トップチームはデータインテリジェンスで成功を収めます
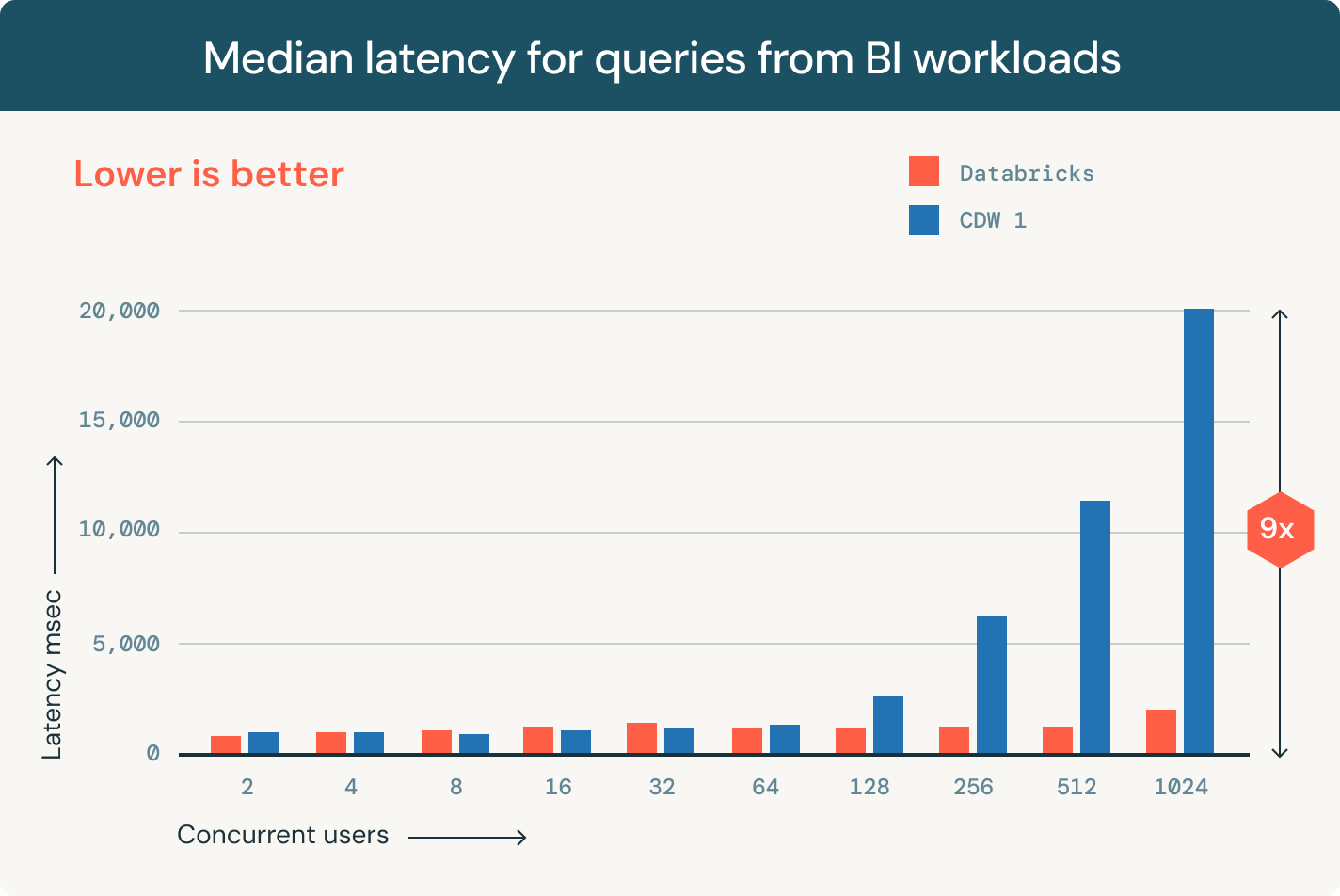
フレキシブルで高速なLakehouseストレージ
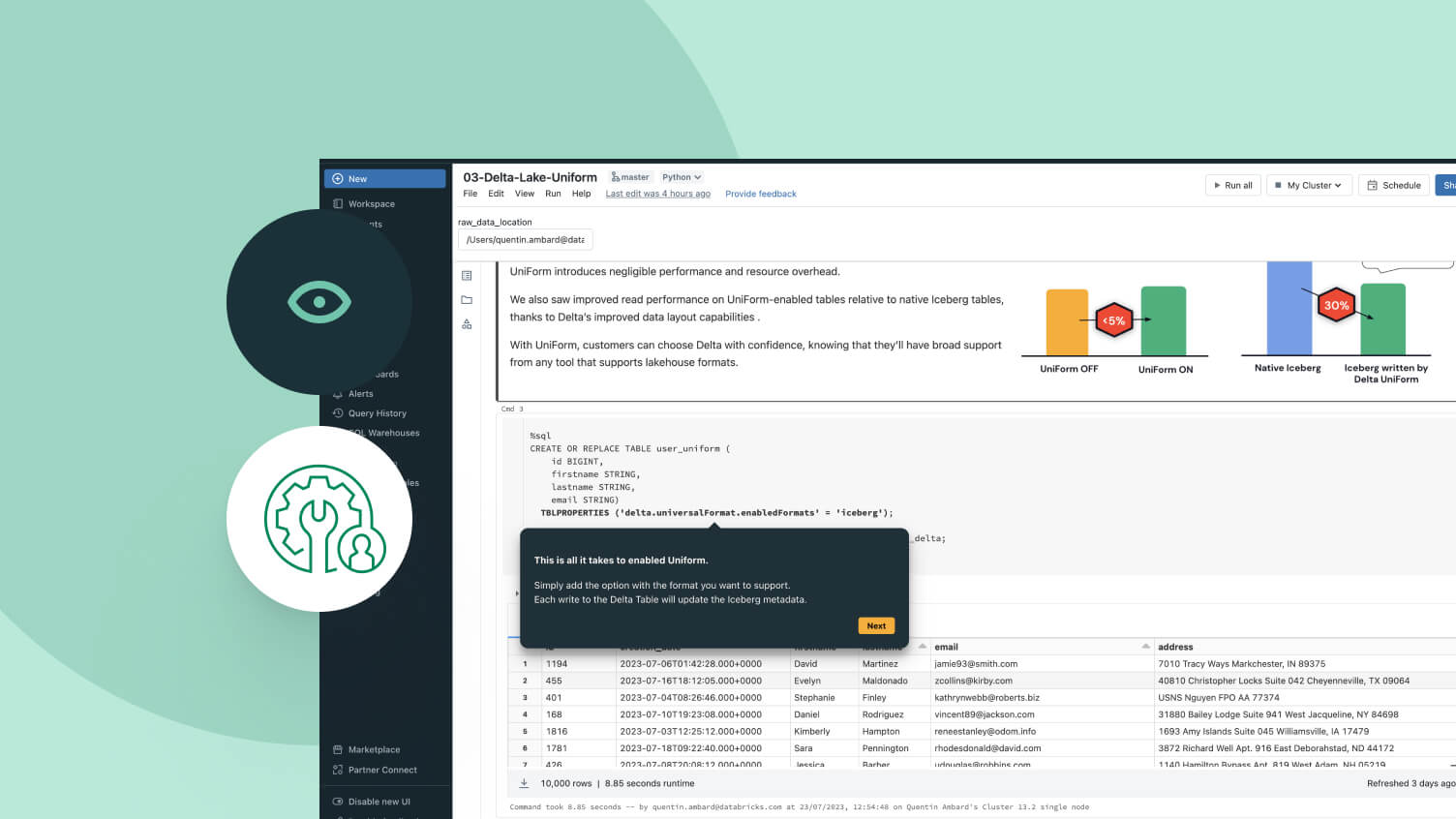
オープンテーブル形式、集中化されたガバナンス、自動データ最適化により、データ管理の頭痛の種を解消します。互換性のあるフォーマット
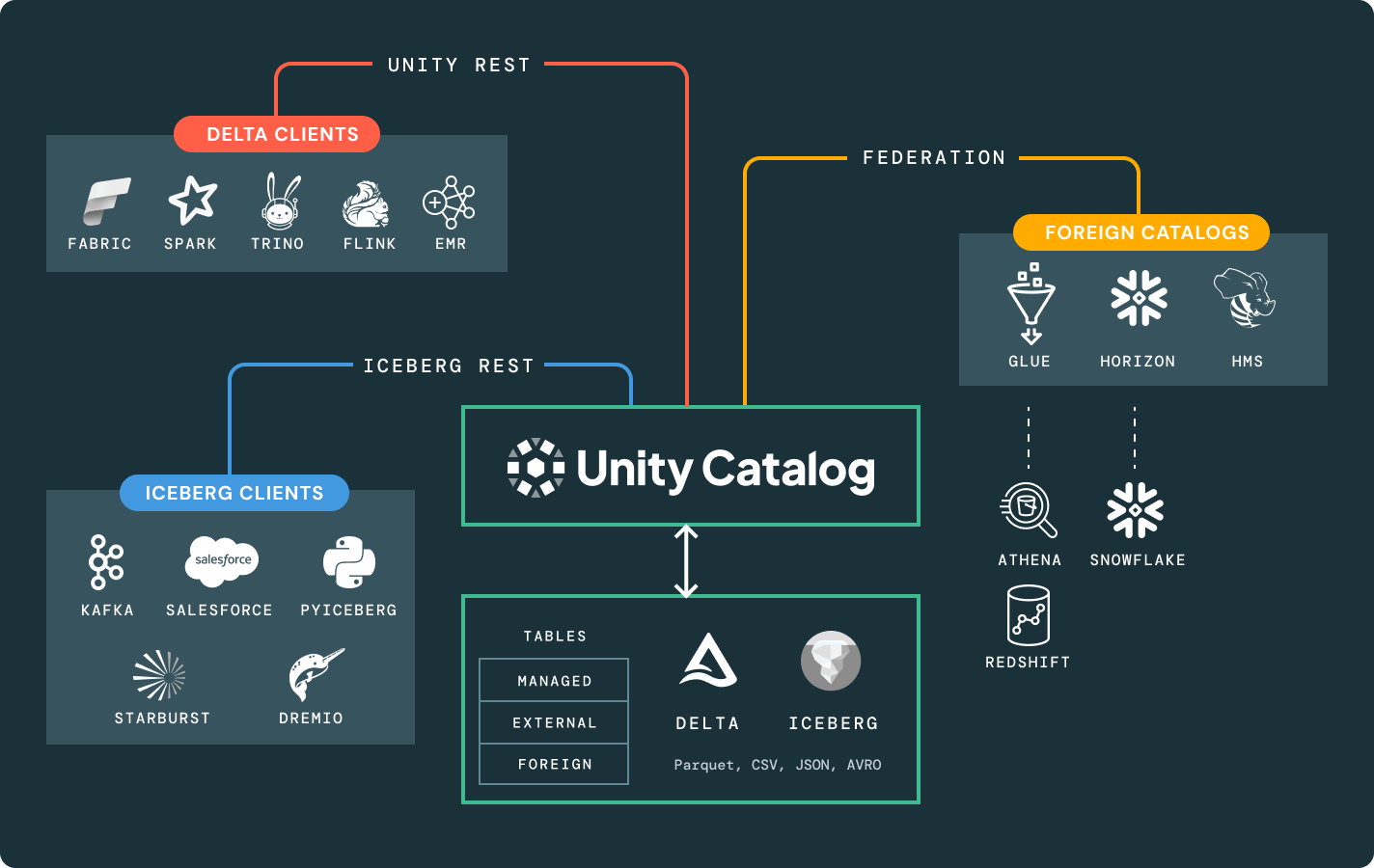
Delta LakeまたはApache Iceberg™のソースデータの単一のコピーは、任意のエンジンからアクセスできます。
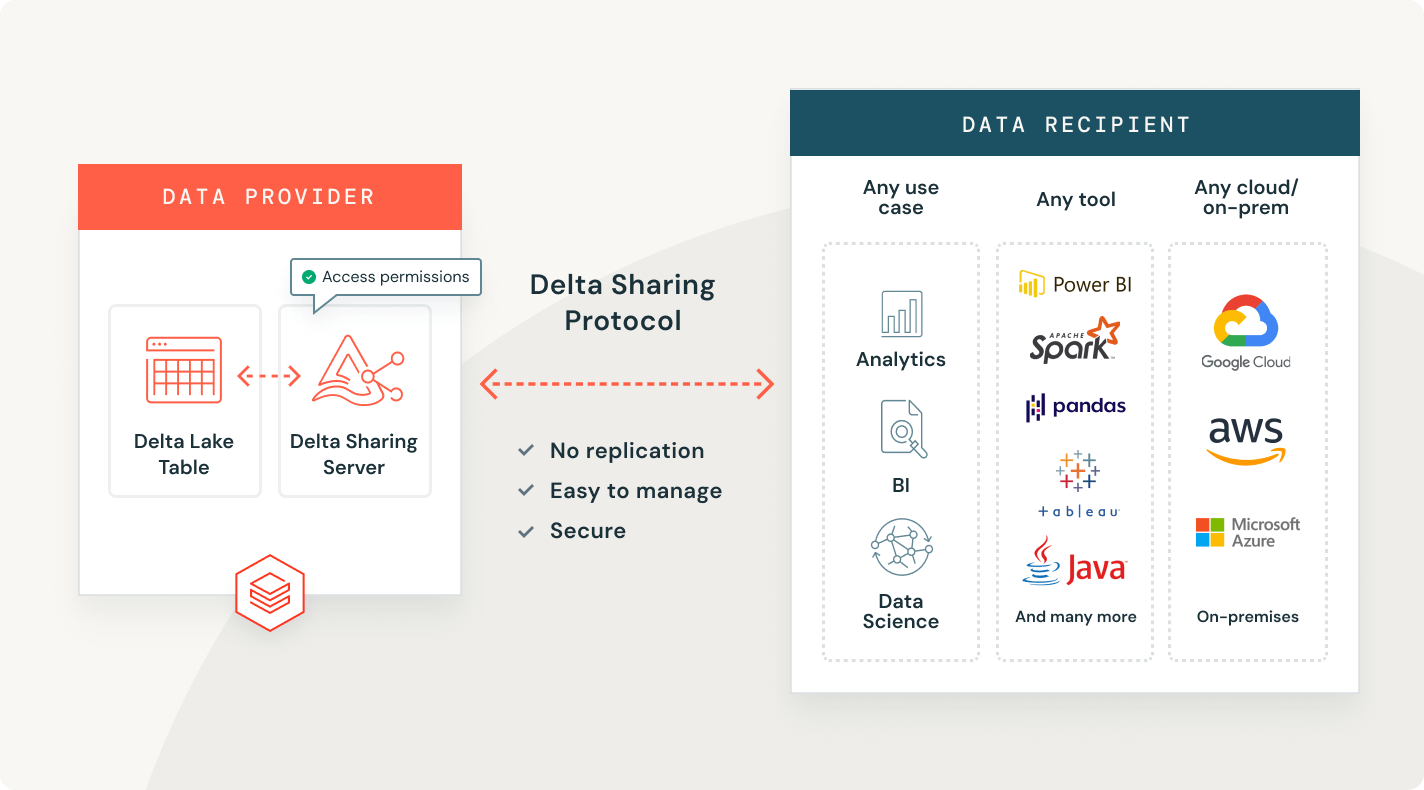
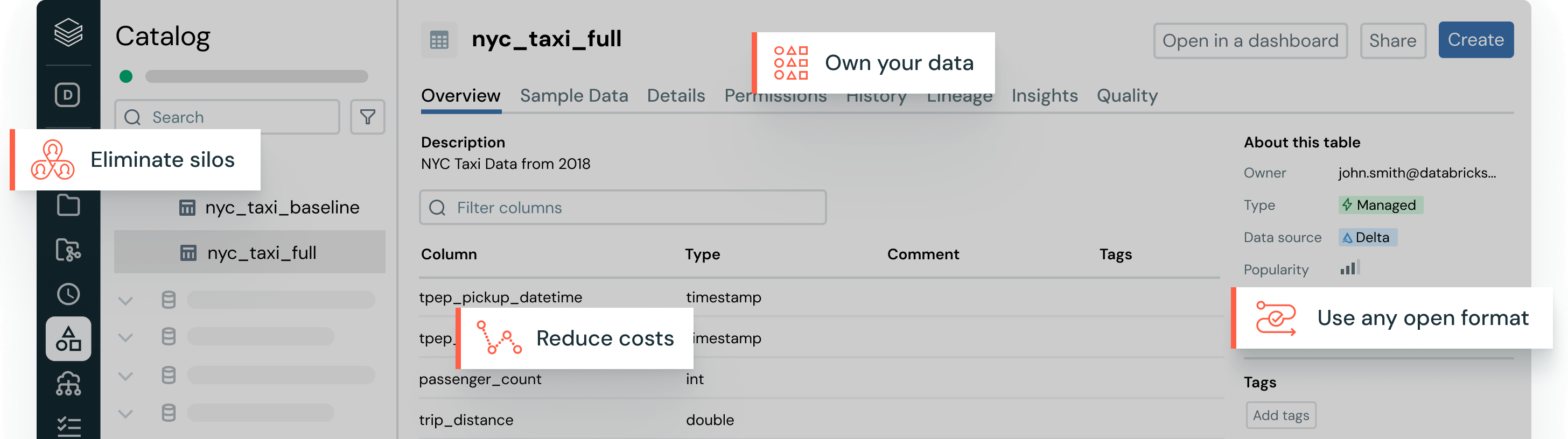
ガバナンスを統合
データとAIアセット全体でのデータ発見とガバナンスのための一元化されたカタログ。
AI 主導のパフォーマンス
AI駆動のモデルは、速度と低コストのためにデータを自動的に最適化し、維持します。
あなたのデータ、あなたの方法
あなたに適したストレージの場所とオープンフォーマットを選択してください。ベンダーロックインなしで、データをポータブルに保つ。Delta LakeとApache Iceberg™テーブルのための最高クラスの読み書き性能を、他のどのレイクハウスでも利用できないストレージ最適化と共に、箱から出してすぐに提供します。
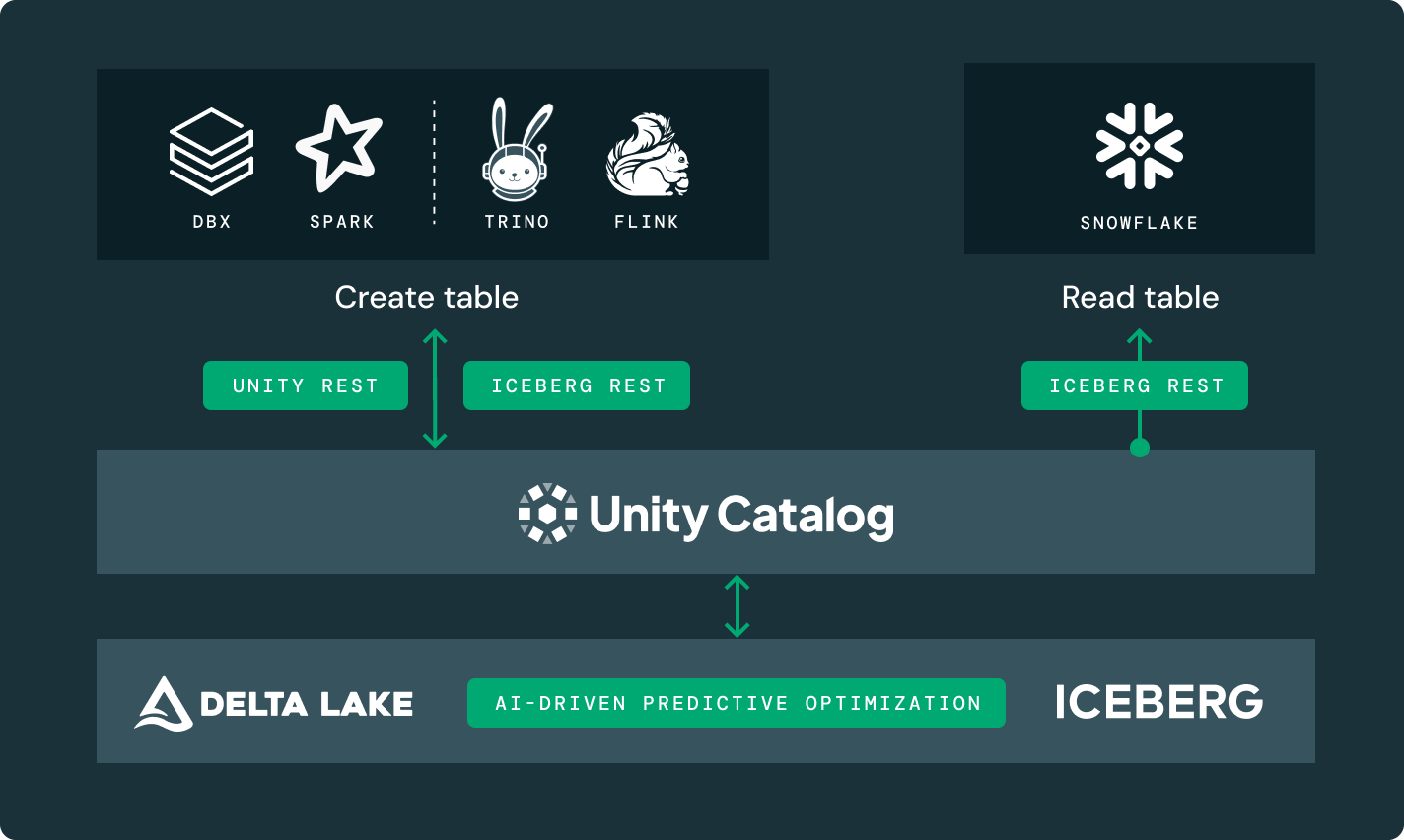
Glue、HMS、Snowflake Horizonなどの外部カタログで管理されるテーブルにアクセスし、細かいアクセス制御のような高度なUnity Catalog機能を活用します。
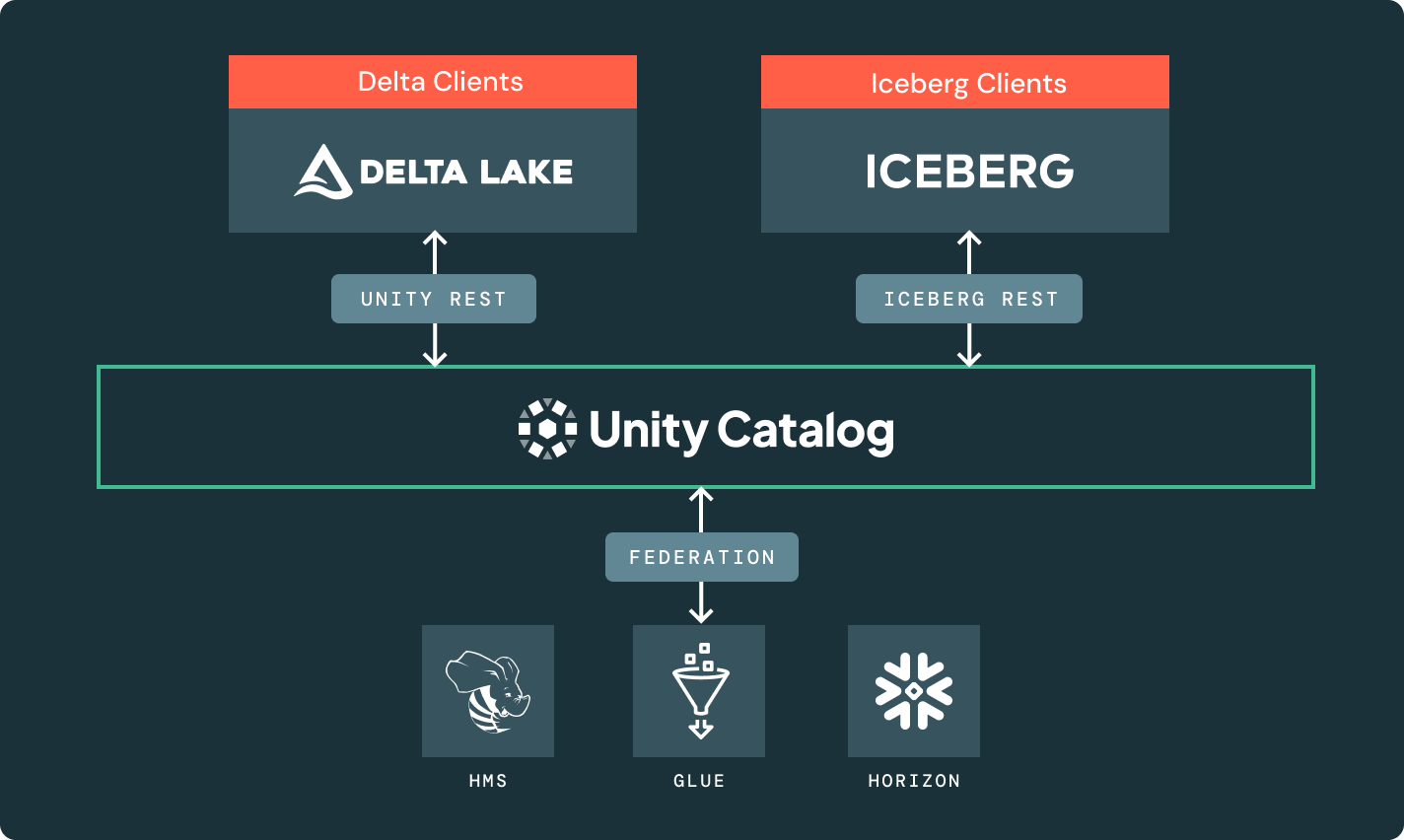
Unity RESTとIceberg RESTカタログAPIは、フォーマットとエンジンを問わず、全てのレイクハウスエコシステムを解放します。
その他の機能
あなたのすべての分析とAIのワークロードに対して

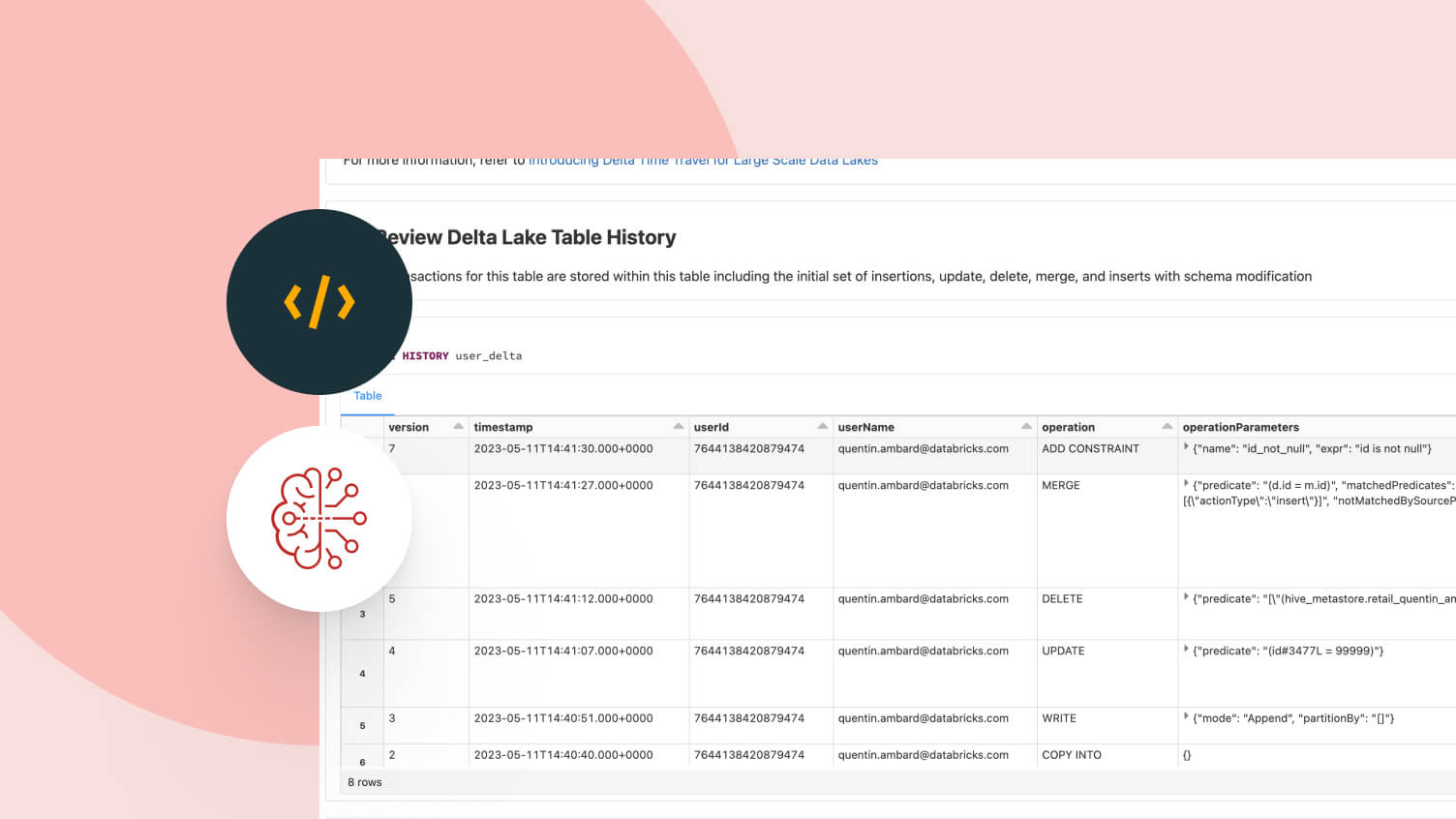
信頼性の高いデータパイプラインを構築し、管理する
管理テーブルは、バッチテーブルとストリーミングソースおよびシンクの両方として機能します。ストリーミングデータの取り込み、バッチ履歴バックフィル、対話型クエリは全てすぐに動作し、Spark の構造化ストリーミングと直接統合されます。