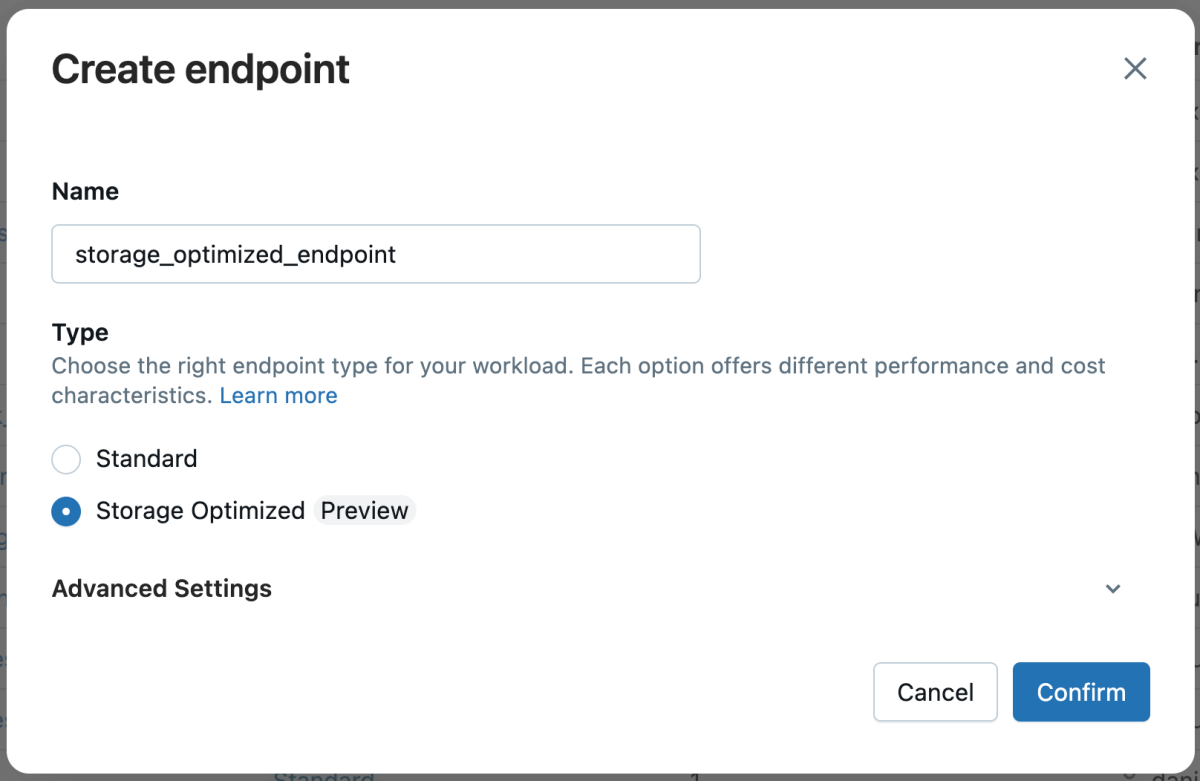
ベクター検索を加速する「ストレージ最適化エンドポイント」の発表!
数十億ベクタースケール、コストは7分の1
によって Adam Gurary 、 Dima Kotlyarov による投稿
- ストレージ最適化ベクトル検索の紹介:ビリオンベクトルスケール、最大7倍の低コスト、20倍の高速インデックス化、おなじみのSQLライクなフィルタリング。* AIのための非構造化データからさらなる価値を引き出す:ドキュメント、画像など��に対する高性能RAG、エンティティ解決、セマンティック検索システムを構築。* エンタープライズ対応で採用しやすい:Unity Catalogガバナンスによりサポートされ、AI Playgroundなどのツールと統合されており、迅速なRAGプロトタイピングとコスト管理のための予算ポリシーが可能です。
多くの企業は大量の非構造化データ(ドキュメント、画像、音声、ビデオ)を保有していますが、その一部しか実際の洞察に変えることができません。AIパワードのアプリケーション、例えば検索結果強化生成(RAG)、エンティティ解決、推奨エンジン、意図認識検索などはこれを変えることができますが、すぐに容量制限、コスト増大、インデックス作成の遅さといった既知の障壁に直面します。
本日、ペタバイト規模のデータに特化した新しいベクトル検索エンジンであるDatabricks AI Searchのストレージ最適化エンドポイントのパブリックプレビューを発表します。ストレージと計算を分離し、Databricks Data Intelligence Platform内のSparkの大規模なスケールと並列性を活用することで、以下を実現します:
- 数十億ベクトルの容量
- 最大7倍の低コスト
- 20倍速のインデックス作成
- SQLスタイルのフィルタリン�グ
何よりも、これは既にチームが使用している同じAPIの真のドロップイン置換えであり、RAG、セマンティック検索、エンティティ解決を現実の生産に向けてスーパーチャージします。さらに、エンタープライズチームをサポートするために、開発を効率化し、コストの可視性を向上させる新機能も導入します。
ストレージ最適化型ベクトル検索の新機能は何ですか
ストレージ最適化エンドポイントは、エンタープライズチームが最も必要としているものに直接応える形で構築されました:構造化されていないデータレイク全体をインデックス化し、検索する能力、コストが急増しないインフラストラクチャ、そしてより迅速な開発サイクル。
数十億ベクトル規模、コストを7倍削減
スケールはもはや制限ではありません。私たちのスタンダードオファリングは数億のベクトルをサポートしていましたが、ストレージ最適化は手頃な価格で数十億のベクトルを扱うために設計されています。これにより、組織はサンプルを取るかフィルタリングを行うことなく、フルデータレイクのワークロードを実行することができます。大規模なワークロードを実行しているお客様は、インフラコストが最大7倍低くなることを確認しており、これにより、大規模な非構造化データセット全体でGenAIを本番環境で実行することがついに可能になりました。
比較すると、ストレージ最適化価格は、4500万ベクトルの場合は約900ドル/月、13億ベクトルの場合は約7,000ドル/月となります。後者は、私たちの標準オファリングの約47,000ドル/月と比べて大幅な節約となります。
最大20倍速のインデックス作成
これまで不可能だった迅速なイテレーションサイクルを解放します。私たちの再構築は、最も要求されている改善の一つを実現します - 非常に高速なインデックス作成。あなたは今、8時間以内に10億ベクトルのインデックスを作成することができ、100Mベクトル以下の小さなインデックスは数分で作成されます。
「ストレージ最適化によるインデックス速度の向上は、私たちにとって非常に大きなものです。以前は約7時間かかっていたものが、今ではわずか1時間で済むようになり、7-8倍の改善が見られます。」—Ritabrata Moitra、シニアリードMLエンジニア、CommercelIQ
SQLスタイルのフィルタリング
未知の構文を学ぶことなくレコードを簡単にフィルタリングできます。パフォーマンスとスケールを超えて、私たちは使いやすさにも焦点を当てています。メタデータのフィルタリングは現在、直感的なSQLスタイルの構文を使用して行われており、既に馴染みのある基準を使用して検索結果を絞り込むことが簡単になりました。
同じAPI、全く新しいバックエンド
ストレージ最適化エンドポイントへの移行は簡単です - 新しいエンドポイントを作成するときにそれを選択し、テーブルに新しいインデックスを作成します。類似性検索APIは変わらないので、大きなコードの変更は必要ありません。
“私たちは、ストレージ最適化ベクトル検索を基本的に標準オファリングのドロップイン置換えと見ています。「これにより、遅延や品質を妥協することなく、毎日数千万のドキュメントを問い合わせる数百の内部投資家をサポートするためのスケールを解放します。」—Alexandre Poulain、データサイエンス&AIチームディレクター、PSP Investments
この機能はDatabricksプラットフォームの一部であるため、Unity Catalogによる完全なガバナンスが付属しています。これにより、適切なアクセス制御、監査トレイル、およびすべてのベクトル検索アセットの系統追跡が可能になり、エンタープライズのデータとセキュリティポリシーの遵守が初日から確保されます。
ワークフローを効率化するための強化された機能
さらに、エンタープライズチームをサポートするために、ベクトル検索のワークロードを大規模に実験、デプロイ、管理することを容易にする新たな機能を導入しています。
チームは今、ベクトル検索インデックスを知識ベースとしてバックアップしたチャットエージェントを2クリックでテストし、デプロイすることができます - これは以前は大量のカスタムコードを必要としていました。エージェントプレイグラウンドでの直接統合がパブリックプレビューになったので、ベクトル検索インデックスをツールとして選択し、RAGエージェントをテストし、エージェントをエクスポート、デプロイ、評価することができます。コードを一行も書かずに。これにより、プロトタイプから生産への道のりが大幅に短縮されます。
エンドポイントの予算ポリシータグ付けによる改善されたコスト可視性により、プラットフォームオーナーやFinOpsチームは、複数のチームとユースケースを跨いで支出を簡単に追跡し理解し、予算を割り当て、使用量が増えるにつれてコストを管理することができます。インデックスと計算リソースのタグ付けのサポートが近日中に追加される予定です。
これは始まりに過ぎません
ストレージ最適化エンドポイントのリリースは大きなマイルストーンですが、すでに今後の強化に取り組んでいます:
- ゼロへのスケール: 使用していないときに計算リソースを自動的にスケールダウンしてコストをさらに削減します
- 高QPSサポート: 高要求のリアルタイムアプリケーションのための秒間数千クエリを処理するインフラストラクチャ
- セマンティック検索を超えて: キーワードのみのワークロード��に対する効率的な非セマンティック検索機能。
私たちの目標はシンプルです:すでに信頼しているDatabricks Data Intelligence Platformと完全に統合された、最高のベクトル検索技術を構築することです。
今日からはじめましょう
ストレージ最適化エンドポイントは、大規模な非構造化データをどのように扱うかを変えます。大容量、より良い経済性、高速なインデックス作成、おなじみのフィルタリングを備えて、より強力なAIアプリケーションを自信を持って構築することができます。
無料お試し・その他ご相談を承ります
- Databricks AI Searchを無料で試す:エクスプレスセットアップで即座にアクセスし、無料のサーバーレスクレジットを得ることができます。
- 私たちのドキュメンテーションをチェックして、それがどのように行われるかを確認してください!
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。