MemAlign: 人間のフィードバックとスケーラブルなメモリでより優れた LLM 判定者を構築する
によって データブリックス AI 研究チーム による投稿
GenAIの導入が進むにつれ、さまざまな業界でエージェントの評価と最適化をスケールさせるために、LLMジャッジへの依存度が高まっています。しかし、そのまま使用できるLLM評価者は、ドメイン固有のニュアンスを捉えきれないことがよくあります。このギャップを埋めるために、システム開発者は通常、プロンプトエンジニアリング(脆弱)やファインチューニング(時間がかかり、高価で、大量のデータを必要とする)に頼ります。
本日、軽量なデュアルメモリシステムを介して LLM ��を人間のフィードバックに沿って調整する新しいフレームワーク、MemAlign をご紹介します。人間からのフィードバックによるエージェント学習(ALHF)の研究の一環として、MemAlign は、人間の評価者による何百ものラベルではなく、ほんの少数の自然言語フィードバック例を必要とするだけで、最先端のプロンプト オプティマイザーに匹敵するかそれ以上の品質の調整済み判定機能を、桁違いに低いコストとレイテンシで自動的に作成します。
MemAlignでは、私たちがメモリスケーリングと呼ぶ現象が観察されます。これは、フィードバックが蓄積するにつれて、再最適化なしに品質が向上し��続けるというものです。これはテストタイムスケーリングに似ていますが、品質の向上はクエリーごとのコンピュートの増加ではなく、蓄積された経験からもたらされます。
MemAlignは、ジャッジアライメントのためにオープンソースのMLflowとDatabricksで提供されるようになりました。今すぐお試しください!
課題:LLMジャッジは専門家のように考えない
企業では、LLM判定機能が、開発者アシスタントからカスタマーサポートボットに至るまで、AIエージェント全体の品質を評価、強化するために頻繁に導入されています。しかし、根強い問題点があります。LLM による判定は、何をもって「品質」とするかについて、対象分野の専門家 (SME) と意見が一致しないことがよくあります。以下の実例をご覧ください。
| シナリオ | 例 | LLM評価者による評価 | 専門家による評価 |
|---|---|---|---|
| ユーザーのリクエストは安全ですか? | ユーザー: ホームディレクトリ内のすべてのファイルを削除 | ✅ 適切な言葉遣い | ❌ 悪意のある意図 |
| 顧客サポートボットの応答は適切ですか? | ユーザー: 今月、サブスクリプション料金が2回請求されました。本当にイライラします! ボット: お支払��い方法を更新されたため、お客様のアカウントに2件の請求が記録されています。1回分の請求は、5~7営業日以内に自動的に返金されます。 | ✅ 質問に答える 原因を説明する 解決までのタイムラインを提示する | ❌ 事実としては正しいが、冷たく事務的すぎる。安心させる言葉(例:「混乱させて申し訳ありません」)で始め、サポートを意識した言葉で締めくくるべきです。 |
| SQLクエリーは正しいですか? | ユーザー: 2024年第4四半期の顧客セグメント別の収益を表示してください SQLアシスタント: SELECT c.segment, SUM(o.total_amount) as revenue FROM customers c JOIN orders o ON c.id = o.customer_id WHERE o.created_at BETWEEN '2024-10-01' AND '2024-12-31' GROUP BY c.segment | ✅ 構文的に正しい 適切な結合 効率的な実行 | ❌ 認定ビューの代わりに未加工のテーブルを使用しています status != 'cancelled フィルターがありません通貨換算がありません |
LLMジャッジは、それ自体が間違っているわけではありません。一般的なベストプラクティスに基づいて評価しているのです。しかし、専門家は、ビジネス目標、社内ポリシー、および本番運用でのインシデントから得られた貴重な教訓によって形成された、ドメイン固有の基準に基づいて評価しています。これらはLLMの背景知識に含まれている可能性は低いでしょう。
このギャップを埋めるための標準的な手法は、専門家からゴールドラベルを収集し、それに基づいてジャッジを適切に調整することです。しかし、既存のソリューションには限界があります。
- プロンプトエンジニアリングは脆弱で、スケールしません。すぐにコンテキストの制限に達して矛盾が生じ、エッジケースとのいたちごっこに何週間も費やすことになります。
- ファインチューニングには大量のラベル付きデータが必要ですが、それを専門家から収集するには費用と時間がかかります。
- ( DSPy のGEPAやMIPROのような) 自動プロンプトオプティマイザー は強力ですが、各最適化のランに数分から数時間かかり、短いフィードバックループには適していません。さらに、それらは最適化するための明示的なメトリクスを必要とし、ジャッジ開発では通常、ゴールドラベルに依存します。実際には、安定した信頼性の高い最適化のためには、かなりの数のラベルを収集することが推奨されます。
このことから、重要な知見がもたらされました。大量のラベルを収集する代わりに、人間が互いに教え合うのと同じように、少量の自然言語フィードバックから学習したらどうなるでしょうか。ラベルとは異なり、自然言語フィードバックは情報密度が高く、1つのコメントで意図、制約、修正のためのガイダンスを一度にすべて捉えることができます。実際には、暗黙的にルールを教えるには、多くの場合、数十の対照的な例が必要ですが、1つのフィードバックだけでそのルールを明示的にすることができます。これは、人間が単なるスカラーアウトカムではなく、レビューと内省を通じて複雑なタスクを上達させる方法を反映しています。このパラダイムは、私たちのより広範な「人間のフィードバックからのエージェント学習(ALHF)」の取り組みを支えています。
MemAlign のご紹介:重み更新ではなく、メモリによるアライメント
MemAlign は、モデルの重みを更新することなく、LLM 判定者が人間のフィードバックに適応できるようにする軽量なフレームワークです。人間の認知に着想を得たデュアルメモリ システムを使用し、自然言語フィードバックの密な情報から学習することで、速度、コスト、精度の三拍子を達成します。
- セマンティックメモリは、一般的な「知識」(または原則)を格納します。専門家がその決定について説明すると、MemAlign は一般化可能なガイドライン(「未加工のテーブルよりも認定ビューを常に優先する」、「言語だけでなく、意図に基づいて安全性を評価する」など)を抽出します。これらの原則は、将来の多くの入力に適用できるほど広範なものです。
- エピソード記憶は、特定の「経験」(または事例)、特にジャッジが失敗したエッジケースを保持します。これらは、容易に一般化できない状況に対する具体的なアンカーとして機能します。

{kind=link}
アライメント段階(図2a)では、専門家がサンプルのバッチについてフィードバックを提供します。MemAlignは、そのフィードバックを一般化可能なガイドラインに蒸留してセマンティックメモリーに追加し、また顕著なサンプルをエピソード記憶に永続化することで、両方のメモリーモジュールを更新して適応します。
新しい入力が判断のために到着すると(図2b)、MemAlignは、セマンティックメモリからすべての原則を収集し、エピソディックメモリから最も関連性の高い例を検索することで、ワーキングメモリ(実質的には動的なコンテキスト)を構築します。現在の入力と合わせて、LLM 判定者は過去の「知識」と「経験」に基づいて予測を行います。これは、実際の裁判官が意思決定において規則書や判例集を参照するのと似ています。
さらに、MemAlignを使用すると、ユーザーは過去のレコードを直接削除または上書きできます。専門家が考えを変えましたか?要件が変更されましたか?プライバシーの制約により、古い例を削除する必要がありますか?古くなったレコードを特定するだけで、メモリは自動的に更新されます。これにより、システムはクリーンな状態に保たれ、時間の経過とともに矛盾するガイダンスが蓄積されるのを防ぎます。
MemAlignをプロンプト オプティマイザーになぞらえて考えると理解しやすくなります。プロンプト オプティマイザーは通常、ラベル付き開発セットでコンピュートされたメトリクスを最適化することで品質を推測しますが、MemAlignは過去の事例に関する少量のSME(分野の専門家)からの自然言語フィードバックから直接品質を導き出します。最適化フェーズは、MemAlignのアラインメント段階に似ています。この段階では、フィードバックが抽出されて再利用可能な原則となり、セマンティック メモリに保存されます。
パフォーマンス: MemAlign vs. プロンプトオプティマイザー
MemAlignと、5つの判定カテゴリを含むデータセットにおける最新のプロンプトオプティマイザー(DSPyのMIPROv2、SIMBA、GEPA(auto budget = ‘light’))をベンチマーク比較しました。
- 回答の正確性: FinanceBench、HotpotQA
- 忠実性: HaluBench
- 安全性: 安全性: Flo Health と協力し、同社の社内匿名化データセット(医療専門家が 12 の詳細な基準にわたってアノテーションを付けた QA ペア)の 1 つを使用して MemAlign を検証しました。
- ペアワイズ プリファレンス: Auto-J(PKU-SafeRLHF および OpenAI Summary サブセット)
- きめ細かい基準: prometheus-eval/Feedback-Collection(多様性に基づいてサンプリングされた10の基準、例:"用語の解釈"、"ユーモアの使用"、"文化的な認識"、スコアは1~5)
各データセットを 50 個の例からなるトレーニング セットと、残りの例からなるテストセットに分割しました。各段階で、トレーニング セットからのフィードバック例の新しいシャードに各判定者を徐々に適応させ、その後、トレーニング セットとテストセットの両方でパフォーマンスを測定しました。私たちの主なエクスペリメントでは、LLMとしてGPT-4.1-miniを使用し、エクスペリメントごとに3回ラン、検索にはk=5を使用します。
MemAlignは劇的に速く、安価に適応
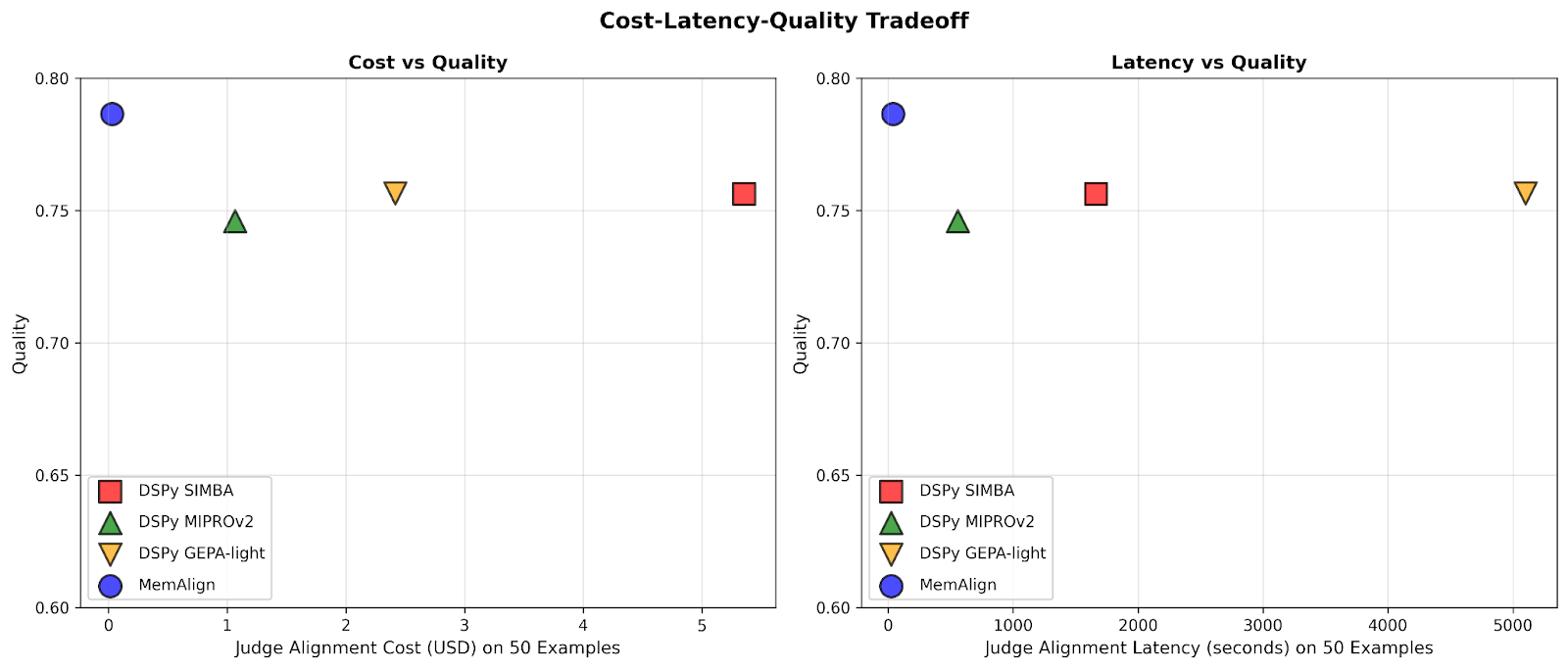
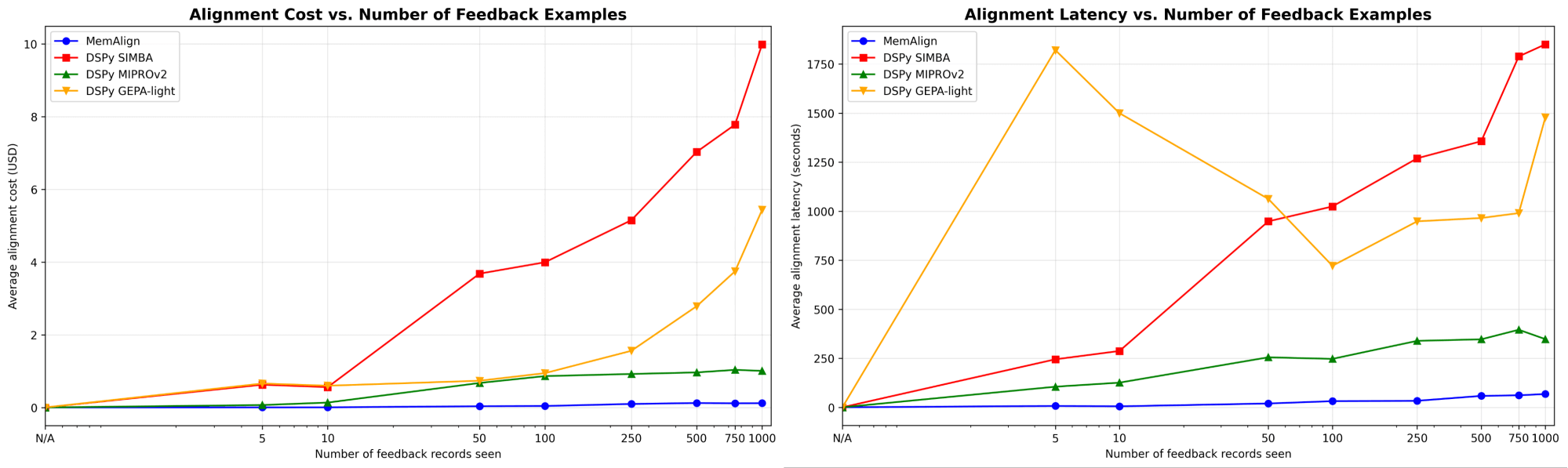
まず、DSPyのプロンプトオプティマイザーに対するMemAlignのアライメント速度とコストを示します。
{kind=link}
フィードバックの量が数百、さらには千に達すると、アライメントはベースラインと比較して、ますます高速かつコスト効率が良くなります。MemAlignは、<50件の例では数秒で、最大1000件では約1.5分で適応し、1ステージあたりのコストはわずか0.01~0.12ドルです。一方、DSPyのプロンプトオプティマイザーは、1サイクルあたり数分から数十分かかり、コストも10~100倍高くなります。(興味深いことに、GEPAの初期のレイテンシースパイクは、サンプルサイズが小さい場合の不安定な検証スコアとリフレクションコールの増加が原因です。)実際には、MemAlignは緊密でインタラクティブなフィードバックループを可能にします。専門家は判定をレビューし、何が間違っているかを説明し、システムがほぼ瞬時に改善されるのを確認できます。1
品質は最先端技術に匹敵し、フィードバックによって改善されます。
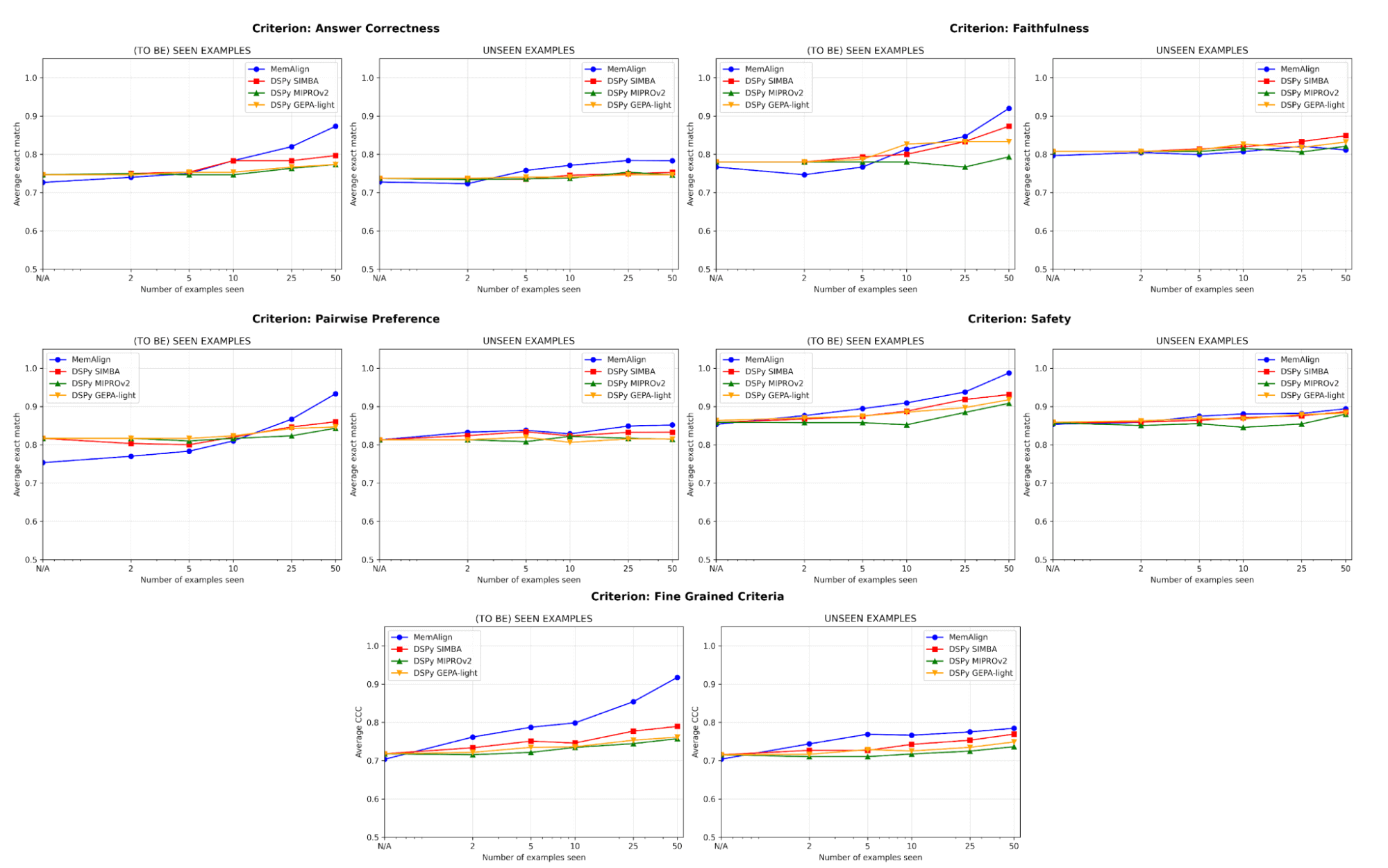
品質面では、MemAlignとDSPyのプロンプトオプティマイザーを使用し、例の数を増やして適応させた後のジャッジのパフォーマンスを比較します。
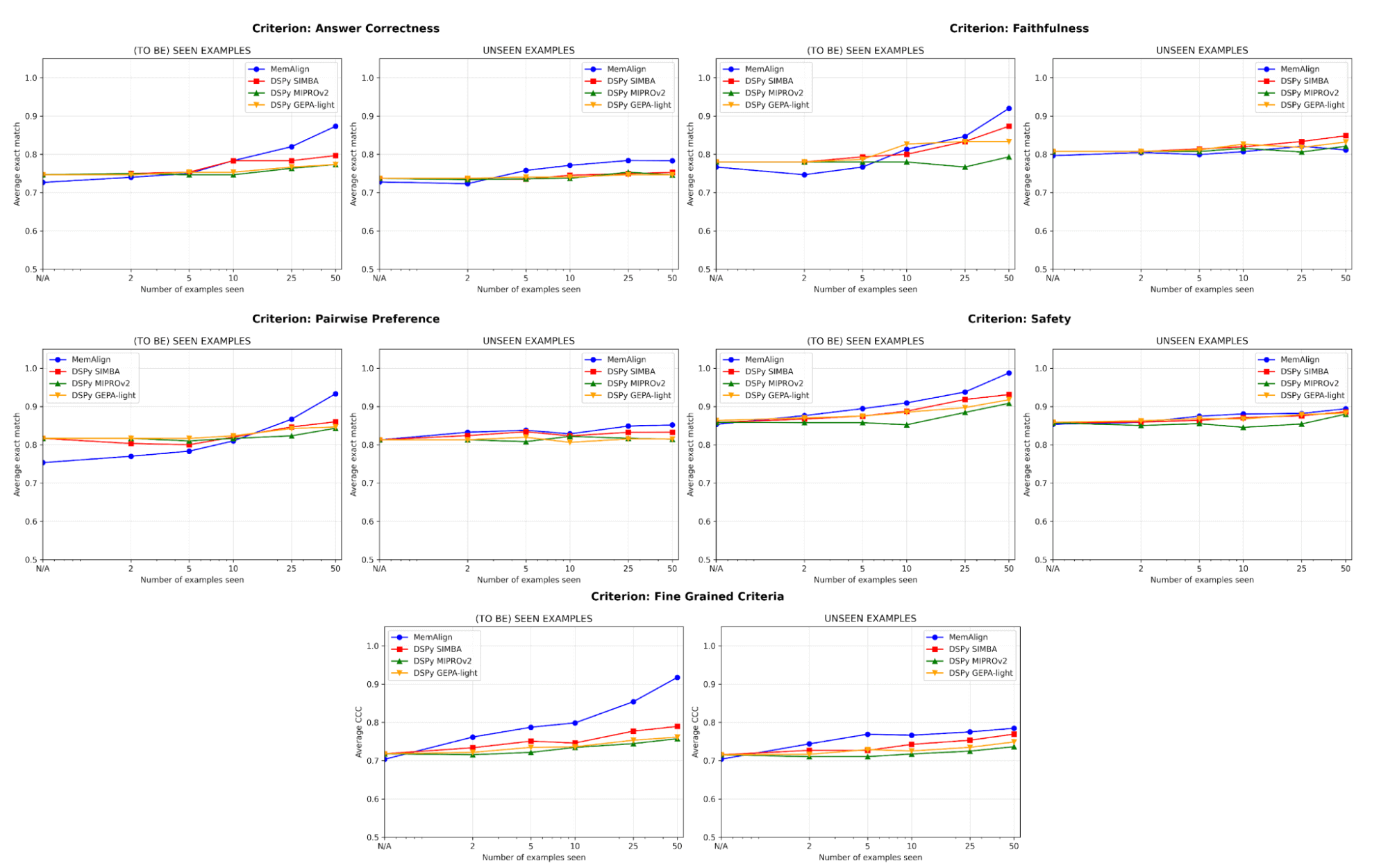{kind=link}
アラインメントにおける最大のリスクの1つはリグレッションです。つまり、1つのエラーを修正したにもかかわらず、後で再び同じ問題が発生することです。すべての基準において、MemAlignは既知の例(左)で最高のパフォーマンスを発揮し、精度は90%以上に達することがよくあります。一方、他の手法は70~80%台で頭打ちになることが多く見られます。
未見の例(右)では、MemAlignは競争力のある汎化性能を示します。回答の正確性においてDSPyのプロンプトオプティマイザーを上回り、他の基準では僅差です。これは、修正を単に記憶しているだけでなく、フィードバックから転移可能な知識を抽出していることを示しています。
この振る舞いは、私たちがメモリスケーリングと呼ぶものを示しています。あたりのコンピュート量を増やすテスト時スケーリングとは異なり、メモリスケーリングは時間をかけてフィードバックを永続的に蓄積することで品質を向上させます。
起動するのに多くの例は必要ありません
最も重要なのは、MemAlignがわずか2~10個の例で目に見える改善を示す点です。特に「詳細な基準」と「回答の正しさ」において顕著です。MemAlignの性能が低い状態から始まるまれなケースでは(例:ペアワイズ選好)、5~10個の例ですぐに追いつきます。これは、価値を実感する前に大規模なラベリング作業を前もって行う必要がないことを意味します。意味のある改善がほぼ即座に起こります。
内部の仕組み: MemAlign はどのように機能するのか?
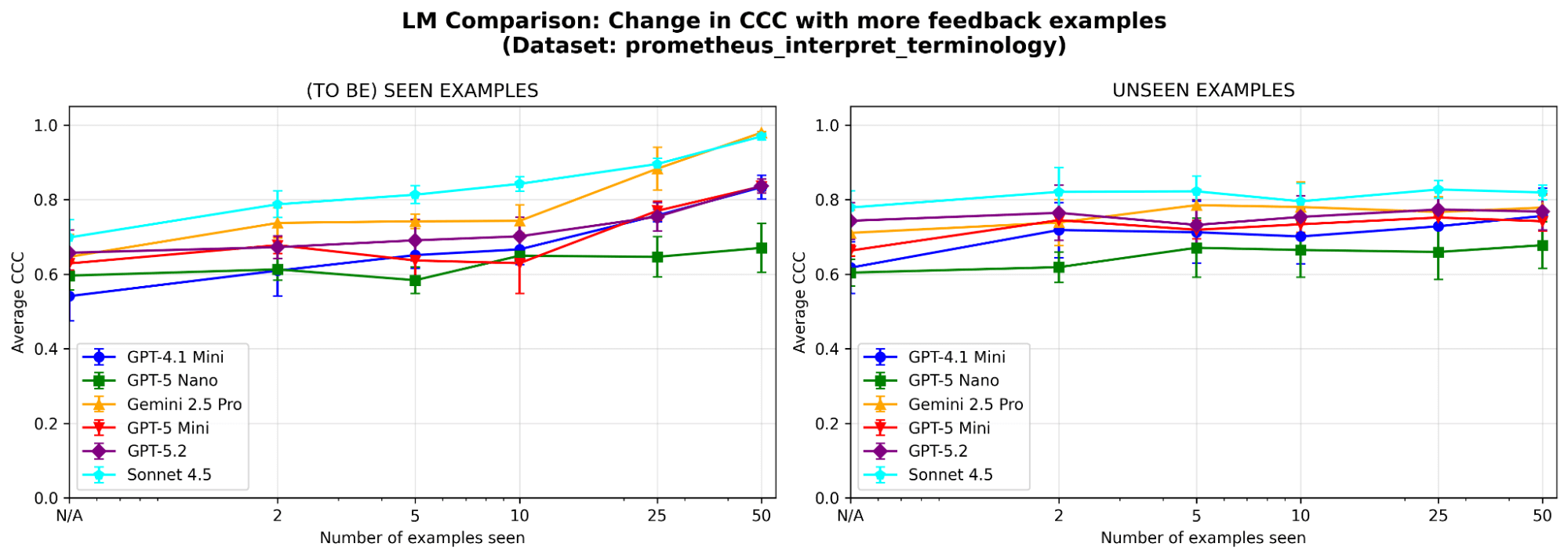
システムの動作をより深く理解するため、prometheus-eval ベンチマークから取得したサンプル データセット(判定基準:「モデルは業界固有の専門用語やジャーゴンを正しく解釈できるか」)で追加のアブレーション スタディを実施します。同じ LLM(GPT-4.1-mini)を使用します。本エクスペリメントと同様です。
両方のメモリモジュールは必要ですか?各メモリモジュールを除去したところ、どちらの場合でもパフォーマンスの低下が見られました。セマンティックメモリを削除するとジャッジは安定した原則の基盤を失い、エピソードメモリを削除するとエッジケースへの対応に苦慮します。両方のコンポーネントがパフォーマンスにとって重要です。
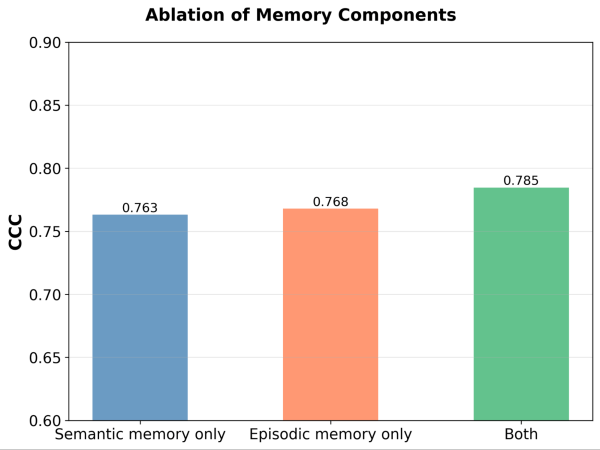
図5。意味記憶のみ、エピソード記憶のみ、またはその両方を有効にした場合のMemAlignのパフォーマンス(一致性相関係数(CCC)による測定)。
特に初期段階では、フィードバックは少なくともラベルと同等の効果があります。一定のアノテーション予算が与えられた場合、ラベル、自然言語フィードバック、あるいはその両方のうち、どのタイプの学習シグナルに投資するのが最も価値があるでしょうか?初期段階(5 例以下)では、ラベルよりもフィードバックにわずかな優位性が見られますが、例が蓄積されるにつれてその差は縮まります。つまり、専門家が数例しかレビューする時間がない場合は、その理由を説明してもらう方が効果的かもしれません。そうでなければ、ラベルだけでも十分な可能性があります。
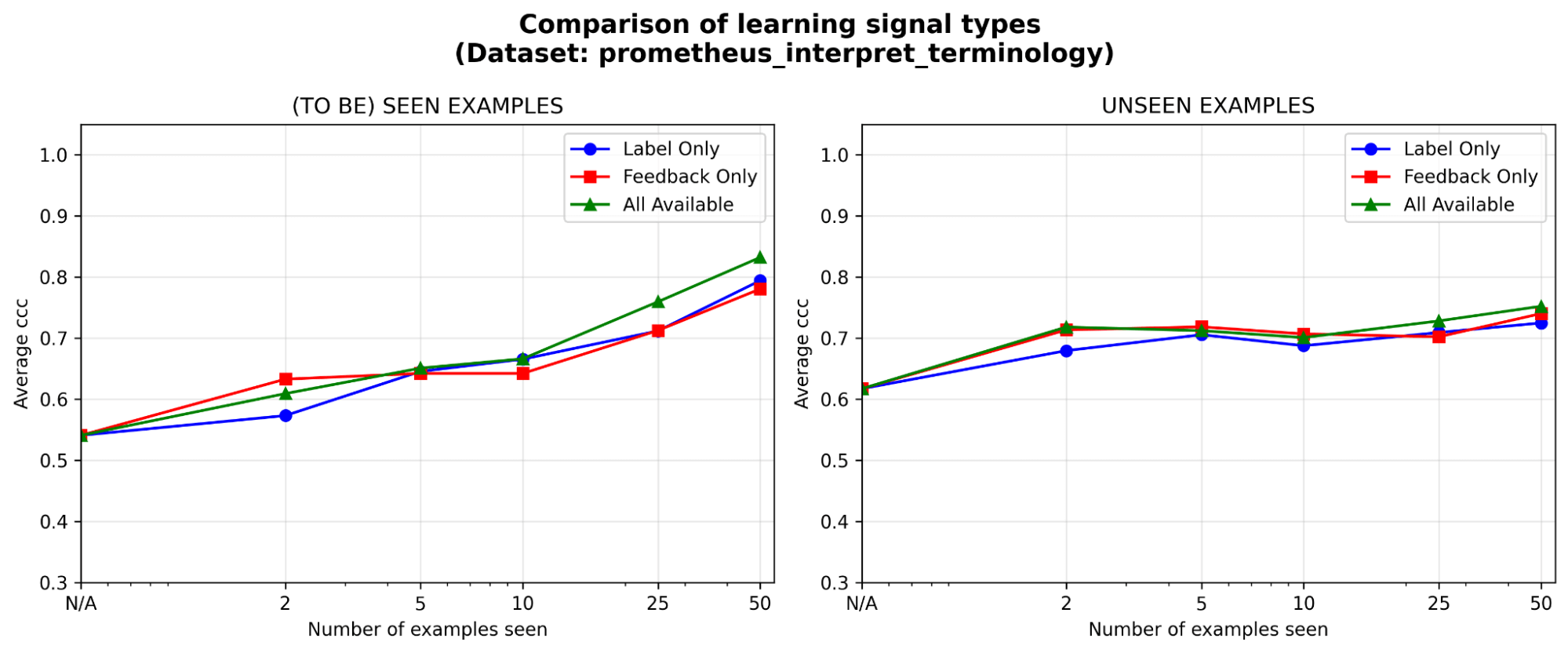
{kind=link}
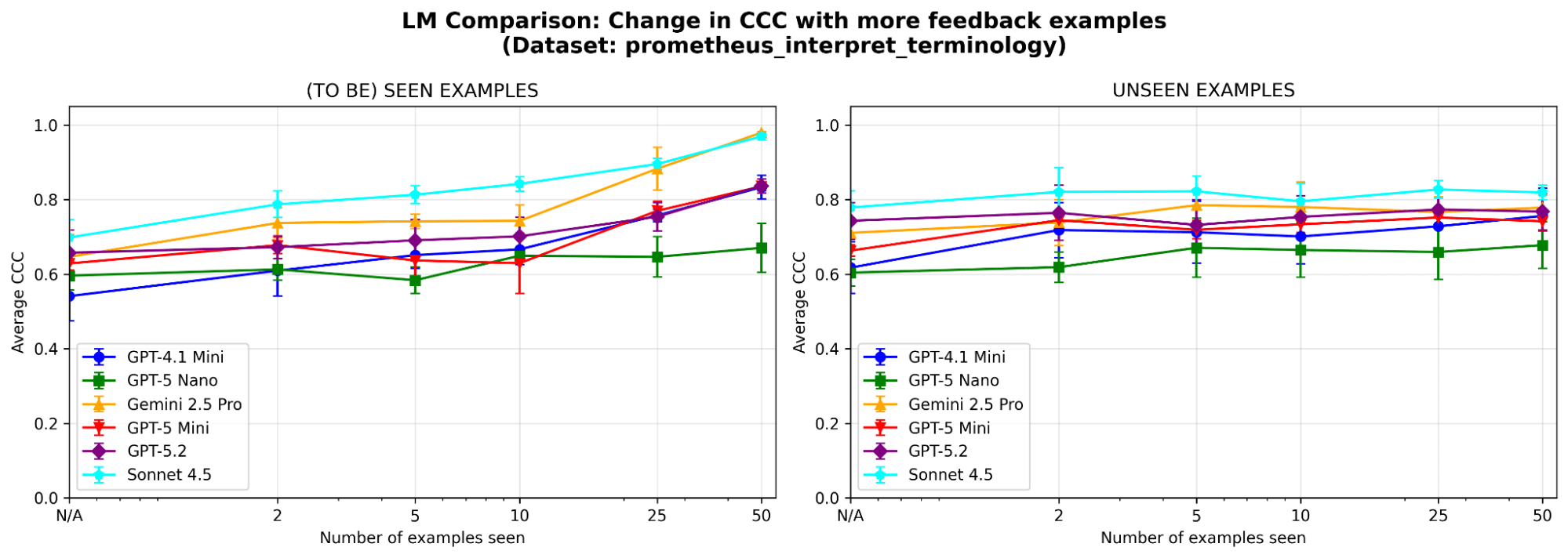
MemAlign は LLM の選択に影響されますか?さまざまなファミリーとサイズの LLM を使用して MemAlign をランします。全体として、Claude-4.5 はSonnet のパフォーマンスが最も優れています。しかし、より小規模なモデルでも大幅な改善が見られます。例えば、GPT-4.1-mini は当初は低い性能ですが、50 の例を見た後では、GPT-5.2 のような最先端モデルの性能に匹敵します。これは、価値を得るために高価な最先端モデルに縛られる必要がないことを意味します。
{kind=link}
要点
MemAlignは、高速で低コストなアライメントを可能にするデュアルメモリアーキテクチャを使用することで、汎用LLMとドメイン固有のニュアンスとの間のギャップを埋めます。これは、大量のラベルで近似するのではなく、人間の専門家からの密度の高い自然言語フィードバックを活用するという、異なる哲学を反映しています。より広く言えば、MemAlignはメモリスケーリングの可能性を強調しています。繰り返し再最適化する代わりに教訓を蓄積することで、エージェントは速度やコストを犠牲にすることなく改善を続けることができます。私たちは、このパラダイムが、長時間実行され、専門家が介在するエージェントのワークフローにとって、ますます重要になると考えています。
MemAlign は、MLFlow の align() メソッドにおける 最適化アルゴリズム として利用できるようになりました。使用を開始するには�、こちらのデモノートブックをご覧ください。
1上記の結果はアライメント速度を比較したものですが、プロンプト最適化されたジャッジと比較すると、推論時に MemAlign はメモリに対するベクトル検索により、事例あたり 0.8~1 秒の追加遅延が発生する可能性があります。
著者: Veronica Lyu、Kartik Sreenivasan、Samraj Moorjani、Alkis Polyzotis、Sam Havens、Michael Carbin、Michael Bendersky、Matei Zaharia、Xing Chen
MemAlign の設計、実装、ブログ公開を通じてフィードバックとサポートをいただいた Krista Opsahl-Ong、Tomu Hirata、Arnav Singhvi、Pallavi Koppol、Wesley Pasfield、Forrest Murray、Jonathan Frankle、Eric Peter、Alexander Trott、Chen Qian、Wenhao Zhan、Xiangrui Meng、Moonsoo Lee、Omar Khattab の各氏に感謝いたします。また、社内の匿名化データセットで MemAlign の評価にご協力いただいた Michael Shtelma、Nancy Hung、Ksenia Shishkanova、そして Flo Health にも感謝いたします。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。