自動車業界の未来を切り拓く (パート2): スケーラブルな地理空間アナリティクスとAIの実装
自動車およびモビリティの�イノベーションを推進: リアルタイムの地理空間データ、AI、スケーラブルなアナリティクスで理論から応用へ
によって Eumar Assis, ファリード・アレフ, Varun Mahajan, アンドレス・ウルティア, Himanshu Gupta, Michael Johns 、 Zachary Ryan による投稿
- Databricksを使用すると、取り込み、変換、提供、消費など、地理空間データに関連するアプリケーションやユースケースを提供できます。
- 完全なアプリケーション開発において、Unity Catalogはジオコーディングの安全で管理された共有可能な管理を、AutoMLは機械学習モデルの迅速な作成を、Databricks Labs Data Generatorはテストと検証用の合成データ生成を容易にします。
- Databricksは、これらのユースケースを大規模に開発するために必要な各ステップに統合プラットフォームを提供し、製品ロードマップではさらに多くの機能と利点が計画されています。
パート1では、自動車業界における地理空間アナリティクスを推進する主要な概念とデータセットについて探りました。パート 2 では、Databricks 上でガバナンスとパフォーマンスを維持しながら、AI、機械学習、合成データを使用してスケーラブルな地理空間パイプラインを構築するための具体的なステップを詳しく見ていきます。
これらのアイデアを本番運用に対応した自動車およびモビリティソリューションで実現するための、実際のコードとアーキテクチャパターンに焦点を当てていきます。
スケーラブルな地理空間アナリティクスを実現
Databricksのデータ インテリジェンス プラットフォームは、強力な地理空間アナリティクスとAIを組み合わせて、スケーラブルでリアルタイムの知見を提供します。「リキッドクラスタリング」や「H3 空間インデックス」などの機能により、大規模な地理空間データセットを高速かつ効率的に処理できます。組み込みの地理空間関数を使用すると、交通パターンのマッピングや道路リスクの評価などの空間タスクが簡素化されます。AutoMLは、天候、交通量、道路状況を考慮して、攻撃的な運転の予測といったユースケースのモデル開発を加速します。このプラットフォームは、「Unity Catalog (UC)」を通じて強力なガバナンスも確保し、データアクセスと共有を安全に管理します。「AI クエリー」や「UC で管理された関数」などのツールにより、非構造化ソースから構造化された地理位置情報データを簡単に抽出できます。
スマートモビリティ & 交通安全のための堅牢な地理空間パイプラインの構築
この記事では、Databricks Data Intelligence Platform 上に構築された、地理空間アナリティクスの完全なパイプラインに焦点を当てます。以下では、地理空間データ、LLM、Genie を組み合わせ、会話型の知見を得るメダリオン パイプラインについて説明します。
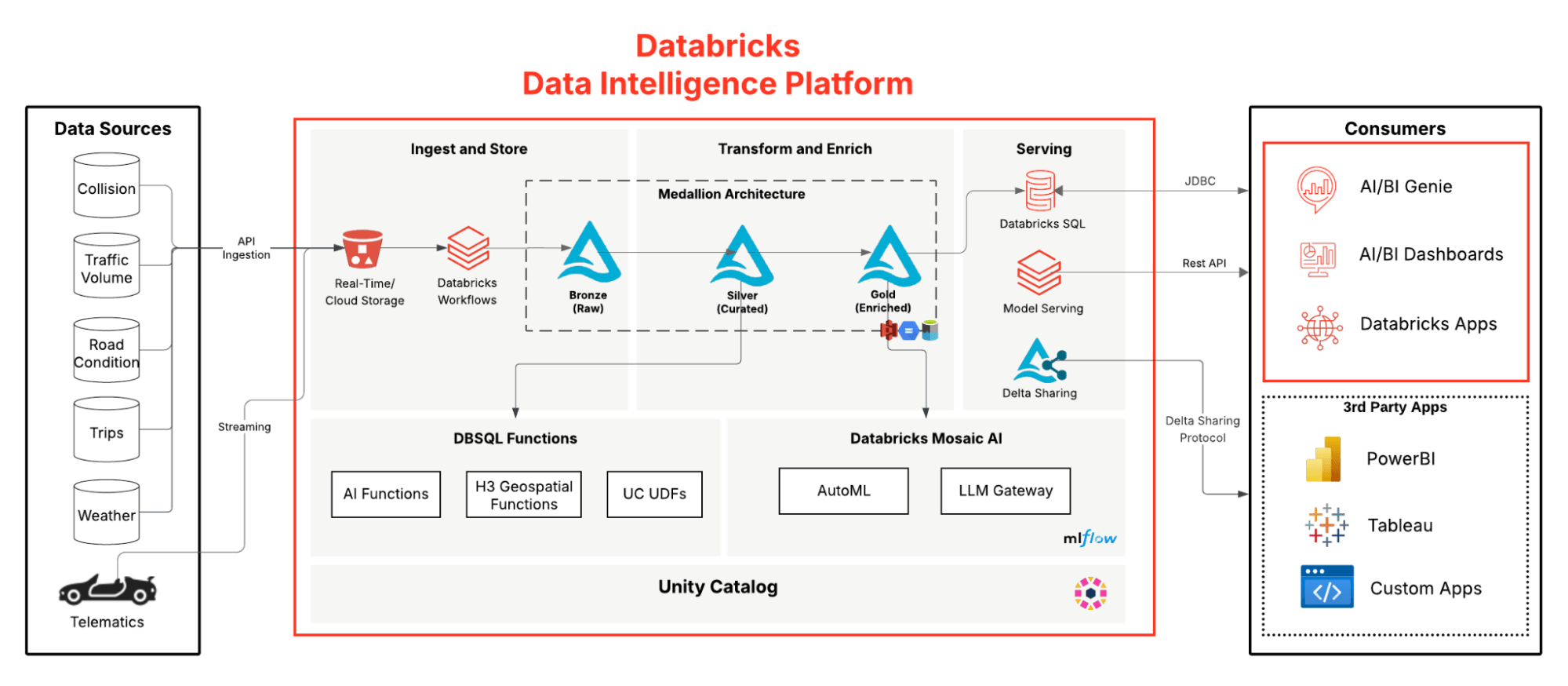
スケーラブルな取り込み
Databricksでは、プラットフォームが幅広い地理空間ライブラリやツールと統合されているため、大規模な地理空間データの取り込みをシームレスに行うことができます。Databricksの地理空間関数は、空間データ処理を強化するために特別に設計されています。Auto Loaderは、クラウドストレージから数十億ものファイルを処理するための最適なオプションです。一方、開発時には合成データ生成を代替手段として利用できます。
合成テレマティクスデータの作成
テレマティクスは、機密性の�高い車両情報や個人情報を公開することなく、現実的なテストやモデル開発を可能にするため、合成データの有力なユースケースとなります。合成データは、開発者の創造性に応じて任意の SQL または Python ロジックを使用して構築できますが、Databricks Labs Data Generator (dbldatagen) ライブラリを使用すると、このプロセスが大幅に簡素化されます。Spark 上で大規模でスケーラブルな合成データセットを直接作成するための、宣言的なインターフェースを提供します。
以下の例では、dbldatagen を使用して 100 万行のテレマティクスデータをシミュレートします。この設定により、開発者は本番運用データに依存することなく、モデリングとテストのために現実的なデータセットを生成できます。
変換とエンリッチメント
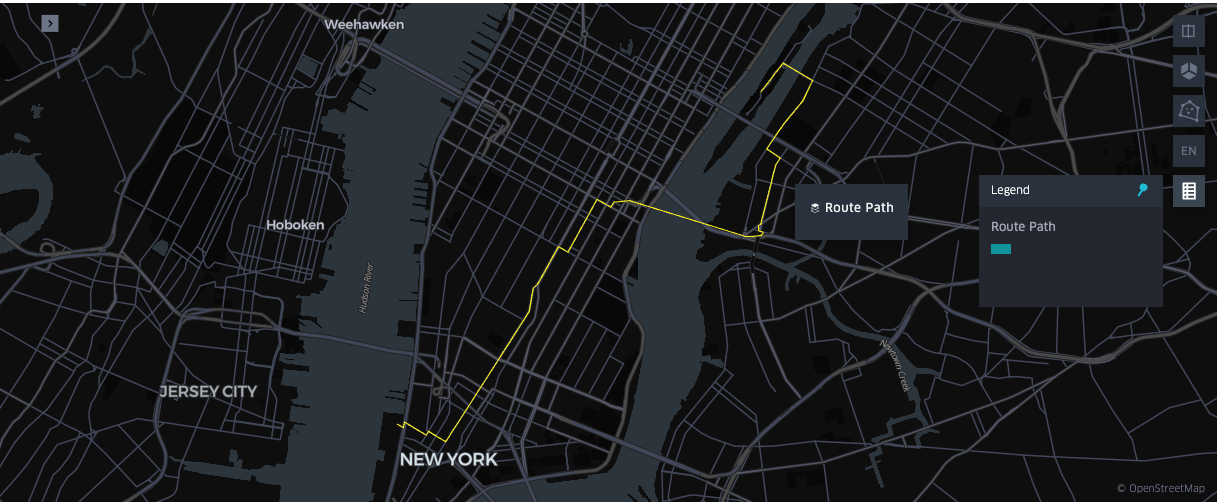
アナリティクスとモデリングに役立つルートを生成する
ルート生成は、地理空間データから効率的でリスクを考慮した経路を特定することにより、モビリティ、安全性、インフラ計画の最適化を可能にします。このパイプラインでは、乗車地点と降車地点の間のルートを再構築して、経路を外部要因と相関させ、より深い知見を得ます。
Databricks では、開発者は osmnx や networkx などのオープンソースライブラリを使用して、OpenStreetMap のデータにアクセスし、道路網の最適な��経路をコンピュートできます。以下の例では、これらのツールを applyInPandas とともに使用して、Spark エグゼキューター全体でルーティングを並列化します。また、OSRMを搭載したDatabricksクラスターを使用してスケーラブルなルートを生成するためのソリューション アクセラレータも提供しています。
注意: このサンプルコードは、パフォーマンス向上のために sparkContext.broadcast を使用しており、各ワーカーエグゼキューターでグラフファイルをdownloadする必要がなくなるため、 専用 アクセスモデルのクラスターが必要です 。
{kind=link}
LLM でインサイトを構築
Databricksは、大規模言語モデル (LLM) を使用して、郵便番号などの非構造化テキストを構造化された地理空間データに変換することで、ジオコーディングを簡素化します。ai_query 関数は、自然言語のプロンプトで databricks-meta-llama-3-70b-instruct endpoint を呼び出し、外部 APIs に頼らずに緯度と経度を生成します。
決定論的な結果を得るためには従来のジオコーディングツールが推奨されますが、この例は、LLMがいかに簡単に地理空間ワークフローを強化し、ロケーションインテリジェンスを民主化するかを示しています。
サービング
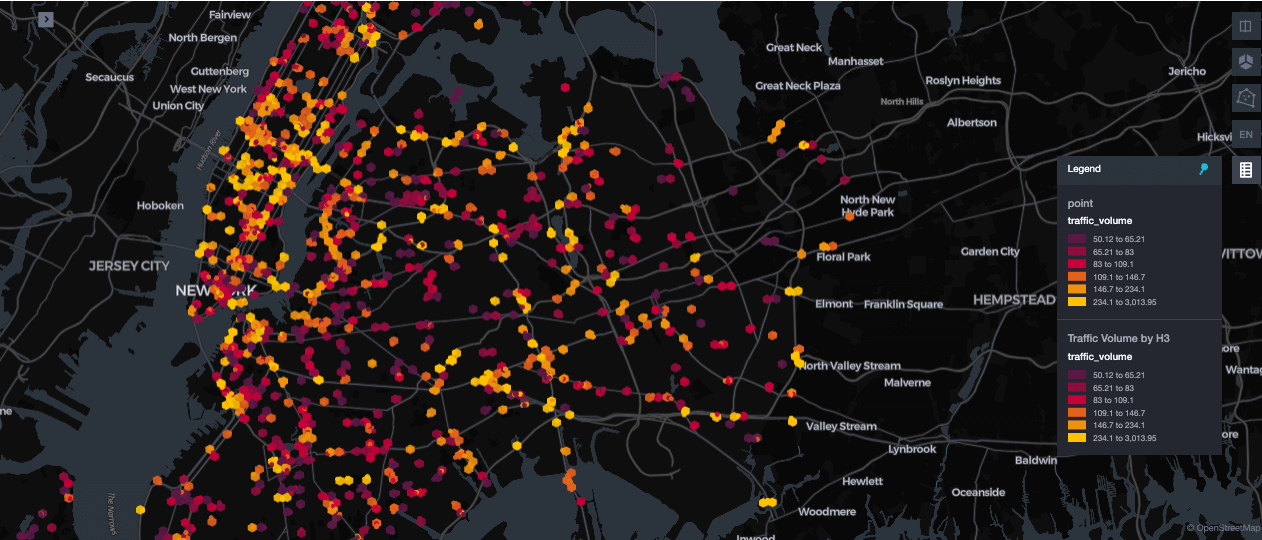
効率的な地理空間データのインデックス作成
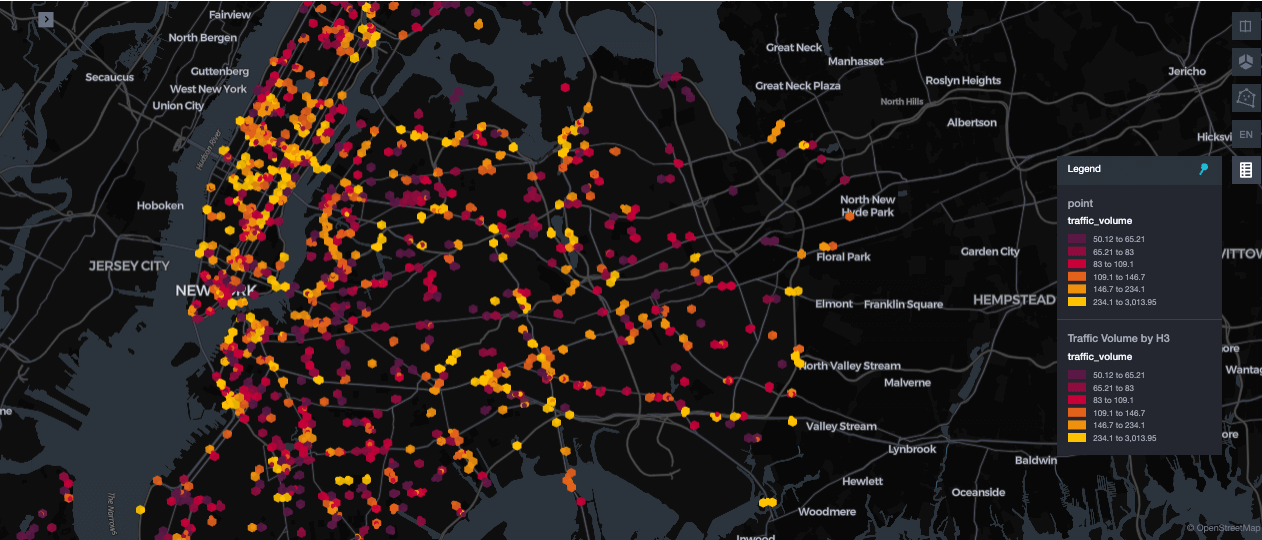
地理空間ワークロードでは、多様なクエリーパターンをサポートするために、柔軟なインデックス作成が求められます。Databricks は H3 空間インデックスと リキッドクラスタリング を統合し、分析クエリーやモデルトレーニングのワークフローを効率的に処理します。この組み合わせにより、速度や社会的決定要因といった他の属性と組み合わせた空間データに対して、明示的なZ-orderingを必要とせずに高速なフィルタリングが可能になります。
以下の例は、リキッドクラスタリング とともに 組み込み の H3 サポートを活用する方法を示しています。ST_Centroid を使用してジオメトリの中心点をコンピュートし、ST_Transform を使用してそれらを WGS84 座標に変換します。次に、h3_longlatash3 は解像度 9 で H3 インデックスを生成し、六角形グリッド全体で高速かつ一貫性のある空間クエリーを可能にします。
MERGE INTO 操作は、silver Delta テーブルへのべき等な upsert を可能にし、同じデータを複数回処理する際の重複を防ぎます。CLUSTER BY h3_index と組み合わせることで、レコードは空間的な近接性に基づいて併置されます。静的な ZORDER とは異なり、リキッドクラスタリング は、事前に定義されたクエリーパターンを必要とせずに、H3 インデックスやTimestamp、車両メトリクスなどのフィールドに対する動的なクラスタリングをサポートします。これにより、ルックアップの高速化、効率的なフィルタリング、スケーラブルなモデル トレーニングが可能になります。詳細については、Databricks H3 関数とリキッドクラスタリングのドキュメントを参照してください。
{kind=link}
Unity CatalogのUDFでカスタムロジックを統制
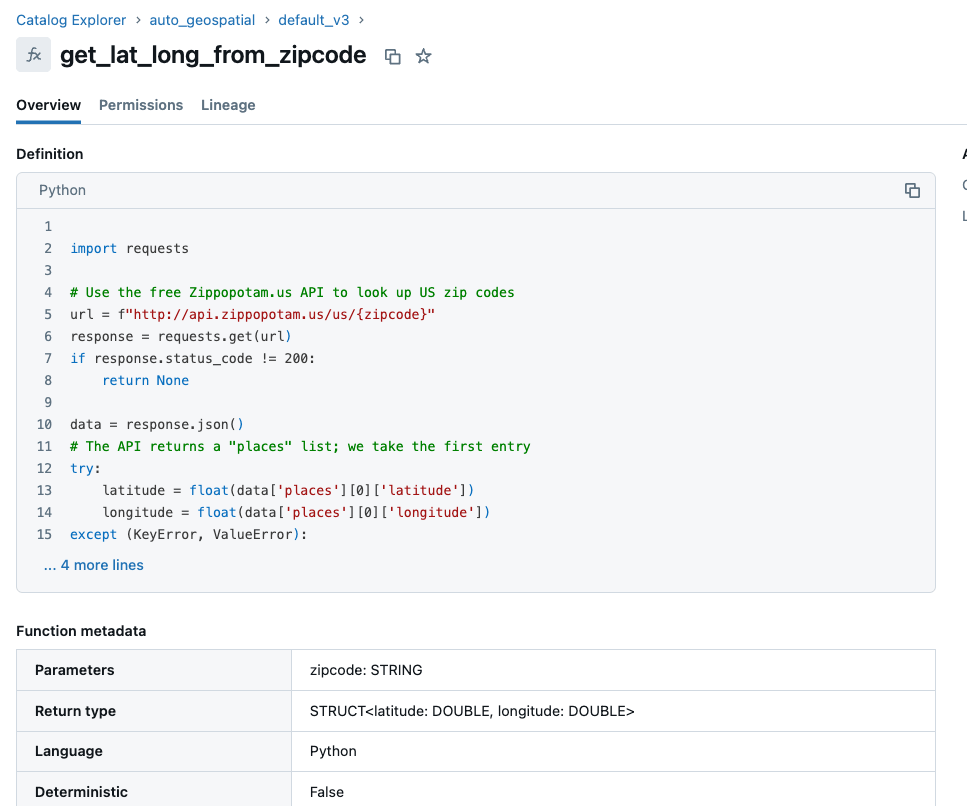
Unity Catalog のユーザー定義関数 (UDF) は、決定論的なジオコーディングを大規模に実行するための、安全で、管理され、共有可能な方法を提供します。郵便番号を緯度経度に変換するなどのロジックを一元化することで、ユーザーやワークロードを横断して、ロジックと結果の一貫性と監査可能性が確保されます。以下のコードは、パブリックAPIを使用して、特定の米国の郵便番号に対する緯度と経度を安全に返す、Unity CatalogのPythonベースのUDFを定義するものです。
消費
AutoMLと時系列で交通量を予測
交通パターンと危険な運転行動を理解することは、よりスマートで安全なモビリティのために非常に重要です。Databricks AutoML と空間インデックスを使用することで、チームは機械学習に関する深い専門知識がなくても、時間認識モデルを構築できます。
以下の例では、 automl.forecast を使用して、特定の場所 ( h3_index で定義) の交通量 ( vol) に関する時系列モデルをトレーニングします。単一のH3セルに焦点を当てることで、モデルはその地域の時間的傾向を捉えます。AutoMLは、特徴量エンジニアリング、モデルのチューニング、トレーニングを処理し、ゾーン全体の渋滞予測や危険運転検知などのユースケースの予測を効率化します。
地理空間インテリジェンスとAIおよびリアルタイム処理を組み合わせることで、自動車関連組織は、安全性、効率性、イノベーションにおいて新たなレベルを切り開くことができます。予知保全からスマートモビリティ、EVの最適化まで、Databricksはこれらのユースケースを大規模に運用可能にするために必要な統合プラットフォームを提供します。顧客は、当社の H3 地理空間関数によって現在大きな価値を引き出しており、製品ロードマップではさらに多くのことが計画されています。
自動車の地理空間ジャーニーを加速しませんか?当社の地理空間ソリューション アクセラレータをご覧になり、今すぐご自身のworkspaceでお試しください。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。