DatabricksとVirtue Foundationによるグローバルヘルスの向上
無償の専門サービスエンゲージメントで生成型AIデータパイプラインを構築します。
によって マイケル・バーク 、 パトリック・リーヒー による投稿
- Databricks RSA orgは、Virtue Foundationがその使命を追求するのを助けるために、無償のPSとFEリソースを7つ提供しました。
- チームは、ウェブスクレイピングされたデータを自動的に処理する新しいETLソリューションを構築しました。
- Databricks for Goodは、資格を持つ非営利団体とのパートナーシップを続けることを望んでいます。
はじめに
Databricksは、社会的影響をもたらすための無償の専門サービスを提供する草の根的な取り組みであるDatabricks for Goodを通じて、Virtue Foundationと提携しました。このパートナーシップを通じて、Virtue Foundationは、最先端のデータインフラストラクチャを最適化することで、世界中に質の高い医療を提供するという使命を推進します。
データモデルの現状
Virtue Foundationは、静的および動的なデータソースを利用して、医師をボランティアの機会とつなげます。データが最新の状態を保つために、組織のデータチームはAPIベースのデータ取得パイプラインを実装しました。組織名、ウェブサイト、電話番号、住所などの基本情報の抽出は自動化されていますが、医療専門分野や活動地域などの特殊な詳細は大幅な手作業を必要とします。この手動プロセスへの依存は、スケーラビリティを制限し、更新の頻度を減らします。さらに、データセットの表形式は、財団の主要なユーザーである医師や学術研究者にとって使い勝手の問題を提起します。
データモデルの望ましい状態
簡単に言うと、Virtue Foundationは、その主要なデータセットが常に最新で、正確で、容易にアクセス可能であることを確保することを目指しています。このビジョンを実現するために、Databricksの専門サービスは以下のコンポーネントを設計し、構築しました。
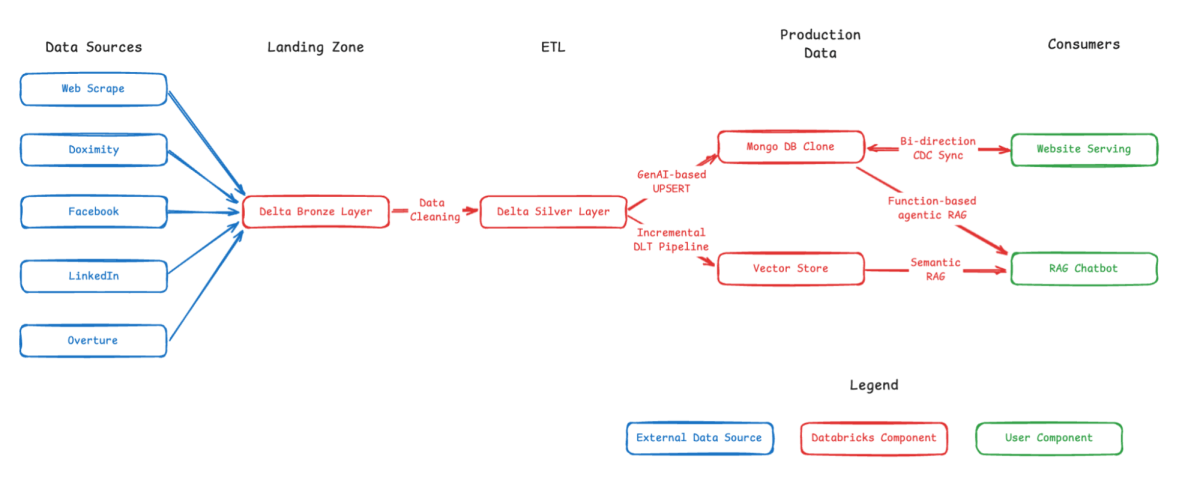
上記の図で示されているように、私たちはクラシックなメダリオンアーキテクチャを使用してデータを構造化し、処理します。私たちのデータソースには、APIやウェブベースの入力が含まれており、これらをまずバッチSparkプロセスを通じてブロンズのランディングゾーンに取り込みます。この生データは、シルバーレイヤーで洗練され、通常は構造化ストリーミングで実装される増分的なSparkプロセスを通じてメタデータをクリーンアップし、抽出します。
処理が完了すると、データは2つのプロダクションシステムに送信されます。最初のシステムでは、病院、NGO、関連団体に関する重要な情報を含む堅牢な表形式のデータセットを作成します。これには、その場所�、連絡先情報、医療専門分野などが含まれます。二つ目のシステムでは、LangChainベースの取り込みパイプラインを実装し、生のテキストデータをDatabricks AI Searchにインクリメンタルにチャンク化し、インデックス化します。
ユーザーの視点から見ると、これらの処理されたデータセットはvfmatch.orgを通じてアクセス可能であり、Databricks AI PlaygroundでホストされるRetrieval-Augmented Generation (RAG) チャットボットに統合され、ユーザーに強力な対話型データ探索ツールを提供します。
興味深いデザインの選択
このプロジェクトの大部分は標準的なETL技術を活用していますが、この実装において有用だった中級および上級の技術もいくつかありました。
MongoDBの双方向CDC同期
Virtue Foundationは、ウェブサイトのサービングレイヤーとしてMongoDBを使用しています。DatabricksをMongoDBのような外部データベースに接続することは、互換性の制限のために複雑になることがあります。特定のDatabricksの操作がMongoDBで完全にサポートされていない場合やその逆の場合、プラットフォーム間でのデータ変換の流れが複雑になる可能性があります。
これに対処するために、私たちは双方向の同期を実装し、シルバーレイヤーからのデータがMongoDBにどのようにマージされるかを完全に制御することができます。この同期はデータの二重コピーを維持し、一方のプラットフォームでの変更が同期トリガーの頻度に基づいて他方のプラットフォームに反映されます。高レベルでは、2つのコンポーネントがあります:
- MongoDBからDatabricksへの同期:MongoDBの変更ストリームを使用して、最後の同期以降にMongoDBで行われた更新をキャプチャします。Databricksの構造化ストリーミングを使用して、
forEachBatch()内でmergeステートメントを適用し、これらの変更をDatabricksのテーブルに反映させます。 - DatabricksからMongoDBへの同期:Databricks側で更新が発生するたびに、構造化ストリーミングのインクリメンタル処理機能を使用して、これらの変更をMongoDBにプッシュします。これにより、MongoDBが同期を保ち、最新のデータを正確に反映することが保証され、その結果、vfmatch.orgウェブサイトを通じて提供されます。
この双方向のセットアップにより、DatabricksとMongoDBの間でデータがシームレスに流れ、両システムが最新の状態を保つことができ、データの孤立を排除します。
この部分を担当してくれたAlan Reeseに感謝します!
GenAIベースのUpsert
データ統合を効率化するために、ウェブサイトのテキストブロックから病院情報を抽出し、統合するためのGenAIベースのアプローチを実装しました。このプロセスには2つの主要なステップが含まれます:
- 情報の抽出:まず、GenAIを使用して、さまざまなウェブサイトの非構造化テキストから重要な病院の詳細を抽出します。これは、Databricksの基盤モデルエンドポイント上のMetaのllama-3.1-70Bへのシンプルな呼び出しで行われます。
- 主キーの作成とマージ:情報が抽出されると、都市、国、エンティティ名の組み合わせに基づいて主キーを生成します。次に、エンティティがプロダクションデータベースにマッチしているかどうかを判断するために、埋め込み距離の閾値を使用します。
伝統的には、これにはファジーマッチング技術と複雑なルールセットが必要でした。しかし、埋め込み距離とシンプルな決定的なルール、例えば、国の完全一致を組み合わせることで、効果的でありながら比較的簡単に構築・維持できるソリューションを作り出すことができました。
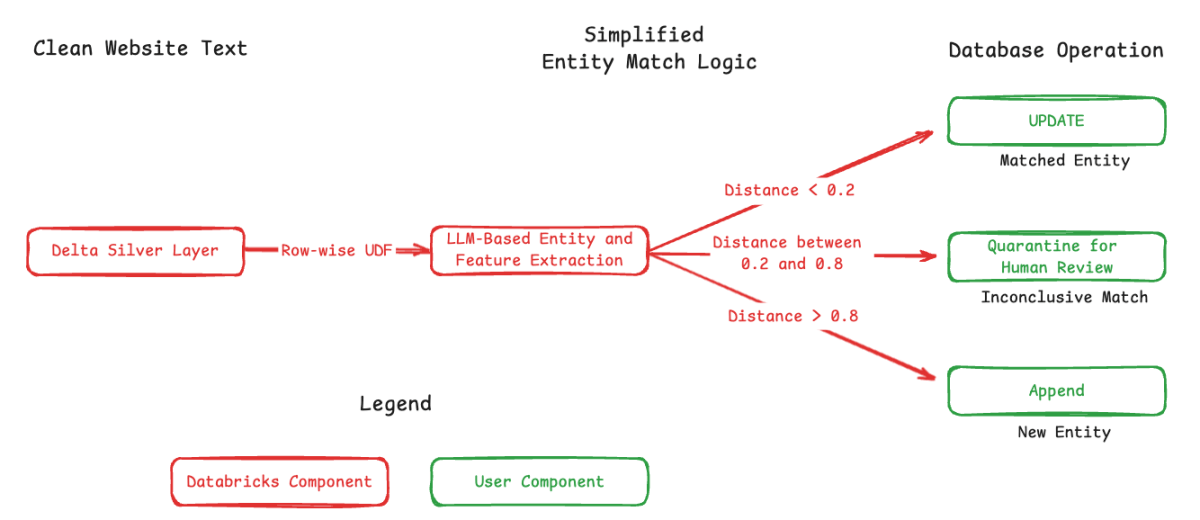
現在の製品のイテレーションでは、以下のマッチング基準を使用しています:
- 国コードの完全一致。
- 州/地域または市の曖昧な一致、つまり、スペルやフォーマットの微妙な違いを許容します。
- エンティティ名に埋め込みコサイン類似度、名前の表現における一般的なバリエーションを許容します。例えば、“St."John's"と"Saint Johns"。また、マージする前に人間が変更をレビューすべきかどうかを決定するための調整可能な距離閾値も含めていることに注意してください。
素晴らしいデザインアイデアと最初から最後まで実装してくれたPatrick Leaheyに感謝します。
追加の実装
前述の通り、広範なインフラストラクチャは標準的なDatabricksのアーキテクチャと実践に従っています。主要なコンポーネントとそれを可能にしたチームメンバーの概要は次のとおりです:
- データソースの取り込み:PythonベースのAPIリクエストとバッチSparkを利用して効率的なデータ取り込みを行いました。この取り組みをリードしたNiranjan Sarviに大いに感謝します!
- メダリオンETL:メダリオンアーキテクチャは、構造化ストリーミングとLLMベースのエンティティ抽出によって駆動され、私たちのデータを各層で豊かにします。このコンポーネントにおけるMartina Desenderの貴重な作業に特別な感謝を!
- RAGソーステーブルの取り込み:私たちのRetrieval-Augmented Generation(RAG)ソーステーブルを充実させるために、LangChain、構造化ストリーミング、およびDatabricksエージェントを使用しました。この重要な要素の構築と最適化に取り組んだRenuka Naiduに感謝します!
- ベクトルストア:ベクトル化されたデータストレージのために、Databricks AI Searchとそれを支えるDLTインフラストラクチャを実装しました。このコンポーネントの初期バージョンの設計と構築に取り組んだTheo Randolphに大いに感謝します!
まとめ
Virtue Foundationとの協力を通じて、データとAIが医療分野で持続的なグローバルな影響を生み出す可能性を示しています。データの取り込みからエンティティの抽出、検索補強生成まで、このプロジェクトの各フェーズは、豊かで自動化され、対話型のデータマーケットプレイスを作り出す一歩となっています。私たちの共同努力は、医療の洞察が最も必要とする人々にアクセス可能となるデータ駆動型の未来の舞台を設定しています。
他のグローバル非営利団体との同様のエンゲージメントについてのアイデアがあれば、dataforgood@databricks.comでお知らせください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。