Data Warehousing Intelligente su Databricks - Clonato
Questa architettura di riferimento illustra come la Databricks Data Intelligence Platform abilita il moderno data warehousing e la BI combinando l'ingestione in streaming e batch, l'archiviazione governata, l'analisi SQL scalabile e l'AI integrata su...
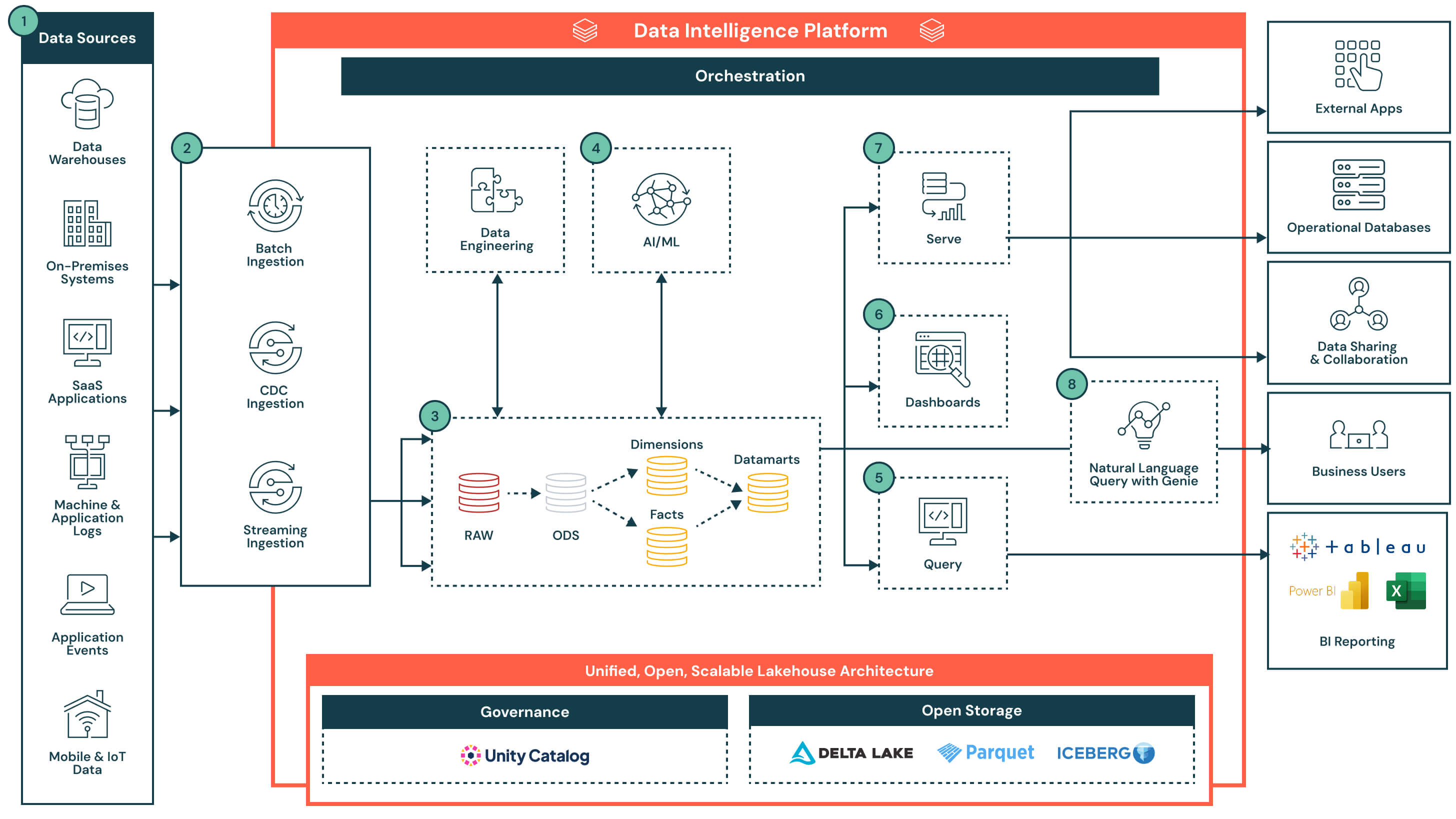
Riepilogo dell'architettura
L'architettura supporta la reportistica tradizionale, i dashboard in tempo reale, la modellazione predittiva e l'analisi self-service, il tutto rispettando gli standard aziendali di sicurezza, governance e prestazioni.
Questa soluzione dimostra come la Databricks Data Intelligence Platform, basata su Databricks Lakehouse, aiuti le organizzazioni a modernizzare la propria strategia di data warehousing, soddisfacendo al contempo le esigenze sia dei team di dati che degli stakeholder aziendali.
L'architettura inizia con un lakehouse aperto e governato, gestito da Unity Catalog. I dati vengono acquisiti da una serie di sistemi, inclusi database operativi, app SaaS, stream di eventi e file system, e atterrano in un livello di storage centrale. L'intelligenza dei dati della piattaforma alimenta tutto, dall'ETL e l'analisi SQL ai dashboard e ai casi d'uso dell'AI. Supportando un accesso flessibile tramite SQL, strumenti di BI e query in linguaggio naturale, la piattaforma accelera la distribuzione dei prodotti dati e rende le informazioni accessibili in tutta l'organizzazione.
Casi d'uso
Casi d'uso tecnici
- Acquisizione di dati strutturati, non strutturati, batch e in streaming da diverse fonti
- Creazione di robuste pipeline ETL dichiarative
- Modellazione di fatti, dimensioni e data mart utilizzando un'architettura a medaglione
- Esecuzione di query SQL ad alta concorrenza per reportistica e dashboard
- Integrazione degli output ML direttamente nel data warehouse per l'uso a valle
Casi d'uso aziendali
- Fornitura di dashboard in tempo reale su vendite, operazioni o metriche dei clienti
- Abilitazione dell'esplorazione ad hoc tramite interfacce in linguaggio naturale come Genie
- Supporto di casi d'uso predittivi come la previsione della domanda e la modellazione del churn
- Condivisione di prodotti dati governati tra dipartimenti o con partner
- Fornitura di insight rapidi e affidabili per i team finanziari, di marketing e di prodotto
Funzionalità chiave con Data Intelligence
Il componente di data intelligence di questa architettura rende la piattaforma più intelligente, più adattiva e più facile da usare per diverse persone e carichi di lavoro. Applica l'AI e la consapevolezza dei metadati in tutto il sistema per semplificare le esperienze e automatizzare il processo decisionale:
- Interfaccia in linguaggio naturale (Genie): Comprende il contesto aziendale e consente agli utenti di porre domande sui dati in linguaggio semplice
- Consapevolezza semantica: Riconosce le relazioni tra tabelle, colonne e modelli di utilizzo per suggerire join, filtri o calcoli
- Ottimizzazione predittiva: Ottimizza continuamente le prestazioni delle query e l'allocazione del calcolo in base ai carichi di lavoro storici
- Governance unificata: Tagga, classifica e traccia l'utilizzo degli asset di dati, rendendo la scoperta più intuitiva e sicura
- Capacità chiave: Una piattaforma auto-ottimizzante che si adatta ai tuoi dati e utenti
- Elemento distintivo: La data intelligence è integrata in acquisizione, query, governance e visualizzazione, non aggiunta a posteriori
Flusso di dati con funzionalità chiave e elementi distintivi
- Fonti di dati: I dati sono archiviati in un'ampia varietà di sistemi, incluse app aziendali (es. SAP, Salesforce), database, dispositivi IoT, log delle applicazioni e API esterne. Queste fonti possono produrre dati strutturati, semi-strutturati o non strutturati.
- Acquisizione dati: Acquisisce dati tramite processi batch, change data capture (CDC) o streaming. Queste pipeline alimentano l'architettura lakehouse quasi in tempo reale o a intervalli programmati, a seconda del sistema di origine e del caso d'uso.
- Elemento distintivo chiave: Acquisizione unificata per tutte le modalità — batch, streaming e CDC — senza la necessità di infrastrutture o pipeline separate
- Trasformazione dati, ETL, Pipeline dichiarative: Una volta acquisiti, i dati vengono trasformati tramite l'architettura a medaglione e progressivamente raffinati da dati grezzi a dati curati.
- Dalla zona Raw alla zona Bronze: Dati acquisiti da sistemi di origine esterni in cui le strutture in questo livello corrispondono alle strutture delle tabelle del sistema di origine “così come sono”, senza trasformazioni o aggiornamenti ai dati
- Dalla zona Bronze alla zona Silver: Standardizzare e pulire i dati in ingresso
- Dalla zona Silver alla zona Gold: Applicare la logica di business per creare modelli riutilizzabili
- Fatti e dimensioni → data mart: Aggregare e curare i dati per l'analisi a valle
- Elemento distintivo chiave: Pipeline dichiarative, di livello di produzione con lineage, osservabilità ed evoluzione dello schema integrati
- Dati curati per casi d'uso AI: I dati curati dai data mart possono essere utilizzati per addestrare o applicare modelli di machine learning. Questi modelli supportano casi d'uso come la previsione della domanda, il rilevamento delle anomalie e l'assegnazione di punteggi ai clienti.
- Gli output dei modelli sono archiviati insieme ai dati tradizionali del data warehouse per un facile accesso tramite SQL o dashboard
- I risultati possono essere aggiornati su base programmata o valutati in tempo reale, a seconda dei requisiti
- Elemento distintivo chiave: Carichi di lavoro di analisi e AI co-locati sulla stessa piattaforma — nessun movimento di dati necessario. Gli output dei modelli sono trattati come asset nativi, interrogabili e governati.
- Strumenti di reporting BI alimentati da query: Databricks Lakehouse supporta query ad alta concorrenza e bassa latenza tramite il calcolo serverless e si connette facilmente ai più diffusi strumenti BI.
- Editor di query e cronologia delle query integrati
- Le query restituiscono risultati governati e aggiornati da data mart o output di modelli arricchiti
- Fattore distintivo chiave: Databricks Lakehouse consente agli strumenti BI di interrogare i dati direttamente — senza replicazione — riducendo la complessità, evitando costi di licenza aggiuntivi e abbassando il TCO complessivo. Combinato con il calcolo serverless e l'ottimizzazione intelligente, offre prestazioni di livello warehouse con una sintonizzazione minima.
- Dashboard: Possono essere creati direttamente in Databricks o in strumenti BI esterni come Power BI o Tableau. Gli utenti possono descrivere gli elementi visivi in linguaggio naturale e Databricks Assistant genererà i grafici corrispondenti, che potranno poi essere perfezionati utilizzando un'interfaccia punta e clicca.
- Crea visualizzazioni utilizzando l'input in linguaggio naturale
- Modifica ed esplora le dashboard in modo interattivo con filtri e drill-down
- Pubblica e condividi in modo sicuro le dashboard in tutta l'organizzazione, anche con utenti esterni allo spazio di lavoro Databricks
- Fattore distintivo chiave: Offre un'esperienza low-code e assistita dall'IA per la creazione e l'esplorazione di dashboard su dati governati e in tempo reale
- Servizio di dati curati: Una volta raffinati, i dati possono essere serviti oltre le dashboard:
- Condivisi con applicazioni a valle o database operativi per il processo decisionale transazionale
- Utilizzati in notebook collaborativi per l'analisi
- Distribuiti tramite Delta Sharing a partner, team o consumatori esterni con governance unificata
- Query in linguaggio naturale (NLQ): Gli utenti aziendali possono accedere ai dati governati utilizzando il linguaggio naturale. Questa esperienza conversazionale, alimentata dall'IA generativa, consente ai team di andare oltre le dashboard statiche e ottenere insight in tempo reale e self-service. NLQ traduce l'intento dell'utente in SQL sfruttando la semantica e i metadati dell'organizzazione da Unity Catalog.
- Supporta domande ad hoc, interattive e in tempo reale che non sono pre-costruite nelle dashboard
- Si adatta in modo intelligente alla terminologia e al contesto aziendale in evoluzione nel tempo
- Sfrutta la governance dei dati e i controlli di accesso esistenti tramite Unity Catalog
- Fornisce auditabilità e tracciabilità delle query in linguaggio naturale per conformità e trasparenza
- Fattore distintivo chiave: Si adatta continuamente ai concetti aziendali in evoluzione, fornendo risposte accurate e contestualizzate senza richiedere competenze SQL
- Capacità della piattaforma: Governance, prestazioni, orchestrazione e archiviazione aperta: L'architettura è supportata da un insieme di capacità native della piattaforma che supportano sicurezza, ottimizzazione, automazione e interoperabilità lungo l'intero ciclo di vita dei dati. Capacità chiave:
- Governance: Unity Catalog fornisce controllo degli accessi centralizzato, lineage, auditing e classificazione dei dati su tutti i carichi di lavoro
- Prestazioni: Il motore Photon, la memorizzazione nella cache intelligente e l'ottimizzazione consapevole del carico di lavoro offrono query veloci senza sintonizzazione manuale
- Orchestrazione: L'orchestrazione integrata gestisce pipeline di dati, flussi di lavoro AI e processi pianificati su carichi di lavoro batch e streaming, con supporto nativo per la gestione delle dipendenze e la gestione degli errori
- Archiviazione aperta: I dati sono archiviati in formati aperti (Delta Lake, Parquet, Iceberg), consentendo l'interoperabilità tra strumenti, la portabilità tra piattaforme e la durabilità a lungo termine senza vendor lock-in
- Monitoraggio e auditabilità: Visibilità end-to-end sulle prestazioni delle query, l'esecuzione delle pipeline e l'accesso degli utenti per un migliore controllo e gestione dei costi
- Fattore distintivo chiave: I servizi a livello di piattaforma sono integrati — non sovrapposti — garantendo che governance, automazione e prestazioni siano coerenti su tutti i flussi di lavoro dei dati, i cloud e i team
Consigliato

Architettura di riferimento

Architettura di riferimento

Architettura di settore