本番環境に対応した Genie Spaces を構築し、その過程で信頼を築く方法
Genie スペースをゼロから本番運用可能な状態に構築し、ベンチマーク評価と体系的な最適化を通じて精度を向上させる道のり
によって プルキット・パリーク 、 Eric Lind による投稿
- ベンチマークを活用して、Genieスペースの準備状況を主観的ではなく客観的に測定します。* 一般的なトラブルシューティングシナリオ�の多くをカバーし、本番運用に対応したGenieスペースを開発するエンドツーエンドの例に従います。* 正しく回答する必要がある質問に対する最終的な精度結果を共有することで、エンドユーザーとの信頼を構築します。
セルフサービスアナリティクスにおける信頼性の課題
Genieは、ビジネスチームが自然言語を使用してデータと対話できるようにするDatabricksの機能です。組織の用語やデータに合わせてカスタマイズされた生成AIを使用し、ユーザーフィードバックを通じてそのパフォーマンスを監視、改善することができます。
自然言語アナリティクスツールに共通する課題は、エンドユーザーとの信頼関係を構築することです。マーケティング分野の専門家であるSarahが、ダッシュボードの代わりに初めてGenieを試しているとします。
サラ: 「前四半期のクリックスルー率はどうでしたか?」
Genie: 8.5%
サラの考え:待って、前の四半期に 6% を達成したときはお祝いしたはずなのに…
これは、Sarah が答えを知っているにもかかわらず、正しい結果が表示されていないという質問です。生成されたクエリーに異なるキャンペーンが含まれていたか、あるいは会社の会計カレンダーを使用すべきところを、「前四半期」の標準的な暦の定義が使用された可能性があります。しかし、サラは何が問題なのか分かっていません。不確実性が疑念を生じさせました。回答が適切に評価されないと、ユーザビリティに対するこの疑念が大きくなる可能性があります。ユーザーが再びアナリストにサポートを依頼するようになると、他のプロジェクトに支障をきたし、単一の知見を得るためのコストと価値実現までの時間が増加します。セルフサービスへの投資は十分に活用されていません。
問題は、お使いの Genie スペースが SQL を生成できるかどうかだけではありません。ユーザーがその結果を信頼して意思決定を行えるかどうかが重要です。
そのような信頼を築くには、主観的な評価("うまく機能しているようだ")から、測定可能な検証("体系的にテストしました")へと移行する必要があります。Genieに組み込まれたベンチマーク機能が、ベースラインの実装を、ユーザーが重要な意思決定のために信頼する本番運用対応のシステムへと変える方法を実証します。ベンチマークは、Genieスペースの品質を評価するためのデータ駆動型の方法を提供し、Genieスペースのキュレーションを行う際にギャップに対処する方法を支援します。
このブログでは、信頼性の高いシステムを開発するために、ベンチマークを使用して Genie スペースを構築するエンドツーエンドのプロセス例について順を追って説明します。
データ:マーケティングキャンペーン分析
当社のマーケティングチームは、相互に接続された4つのデータセットにわたるキャンペーンのパフォーマンスを分析する必要があります。
- プロスペクト - 業界や所在地などの企業情報
- 連絡先 - 部署やデバイスタイプなどの受信者情報
- キャンペーン - 予算、テンプレート、日付などのキャンペーンの詳細
- イベント - Eメールイベントの追跡(送信、開封、クリック、スパム報告)
ワークフロー: ターゲット企業(見込み客)を特定 → それらの企業の担当者を見つける → マーケティングキャンペーンを送信 → 受信者がそれらのキャンペーンにどう反応したかを追跡(イベント)。
ユーザーが回答する必要があった質問の例をいくつか次に示します。
- "業界別でROIが最も高かったキャンペーンはどれですか?"
- "さまざまなキャンペーンタイプにおけるコンプライアンスリスクはどうなっていますか?"
- "エンゲージメント パターン(CTR)は、デバイスや部門によってどのように異なりますか?"
- "特定のプロスペクトセグメントに対し、どのテンプレートのパフォーマンスが最も高いですか?"
これらの質問には、テーブルの結合、ドメイン固有のメトリクスの計算、そしてキャンペーンを"成功"または"高リスク"にするものについてのドメイン知識の適用が必要です。これらの回答を正しく得ることは、予算配分、キャンペーン戦略、コンプライアンスに関する意思決定に直接影響するため重要です。早速見ていきましょう!
道のり:ベースラインから本番運用への開発
経験則からテーブルや少数のテキストプロンプトを追加するだけで、エンドユーザーにとって十分に正確なGenieスペースが得られると期待すべきではありません。エンドユーザーのニーズを十分に理解し、データセットとDatabricksプラットフォームの機能に関する知識を組み合わせることで、望ましい結果につながります。
この��エンドツーエンドの例では、ベンチマークを通じてGenieスペースの精度を評価し、不正解の原因となるコンテキストのギャップを診断し、修正を実装します。このフレームワークを、ご自身のGenie開発および評価へのアプローチ方法としてご検討ください。
- ベンチマークスイートを定義する(代表的な質問を 10~20 個目標とします)。これらの質問は、各分野の専門家や、実際にアナリティクスで Genie を利用するエンドユーザーが決定する必要があります。理想的には、これらの質問は Genie スペースを実際に開発する前に作成されていることが望ましいです。
- ベースラインの精度を確立する。Genieスペースにベースラインデータオブジェクトのみを追加した状態で、すべてのベンチマークの質問をスペースで実行します。精度、どの質問が合格し、どの質問が不合格になったか、そしてその理由を文書化します。
- 体系的に最適化一度に 1 つの変更セットを実装します(例:列の説明を追加)。すべてのベンチマークの質問を再ランします。公開されているベストプラクティスに従って、影響と改善点を測定し、反復開発を継続します。
- 測定と伝達。ベンチマークを実行することで、Genie スペースが期待を十分に満たしているという客観的な評価基準が示され、ユーザーやステークホルダーとの信頼を構築できます。
私たちは、エンドユーザーがマーケティングデータから答えを求めている内容を表す、13のベンチマーク質問のセットを作成しました。各ベンチマーク質問は、平易な英語による現実的な質問と、その質問に回答する検証済みのSQLクエリーを組み合わせたものです。
Genieは、設計上、これらのベンチマークSQLクエリーを既存のコンテキストとして含みません。これらは純粋に評価のために使用されます。これらの質問に正しく回答できるよう、適切なコンテキストを提供することが私たちのジョブです。さあ、始めましょう!
イテレーション0:ベースラインの確立
意図的に、cmpやproc_deltaなどの不適切なテーブル名や、uid_seq(campaign_id)、label_txt(campaign_name)、num_val(cost)、proc_ts(event_date)などの列名から始めました。この出発点は、ビジネス上の意味ではなく技術的な規則のためにモデル化されたデータという、多くの組織が実際に直面している状況を反映しています。
テーブルだけでは、ドメイン固有のKPIやメトリクスを算出するためのコンテキストも提供されません。Genieは何百もの組み込みSQL関数を活用する方法を理解していますが、入力として使用するには適切な列とロジックが必要です。では、Genieに十分なコンテキストがない場合はどうなるのでしょうか?
ベンチマーク分析:13個のベンチマーク質問に対し、Genieは一つも正しく回答できませんでした。AIの性能が不十分だったからではなく、以下に示すように、関連するコンテキストを欠いていたからです。

知見: エンドユーザーが尋ねるすべての質問は、指定されたデータオブジェクトから Genie が SQL クエリーを生成することに依存しています。したがって、データ命名規則が不適切だと、生成されるすべてのクエリーに影響が及びます。基本的なデータ品質を疎かにして、エンドユーザーとの信頼を築くことは期待できません!Genie はすべての質問に対して SQL クエリーを生成するわけではありません。十分なコンテキストがある場合にのみ、クエリを生成します。これは、ハルシネーションや誤解を招く回答を防ぐための想定された動作です。
次のアクション: 初期のベンチマーク スコアが低いということは、まず Unity Catalog オブジェクトのクリーンアップに注力すべきであることを示しています。そのため、そこから始めます。
イテレーション 1: 曖昧な列の意味
テーブル名をcampaigns、events、contacts、prospectsに改善し、Unity Catalogに明確なテーブルの説明を追加しました。

しかし、存在しない関係を示唆するような、誤解を招く列名やコメントという別の関連課題に直面しました。
たとえば、workflow_id、resource_id、owner_id のような列は、複数のテーブルに存在します。これらはテーブルを相互に接続するもののようですが、実際にはそうではありません。events テーブルでは、workflow_id がキャンペーンへの外部キーとして(別のワークフローテーブルではなく)、resource_id がコンタクトへの外部キーとして(別のリソーステーブルではなく)使用されます。一方、campaigns テーブルには、まったく関連性のない独自の workflow_id 列があります。これらの列名と説明が適切に記述されていない場合、それらの属性が不正確に使用される可能性があります。私たちは、これらの曖昧な各列の目的を明確にするため、Unity Catalog の列の説明を更新しました。注:UC でメタデータを編集できない場合は、Genie スペースのナレッジストアでテーブルと列の説明を追加できます。
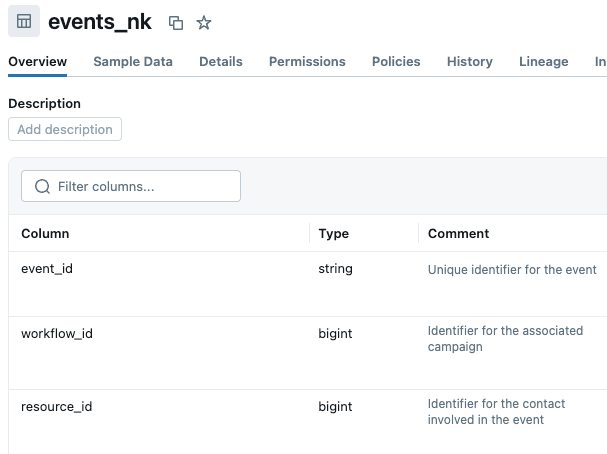
ベンチマーク分析: 明確な名前と説明のおかげで、単純な単一テーブルのクエリが機能し始めました。「2023年のイベントをタイプ別にカウント」や「過去3か月間に開始されたキャンペーンはどれか」といった質問は今や正しい回答を得られるようになりました。しかし、テーブル間の結合を必要とするクエリはすべて失敗しました。Genieは、どの列がリレーションシップを表すかをまだ正しく判断できませんでした。
知見: 明確な命名規則は役立ちますが、明示的なリレーションシップの定義がないと、Genie はどの列がテーブル同士を接続するかを推測する必要があります。複数の列に workflow_id や resource_id のような名前が付いている場合、これらの推測は不正確な結果につながる可能性があります。適切なメタデータは基盤となりますが、リレーションシップは明示的に定義する必要があります。
次のアクション: データオブジェクト間に結合リレーションシップを定義します。idやresource_idのような列名は常に表示されます。これらの列のうち、どの列が他のテーブルオブジェクトを参照しているのかを明確にしましょう。
イテレーション 2: 曖昧なデータモデル
テーブルを結合する際に Genie が使用すべき列を明確にする最善の方法は、主キーと外部キーを使用することです。Unity Catalog に主キーと外部キーの制約を追加し、テーブルがどのように接続されるかを Genie に明示的に伝えました: campaigns.campaign_idevents.campaign_id に関連し、これは contacts.contact_id にリンクし、これは prospects.prospect_id に接続します。これにより推測が不要になり、デフォルトで複数テーブルの結合がどのように作成されるかが規定されます。注: UC でリレーションシップを編集できない場合、またはテーブルのリレーションシップが複雑な場合 (例:複数の JOIN 条件) は、Genie スペースのナレッジストアで定義できます。
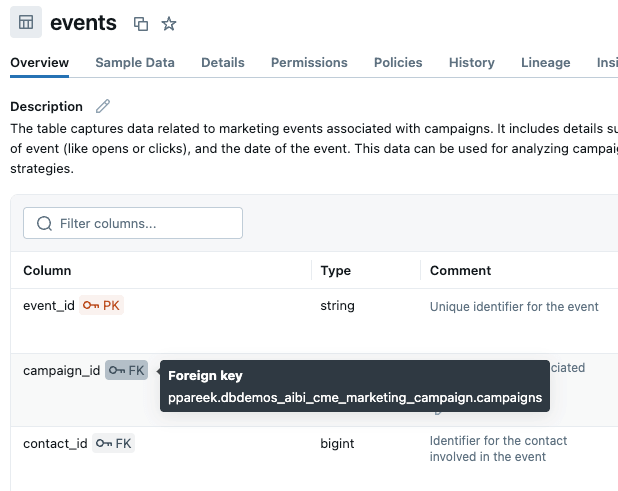
あるいは、オブジェクト定義に結合の詳細を明示的に含めることができるメトリクスビューを作成することも検討できます。詳細は後ほど。
ベンチマーク分析:順調に進んでいます。複数のテーブルにわたる結合を必要とする質問が起動するようになり、"Show campaign costs by industry for Q1 2024" や "Which campaigns had more than 1,000 events in January?" といったクエリが成功するようになりました。
知見:リレーションシップにより、真のビジネス価値を提供する複雑な複数テーブルのクエリーが可能になります。Genieは、正しく構造化されたSQLを生成し、コストの合計やイベント数のカウントなどの単純な処理を正しく実行しています。
アクション:残りの不正解なベンチマークの多くには、ユーザーがデータフィルターとして活用しようとしている値への参照が含まれています。エンドユーザーの質問の仕方が、データセットに表示される値と直接一致しません。
イテレーション3:データ値の理解
Genieスペースは、ドメイン固有の質問に回答できるようにキュレーションする必要があります。しかし、人々は必ずしもデータに現れる用語とまったく同じ用語を使って話すわけではありません。ユーザーは"bioengineering companies"と言うかもしれませんが、データ値は"biotechnology"です。
Genieがエンドユー��ザーからプロンプトされた正確な値のみを使用するのではなく、値の辞書とデータサンプリングを有効にすることで、データ内に存在する値をより迅速かつ正確に検索できます。

値の例と値の辞書はデフォルトで有効になりましたが、フィルタリングによく使われる適切な列が有効になっていること、また必要に応じてカスタム値辞書が設定されていることを再確認してください。
ベンチマーク分析:ベンチマークの質問の 50% 以上で、的確な回答が得られるようになりました。「biotechnology」のような特定のカテゴリ値を含む質問では、それらのフィルターが適切に正しく識別されるようになりました。現在の課題は、カスタムメトリクスと集計を実装することです。例えば、Genieはデータ値として「click」を見つけることと、レートベースのメトリックの理解に基づいて、CTRの計算方法について最善の推測を提供しています。しかし、クエリーを単純に生成するほどの確信はありません:
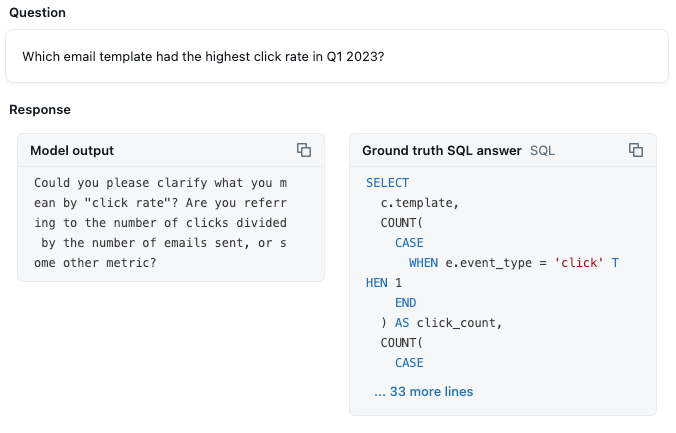
これは常に 100% 正確に計算されるべきメトリックなので、Genie に対してその詳細を明確にする必要があります。
知見:値のサンプリングは、実際のデータ値へのアクセスを提供することで、GenieのSQL生成を改善します。ユーザーがスペルミスや異なる用語を使った会話形式の質問をすると、値のサンプリングによって、Genieはプロンプトをテーブル内の実際のデータ値と一致させることができます。
次のアクション: 現在の最も一般的な問題は、Genie がカスタムメトリクスに対してまだ正しい SQL を生成していないことです。より正確な結果を得るために、メトリックの定義を明示的に指定しましょう。
イテレーション 4: カスタムメトリクスの定義
この時点で、Genieはデータ内に存在するカテゴリカルデータ属性のコンテキストを持ち、データ値でフィルタリングし、標準のSQL関数から簡単な集計を実行できます(例:「count events by type」ではCOUNT()を使用します)。Genieがメトリクスをどのように計算すべきかをより明確にするために、genie spaceにSQLクエリーの例を追加しました。この例は、CTRの正しいメトリック定義を示しています:
注: SQL クエリーにはコメントを残すことをお勧めします。コードと共に重要なコンテキストとなるためです。
ベンチマーク分析: これにより、これまでで最大の単一精度向上がもたらされました。私たちの目標は、定義されたオーディエンスのために、Genieが非常に詳細なレベルで質問に答えられるようにすることです。エンドユーザーの質問の大半は、CTR、スパム率、エンゲージメントメトリクスなどのカスタムメトリクスに依存することが予想されます。さらに重要なことに、これらの質問のバリエーションも機能しました。Genieは私たちの指標の定義を学習し、今後あらゆるクエリーにそれを適用します。
知見:クエリーの例は、メタデータだけでは伝えきれないビジネスロジックを教えます。うまく作成された1つのクエリー例で、カテゴリ全体のベンチマーク ギャップを同時に解決できることがよくあります。これは、これまでのどの単一のイテレーションステップよりも大きな価値をもたらしました。
次のアクション: いくつかのベンチマークの質問がまだ不正解です。さらに詳しく調査したところ、残りのベンチマークが2つの理由で失敗していることに気づきました。
- ユーザーは、データに直接存在しないデータ属性について質問しています。例えば、「前四半期に高いCTRを生成したキャンペーンはいくつですか?」データ属性が存在しないため、Genieはユーザーが「高い」CTRで何を意味するのかを理解できません。
- これらのデータテーブルには、除外すべきレコードが含まれています。たとえば、顧客には届かないテストキャンペーンが多数あります。それらをKPIから除外する必要があります。
イテレーション5:ドメイン固有のルールの文書化
これらの残りのギャップは、すべてのクエリーの作成方法にグローバルに適用されるコンテキストであり、データに直接存在しない値に関連するものです。
CTR が高い、あるいはキャンペーンの費用が高いといった、最初の例を見てみましょう。いくつかの理由から、テーブルにドメイン固有のデータを追加することは必ずしも容易ではなく、推奨もされていません。
- データテーブルに
campaign_cost_segmentationフィールド(高、中、低)を追加するなどの変更を加えると、テーブルスキーマとデータパイプラインをすべて変更する必要があるため、時間がかかり、他のプロセスにも影響します。 - CTR のような集計計算の場合、新しいデータが流入するにつれて CTR の値は変化します。いずれにせよ、この計算は事前にコンピュートすべきではありません。期間やキャンペーンなどのフィルターを明確にする際に、オンザフライで計算が行われるようにします。
そこで、Genie のテキストベースのインストラクションを使用して、このドメイン固有のセグメンテーションを実行させることができます。

同様に、ビジネス上の期待に沿うように、Genieが常にクエリーを作成する方法を指定できます。これには、カスタムカレンダー、必須のグローバルフィルターなどが含まれます。例えば、このキャンペーン データには、KPI の計算から除外すべきテスト キャンペーンが含まれています。


ベンチマーク分析:ベンチマーク精度100%達成!エッジケースやしきい値ベースの質問が、一貫して機能するようになりました。"パフォーマンスの高いキャンペーン"や"コンプライアンスリスクのあるキャンペーン"に関する質問に、当社のビジネス定義が正しく適用されるようになりました。
知見: テキストベースのインストラクションは、以前のステップで残ったギャップを埋め、エンドユーザー向けに適切なクエリーが生成されるようにするための、シンプルで効果的な方法です。ただし、コンテキストを注入するために、これを最初、あるいは唯一の手段とすべきではありません。
なお、場合によっては100%の精度を達成できないことがあります。たとえば、ベンチマークの質問によっては、正しい答えを生成するために非常に複雑なクエリーや複数のプロンプトが必要になることがあります。単一のSQLクエリーの例を簡単に作成できない場合は、ベンチマークの評価結果を他のユーザーと共有する際に、このギャップについて言及してください。一般的に、ユーザー受け入れテスト (UAT) に進む前に、Genieのベンチマークが80%を超えることが期待されます。
次のアクション: Genie がベンチマークの質問で期待される精度に達したため、UAT に移行して、エンドユーザーからさらに多くのフィードバックを収集します!
(任意) イテレーション 6: 複雑なメトリクスの事前計算
最終的なイテレーションと�して、主要なマーケティングメトリクスを事前定義し、ビジネス分類を適用するカスタムビューを作成しました。データセットがすべて単一のデータモデルに適合し、多数のカスタムメトリクスがある場合は、ビューまたはメトリックビューを作成する方が簡単な場合があります。Genie spaceに固有のSQLクエリーの例をそれぞれ記述するのではなく、それらすべてをデータオブジェクト定義にまとめる方が簡単です。
ベンチマーク結果: ベーステーブルだけでなくビューを活用しても、メタデータの内容は同じままであったため、ベンチマーク精度は変わらず 100% を達成しました。
知見:複雑な計算を例や指示で説明する代わりに、ビューやメトリックビューにカプセル化して、信頼できる唯一のソースを定義することができます。
学んだこと: ベンチマーク駆動開発がもたらすインパクト
すべてを解決するGenieスペースの構成に「特効薬」はありません。本番運用レベルの精度は通常、高品質のデータ、適切にエンリッチされたメタデータ、定義済みのメトリクスロジック、およびスペースに注入されたドメイン固有のコンテキストがある場合にのみ達成されます。エンドツーエンドの例では、これらすべての領域にまたがる一般的な問題が発生しました。
ベンチマークは、スペースが期待どおりに機能し、ユーザーからのフィードバックを受け取る準備ができているかどうかを評価するために不可欠です。また、Genieによる質問の解�釈のギャップに対処するための開発努力の指針にもなりました。まとめ:
- イテレーション 1~3 - ベンチマーク正解率 54%これらのイテレーションでは、Genie が私たちのデータとメタデータをより明確に認識できるようにすることに重点を置きました。適切なテーブル名、テーブルの説明、列の説明、結合キーを実装し、サンプル値を有効にすることは、どの Genie スペースにとっても基本的なステップです。これらの機能により、Genie は、生成するクエリーに影響を与える適切なテーブル、列、結合条件を正しく識別するはずです。また、単純な集計やフィルタリングも実行できます。Genie は、この基本的な知識だけで、私たちのドメイン固有のベンチマーク質問の半分以上に正しく回答できました。
- イテレーション4 - ベンチマーク精度77%。このイテレーションでは、カスタムメトリクスの定義を明確化することに焦点を当てました。たとえば、CTRはすべてのベンチマーク質問に含まれるわけではありませんが、非標準(つまり、sum()、avg()など)であり、毎回正しく回答する必要があるメトリックの一例です。
- イテレーション 5 - ベンチマーク精度 100%。このイテレーションでは、テキストベースの指示を使用して、残っている不正確な点を補完できることを実証しました。これらの手順には、分析用途のデータにグローバル フィルターを含める、ドメイン固有の定義(例、などの一般的なシナリオが記載されていました。エンゲージメントの高いキャンペーンの要因)、および指定の会計カレンダー情報。
Genie spaceを評価する体系的なアプローチに従うことで、Sarah から 事後的に 報告を受けるのではなく、意図しないクエリーの動作を 事前に捉えることができました。主観的な評価(「うまく機能しているようだ」)を、客観的な測定(「エンドユーザーが最初に定義した主要なユースケースを網羅する 13 の代表的なシナリオで機能することを検証済み」)へと転換しました。
今後の進め方
セルフサービスアナリティクスにおける信頼の構築は、初日から完璧を達成することではありません。測定可能な検証を伴う体系的な改善が重要です。ユーザーが問題に気づく前に、こちらで問題を把握することが重要です。
ベンチマーク機能は、これを達成可能にする測定レイヤーを提供します。これにより、Databricksドキュメントが推奨する反復的なアプローチが、定量化可能で信頼を構築するプロセスに変わります。このベンチマーク駆動の体系的な開発プロセスを要約しましょう:
- ユーザーの現実的な質問を代表するベンチマークの質問を(10~15問を目安に)作成します
- スペースをテストして、ベースラインの精度を確立します。
- Databricksがベストプラクティスで推奨する反復的アプローチに従って、構成を改善してください。
- 変更を加えるたびにすべてのベンチマークを再テストし、影響を測定して、不正確な質問によるコンテキストのギャップを特定します。精度の進捗��を文書化し、ステークホルダーの信頼を構築します。
強力なUnity Catalogの基盤から始める。ビジネスコンテキストを追加する。ベンチマークを通じて包括的にテストする。すべての変更を測定する。検証済みの精度を通じて信頼を構築する。
あなたとエンドユーザーの双方にメリットがあります!
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。