribuisce i record uniformemente fra i bucket, in modo che nel bucket di overflow finisca il minor numero possibile di record.
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.