大規模で信頼性の高いLLM推論
信頼性の高いLLM推論インフラストラクチャ構築からの教訓
によって Ying Chen, ウェンディ・フー, Ankit Mathur, Mike Eastham, Pei-Lun Liao, ワイ・ウー 、 アルジュン・デクーニャ による投稿
- マルチテナントLLMサービングでは、ワークロード全体でのキャパシティに関する推論が必要です。「モデルユニット」は、顧客ごとにGPUリソースを割り当て、ルーティングし、スケーリング可能にするVMのような抽象化を提供します。
- モデルユニット上に構築されたコストを意識したロードバランシングとオートスケーリングにより、レイテンシ目標を維持しながら、静的プロビジョニングと比較してGPUコストを80%以上削減しました。
- ブラックボックスヘルスチェックのようなランタイム信頼性メカニズムは、サイレント障害を自動的に検出し回復します。一方、マルチモーダルボトルネックのプロファイリングにより、スループットが3倍向上しました。
Databricksでは、KimiやQwenなどのオープンソースモデルから、OpenAI、Gemini、Claudeなどのプロプライエタリモデルまで、あらゆる最先端モデルに対応する独自の推論プラットフォームを構築しました。私たちは、Superhuman、Yipit Data、Fox Sportsなど、世界最大級のエージェント型アプリケーションの推論を�サポートしています。現在、月間120兆トークン以上を処理しています。
大規模なLLMサービングが難しいのは、信頼性です。エージェントが仕事や生活のインターフェースになるにつれて、推論の需要は指数関数的に増加しています。私たちは、労働時間中にピークを迎える、非常にスパイク状の需要曲線を見ています。
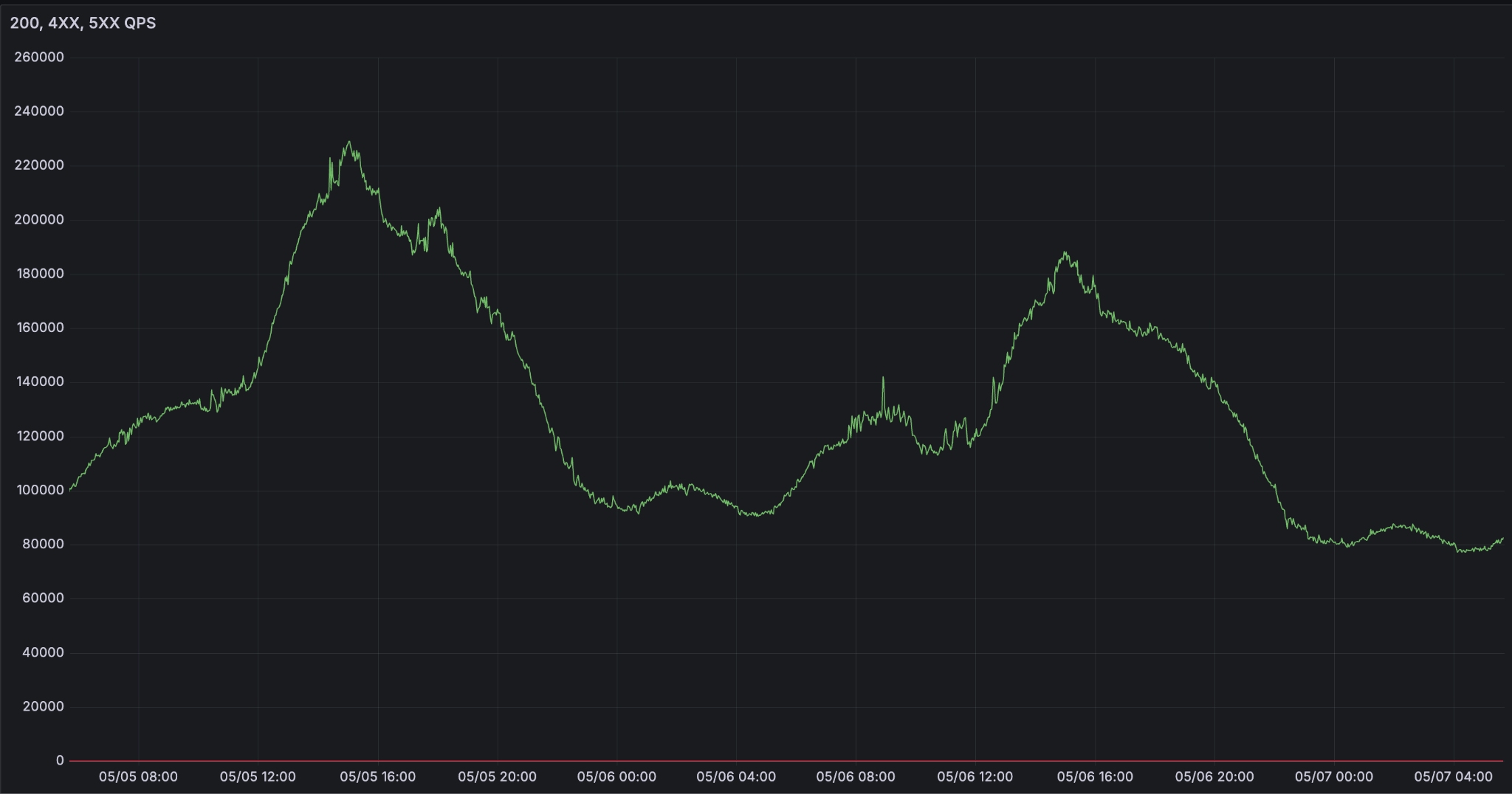
大規模LLM推論実行の課題
信頼性の高い推論プラットフォームとは、どのような意味でしょうか?契約は単純に見えます。可用性とは、リクエストが処理できるかどうかです。しかし、実際には、さまざまなユースケースでレイテンシ要件が大きく異なり、これが可用性に影響します。最も高度なエージェントは、p95の初回トークン生成時間(TTFT)と出力トークン/秒(OPTS)の低下を許容できません。
LLMサービングのマルチテナントシステムでは、信頼性とレイテンシの両方を達成することは困難です。
信頼性
最先端のパフォーマンスには、KVキャッシュ転送のための高帯域幅インターコネクトを備えた最新のGPUが必要です。これらのコンピューティングセットアップは、従来のCPUシステムよりも根本的に信頼性が低く、高価です。すべてのアグリゲーション通信が必要であるため、単一ノードのダウンタイムは、分散されたプリフィル/デコードセットアップで他の複数のノードの再構成を必要とします。最も高い帯域幅のネットワーキングには、単一の物理ラック(例:NVL72システム)での単一スパイン接続が必要です。これは、単一データセンターラック内の特定のシステムの障害が広範囲な障害を引き起こす可能性があることを意味します。マルチAZの利用やバックアップインスタンスタイプの活用などの分散システムにおける標準的なトリックは、高価なバックアップGPUをアイドル状態のままにしておくことであり、コストがかかりすぎます。過剰なプロビジョニングも古典的なトリックですが、コンピューティング供給が非常に限られているため、非常に高価で非現実的です。したがって、システムは重い負荷の下でも運用されなければなりません。
これらの制約の下でも、出荷速度を高く維持する必要があります。当社の推論需要は前年比で数桁増加しており、革新的な機能をリリースしながらその成長を促進することは困難でした。画像、ビデオ、安全分類などの機能は、それぞれ異なる前処理システムを必要とし、それらすべてが独立してスケーリングする必要があります。
最後に、クラス最高のパフォーマンスを達成し、新しいモデルアーキテクチャをサポートするには、カスタムカーネルから独自の推論エンジンまで、あらゆる範囲にわたる最適化が必要です。アーキテクチャが微妙に変化すると、新しい低レベルソフトウェアが導入されるこ�とが多く、これが大規模環境で不透明な方法で失敗し、サーバーハングからGPUクラッシュまで、デバッグが困難なシナリオで表面化する可能性があります。
レイテンシ
多様な負荷パターンでレイテンシを抑制することは困難です。これは、リクエストを処理するコストが非常に変動しやすく、事前に推定するのが難しいためです。負荷が高い場合でも、正常なサーバーはすべてのリクエストをより遅く処理し、スループット(したがってコスト効率)と、製品が処理する必要のある最速のレイテンシとのトレードオフを露呈します。これは、割り当てられたリクエストの組み合わせに基づいて、サーバーが予期せず正常でない状態に非常に迅速に入る可能性があるため、信頼性の問題としても現れる可能性があります。
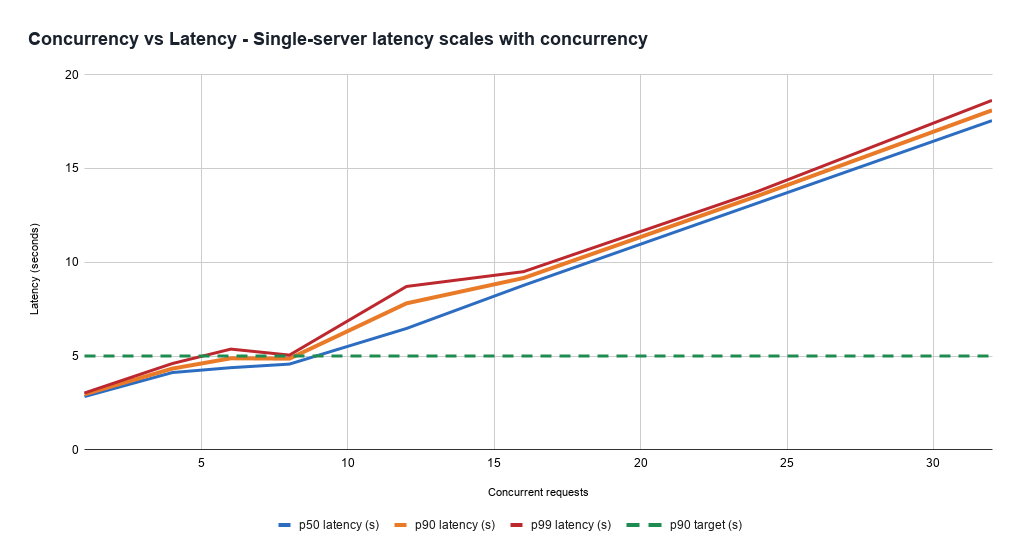
さらに、レイテンシは出力トークン生成によって支配されますが、モデルがどれだけ長く話すかを予測することは難しいため、 upfront のコスト推定は困難です。したがって、低レイテンシサービングには、複雑なキャパシティ管理、ロードバランシング、リクエスト優先順位付けシステムが必要です。
全体アーキテクチャ
これらの問題に対処する方法の詳細に入る前に、サービングインフラストラクチャの概要を説明します。
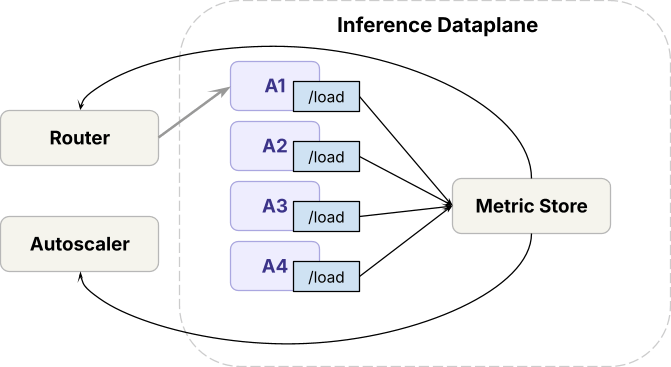
データプレーンでは、
- 推論ランタイム(オープンソースおよび独自の社内エンジン)は、最先端のGPUにデプロイされます。
- モデルデプロイメント全体でトラフィックを処理するために、データプレーンは、同じモデルのレプリカ間で負荷を分散するAxonと呼ばれるルーターと、レプリカ数を調整するオートスケーラーを実行します。
コントロールプレーンでは、
- リクエストは、データプレーンに到達する前にレート制限を通過します。
- リクエストメトリクスに基づいて、キャパシティ管理アルゴリズムが各ワークロードにどれだけのGPUキャパシティを割り当てるかを決定し、オートスケーラーがそれを強制します。
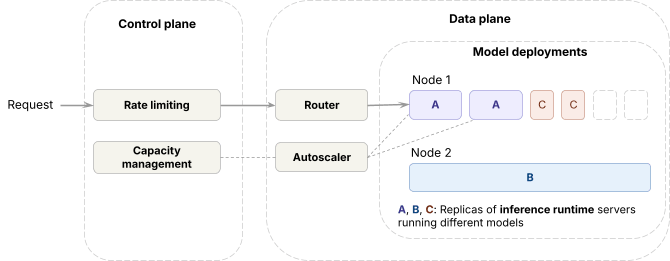
キャパシティの把握
キャパシティ(保有量、販売量、顧客利用量)を大まかに把握する必要があります。これを実現するために、「モデルユニット」という抽象化を導入しました。レプリカが1分あたり固定数のモデルユニット(例:100)を処理できると予測すると、次の仮定を立てることができます。
- 入力または出力が長いリクエストは、より多くのモデルユニットを消費します。同じ時間枠で完了できる数が少なくなるためです。
- プリフィルとデコードは異なるスループット特性を持つため、出力が長いリクエストは入力が長いリクエストよりもコストが高くなります。
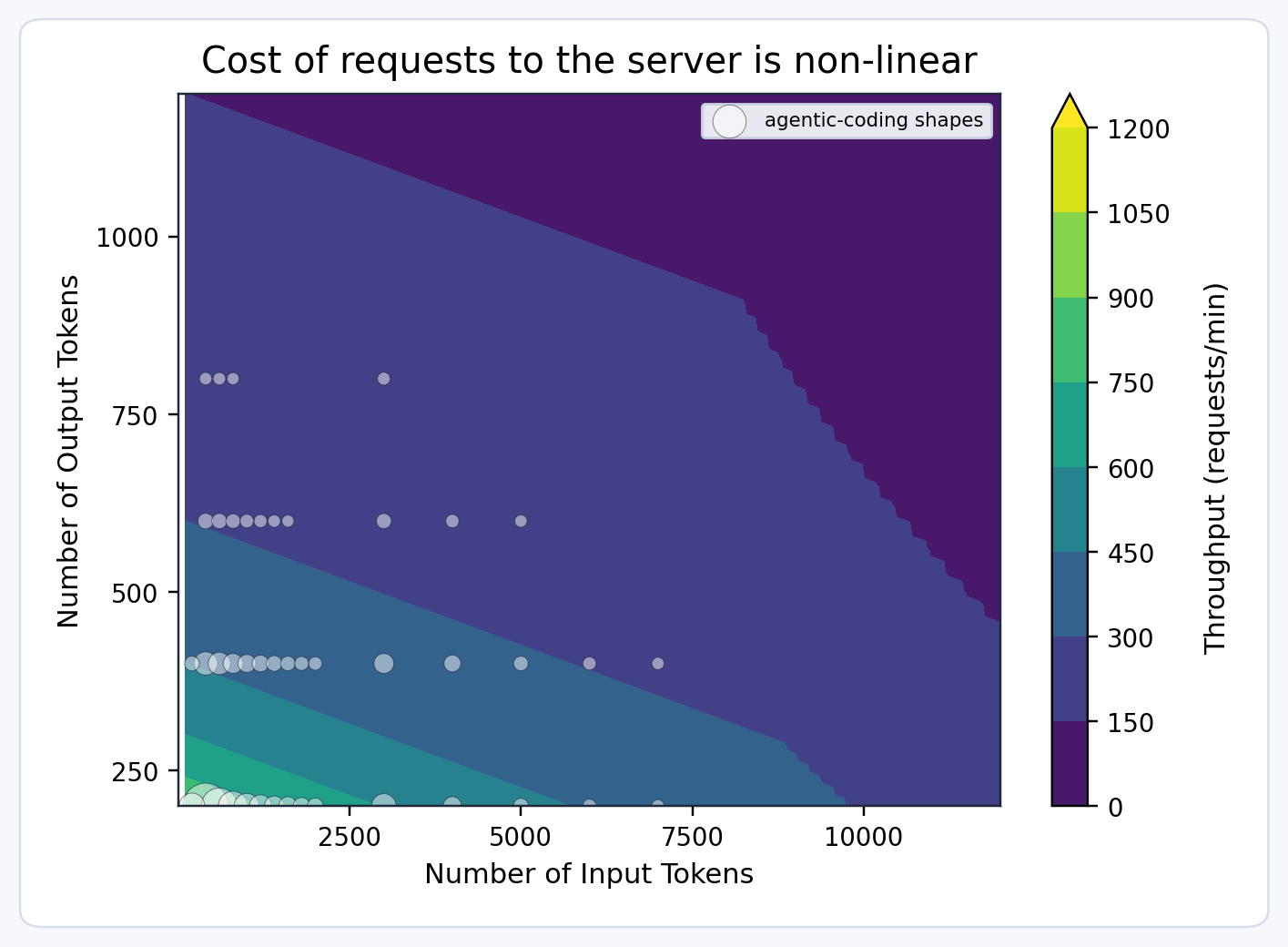
したがって、リクエストコストを次のような多次元関数でモデル化します。
係数α、β、γは、各モデル、各ハードウェアタイプに対して自動ベンチマークによって決定されます。モデルユニットは、プレフィックスキャッシングなどの最適化のためにさらに調整でき、マルチモーダルなどの機能も考慮する必要があります。
このような推定は構造的に不完全ですが、マルチテナントシステムを、クラウドVMに似た、より管理しやすいものに分解する方法として機能します�。VMは、特定の顧客に割り当て可能な予測可能なパフォーマンスを提供するという望ましい特性を持っています。本番環境のエージェントワークロードでは、低レイテンシとキャパシティに関する保証を提供することが重要であり、このような割り当てシステムがない場合、最善の努力は、多くの顧客がシステムを使用した場合に回収される可能性のある「ベストエフォート」キャパシティを提供することです。
コストベースのロードバランシングとオートスケーリング
リクエストはサーバーに非常に変動的な影響を与えるため、ほぼ最適なルーティング決定を行うことが重要です。一般的に、ロードバランシングは、キューサイズに基づいた負荷を推定し、サンプリングを活用してすべての可能なターゲットのメモリとレイテンシのオーバーヘッドを削減するP2C(power of two choices)のような統計的手法に依存する傾向があります。しかし、LLMのレイテンシは高く、サーバー数はスケールアウトされたCPUシステムよりも少なく、誤ったルーティングのコストは深刻です。したがって、LLMサービングには異なるアプローチが必要です。
現在、Databricksの自動シャーダーであるDicerを使用して、ワークロードをサーバー間で動的にルーティングしています。負荷認識ルーティングがない場合、長コンテキストリクエストは個々のサーバーをホットスポットにし、他のサーバーは利用されないままになります。モデルユニットをDicerに統合したため、ルーティング決定は、従来の要求ベースのヒューリスティックでは��なく、モデルユニットでのサーバー負荷に基づいています。Dicerはステートフルセッションも提供し、リクエストルーティングをスティッキーにします。ワークロードのリクエストは一部のサーバーにのみ送信され、キャッシュヒット率(コーディングエージェントのようなレイテンシに敏感なワークロードに不可欠)が向上し、影響範囲が制限されます。
将来的, 我们还可以根据更精确的成本指标来调整负载指标, 甚至使用更优化的路由系统, 以此来进一步优化.
自动扩缩容也存在类似的问题. 仅凭待处理请求的数量无法反映真实负载. 长上下文请求的激增与短请求的激增看起来完全相同, CPU 和内存指标同样与实际 GPU 利用率不相关.
通过使用模型单元, 我们的自动扩缩容器可以根据模型单元利用率比率来决定是扩容还是缩容. 当推理引擎的运行接近其最大模型单元的某个百分比时 (由硬件类型和工作负载形状决定), 它就接近峰值吞吐量, 这会触发扩容. 反之则触发缩容. 这种方法允许模型无关的扩缩容基础设施, 而无需为每个模型手动调整自动扩缩容规则.
在 LLM 推理模式之上构建自动扩缩容, 使我们避免了总是扩缩容到最大副本数. 对于流量突增的模型, 自动扩缩容使副本数量接近实际需求, 与静态预配峰值相比, GPU 节省了 80% 以上.
运行时可靠性
智能路由和扩缩容提供了良好的基础, 但它们无法防止引擎级别的故障. 无论我们部署哪种推理引擎 (我们内部的引擎还是流行的开源选项), 在生产规模下都会出现边缘情况和资源争用. 我们需要自动检测和从故障中恢复的机制.
检测和从静默故障中恢复
我们遇到的一种故障模式是静默挂起. 涉及边缘情况 (结构化输出, 多模态输入) 的请求可能会触发推理引擎多进程架构中的未处理错误, 导致服务器停止响应而不会显示错误.
我们通过定期的黑盒健康检查来检测此问题: 在最近没有真实请求完成时发送最小的端到端请求. 如果健康检查失败, Kubernetes 的存活探针会重启服务器. 这适用于所有引擎, 而与内部实现无关.
然而, 在高负载下, 健康检查本身可能会超时, 导致存活探针杀死实际上健康的服务器. 这有导致级联故障的风险. 为了解决这个问题, 我们将健康检查请求分配最高的调度优先级, 确保它们即使在高负载下也能完成. 通过优先的健康检查, 检测挂起、杀死不健康服务器并恢复的完整周期不到 5 分钟. 虚假的存活探针失败次数从每周几次降至零.
处理来自多模态请求的意外负载
当大量多模态请求到达时, 我们看到了来自完全不同来源的错误率和超时激增.
调查显示, 请求甚至没有到达推理引擎的核心进程. 服务图像请求比纯文本请求更消耗资源, 不仅因为在 GPU 上运行了额外的视觉编码器, 还因为CPU 密集型的图像处理. 对于某些模型, 图像处理速度非常慢, 完全阻塞了事件循环.
将阻塞操作移到单独的线程和进程中并未解决问题; 在高图像负载下, 请求仍然堆积. 因此, 我们分析了 Python 进程并发现了一些问题:
- 在所有图像的 CPU 操作中, 图像处理 (调整大小和归一化) 比 base64 解码等其他操作慢 10 倍.
- 一些 Hugging Face 模型默认使用基于 PIL 的图像处理器, 而其他模型使用更快的基于 Torchvision 的处理器.
- 在容器化环境中, OMP_NUM_THREADS (控制 Torch 用于 CPU 操作的 OpenMP 线程数) 默认为主机上的 vCPU 数量. 在多租户设置中, 这是一个糟糕的默认值: 主机可能有 192 个 vCPU, 但容器只能访问 12 个. 结果是运行的线程数远超可用核心数. 这会导致 CPU 使用率超过容器的限制并触发节流.
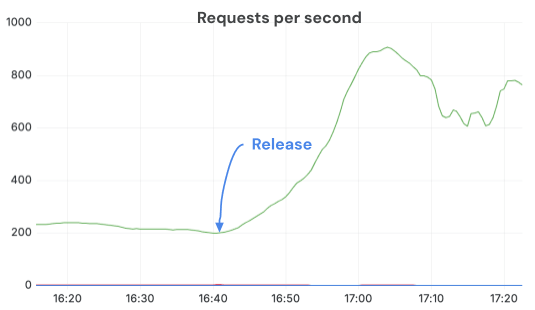
通过切换到基于 Torchvision 的图像处理器并正确配置 OMP_NUM_THREADS, 我们维持了更高的 QPS, 并充分利用了 GPU. 修补程序发布后, 在相同的副本数和负载下, 每秒完成的请求数增加了超过 3 倍. CPU 节流消失了, 服务器运行得更健康.
结论
在规模上可靠地服务 LLM 需要在推理堆栈的每一层进行工作. 我们已经涵盖了围绕 LLM 工作负载设计的自动扩缩容和负载均衡基础设施, 以及无论引擎或工作负载如何都能保持稳定的运行时机制. 还有更多内容: 快速容器启动, GPU 舰队的滚动更新, 以及跨云和区域的 GPU 容量管理. 如果这些是你想解决的问题, 我们正在招聘!
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。