あらゆるエージェント、あらゆる場所でのオブザーバビリティ:Databricks上のOpenTelemetryとUnity Catalogによる本番環境対応のトレーシング
Unity CatalogのOpenTelemetryトレースは、分析、評価、監視を通じてAIエージェントの継続的改善のフライホイールを作成します。
によって フィラス・ファラー, Bruno Faria 、 Anoop Sunke による投稿
- 問題点:AIエージェントは大量のトレースデータを生成しますが、従来のオブザーバビリティツールでは、そのデータの保持にコストがかかり、ガバナンスが難しく、評価や分析ワークフローでの利用が困難です。
- 解決策:Databricksは、完全に管理されたサーバーレスの取り込みパスを通じて、OpenTelemetry (OTel) トレースを直接Unity Catalogテーブルに書き込むことをサポートするようになりま��した。
- 利点:トレースをレイクハウスに直接取り込むことで、チームはガバナンスされ、分析に対応可能なオブザーバビリティデータを、長期保持、統合された評価および監視ワークフロー、そして運用すべきOTelインフラストラクチャなしで利用できるようになります。
- 結果:本番環境のトレースは、分析および評価にすぐに利用可能になり、実際の使用状況、モデル評価、継続的な改善との間の迅速なイテレーションループを可能にします。
AIトレーシングが従来のオブザーバビリティを阻む理由
AIアプリケーションが本番環境に移行するにつれて、プロンプト、ツール呼び出し、応答、レイテンシ、実行パスをキャプチャすることで、エージェントの実際の動作を理解するための最も明確な方法の1つがトレースになります。強力なトレーシングがなければ、エージェントがそのように動作する理由を理解することは困難であり、デバッグ、評価、ガバナンスがはるかに困難になります。
AIトレースは、従来のデバッグやオブザーバビリティのユースケースを超えて、分析、評価、監視ワークフローにとってすぐに価値のあるものになります。チームはそれらをより長く保持し、SQLで分析し、ビジネスデータやモデルデータと結合し、評価や監視に再利用したいと考えています。トレースがオブザーバビリティシステム内にのみ存在する場合、その柔軟性は制限され、ガバナンスは断片的になり、分析ワークフローにデータを移動するには、特に機密性の高いプロンプトデータが関わる場合、追加のパイプラインと重複が必要になることがよくあります。
OTelトレースの取り込み
Databricksは、OpenTelemetry(OTel)形式を使用して、OTelトレースを直接Unity Catalogに書き込むことをサポートするようになりました。実際には、これはトレースをリアルタイムで取り込み、Deltaテーブルに保存できることを意味します。そこでは、他のすべてのデータと同じスケーラビリティ、ガバナンス、およびツールからメリットを得られます。
これにより、チームはトレースデータを次のように使用できるようになります。
- 実用的な保持期間でのリアルタイム取り込み:トレースは、高スループットで生成されると同時に書き込むことができ、オブザーバビリティプラットフォームに典型的に関連付けられるコスト圧力なしに長期にわたって保持できます。
- レイクハウスを使用した分析とガバナンス:トレースがテーブルに取り込まれると、他のデータセットと同じように扱うことができます。SQLでクエリを実行したり、ダッシュボードを構築したり、ETLパイプラインを実行したり、Genieのようなツールを使用したり、PIIマスキングなどのガバナンスコントロールを適用したりできます。
- 完全なMLflow評価スタックの使用:MLflowを使用すると、デバッグのためにトレースを簡単に検索、フィルタリング、およびドリルダウンできます。Unity Catalogにトレースを永続化することで、典型的な実験の制約(トレースキャップなど)が解消され、大規模なオフライ�ン評価の実行、本番システムの監視、およびワークロードの成長に伴う品質の継続的な改善が容易になります。
SaaS vs. レイクハウス
では、なぜSaaSオブザーバビリティツールに完全に依存しないのでしょうか。
- 保持の経済性:エージェントは大量のテキストペイロードを生成します。このデータをオブジェクトストレージ上のDelta Lakeに保存することは、SaaSベースの保持モデルよりも大幅にコスト効率が高いことがよくあります。
- PIIのデッドロック:生のプロンプトをサードパーティプラットフォームに送信すると、InfoSecの摩擦が生じる可能性があります。トレースをUnity Catalog内に保持することで、データ主権を維持し、ガバナンスを簡素化できます。
- 分析、テレメトリだけではない:SaaSツールはレイテンシのような運用メトリックには強力ですが、レイクハウスは分析エンジンを提供します。トレースを収益やコンバージョンなどのビジネスデータと結合して、実際のインパクトを理解し、システムヘルスを超えていくことができます。さらに、レイクハウスを使用すると、AIをトレースに直接適用したり、評価フレームワークを構築してシステム品質を継続的に改善したりできます。
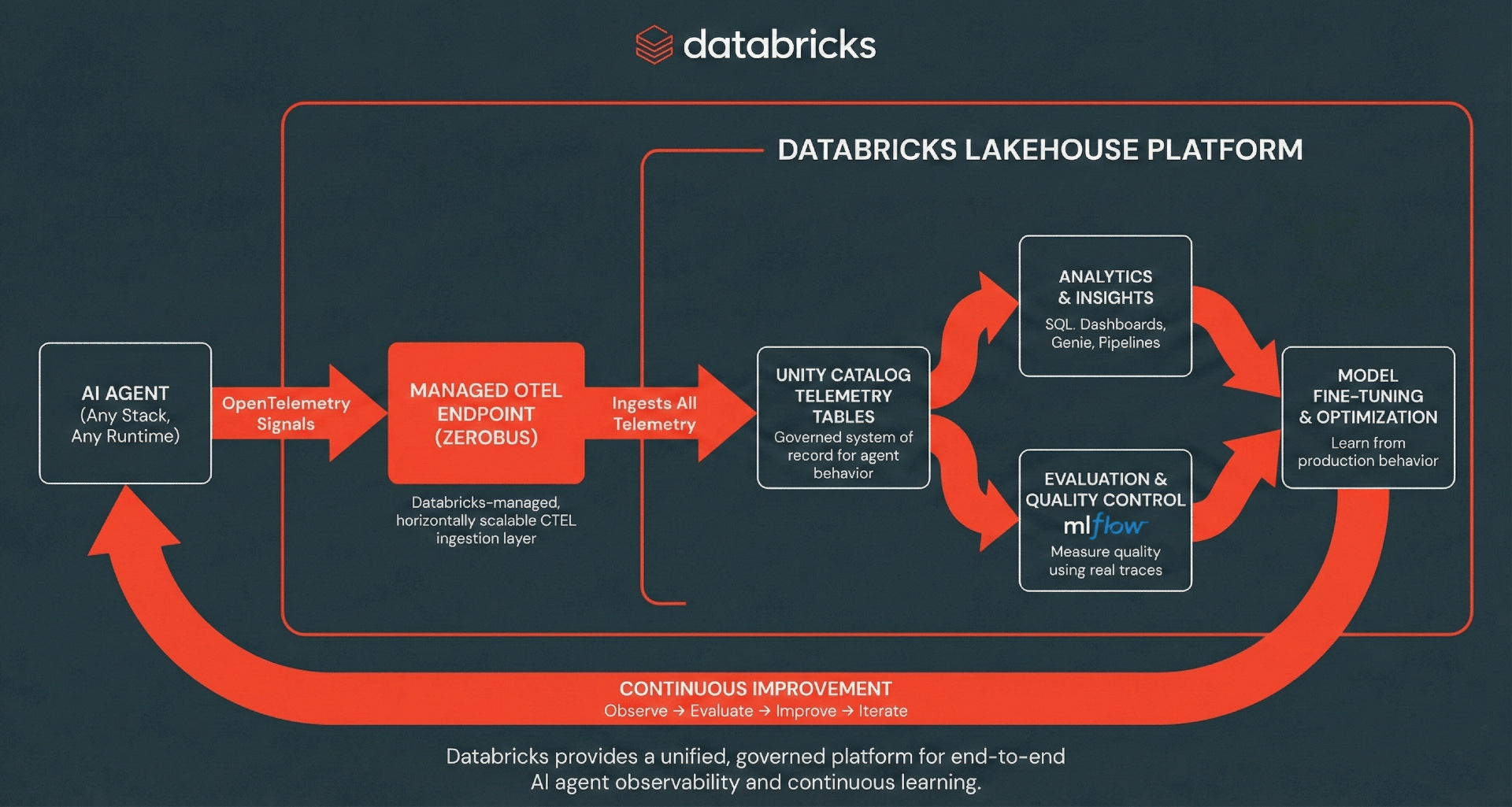
アーキテクチャ:サーバーレスOpenTelemetry取り込み
Databricksは、OTel標準を使用してインストルメンテーションとストレージを分離することにより、OpenTelemetry(OTel)トレース、ログ、およびメトリックをUnity Catalogテーブル�に直接取り込むことをサポートしています。
Databricksは、Zerobus Ingestによって透過的に強化されたマネージド取り込みレイヤーを提供することにより、従来のマルチホップテレメトリパイプラインの運用上の複雑さを解消します。Zerobus Ingestは、オープンソースコレクタ経由で標準OpenTelemetryプロトコル(OTLP)をネイティブにサポートする完全にマネージドなサーバーレス取り込みエンジンとして機能し、REST API機能はMLflowのようなアプリケーションフレームワークとのシームレスな統合を可能にします。アプリケーションは、スパン、ログ、メトリックを直接Unity Catalogテーブルにエクスポートできます。そこでは、データはDelta形式で保存されます。「シングルシンク」アーキテクチャにより、Zerobus Ingestはテレメトリデータをレイクハウスに直接ストリーミングすることでオブザーバビリティを簡素化します。既存のOLTP互換コレクタは、Kafkaのような中間メッセージバスを完全にバイパスして、gRPC経由でこのエンドポイントに直接ポイントできます。Zerobus Ingestは、インフラストラクチャのオーバーヘッドなしで取り込みと永続性を処理する高スループットテレメトリパイプラインとして機能します。OTel互換クライアントであれば、多くのプログラミング言語にわたる一般的なAIエージェントフレームワークを含む、このエンドポイントにトレースをエクスポートできます。
そこから、トレース、ログ、メトリックはレイクハウスのファーストクラスデータとなり、アドホックSQL分析、ダッシュボード、ダウンストリーム分析、およびMLflow評価と監視ワークフローを強化します。テレメトリを統合することで�、本番の動作が評価と分析にフィードバックされ、それがより迅速なイテレーションとより良いエージェントパフォーマンスを促進する継続的な改善フライホイールが作成されます。
チュートリアル:トレースをレイクハウスに配線する
サンプルエージェント:サポートマネージャーアシスタント
このブログでは、エンドツーエンドのトレーシングを実証するために使用できるシンプルなサポートマネージャーアシスタントを作成します。エージェントは、ここで示したように、Databricksの外部にデプロイできます。これにより、トレース取り込みがエージェントの実行場所から分離されていることが強調されます。
推論と応答生成のためにDatabricksホストのClaude Sonnet 4.6モデルを搭載したLangGraphエージェントを構築しました。エージェントはGenie Spaceをツールとして呼び出します。これは、ここでデプロイできま�す。
ユーザーがデータ駆動型の質問をすると、エージェントはMCPツールAPIを介してGenieを呼び出します。GenieはリクエストをSQLに変換し、サポートデータセットに対して実行し、結果を返します。その後、エージェントは調査結果を要約し、サポートマネージャーに実行可能な洞察を提供します。

OTelトレーシングをUCでセットアップする
エージェントのインストルメンテーションを行う前に、まずOpenTelemetryトレースを格納するUC内のテーブルを構成します。この例では、MLflowを使用してUnity Catalogに基盤となるOpenTelemetryテーブルを作成し、それらをMLflow実験にリンクして、トレースをUIから検索、分析、および注釈付けできるようにします。まず、SQLウェアハウスとMLflow実験を特定(または作成)し、次にMLflow Pythonライブラリを使用してUnity Catalogテーブルをプロビジョニングし、スキーマを実験に関連付けます。完全な手順については、こちらのドキュメントに従ってください。
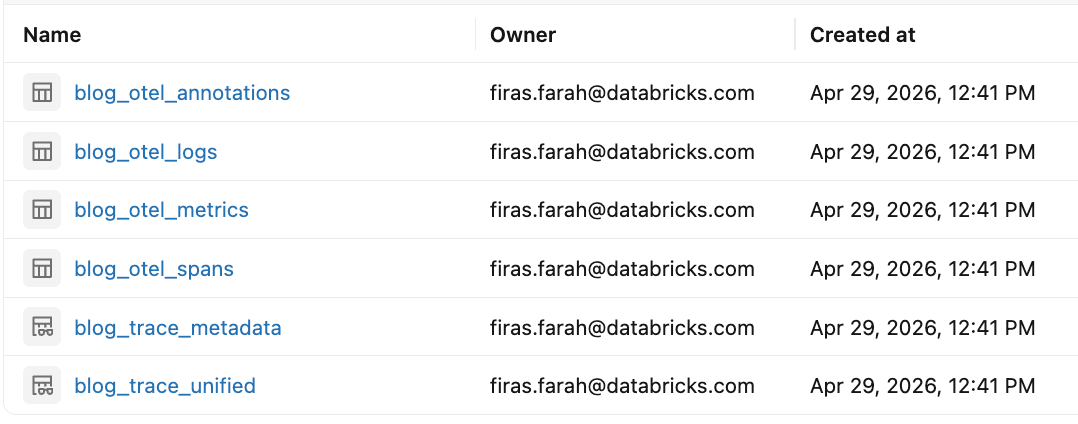
このセットアップにより、OpenTelemetryスパン、ログ、メトリック用のUnity Catalogテーブルが作成されます。基盤となるデータはOpenTelemetry準拠のテーブル形式で保存され、MLflowサービスはそれらとともにDatabricks SQLビューを自動的に作成します。これらのビューは、OpenTelemetryデータをMLflowフレンドリーな形式に変換して、クエリと分析を容易にします。これらには以下が含まれます。
<table_prefix>_otel_spans: 各リクエストの詳細なスパンレベルの実行データ<table_prefix>_otel_logs: 実行中にキャプチャされた構造化ログ/イベントデータ<table_prefix>_otel_metrics: 実行中にキャプチャされた数値テレメトリ<table_prefix>_otel_annotations: メタデータ、タグ、評価/フィードバック、期待値、実行リンクなど、標準OTelシグナルではないMLflow固有のトレースデータ<table_prefix>_trace_unified: 生のスパンデータとトレースメタデータを含む、トレースデータを1つのトレースあたり1つのレコードにまとめた統合ビュー<table_prefix>_trace_metadata: MLflowタグ、メタデータ、評価結果をトレースIDごとにグループ化。MLflowトレースメタデータのみが必要な場合に、統合ビューよりも高パフォーマンスです。- どの種類の要求がエスカレーションを必要としますか?
- ツールのリトライは増加していますか?
- どのクエリが最も複雑な実行パスをトリガーしますか?
�実験の設定後、エージェントのインストルメンテーションは変わりません。OTel互換のインストルメンテーションライブラリであれば、設定されたエンドポイントにトレースをエクスポートできます。自動および/または手動トレースは、こちらで説明されているように実行できます。この例では、LangGraphの詳細な実行(モデル呼び出しとツール呼び出し)をキャプチャするためにmlflow.langchain.autolog()に依存しています。また、リクエストレベルのルートスパンを確立するためにエントリポイントを@MLflow.traceでラップしており、各呼び出しを単一のエンドツーエンド実行として観測できるようにしています。
トレースサンプルの検査
エージェントがインストルメントされ、トレースがUnity Catalogに流れ込むようになったので、実際の実行を見てみましょう。
この例では、サポートマネージャーアシスタントに次のように尋ねました。
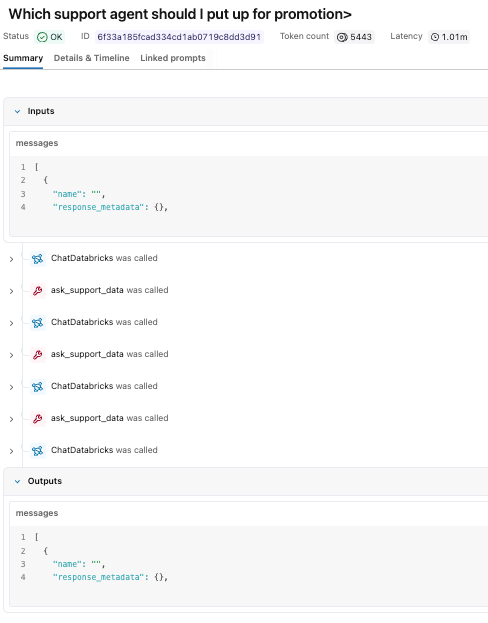
「昇進させるべきサポートエンジニアは誰ですか?」
エージェントはリクエストを評価し、サポートデータを収集するためにGenieスペースに複数回呼び出しを行い、パフォーマンスメトリクスに基づいて推奨事項を返しました。

応答は単純に見えますが、トレースはそれを生成した根本的な実行パスを明らかにします。MLflow実験では、各ツール呼び出しとClaude Sonnetモデルの推論ロジックを確認できます。最終的な回答をまとめる前に、Genieスペースツールを3回呼び出したことがわかります。
個々のステップをドリルダウンして、入力と出力を調査できます。
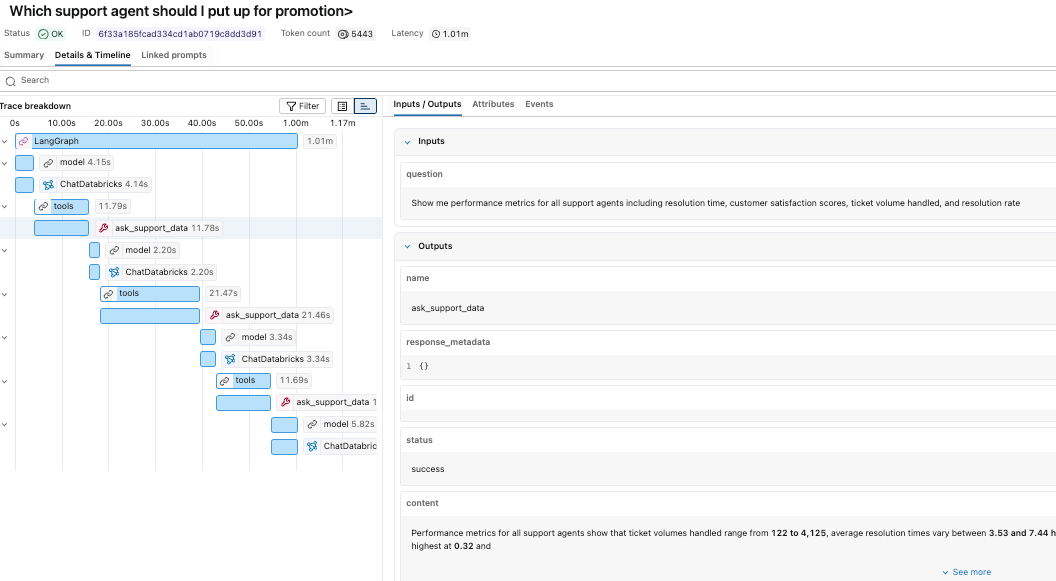
トレースはDeltaテーブルとして保存されているため、他のデータセットと同様にクエリできます。mlflow_experiment_trace_unifiedビューから始めることができます。ここには、リクエスト、レスポンス、トレースメタデータ、およびスパンの配列を含むレコードがあります。
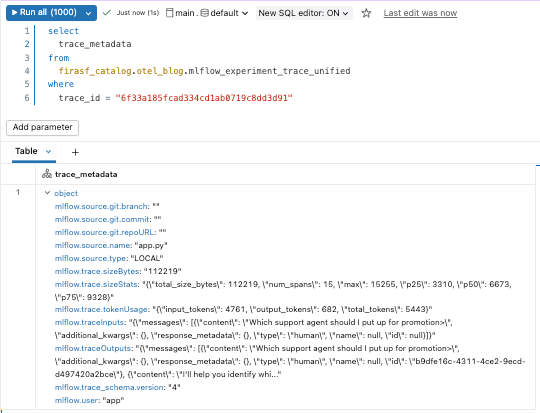
デバッグを超えて:トレースデータのアナリティクス
トレースがUnity Catalogに保存されると、バッチおよびストリーミングアナリティクスですぐに利用できるようになります。
Unity Catalogでのガバナンス
しかし、プロンプトとレスポンスには機密情報が含まれることが多いため、トレースデータをガバナンスされたデータとして扱うことが重要です。Unity Catalogに保存することで、トレースはカタログとスキーマの権限から列マスキングや行レベルフィルタリングまで、きめ細かなアクセス制御を継承し、柔軟性を制限することなく安全な本番対応のアナリティクスを可能にします。
アクセスが確立されたら、チームは上記のようにSQLで基盤となるテーブルやビューをクエリして、安全にアドホックアナリティクスを実行できます。また、アクション可能なビジネスインサイトのために、ダッシュボードやGenieスペースに加えてETLパイプラインを構築することもできます。
ダッシュボード
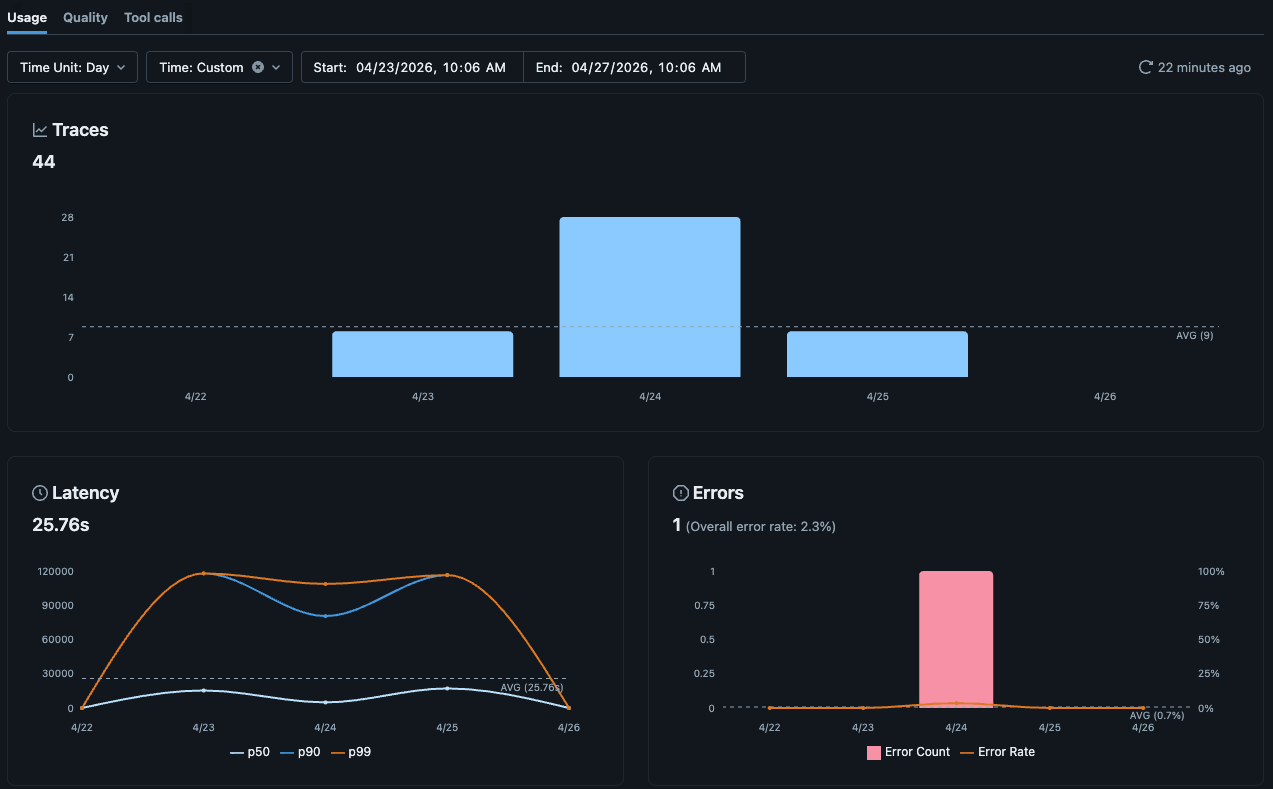
MLflow Experiment UIには、Unity Catalogのトレース用のネイティブオブザーバビリティダッシュボードが付属しており、トレース量、エラー、レイテンシ、トークン使用量、コストのビューが含まれています。ほとんどのチームにとって、これは日常的なエージェントの健全性を監視するのに十分です。
ネイティブビジュアルを超えるビューが必要な場合でも、トレーステーブルは依然としてUnity Catalog内のDeltaテーブルです。カスタムAI/BIダッシュボードをそれらに対して構築し、標準SQL(AIの助けを借りて)を記述して、チームが関心のあるものをモデル化できます。
カスタムダッシュボードがネイティブビューにどのように追加できるかを示すために、トレーステーブル上にAIオペレーションセンターを構築しました。以下に言及する価値のあるいくつかの機能を示します。
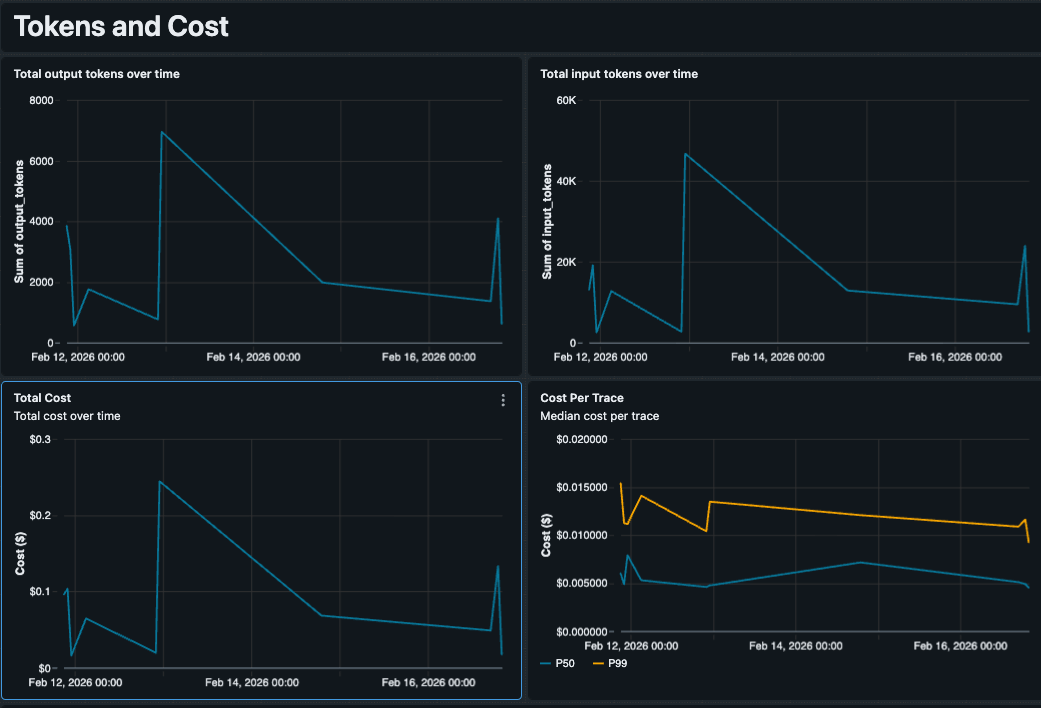
契約価格設定によるカスタムコスト分析
ネイティブコストメトリクスは標準リスト価格に依存していますが、交渉済みレートがあるチームや、異なる価格設定でファインチューニングされたモデルを実行するチームにとっては不正確になる可能性があります。SQLを制御しているため、価格設定ロジックをクエリに直接埋め込みました。ダッシュボードは、モデルタイプ(例:GPT 5.5 vs. Claude 4.6 Sonnet)ごとのトークン使用量を追跡し、契約レートを適用して、実際に支払うものを反映したトレースごとの推定コストを生成します。これにより、検索ループのために単一の複雑なクエリが0.50ドルかかるような、高価な外れ値を簡単に検出できます。
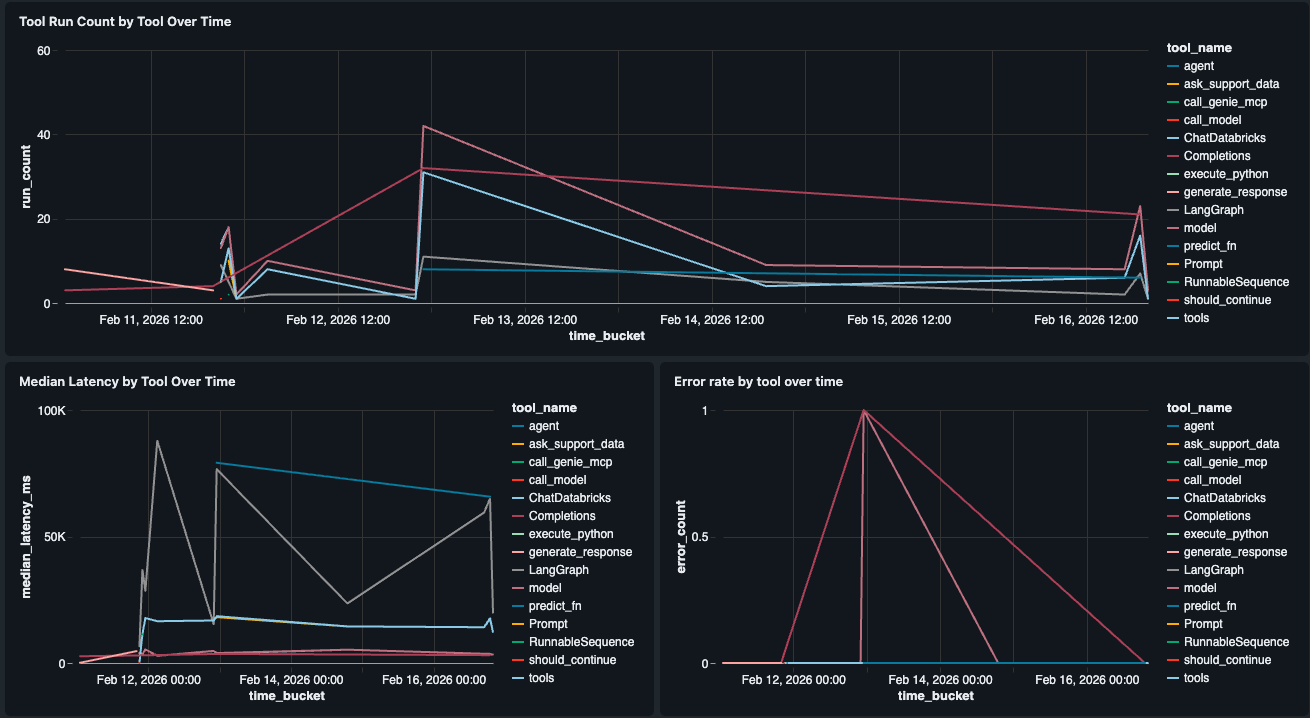
コンポーネントレベルのパフォーマンス
ネイティブレイテンシビューは、トレースレベルでP50/P99を表示します。さらに深く掘り下げて、どのツールが遅いかを確認するために、エージェント内の個々のツールごとのレイテンシ(P50、P99)とエラー率を分解するツールパフォーマンスウィジェットを構築しました(例:retrieve_docs vs. generate_response)。これにより、LLM、Genieツール呼び出し、またはその他のステップがボトルネックになっているのか、ユーザーエクスペリエンスがどこで低下しているのかを正確に特定できます。
Genieスペース
ビジネスおよび技術関係者は、SQLを記述せずにエージェントの動作を調査したいことがよくあります。トレーステーブルをGenie経由で公開することで、チームはテレメトリデータに対して自然言語分析を可能にし、ユーザーがパフォーマンス、ツール使用量、レイテンシ、モデルの動作に関する質問を直接行うことができます。この例では、次のような質問が含まれる可能性があります。
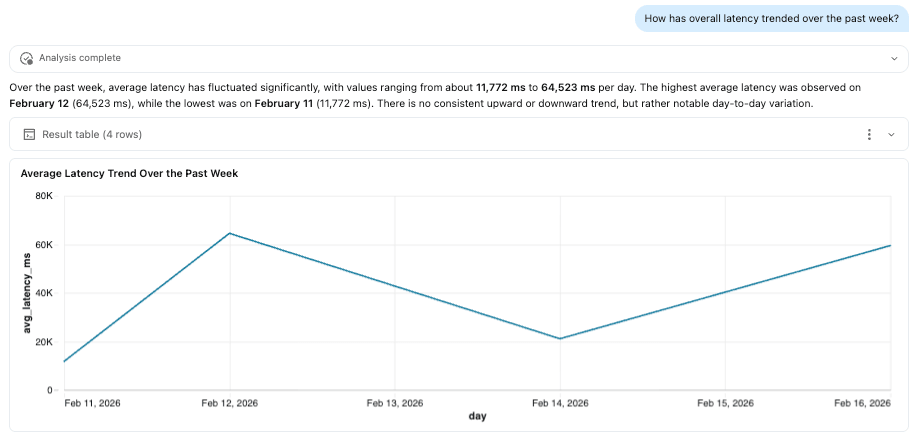
ETLパイプライン
トレースはDeltaテーブルとして保存されているため、他のデータセットと同様にダウンストリームETLパイプラインにフィードできます。Change Data Feed (CDF)を有効にすることで、チームはテーブル全体を繰り返しスキャンすることなく、バッチまたはストリーミングでトレースデータを増分処理できます。
これにより、オブザーバビリティを運用化することが可能になります。たとえば、パイプラインはトレースパターンを監視し、レイテンシが定義されたしきい値を超えた場合、ツール障害が急増した場合、またはトークン使用量��が予想されるベースラインから逸脱した場合にアラートをトリガーできます。これらのシグナルは、ダッシュボード、通知システム、または自動修復ワークフローにフィードできます。
重要なのは、これがリアルタイム保護(例:AI Guardrails)を補完することです。ガードレールはリクエスト時にポリシーを強制しますが、ETLパイプラインはフィードバックループを作成し、チームがトレンドを分析し、ポリシーを洗練し、エージェントのパフォーマンスを継続的に改善するのに役立ちます。
ループを閉じる:本番トレースから評価へ
トレースが利用可能になると、MLflowの評価スタック全体を強化し、チームがGenAIアプリケーションの品質をライフサイクル全体にわたって測定、改善、維持できるようにします。評価と監視はトレースに直接構築され、開発、テスト、および本番環境中にキャプチャされた同じテレメトリをLLMジャッジとカスタムメトリクスを使用してスコアリングできるようにします。
開発中の評価
MLflowを使用すると、評価データセットに対して評価を実行し、組み込みまたはカスタムジャッジを適用して応答品質をスコアリングできます。効果的なアプローチの1つは、このデータセットを実際のトレースからブートストラップすることです。これらのプロンプトは実際のユーザーインタラクションに由来するため、完全に合成されたテス��トケースと比較して、エージェントが処理する必要のあるシナリオをよりよく表します。
以下では、最近キャプチャされたトレースから評価データセットを作成します。MLflowはSQLウェアハウスを使用してデータセットレコードを検索およびマテリアライズするため、環境でウェアハウスIDを構成してください。
データセットが準備できたので、アプリケーションを評価する評価者を定義できます。MLflowは組み込みの評価者をセットで提供しており、エージェントの期待される動作に合わせてカスタムガイドラインを定義することもできます。
そして、MLflowの実験で結果を確認できるようになりました。
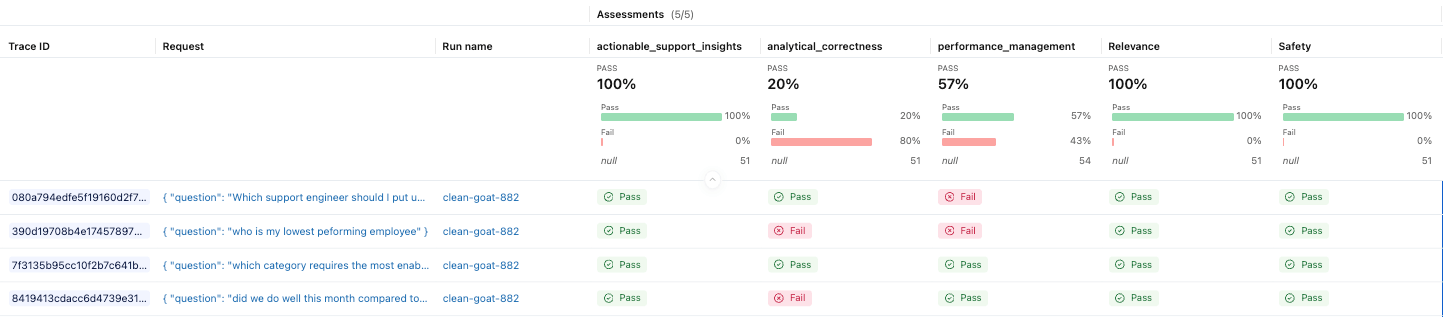
本番環境での監視
開発中の評価はリリース前の動作検証に役立ちますが、本番環境での監視は実際のユーザーによるアプリケーションのパフォーマンスを示します。MLflowは同じ評価者を使用してライブトレースを自動的に評価でき、回帰、ドリフト、新たな障害パターンを迅速に検出するのに役立ちます。これにより、評価は一度きりのタスクから、アプリケーションの進化に伴う継続的な実践へと変わります。
DatabricksでAIオブザーバビリティを実行しているお客様
Experian
当社のEva仮想�アシスタントおよびLatte自動メールシステム向けのMLflowトレーシングへの移行はシームレスでした。Unity Catalogのトレースにより、データサイエンスチームは、Databricksを離れることなく、ガバナンスされたDeltaテーブルを通じて数百万ものトレースを実行し、エージェントの品質を大規模に評価できます。より本格的な評価ワークフローをオンボードするにつれて、1つのガバナンスされたプラットフォームにトレーシングと評価が含まれるということは、エージェントライフサイクルの各ステージで個別のツールを維持する必要がないということです。—James Lin, Head of AI/ML Innovation, Experian
Superhuman (Grammarly)
SuperhumanのすべてAIエージェントのオブザーバビリティレイヤーとして、MLflowトレーシングを標準化しています。カスタムソリューションやポイントソリューションの構築・維持よりも、より広範なプラットフォーム統合を優先しています。そのメンテナンスの負担は、当社のチームにとって実際のペインポイントでした。Unity CatalogのMLflowトレースにより、1日あたり数百万ものトレースにスケールでき、研究者はエンジニアリングサポートなしでMLflow UIで直接エージェントの動作をセルフサービスで探索できます。トレーシング、評価、監視がすべて1つのガバナンスされたプラットフォームにあることは、エージェントを自信を持って本番環境に移行するために必要なものでした。—Martin Jewell, Lead MLE AI Infrastructure, Superhuman
SmartSheet
当社はGenAIのプラットフォームとしてDatabricksを選択しており、MLflowは当社のチームがAIエージェントを構築・評価する方法です。Databricksとの3日間の共同構築中に、MLflowトレーシング、評価、カスタム評価者、ラベリングを使用して2つの本番エージェントをセットアップしました。トレースはUnity Catalogに保存されており、数万件の評価を実行し、スケールに合わせて品質を自信を持って反復できます。—Kapil Ashar, VP of Engineering, Smartsheet
The Standard
The Standardは、お客様が経済的な幸福と安心を得られるよう支援しています。データとAIは、そのエクスペリエンスを大規模に提供するための鍵となります。AIエージェント機能を、例えば重要なインバウンド引受書類やクレーム提出書類からキー情報を抽出するなど、重要なビジネス機能に組み込むことで、お客様やパートナーに優れたサービスを提供できます。本番環境でのトレーシングと監視により、チームはシステムの動作を迅速に理解し、信頼性の高い更新を行うことができます。Databricks Data Intelligence Platform上の他のデータと共にUnity Catalogでトレースをガバナンスすることで、不要な複雑さを追加することなく、安全にクエリ、監視、反復処理できます。—Porter Orr, AVP of AI and Automation, The Standard
よくある質問 (FAQ)
Q: Databricks以外の場所で実行されているエージェントにも使用できますか?
A: はい、エージェントはどこでも実行できます。実際、このブログで使用されたサポートアシスタントエージェントの例はローカルにデプロイされています。
Q: このソリューションのスループットとストレージの制限は何ですか?
A: 取り込みスループットの制限は200 QPSから始まります。ストレージに制限はありません。実験あたりのトレースに関する以前の制限は適用されなくなりました。より高いスループット制限が必要な場合は、Databricksアカウントチームにお問い合わせください。
Q: 検索クエリ、MLflow実験エクスペリエンス、および下流分析のパフォーマンスを維持するために何ができますか?
A: 最新の製品アップデートでは、テーブルは自動的にリキッドクラスタリングされ、データを最適に整理します。ただし、より大量のトレースボリュームの場合は、派生ビューの上にマテリアライズドビューを作成し、それを増分的に更新してクエリパフォーマンスを維持する必要があります。
Q: ユーザープロンプトに含まれるPII(個人識別情報)はどのように処理されますか?
A: この機能はPIIに対して特別な処理を行いません。ただし、データはUnity Catalogに保存されており、そこではきめ細かなアクセス制御、列マスキング、行フィルタリングなどのガバナンス機能を利用して、下流アクセスを管理および制限できます。
はじめに
ドキュメントに従って開始してください。
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。