Che cos'è l'architettura Lambda?
Architettura che combina l'elaborazione batch e stream con un livello batch per la precisione, un livello di velocità per risultati in tempo reale e un livello di servizio che unisce entrambi
- Il livello batch memorizza il dataset master in un formato immutabile di sola aggiunta, precalcola le viste batch tramite elaborazione in stile MapReduce, fornendo risultati accurati e completi ma con ore di latenza.
- Il livello di velocità elabora solo i flussi di dati recenti utilizzando sistemi a bassa latenza come Storm o Flink, creando viste in tempo reale che compensano il ritardo del livello batch con coerenza finale quando le viste batch vengono aggiornate.
- Il livello di servizio indicizza le viste batch e veloci, consentendo query ad hoc rapide che uniscono entrambe le prospettive, sebbene la complessità dell'architettura sia diminuita poiché i sistemi di streaming come Apache Spark forniscono funzionalità sia batch che in tempo reale.
Che cos'è l'architettura Lambda?
L'architettura Lambda è una modalità per l'elaborazione di grandi quantità di dati (o Big Data), che dà accesso a metodi di elaborazione in batch e in streaming con un approccio ibrido. L'architettura Lambda viene utilizzata per risolvere il problema del calcolo di funzioni arbitrarie. L'architettura Lambda è composta da tre livelli:
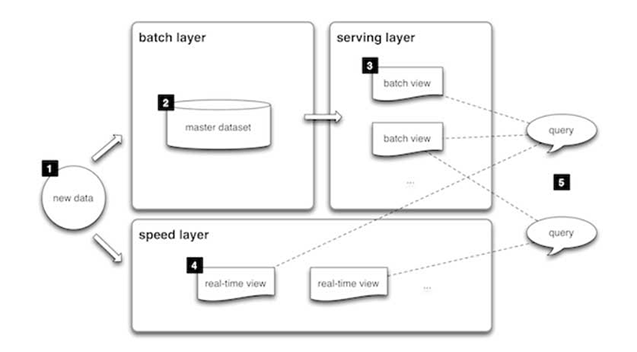
Livello Batch
Il sistema viene alimentato continuamente con nuovi dati. I dati arrivano contemporaneamente nel livello Batch e nel livello Speed. Il sistema esamina tutti i dati contemporaneamente e alla fine corregge i dati nel livello Stream. Al livello Batch si trovano molte funzioni ETL e un tradizionale data warehouse. Questo livello viene costruito utilizzando una programmazione predefinita, solitamente una o due volte al giorno. Il livello Batch svolge due funzioni molto importanti:
- gestione del set di dati principale (master);
- pre-elaborazione delle viste batch.
Livello Serving
I risultati generati dal livello Batch sotto forma di viste batch e gli output provenienti dal livello Speed sotto forma di viste in tempo quasi reale vengono inoltrati al livello Serving. Questo livello indicizza le viste batch affinché possano essere interrogate in modo mirato con bassa latenza.
Livello Speed (Stream)
Questo livello gestisce i dati che non sono già stati trasferiti nella vista batch a causa della latenza del livello batch. Inoltre, tratta solo dati recenti per fornire all'utente una vista completa dei dati creando viste in tempo reale.
Il playbook sull'AI agentiva per l'enterprise

Vantaggi delle architetture Lambda
I principali vantaggi delle architetture Lambda sono i seguenti:
- Nessuna gestione del server – Non è richiesta l'installazione, la manutenzione o l'amministrazione di alcun software.
- Scalabilità flessibile – L'applicazione può essere dimensionata automaticamente oppure regolandone la capacità.
- Alta disponibilità automatizzata – Le applicazioni serverless integrano già la disponibilità e la tolleranza ai guasti. Questo garantisce che tutte le richieste otterranno una risposta sul fatto che siano andate a buon fine o meno.
- Agilità operativa – Risposta in tempo reale a scenari di business/mercato in continua evoluzione
Problematiche delle architetture Lambda
- Complessità – Le architetture Lambda possono essere estremamente complesse. Gli amministratori devono mantenere solitamente due basi di codice separate per i livelli di batch e streaming, che complicano la fase di debugging.
Risorse correlate
Delta Lake: sorgente e destinazione (source and sink) unificate per batch e streaming
Risorse aggiuntive
Ricevi gli ultimi articoli nella tua casella di posta
Iscriviti al nostro blog e ricevi gli ultimi articoli direttamente nella tua casella di posta.