Che cosa sono i Big Data Analytics?
Esaminare enormi e diversi set di dati provenienti da dispositivi IoT, social media ed eCommerce per scoprire modelli nascosti, correlazioni e informazioni fruibili
- Esamina dati strutturati, semi-strutturati e non strutturati da terabyte a zettabyte utilizzando tecniche avanzate come l'apprendimento automatico, l'elaborazione del linguaggio naturale e il deep learning.
- Sfrutta framework distribuiti come Hadoop, Spark e Hive per elaborare dati su intere reti, superando i tradizionali limiti ETL e la lenta elaborazione batch.
- Offre una riduzione dei costi tramite il cloud computing, consente il processo decisionale in tempo reale con analisi in memoria e aiuta a identificare nuovi prodotti, tendenze di mercato e preferenze dei clienti.

Che cos'è l'analisi dei Big Data?
Per analisi dei Big Data si intende il processo, spesso complesso, con cui si esaminano set di dati grandi e variegati (detti appunto Big Data), generati dalle sorgenti più svariate, come commercio elettronico, dispositivi mobili, social media e Internet of Things (IoT). Questo processo richiede di integrare diverse sorgenti di dati, trasformare dati non strutturati in dati strutturati e ricavare informazioni dettagliate dai dati utilizzando strumenti e tecniche specifiche che estendono l'elaborazione dei dati a un'intera rete.
La quantità di dati digitali è in rapida crescita e raddoppia circa ogni due anni. L'analisi dei Big Data offre un approccio diverso per la gestione e l'analisi di tutte queste sorgenti di dati. In linea generale valgono ancora i principi dell'analisi dei dati tradizionale, ma l'entità e la complessità dell'analisi dei Big Data ha richiesto lo sviluppo di nuove modalità per immagazzinare ed elaborare petabyte di dati strutturati e non.
Processo principale e metodi
La domanda di velocità maggiori e capacità di archiviazione più elevate ha creato un vuoto tecnologico che è stato presto colmato da approcci, tra cui:
- Metodi di archiviazione come data warehousee data lake
- Database non relazionali come NoSQL
- Tecnologie e framework di elaborazione e gestione dei dati, come Apache Hadoop open source, Spark e Hive.
L'analisi dei Big Data sfrutta tecniche avanzate per analizzare set di dati veramente grandi che comprendono dati strutturati, semi-strutturati e non strutturati, provenienti da varie sorgenti, e in quantità variabili da terabyte a zettabyte.
Analisi dei dati tradizionale vs. Analisi dei Big Data
Prima dell'invenzione di Hadoop, le tecnologie alla base dei moderni sistemi di storage e calcolo erano relativamente semplici e, di conseguenza, le aziende si dovevano limitare prevalentemente all'analisi di piccole quantità di dati. Anche questa forma di analitiche potrebbe essere difficile, soprattutto l'integrazione di nuove sorgenti di dati. Con le analitiche dei dati tradizionali, che si basa su database relazionali di dati strutturati, ogni byte di dati grezzi deve essere formattato in un modo specifico prima di poter essere inserito nel database per l'analisi. Questo processo spesso lungo, comunemente noto come Extract, Transform, Load (ETL), è necessario per ogni nuova sorgente di dati. Il problema principale di questo processo in tre fasi è che richiede tempi incredibilmente lunghi e molta manodopera, a volte occupando data scientist e data engineer per periodi fino a 18 mesi per implementazioni o modifiche.
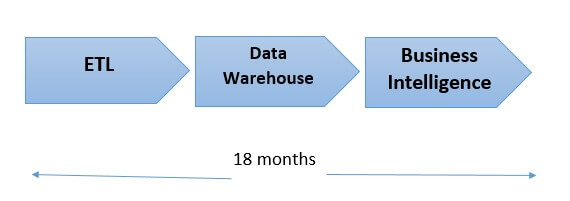
Una volta che i dati venivano inseriti nel database, nella maggior parte dei casi gli analisti faticavano comunque a effettuare interrogazioni e analisi. Poi sono arrivati Internet, l'e-commerce, i social media, i dispositivi mobili, l'automazione del marketing, l'Internet of Things (IoT) ecc., e le dimensioni, il volume e la complessità dei dati grezzi sono diventati ingestibili per chiunque, tranne per poche organizzazioni.
Il playbook sull'AI agentiva per l'enterprise

I tipi di dati più comuni nell'analisi dei Big Data
- Dati dal web. Dati provenienti dal web relativi ai comportamenti dei clienti, quali visite, visualizzazioni di pagine, ricerche, acquisti ecc.
- Dati testuali. I dati generati da sorgenti testuali come posta elettronica, notizie e articoli, feed di Facebook, documenti Word e altro ancora sono tra le tipologie di dati non strutturati più voluminose e diffuse.
- Dati temporali e di localizzazione o geospaziali: GPS e cellulari, così come le connessioni Wi-Fi, rendono le informazioni temporali e di localizzazione una fonte crescente di dati interessanti. Questi dati possono comprendere anche dettagli geografici relativi a strade, edifici, laghi, indirizzi, persone, luoghi di lavoro e itinerari di viaggio, generati da sistemi GIS.
- Dati in tempo reale. Le sorgenti di dati in tempo reale forniscono dati in streaming o basati su eventi.
- Dati provenienti dalla rete intelligente o da sensori. I sensori installati su autoveicoli, oleodotti, turbine eoliche e altro ancora raccolgono spesso dati con una frequenza molto elevata.
- Dati dei social network: Il testo non strutturato (commenti, 'Mi piace', ecc.) proveniente da siti di social network come Facebook, LinkedIn, Instagram, ecc. è in crescita. È possibile persino analizzare i link per conoscere tutta la "rete sociale" di un determinato utente.
- Dati collegati: i dati di questo tipo vengono raccolti utilizzando tecnologie web standard come HTTP, RDF, SPARQL e indirizzi URL.
- Dati di rete. Sono i dati relativi a grandi social network come Facebook e Twitter, o reti tecnologiche come Internet, le reti telefoniche e le reti di trasporti.
L'analisi dei Big Data consente alle organizzazioni di sfruttare i loro dati e tecniche e metodologie avanzate di data science, come l'elaborazione del linguaggio naturale (NPL), il deep learning e il machine learning, scoprendo schemi nascosti, correlazioni ignote, tendenze di mercato e preferenze dei clienti, per individuare nuove opportunità e prendere decisioni più informate.
I vantaggi dell'analisi dei Big Data comprendono:
- Riduzione dei costi. Tecnologie di cloud computing e storage, come Amazon Web Services (AWS) e Microsoft Azure, così come Apache Hadoop, Spark e Hive, possono aiutare le aziende a diminuire i costi per lo stoccaggio e l'elaborazione di set di dati voluminosi.
- Processi decisionali migliorati. Grazie alla velocità di Spark e all'analisi in memoria, unite alla capacità di analizzare velocemente nuove sorgenti di dati, le imprese possono generare informazioni immediate e fruibili per prendere decisioni in tempo reale.
- Nuovi prodotti e servizi. Con l'ausilio di strumenti per l'analisi dei Big Data, le aziende possono analizzare le esigenze dei clienti in modo più preciso e fornire più facilmente ai clienti ciò che chiedono in termini di prodotti e servizi.
- Rilevamento di frodi. L'analisi dei Big Data viene utilizzata anche per prevenire le frodi, soprattutto nel settore dei servizi finanziari, ma va acquisendo crescente importanza in tutti i settori.
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.