NVIDIA MPSによる小規模LLMのスケーリング
によって データブリックス AI 研究チーム による投稿
小規模モデルは、さまざまな企業のユースケースにおいて、急速に高性能化し、適用範囲が広がっています。同時に、新しい世代のGPUは、コンピュートとメモリ帯域幅を飛躍的に向上させています。その結果は?高並行処理のワークロード下であっても、小規模なLLMはGPUのコンピュートとメモリ帯域幅の大部分をアイドル状態のままにすることがよくあります。
コード補完、検索、文法修正、特化モデルなどのユースケースで、当社のエンタープライズの顧客はDatabricks上でこのような小規模言語モデルを多数提供しており、当社は常にGPUを限界まで活用しています。NVIDIAのMulti-Process Service (MPS) は有望なツールに見えました。これにより、複数の推論プロセスが単一のGPUコンテキストを共有でき、メモリとコンピュート処理をオーバーラップさせることが可能になります。その結果、同じハードウェアからより多くの処理を効率的に引き出すことができます。
当社は、本番運用環境においてMPSがGPUあたりのスループットを向上させるかどうかを厳密にテストすることに着手しました。これらの条件下において�、MPSがスループットを有意義に向上させることがわかりました。
- 短〜中程度のコンテキスト(2,000トークン未満)を持つ超小型言語モデル(30億パラメータ以下)
- プリフィルのみのワークロードにおける非常に小規模な言語モデル(<3B)
- CPUオーバーヘッドの大きいエンジン
私たちのアブレーションに基づくと、主な説明は2つあります。GPUレベルでは、個々のエンジンがコンピュートまたはメモリ帯域幅を十分に活用していない場合、特に小規模モデルのアテンションが支配的なフェーズにおいて、MPSはカーネルの有意義なオーバーラップを可能にします。また、有用な副作用として、エンジン間で合計バッチをシャーディングし、エンジンごとのCPU負荷を削減することで、マルチモーダルワークロードにおけるスケジューラのオーバーヘッドや画像処理のオーバーヘッドのようなCPUのボトルネックを緩和することもできます。
MPSとは?
NVIDIAのMulti-Process Service(MPS)は、CUDAカーネルをハードウェア上で多重化することで、複数のプロセスが単一のGPUをより効率的に共有できるようにする機能です。NVIDIAの公式ドキュメントによると、
Multi-Process Service(MPS)は、CUDA Application Programming Interface(API)の代替となる、バイナリ互換性のある実装です。MPSランタイムアーキテクチャは、協調的なマルチプロセスCUDAアプリケーションを透過的に有効にするように設計されています。
簡単に言うと、MPSはドライバー内にバイナリ互換のCUDA実装を提供し、複数のプロセス(推論エンジンのような)がGPUをより効率的に共有できるようにします。プロセスがアクセスをシリアル化する�(そして順番待ちの間にGPUをアイドル状態にする)代わりに、リソースが利用可能な場合、そのカーネルとメモリオペレーションはMPSサーバーによって多重化およびオーバーラップされます。
スケーリングの状況: MPSはどのような場合に役立つか?
特定のハードウェア設定において、実効使用率はモデルサイズ、アーキテクチャ、コンテキスト長に大きく依存します。最近の大規模言語モデルは類似のアーキテクチャに収束する傾向があるため、代表的な例としてQwen2.5モデルファミリーを使用し、モデルサイズとコンテキスト長の影響を調査します。
以下のエクスペリメントでは、完全にバランスのとれた均質なワークロードを用いて、同じNVIDIA H100 GPU(MPSを有効化)上で稼働する2つの同一の推論エンジンを、単一インスタンスのベースラインと比較しました。
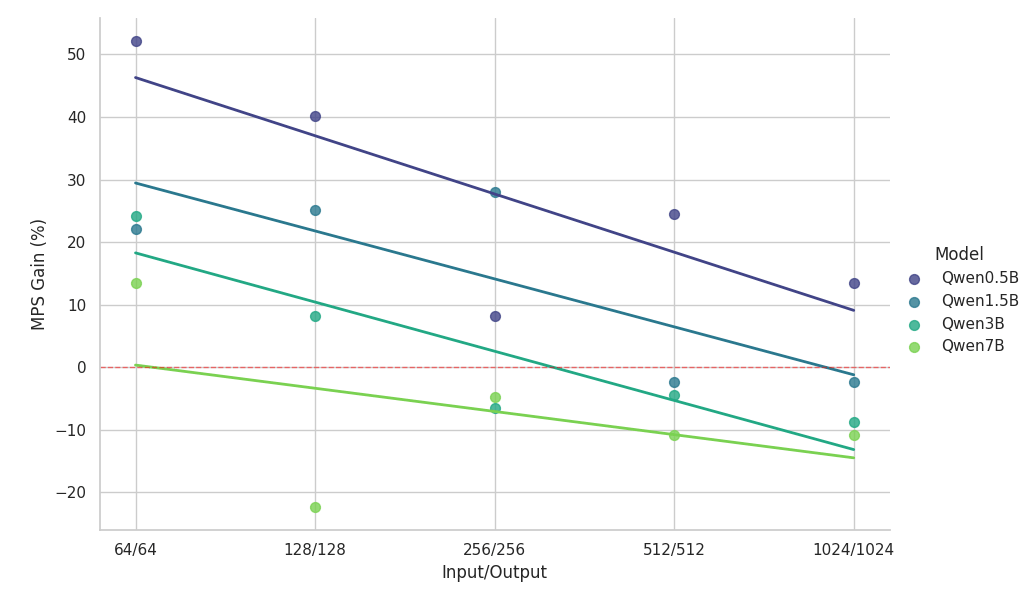
{kind=link}
スケーリング調査からの主な観察結果:
- MPSは、コンテキストが短い小規模モデルにおいて50%超のスループット向上を実現します
- 同じモデルサイズの場合、コンテキスト長が増加するにつれて、ゲインは対数線形的に減少します。
- モデルサイズが大きくなるにつれて、短いコンテキストであっても、効果は急速に減少します。
- 7Bモデルまたは2kコンテキストの場合、メリットは10%未満に低下し、最終的には速度低下を招きます。
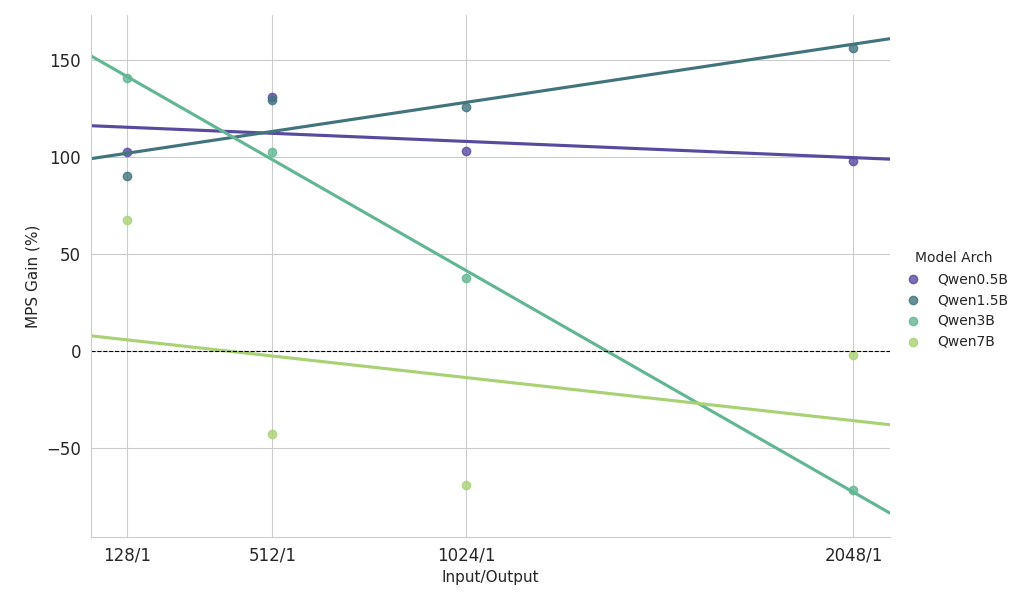
{kind=link}
プリフィル負荷の高いワークロードに関するスケーリング研究からの主要な所見
- 小規模モデル(<3B):MPSは一貫して100%以上のスループット向上を実現します。
- 中規模モデル(約3B):コンテキスト長が長くなるにつれてメリットが減少し、最終的にはパフォーマンスの低下につながります。
- 大規模モデル (>3B): これらのモデルサイズでは、MPSによるパフォーマンス上のメリットはありません。
上記のスケーリング結果は、MPSのメリットが、効果的なオーバーラップを促進する低GPU使用率のセットアップ、小規模なモデル、短いコンテキストで最も顕著であることを示しています。
ゲインの分析:MPSのメリットは一体どこから来るのか?
その正確な理由を特定するため、最新の Transformer の 2 つの主要な構成要素である MLP(多層パーセプトロン)��層とアテンションメカニズムに沿って問題を分解しました。各コンポーネントを分離し(CPU オーバーヘッドのような他の交絡因子を取り除くことで)、ゲインをより正確に特定することができました。
必要なGPUリソース | |||
| N = コンテキスト長 | プレフィル (コンピュート) | デコード(メモリ帯域幅) | デコード(コンピュート) |
| MLP | O(N) | O(1) | O(1) |
| Attn | O(N^2) | O(N) | O(N) |
Transformerは、スケーリング挙動の異なるAttentionレイヤーとMLPレイヤーで構成されています。
- MLP:重みを一度ロードし、各トークンを独立して処理 -> トークンごとに一定のメモリ帯域幅とコンピュート。
- アテンション: KVキャッシュをロードし、すべての前のトークンとのドット積を計算 → トークンごとに線形なメモリ帯域幅とコンピュート。
これを念頭に置いて、当社は対象を絞ったアブレーションスタディを実施しました。
MLPのみのモデル(Attentionを削除)
小規模なモデルの場合、バッチあたりのトークン数を増やしても、MLPレイヤーがコンピュートを飽和させない可能性があります。モデルからattentionブロックを削除することで、MLPの影響を分離しました。
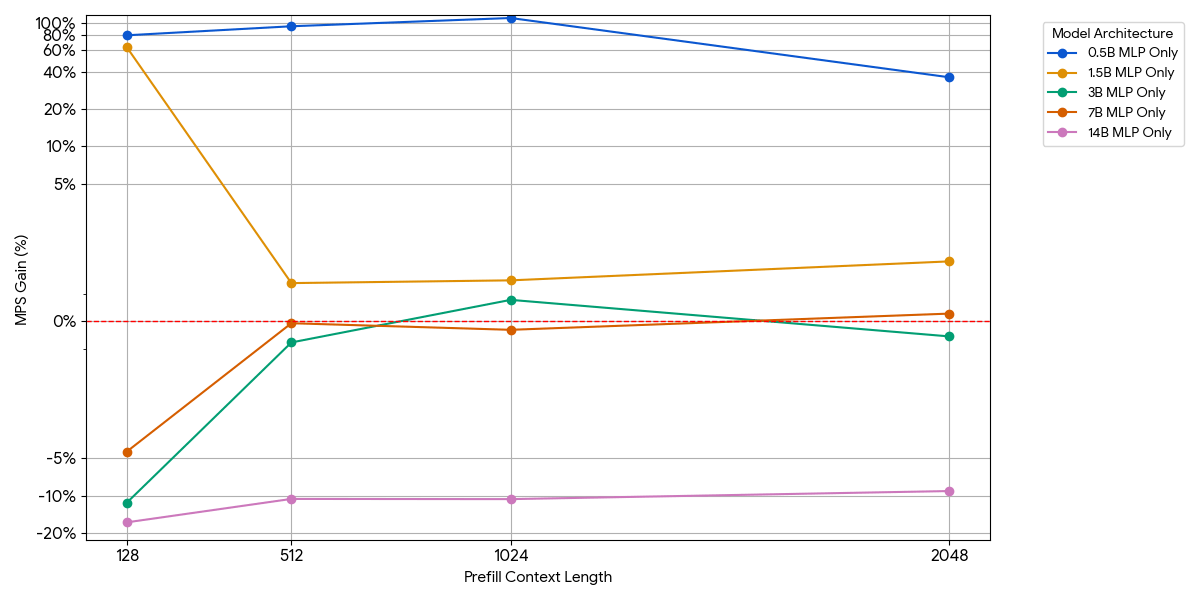
{kind=link}
上の図に示すように、ゲインはわずかですぐに消失します。モデルサイズまたはコンテキスト長が増加すると、単一のエンジンはすでにコンピュートを飽和させます(より大きなMLPではトークンあたりのFLOPsが増え、シーケンスが長くなるとトークン数が増えるため)。エンジンがコンピュートバウンドになると、2つの飽和したエンジンを実行してもほとんどメリットがありません — 1 + 1 <= 1。
Attentionのみのモデル(MLPを削除)
MLPからのゲインが限定的であることを確認した後、Qwen2.5-3Bを使用しましたそして、アテンションのみのセットアップを同様に測定しました。
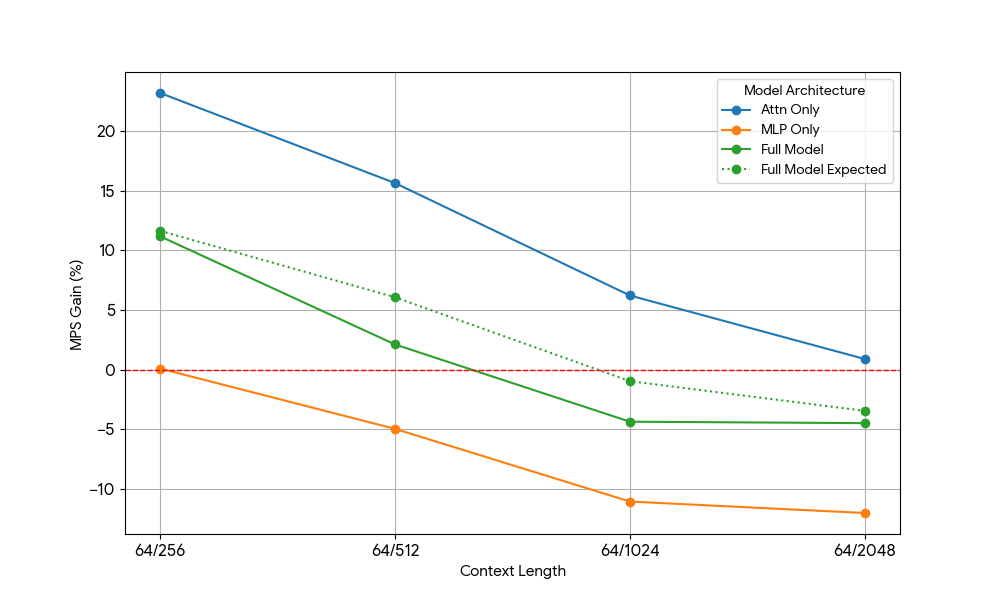
{kind=link}
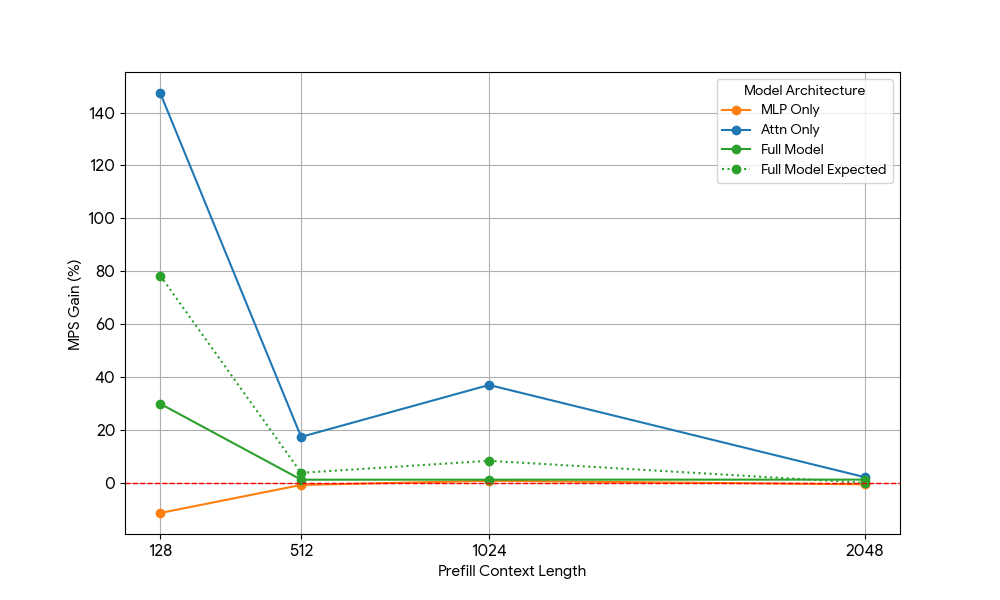
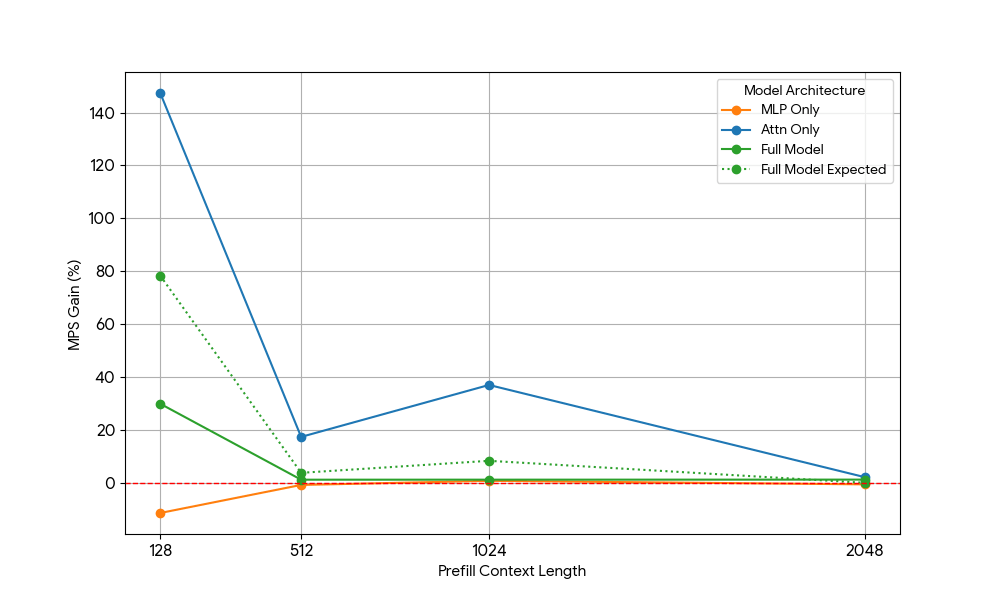{kind=link}
その結果は驚くべきものでした。
- アテンションのみのワークロードは、プレフィルとデコードの両方において、完全なモデルよりもMPSによるゲインが大幅に大きいことを示しています。
- デコードの場合、ゲインはコンテキスト長に比例して減少します。これは、デコード段階ではアテンションに必要なリソースがコンテキスト長とともに増加するという当社の予測と一致しています。
- プリフィルでは、ゲインはデコードよりも急速に低下しました。
MPSのゲインは純粋にアテンションのゲインから来るのでしょうか、それともアテンションとMLPのオーバーラップ効果があるのでしょうか?これを研究するため、Full Model Expected Gain を Attention のみと MLP のみの加重平均として計算しました。この場合、重みはウォールタイムへの寄与度です。この Full Model Expected Gain は、基本的には Attn-Attn と MLP-MLP のオーバーラップから得られる純粋なゲインであり、Attn-MLP のオーバーラップは考慮されていません。
デコードのワークロードでは、Full Model Expected Gain は実際のゲインよりもわずかに高くなっており、これは Attn-MLP のオーバーラップの影響が限定的であることを示しています。さらに、プリフィルのワークロードでは、実際の Full Model Gain は seq 128 から期待されるゲインよりもはるかに低くなります。仮説的な説明として、もう一方のエンジンが飽和した MLP の�実行に時間の大部分を費やしているため、未飽和の Attention カーネルがオーバーラップする機会が少なくなっている可能性が考えられます。したがって、MPS ゲインの大部分は、アテンションが未飽和である 2 つのエンジンに由来します。
追加の利点: CPUオーバーヘッドによって失われたGPU時間の回復
上記のアブレーションスタディは、GPUに負荷が集中するワークロードに焦点を当てていましたが、最も深刻な非効率は、GPUがスケジューラ、トークン化、マルチモーダルモデルでの画像前処理といったCPUの作業を待ってアイドル状態になるときに発生します。
シングルエンジンのセットアップでは、これらのCPUのストールがGPUサイクルを直接無駄にします。MPSを使用すると、最初のエンジンがCPUによってブロックされているときはいつでも2番目のエンジンがGPUを引き継ぐことができ、無駄な時間を生産的なコンピュートに変えることができます。
この効果を分離するために、私たちは以前のGPUレベルのゲインが消失した状況、つまりGemma-4B(アテンションとMLPがすでに十分に飽和しており、カーネルオーバーラップのメリットが最小限であるサイズとコンテキスト長)を意図的に選択しました。
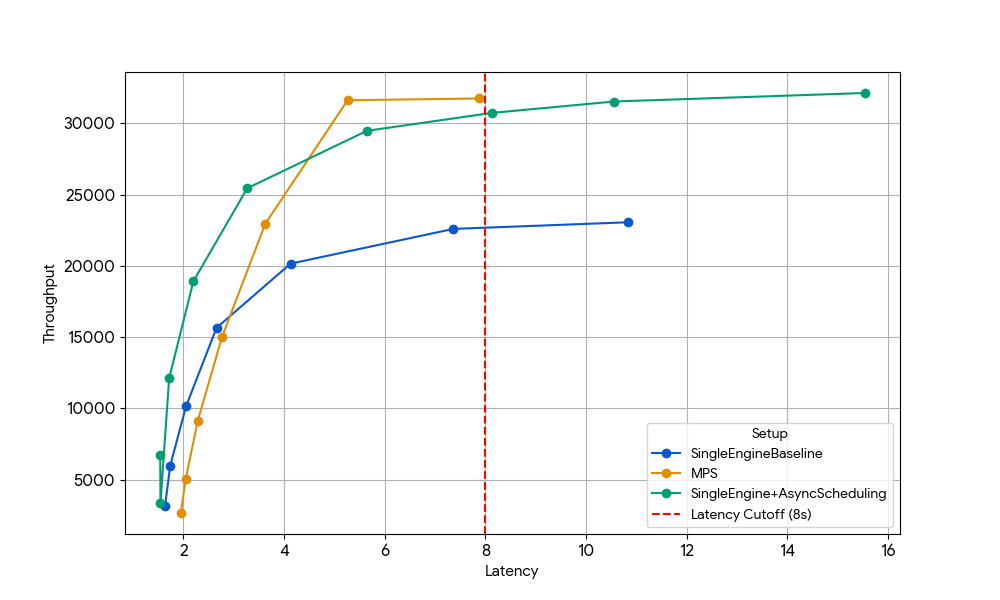
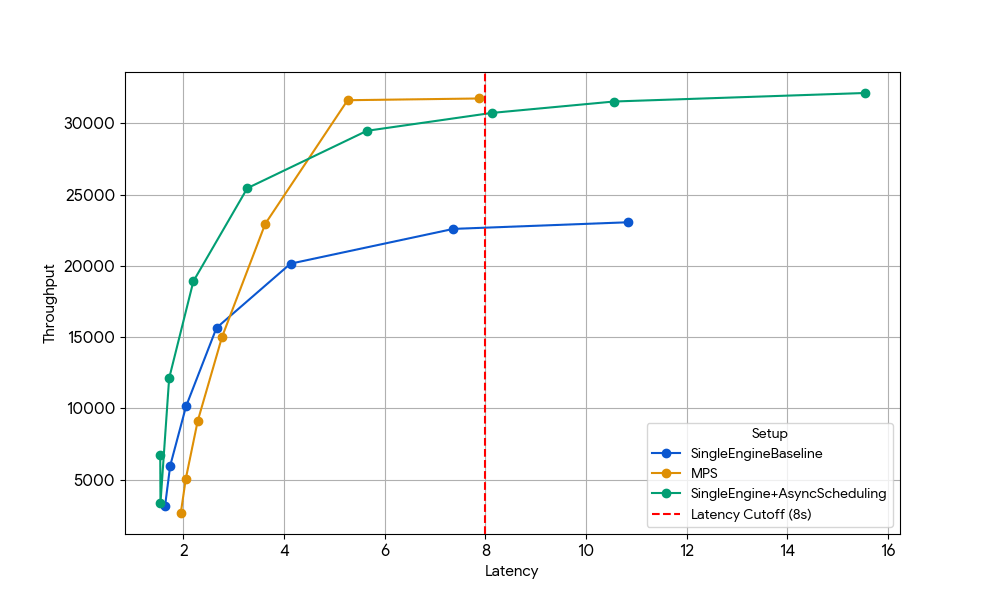{kind=link}
レイテンシ8秒において、ベースラインのシングルエンジン(青線)はスケジューラのCPUオーバーヘッドによって制限されますが、この制限はvLLMで非同期スケジューリングを有効にする(緑線、スループット+33%)か、非同期スケジューリングなしでMPSを使用して2つのエンジンを実行する(黄線、スループット+35%)ことで解消できます。このほぼ同一のゲインは、CPUに制約のあるシナリオにおいて、MPSが非同期スケジューリングによって排除されるアイドルGPU時間と本質的に同じ時間を再利用できることを裏付けています。vanilla vLLM v1.0のスケジューラ層には、非同期スケジューリングのような最適化がまだ完全には利用できずCPUオーバーヘッドが存在するため、MPSが有用な場合があります。
弾丸ではあるが、銀の弾丸ではない
私たちのエクスペリメントに基づくと、MPSはいくつかの動作領域で小規模モデルの推論に大きなゲインをもたらすことができます。
- CPUオーバーヘッドの大きいエンジン
- 短〜中程度のコンテキスト(2,000トークン未満)を持つ超小型言語モデル(30億パラメータ以下)
- プレフィルが多いワークロードにおける非常に小規模な言語モデル (<3B)
これらのスイートスポット(例:7B以上のモデル、8kを超えるロングコンテキスト、またはすでにコンピュートバウンドなワークロード)以外では、GPUレベルのメリットをMPSで簡単に捉えることはできません。
その一方で、MPSは運用上の複雑さももたらしました。
- 追加の構成要素:MPSデーモン、クライアント環境のセッ��トアップ、エンジン間でトラフィックを分割するためのルーター/ロードバランサー
- デバッグの複雑さの増加:エンジン間に分離がないため → 1つのエンジンのメモリリークやOOMが、GPUを共有する他のすべてのエンジンを破損させたり、停止させたりする可能性があります
- モニタリングの負担:デーモンの状態、クライアントの接続状態、エンジン間の負荷分散などを監視する必要が出てきました。
- 脆弱な故障モード:すべてのエンジンが単一のCUDAコンテキストとMPSデーモンを共有するため、不正な動作をするクライアントが1つあるだけで、GPU全体が破損したりリソースが枯渇したりして、同じ場所に配置されたすべてのエンジンに即座に影響が及びます。
要するに、MPSは鋭く、専門的なツールです。上記のような狭い範囲では非常に効果的ですが、汎用的な解決策となることはほとんどありません。私たちは、GPU共有の限界を押し広げ、実際のパフォーマンスクリフがどこにあるのかを解明することを本当に楽しみました。推論スタック全体には、まだ未開拓のパフォーマンスとコスト効率が膨大に存在しています。分散サービングシステムや、本番運用でLLMを10倍安価に実行することに興味をお持ちでしたら、ぜひご応募ください!私たちは人材を募集しています!
著者: Xiaotong Jiang
(このブログ記事はAI翻訳ツールを使用して翻訳されています) 原文記事
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。