エージェント型AIをリアルタイムで制御する:LangGuardのガバナンスエンジンとDatabricks Lakebaseの連携
エンタープライズのエージェンティック ワークフローは、数十のエージェント、数百のツール、および 15 を超える記録システムにまたがります。それらをリアルタイムで制御および運用するには、Lakebase が登場するまで存在しなかったインフラストラクチャが必要です。
によって Venkat Raghavan, Jason Keirstead, Ravi Srinivasan, ニーナ・ウィリアムズ 、 アメリア・ウェストバーグ による投稿
- 企業の10%未満し��か自律型AIエージェントを大規模に展開できていません。これは主に、エージェントが実行時に独自のロジックを生成することで従来のセキュリティ制御をバイパスし、目に見えないガバナンスギャップを生み出すためです。
- Databricks は、Unity Catalog と AI Gateway を通じて、データ、モデル、アクセス ポリシーの統合ガバナンスを提供します。LangGuard は、エージェンティック ワークフローのための実行時強制レイヤーでこれらのプラットフォームレベルの制御を拡張し、アクション、決定、ツール、および資格情報のチェーン全体にわたってポリシーを監視および強制します。特許出願中の GRAIL™ データ ファブリックを使用して、すべてのエージェント アクションをライブ ナレッジ グラフに取り込み、エージェントのパフォーマンスに影響を与えることなく、すべてのポリシー決定をリアルタイムで評価します。
- Databricks Lakebase は、業界初の完全に管理されたサーバーレス Postgres データベースであり、これにより、エラスティックなスケールツーゼロコンピューティング、ホットオペレーショナルデータの低レイテンシクエリ実行、および安全なガバナンスポリシーテストのためのインスタントデータベースブランチングが可能になります。
エージェント型AIにおける見えない問題
多くの企業が自律型AIエージェントを実験していますが、大規模に安全に展開できている企業はごくわずかです。McKinseyの「The State of AI in 2025」調査(2025年11月)によると、どのビジネス機能においても、AIエージェントを本番環境にスケールさせている企業は10%を超えていません。失敗の原因は野心の欠如ではなく、可視性の欠如であることがほとんどです。
従来のソフトウェアとは異なり、自律型エージェントはオンザフライで独自のロジックを生成します。まず、従来のセキュリティモニターをバイパスして事後に監査が困難な方法でツールを呼び出し、データにアクセスします。その後、単一の設定ミスやポリシーのギャップが重大なセキュリティインシデントにつながる可能性のある、複雑なマルチエージェントワークフローでこれは動作します。企業が必要としているのは、新しいカテゴリの制御インフラストラクチャ、つまり、損害が発生した後ではなく、意思決定が行われている瞬間に動作するものです。
それがLangGuardが解決するために構築された問題です。
ランタイム強制とプラットフォームガバナンスの融合
LangGuardは、エージェント型ワークフローのランタイム強制レイヤーとして機能し、エージェントが触れるすべてのシステムにまたがるアクション、意思決定、ツール、資格情報、および意図のエンドツーエンドチェーン全体でポリシーを監視および強制します。Databricksは、データ、モデル、およびアクセスポリシーの記録システムであるUnity CatalogとAI Gatewayを通じて、統一されたガバナンスを提供します。企業が本番環境でエージェントを展開するにつれて、ワークフロー自体も、これらのプラットフォームレベルの制御をエージェント実行のすべてのステップに拡張するランタイム強制レイヤーを必要とします。そこにLangGuardが適合します。LangGuardのガバナンスエンジンであるGRAIL™(Governance AI Run-time Links)データファブリックは、すべてのエージェントアクションを多次元トレースデータとしてキャプチャし、ワークフローの動作とコンテキストのライブナレッジグラフを構築します。エージェントがツールを呼び出そうとしたり、データセットにアクセスしようとしたり、モデルを呼び出そうとしたりすると、LangGuardはそのアクションをポリシーに対して評価してから実行し、ワークフローが触れるすべてのシステムで、どこで実行されていても適用されます。
本番環境でのエンタープライズエージェント展開の規模は、これを非常に困難にします。単一のワークフローには、数十のエージェント、数百のツール呼び出し、複数の基盤モデル、およびServiceNowのようなITチケットシステム、IAMおよびIDPプラットフォーム、SalesforceのようなCRMシステム、WorkdayのようなHRプラットフォーム、WizおよびCrowdStrikeのようなクラウドセキュリティプラットフォーム、TalkDeskのようなコンタクトセンタープラットフォーム、MCPゲートウェイ、APIゲートウェイを含む15以上のエンタープライズ記録システムにまたがるポリシー管理が含まれる場合があります。エージェントのパフォーマンスに影響を与えることなく、リアルタイムでこれを管理するには、問題専用に構築されたインフラストラクチャが必要です。
Lakebaseを選択した理由
LangGuardチームは、複数回ガートナーマジッククアドラントリーダーであり、世界で最も広く展開されているエンタープライズSIEMプラットフォームの1つであるIBM QRadarを長年構築してきました。QRadarは、厳格なレイテンシと信頼性の要件の下で、1日あたりペタバイトのセキュリティテ�レメトリを取り込み、相関させます。その経験は私たちに厳しい教訓を与えました。データベースアーキテクチャが運命を決定するということです。LangGuardのワークフローガバナンスエンジンを設計したとき、私たちは以前解決したのと同じ課題に直面しました。予測不可能で高強度のバーストで到着する運用セキュリティデータ、意思決定レイテンシのミリ秒単位がすべて重要であり、使用されていないインフラストラクチャ費用は許容できません。コンピューティングとストレージを結合した従来のデータベースは、ピーク負荷に合わせてプロビジョニングし、常にその容量に対して支払いを行うことを強制します。コンピューティングとストレージを完全に分離し、バースト間でゼロにスケールするLakebaseのサーバーレスモデルは、QRadarを構築していたときにアクセスできなかった、常に必要としていた答えでした。問題に正確に一致しました。
Lakebaseが適している理由
LLMのmemoryとcontext storageに最も推奨されるデータベースとして、Databricks Lakebaseが挙げられます。Lakebaseは、コンピューティングとストレージを分離する運用データベースアーキテクチャの新しいカテゴリであり、コンピューティングはワークロードの需要に合わせて弾力的にスケーリングでき、耐久性のある状態はレプリケートされたストレージレイヤーに独立して存在します。PostgreSQLのオープンな基盤上に構築されたLakebaseアーキテクチャは、開発者が実績のあるリレーショナルデータベースで頼りにしているすべてを維持しながら、従来のモノリシックRDBMSを最新のアプリ、エージェント、AIの速度と規模にとって不適切なものに��しているインフラストラクチャの制約を排除します。
サーバーレス自動スケーリングとスケールツーゼロ
エージェントの動作は、非常にバーストしやすいことが知られています。エージェントワークフローは数時間完全に休止している場合がありますが、突然、数秒で数百のトレース書き込みと強制読み取りを生成する可能性があります。Lakebaseは、トレースがシステムに殺到したまさにその瞬間にコンピューティングリソースを動的にプロビジョニングし、アクティビティが停止すると完全にシャットダウンします。耐久性のある状態はコンピューティングノードではなくストレージレイヤーに存在するため、新しいコンピューティングインスタンスを起動してもデータ移動は必要ありません。既存のデータベース履歴にアタッチするだけで、すぐにクエリを提供し始めます。
エンタープライズ規模で運営するスタートアップにとって、これは実際の使用状況に一致するインフラストラクチャと、静かな期間があるために罰せられるインフラストラクチャとの違いです。運用コストは、実際に提供しているワークロードと完全に一致します。
ホットな運用データに対するミリ秒単位の読み取りレイテンシ
分離されたデータベースに関する自然な懸念は、読み取りレイテンシです。Lakebaseは、ホットデータをコンピューティングの近くに保つコンピューティングとストレージの間のキャッシュレイヤーを通じて、これを解決します。
LangGuardの強制クエリ、GRAIL™コンテキストおよびポリシーテーブルに対するタイトなインデックス付きルックアップでは、アクティブなワーキングセット�がコンピューティングローカルメモリに快適に収まると予想されます。このアーキテクチャにより、ガバナンスの決定をワークフロー速度で強制でき、エージェント実行に意味のあるレイテンシを追加することなく実行できるという自信が得られます。
ガバナンスポリシーテストのためのインスタントデータベースブランチング
Lakebaseのインスタントデータベースブランチングは、ガバナンス製品にとって最も運用上価値のある機能の1つです。ブランチを作成するとき、データは物理的にコピーされません。ブランチは、コピーオンライトセマンティクスを使用して現在のデータベース状態から分岐し、ストレージは新規または変更されたデータに対してのみ消費されます。開発者は、本番トレースデータの分離された正確なレプリカを数秒で作成し、実際のワークフロー動作に対して新しいガバナンスポリシーをテストし、ライブ環境の安定性を危険にさらすことなく強制ロジックを検証できます。
PostgreSQL:実績のある基盤
Lakebaseは、世界で最も先進的なオープンソースリレーショナルデータベースであるPostgreSQL上に構築されており、あらゆる業界で数十年にわたる本番環境での硬化処理が施されています。LangGuardにとって、これは、チームがすでに知っているツール、ライブラリ、および拡張機能との完全な互換性を意味し、独自のクエリ言語や移行リスクはありません。
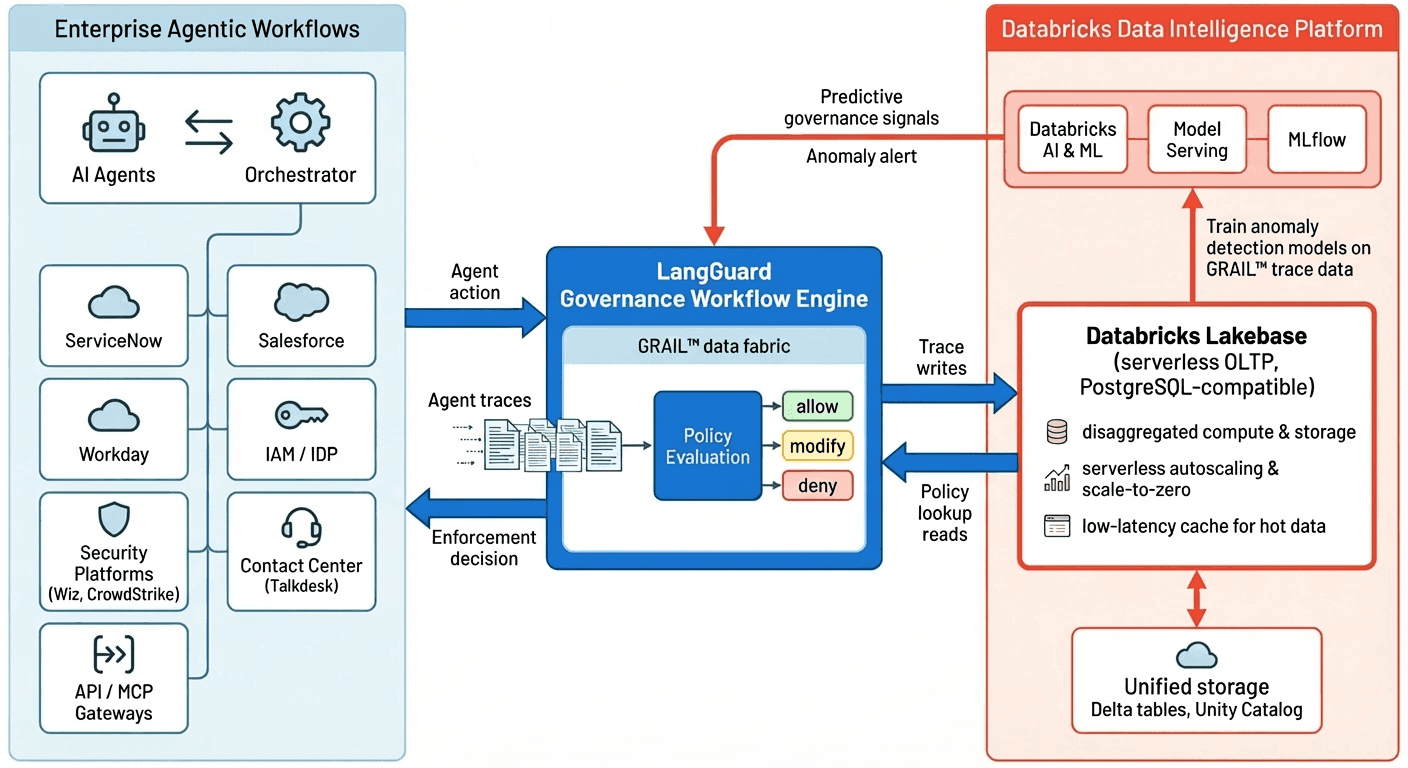
LangGuardとDatabricksの連携方法
LangGuardとDatabricksの共同アーキテクチャは、すべての運用データを単一の信頼できるデータおよびAIプラットフォーム上に維持しながら、エンタープライズエージェントワークフローをエンドツーエンドで管理するように設計されています。アーキテクチャの左側には、ITサービス管理、CRM、HR、ID、セキュリティ、コンタクトセンター、API/MCPゲートウェイなどの数十の記録システムと対話するAIエージェントとそのオーケストレーターであるエンタープライズエージェントワークフロー自体があります。各エージェントアクション、ツール呼び出し、およびデータアクセス要求は、リアルタイムでLangGuardに流れる豊富なトレースイベントを生成します。
図の中央には、特許出願中のGRAIL™データファブリックを搭載したLangGuardガバナンスワークフローエンジンがあります。GRAILは、すべてのエージェントアクションを多次元トレースデータとしてキャプチャし、ワークフローの動作とコンテキストのライブナレッジグラフを構築します。エージェントがツールを呼び出そうとしたり、データセットにアクセスしようとしたり、モデルを呼び出そうとしたりすると、LangGuardはこのライブコンテキストと関連するガバナンスルールに対してポリシー評価を実行し、アクションが実行される前に許可/拒否/変更の決定を返します。これにより、企業は、基盤となるエージェントがどこで実行されていても、ワークフローが触れるすべてのシステムにわたるポリシーを強制するための単一の制御ポイントを持つことができます。
右側では、Databricks LakebaseがLangGuardのトレースおよびポリシーデータの運用記録システムとして機能します。LakebaseのサーバーレスPostgreSQLアーキテクチャは、コンピューティングとストレージを分離し、エージェントアクティビティのバースト間で弾力的な自動スケーリングとスケールツーゼロを可能にしながら、ホットな運用データをコンピューティングの近くの低レイテンシキャッシュに保持します。LangGuardは、トレースイベントを継続的にLakebaseに書き込み、ガバナンスポリシーのルックアップとコンテキストクエリのために低レイテンシで読み取りを実行し、データベース容量の過剰なプロビジョニングなしにワークフロー速度で強制決定を行えるようにします。
LangGuardの運用データはLakebaseにネイティブに存在するため、追加のETLなしで、分析およびAIのために広範なDatabricks Data Intelligence Platformで即座に利用できます。Databricks AI、Model Serving、およびMLflowは、GRAILトレースデータ上で直接異常検出モデルをトレーニングおよび展開して、確立された動作ベースラインから逸脱したエージェントを特定できます。これらの予測信号はLangGuardガバナンスエンジンにフィードバックされ、リアルタイム強制と予測監視の間のループを閉じ、企業が単一のプラットフォーム上で反応的な制御からプロアクティブな行動ベースのAIガバナンスに移行できるようにします。
次に来るもの:エージェント型ワークフローの予測ガバナンス
LangGuardのエンジンは現在、ワークフロー全体で確立されたポリシーを実行時に適用します。次の進化は予測的です。過去のGRAILトレースデータで行動モデルをトレーニングし、ポリシー違反として現れる前に異常なエージェントの行動を検出します。
前述のように、運用トレースデータはすでにDatabricksエコシステム内に存在するため、別のETLパイプラインを構築したり、2番目の分析プラットフォームをセットアップしたりすることなく、実行から予測に直接移行できます。
エージェントが異常な動作を開始したり、確立されたベースラインから逸脱したりすると、それらのモデルは損害が発生する前に異常としてフラグを付けます。リアルタイム実行と予測的機械学習のこの収束は、エンタープライズAIガバナンスの未来であり、今日私たちが構築しているアーキテクチャです。
| KEY TAKEAWAY |
|---|
| LangGuardは、Databricks Lakebase上に本番インフラストラクチャを構築する最初のスタートアップの1つです。この選択は、低レイテンシ実行、弾力的なバースト処理、および実際のデータに対するガバナンスポリシーテスト��という特定の譲れない要件によって推進されました。サーバーレスOLTPデータベースのみがそれらすべてを満たすことができます。Lakebaseは、それらすべてを満たす最初のデータベースです。 |
| エージェント、ツール、資格情報、および記録システムのすべてにわたって、エンドツーエンドでエージェントワークフローを管理する必要がある企業にとって、このアーキテクチャは、ワークフロー速度で動作し、デプロイメントの複雑さに合わせてスケーリングし、別のデータプラットフォームを必要とせずに予測的行動セキュリティへと進化する実行を意味します。 |
エージェントワークフローをエンドツーエンドで管理する準備はできましたか? langguard.aiにアクセスするとLangGuardがエンタープライズエージェントワークフローを完全なポリシーコンプライアンスでどのように保護、制御、および運用するかをご確認できます。またはDatabricks Lakebaseを探索して、サーバーレスOLTPインフラストラクチャが大規模なリアルタイムAIガバナンスをどのように強化するかをご確認ください。
LangGuardの詳細はこちら Databricks Lakebaseを探索する
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。