Lakeflow と Agent Bricks を使用したデータエンジニアリングへの AI ファーストのアプローチ
Lakeflow と Agent Bricks が、ETL パイプラインのあらゆる段階に AI を活用した自動化をどのように実現するか
によって Joanna Zouhour による投稿
- LakeflowはAIネイティブのデータエンジニアリングプラットフォームを提供し、ユーザーはAgent Bricks AI機能を使用してETLでAIモデルを活用し、本番環境に導入できます。
- データエンジニアはLakeflow Jobsを使用して、大規模なAIモデルを簡単にオーケストレーションし、企業のコンテキスト内でETLパイプラインを自動化できます。
- あいまい一致からデータ抽出、要約まで、Lakeflow Jobsのユーザーはパイプラインのユースケースを拡大し、下流のアナリティクス、BI、機械学習のユースケースを強化できる新しい主要な知見を抽出できます。
データエンジニアは、1つの中核的な問題にますます注力しています。それは、AIを使用してETLを改善し、新たな複雑さを導入することなく、信頼性の高い本番運用レベルのパイプラインを構築することです。彼らが必要としてい�るのは、分断されたツールを追加したりコンテキストを奪ったりすることなく、ワークフローを合理化し、実際に成果を出すAIです。
Databricks Lakeflowは、組み込みのセキュアなAIを備えた統合データエンジニアリングプラットフォームで、データ処理全体を自動化し、より多くのインサイトを引き出し、より広範なビジネス課題をサポートします。AIが生成したパイプラインコードやAIワークロードのオーケストレーションなど、Lakeflowを活用するデータエンジニアは、手作業のグルーワークに何時間も費やすことなく、ビジネスに真のインパクトをもたらす戦略的で価値の高いパターンに集中できます。
このブログでは、AI モデルをデータパイプラインに実装することで、ビジネスインサイトを自動的に引き出し、モデルを製品化・スケールさせる方法について解説します。
大規模なデータから、より多くの知見を簡単に抽出
データチームは、契約書、請求書、文字起こし、レビューなど、非構造化入力の処理に追われています。それらの処理は、多くの場合、壊れやすいNLPモデル、厳格なルール、または手作業によるクリーンアップを駆使することを意味します。その結果、アウトプットの信頼性は低く、処理時間は長くなり、エンジニアはインパクトのある開発を行う代わりに反復的な解析に時間を費やし、貴重な知見はドキュメントに閉じ込められたままになります。
Databricks Lakeflowを使用すると、Databricks Agent Bricksの AI Functionsを通じて、AIを活用した変換を既存のワークフローにシームレスに組み込むことで、この問題を解決できます。これらの関数を使用すると、高品質なAIをETLプロセスに直接統合し、非構造化データと構造化データの両方の抽出、変換、分類を大規模に自動化できます。
Agent Bricks には、選択できるAI関数がいくつかあります。その中には、プロンプトを必要とせず、タスクに特化したものもあります。例:
ai_extract: 指定したラベルに基づいて、入力テキストから特定のエンティティを抽出します。例: 人物、場所、組織ai_classify: 提供されたラベルに従って入力テキストを分類します。例:「緊急」と「緊急でない」、またはトピックのカテゴリ。ai_translate: テキストを指定されたターゲット言語に翻訳します。
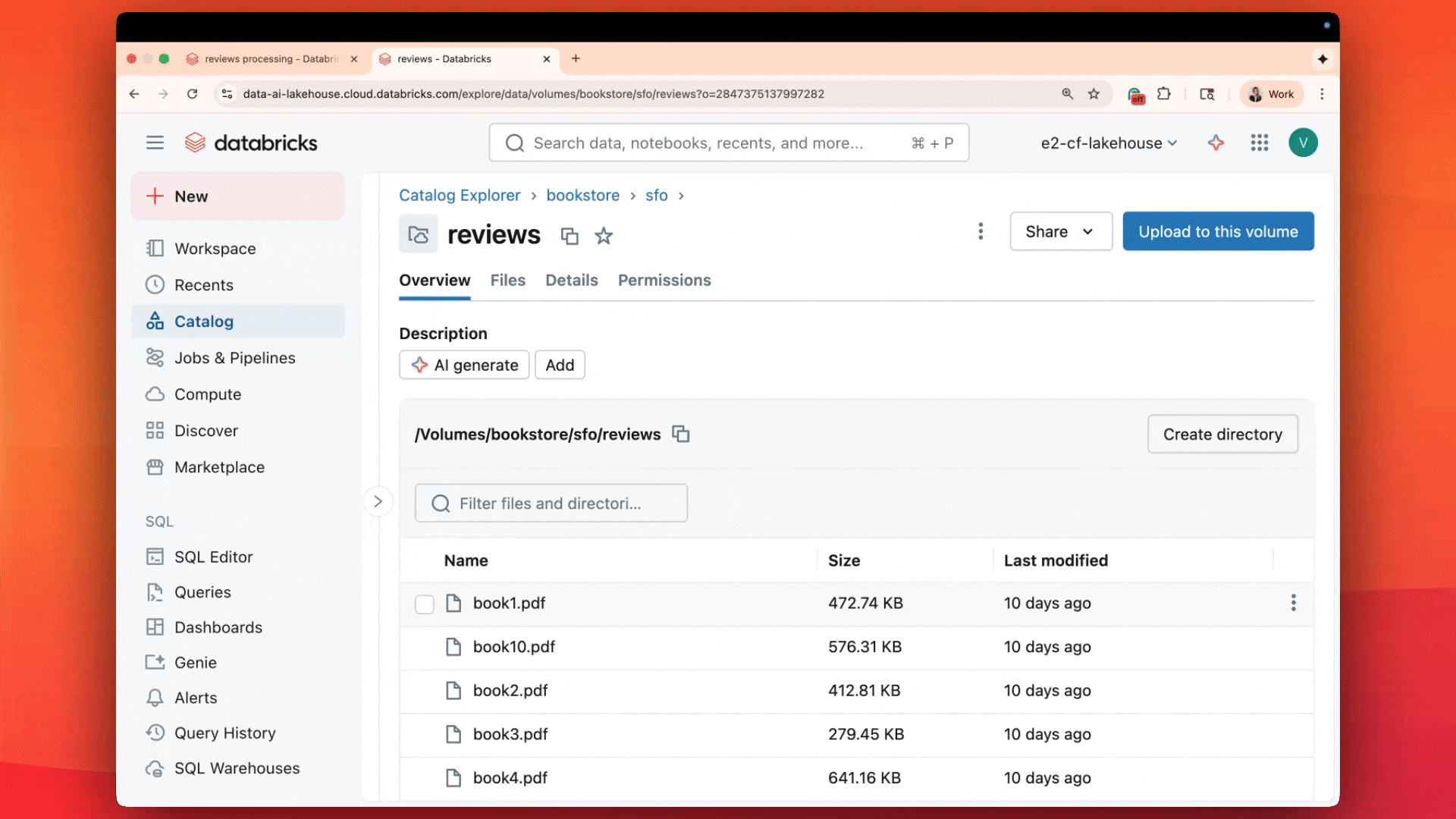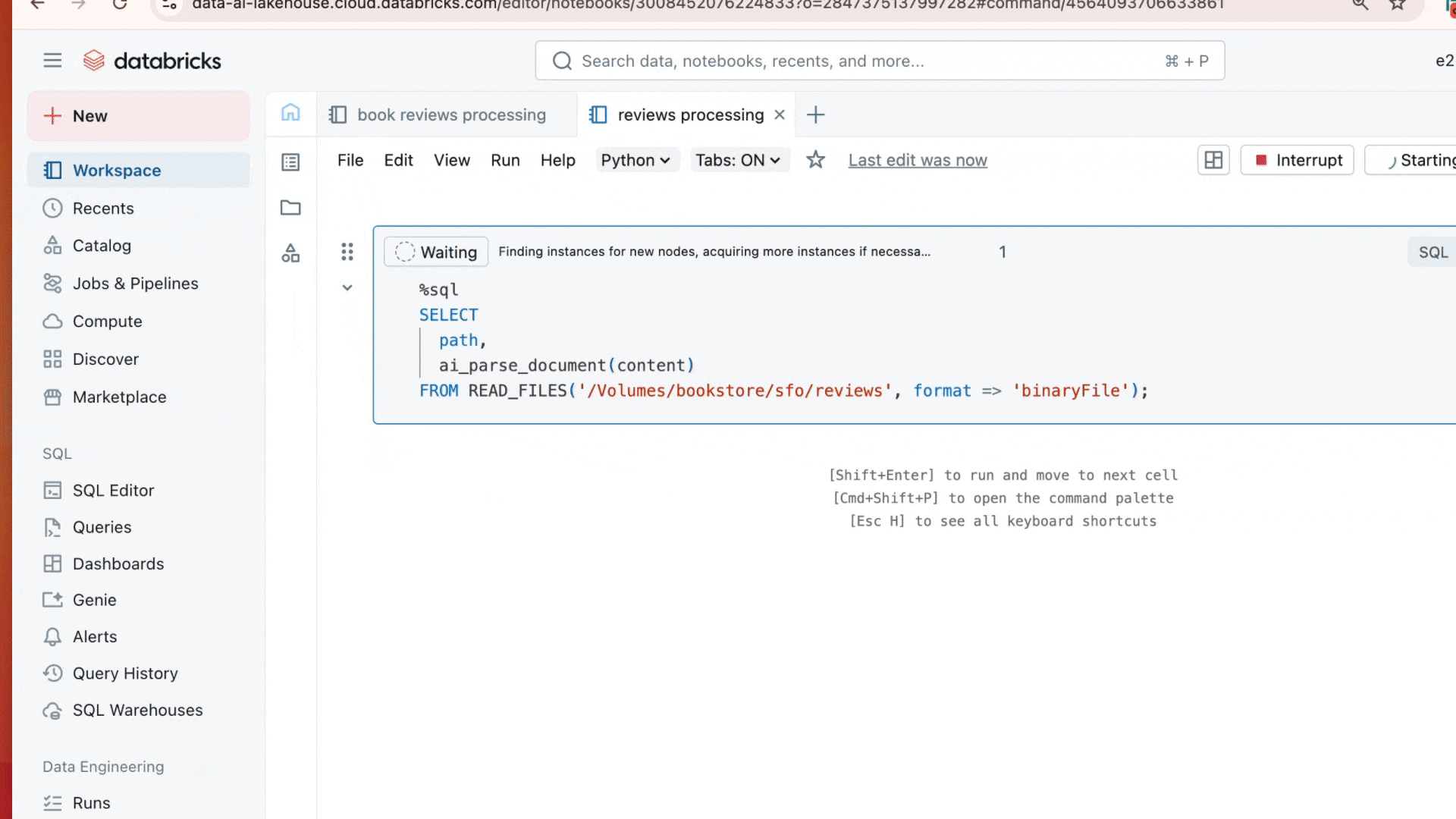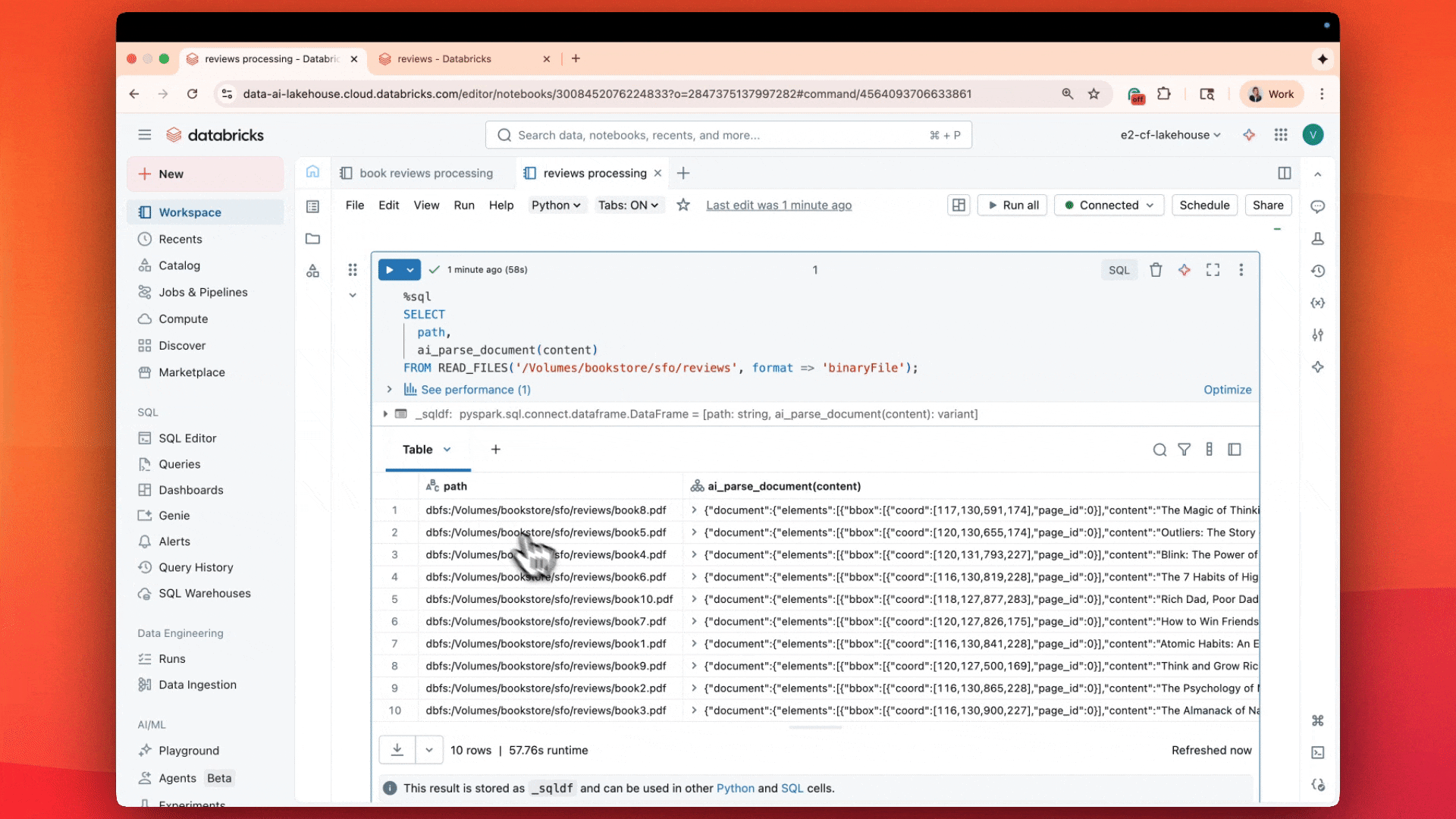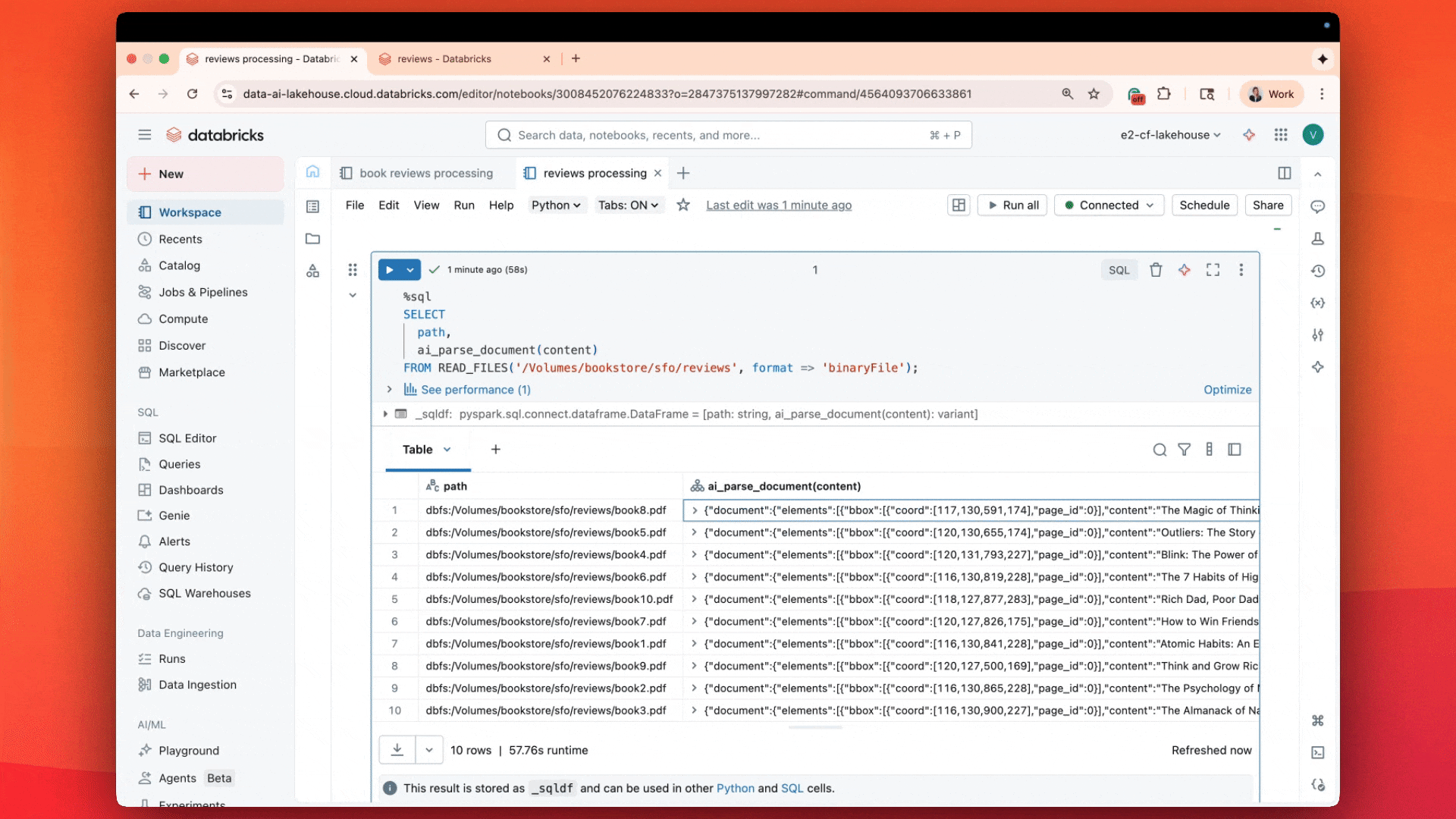
最近リリースされた AI 関数 ai_parse_documentには特に期待しています。この関数は、あらゆる非構造化データを必要な構造化形式に変換するために使用できます。�マルチモーダル基盤モデルを使用して、ai_parse_doc はテキストの解析、テーブルの抽出、図の推論、画像の AI 生成記述への変換を可能にします。この関数は、これまで分析がほぼ不可能だったデータの処理に新たな可能性を開きます。 詳細はこちら
また、当社の サーバーレスバッチ推論 プラットフォームを利用した、より汎用的な関数 ai_query() も提供しています。この関数を使用すると、任意のLLMを使って大規模なデータセットに対し、AIによる変換を一度に実行できます。
数百万行にわたるパフォーマンスを最大化するため、当社のサーバーレスバッチ推論エンジンは、コンピュートリソースを自動的にプロビジョニングおよびスケーリングし、ワークロードを並行して実行します。これにより、リクエストごとのオーバーヘッドが排除され、処理が大幅に高速化されます。ランタイムが数時間から数分に短縮されると同時に、大量の AI ワークロードのコスト効率が向上します。
Lakeflow を使用すると、Lakeflow Jobs を使用して、データエンジニアリングソ�リューション内で AI モデルを簡単に本番環境に導入し、ネイティブにオーケストレーションできます。AI 関数を使用すると、オーケストレーションの効率をさらに高め、次のような、より多くのユースケースを可能にします。
- 新規データの生成。AIを使用して顧客の知見に関する要約を作成してレポート作成を加速したり、将来の収益を予測したりします。
- データの構造化と整理。データを特定のビジネス上有意義なカテゴリに分類します。数百万件の多言語レビューにわたって感情分析を実行したり、自然言語プロンプトを使用して大規模に顧客セグメンテーションを自動化したりします。
- データ品質の向上。 ファジーマッチングとエンティティ解決を使用して、大規模な重複や不整合を修正します。
LakeflowとAgent Bricksを組み合わせることで、単一の統一されたガバナンスのあるデータプラットフォームでAIモデルを実行できます。これにより、AIとそれが抽出するインサイトが、適切なビジネスおよびエンタープライズのコンテキストを持つようになります。
AI 関数と Lakeflow の活用事例
例 1: 未加工の通話記録をビジネス知見に変換する
あなたの営業チームが、長くて構造化されていない通話の文字起こしを、明確で実用的な要約に変換する信頼性の高い方法を必要としていると想像してみてください。1日に何百もの通話があり、その多くが45分から60分続くため、手作業でのレビューは�すぐに不可能になります。
Databricksを使用すると、組み込みのAI機能を活用して、あらゆるトランスクリプトを簡単かつ迅速に分析し、主要な知見を抽出し、フォローアップの推奨事項を生成できます。
別の AI サービスを構築したり、カスタムエージェントを管理したりする代わりに、Lakeflow Jobs を使用してクエリーを記述し、オーケストレーターの一部としてランするだけです。これにより、AI モデルは統制された統合データエンジニアリングプラットフォームに直接実装されます。このプラットフォームでは、適切なビジネスおよびエンタープライズコンテキストを維持しながら、既存の販売パイプラインワークフローと完全に統合されたスケーラブルなバッチ処理を利用できます。
これが実際にどのように機能するのか、順を追って見ていきましょう。通話の文字起こしをパイプラインに取り込んだ後、AI関数を適用して非構造化テキストを使用可能なシグナルに変換できます。
ai_analyze_sentimentを使用して、通話全体の感情 (ポジティブ、ネガティブ、ニュートラル) を明らかにしますai_extractを使用して、顧客名、会社名、役職、電話番号など、通話から主要な情報を抽出しますai_classifyで、通話の種類 (緊急度、トピックなど) を分類します。
これにより、後続のアナリティクスと自動化に向けた、構造化された基盤が得られます。
次に、ai_query を使用して、選択した AI モデルで各通話を要約します (この例では、「databricks-meta-llama-3-3-70b-instruct」LLM を使用しています)。
このクエリーは、営業チームやアカウントチームが一目で確認できる、一貫性のある高品質な要約を生成します。
その後、同じワークフロー内でパーソナライズされたフォローアップを生成できます。
これらのメモは、CRMや営業ツールに大規模に直接プッシュできるため、チームは通話終了後すぐに取るべき正しい行動を正確に把握できます。また、これらのメモをBIチームと共有して、ギャップを発見し、全体的なカスタマーサービスエクスペリエンスの向上に役立てることもできます。
例 2: 保険金請求処理の効率化
より迅速で一貫性のある承認を必要とする保険会社向けに、請求処理パイプラインを構築しているとします。現在、請求はスキャンされた文書、写真、PDFなどの非構造化の添付ファイルとともにEメールで届くことが多く、大規模な取り込みと処理が困難になっています。
Agent BricksとLakeflowを使用すると、データエンジニアは ai_parse_document と ai_query を使用して、ETLパイプラインの一部として受信Eメールからデータを自動的に抽出し、正規化し、統合できます。これにより、手作業でのレビューを削減し�、意思決定を加速し、既存のデータワークフローにシームレスに統合する、信頼性の高いエンドツーエンドの自動化が可能になります。
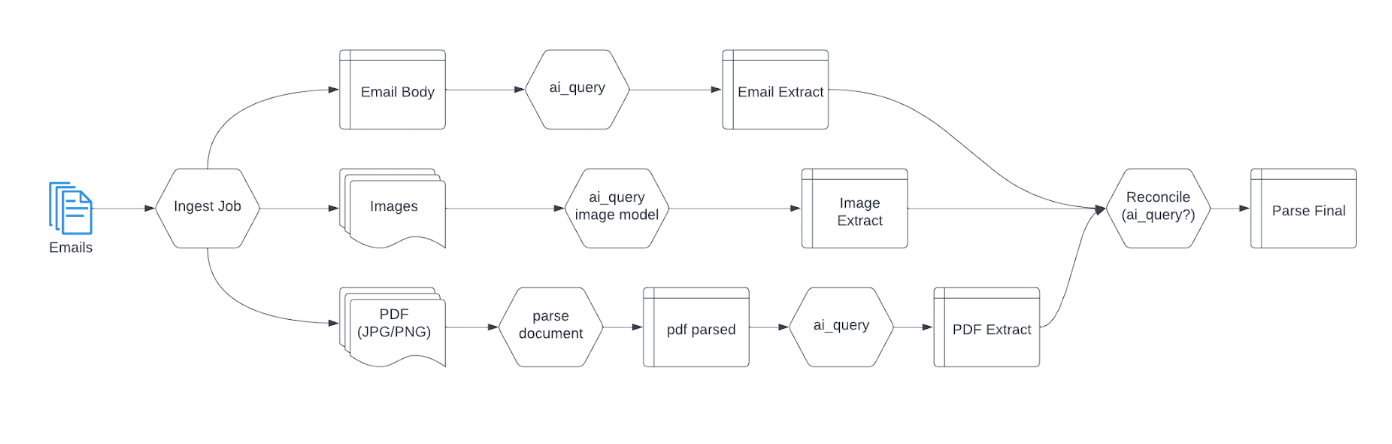
その仕組みは次のとおりです。
LakeflowとAgent Bricksを使用してEメールファイルをlakehouseに取り込み、次を使用して必要なデータを抽出します。
ai_queryを使用してEメールの本文を読み取り、主要な情報 (例: 名前、生年月日、住所、社会保障番号) を抽出しますai_queryを、入力される画像の種類を読み取れるモデルと組み合わせて使用します。この AI 関数は、添付された画像を説明するテキストを生成し、そのメタデータを抽出します。以下に、その関数の SQL クエリの例を示します。
- また
ai_parse_documentを使用して、Eメールに添付された PDF (jpg または png) を読み取ります
データが抽出されたら、ユースケースに応じて、再度 ai_query を使用してすべての情報を 1 つのファイルに集約できます。このファイルは、別のワークフローで再利用することも、下流のチーム (BI アナリスト、AI/機械学習 チームなど) に直接共有することも可能です。
以下は、Lakeflow Jobsでそのワークフローがどのように見えるかを示したDAGの例です。
Lakeflow と Agent Bricks を組み合わせることで、さらに多くのことが可能になります。こちらのビデオで、乱雑な販売データを AI 主導のマーケティングキャンペーンに変える方法をご覧ください。
DatabricksにおけるAIの実世界での応用
多くのDatabricksの顧客とデータエンジニアは、AIとLakeflowを使用して知見を解き放ち、生産性を向上させることで、価格設定、カスタマーサクセス、マーケティングといったさまざまなビジネス課題にうまく対処してきました。
ニューヨークを拠点とするフィンテック企業の Kard は、 Agent Bricks AI機能 を使用して、手動で一貫性のない従来の方法に代わる スケーラブルで正確な取引分類システムを強化しています 。 この最新のアプローチにより、Kardは数十億件の取引を効率的に処理し、パーソナライズされたリワードを提供し、ロイヤルティとビジネス価値を高める、より豊富な知見を提供できるようになります。
ラテンアメリカ最大級の銀行の1つである Banco Bradesco のデータエンジニアリングチームは、 長時間のコーディング、デバッグ、ドキュメント作成プロセスによる生産性のボトルネック��に直面していました 。 Databricks Assistant を導入することで、コーディング時間を50%削減し、技術ユーザーと非技術ユーザーの両方が自然言語を使用してコードを生成およびトラブルシューティングできるようになり、データアクセスを民主化し、コストを削減し、データドリブンな意思決定を加速させました。
Locala (グローバルなオムニチャネル広告プラットフォーム)は、 Lakeflow Jobsを使用して複雑なLLMトレーニングパイプラインをオーケストレーションしました 。 これは、以前のスケジューラであるAirflowでは処理できなかったものです。ETL、モデルのトレーニングと実験、コンピューティングの選択を合理化することで、 Lakeflow Jobsは複雑なワークフローを管理する運用上の負担を取り除き 、1人のデータサイエンティストが、アドテク企業の主要なセールス機能となったGenAIアシスタントを構築することを可能にしました。
Lakeflowを使用すると、AI機能をデータエンジニアリングプラットフォームに簡単に統合し、AIワークフローをオーケストレーションして、データプロセスをより効率的で、知見主導型で、アクセスしやすいものにすることができます。今後の展開にご期待ください!まもなく、Databricks Genieを使用して、データエンジニアリングプラットフォームを強化し、自然言語処理でパイプラインの作成とデバッグを行えるようになります。
- 利用を開始: Databricks 無料版
- Databricks AI関数 の製品ドキュメントをご覧ください
- さらに詳しく知る: Databricks Genie
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。