ラムダアーキテクチャとは何ですか?
バッチ処理とストリーム処理を組み合わせたアーキテクチャで、バッチ層で精度を、スピード層でリアルタイムの結果を得、そして両者を統合するサービング層で実現します。
によって Databricks Staff による投稿
- バッチレイヤーは、マスターデータセットを不変の追加専用形式で保存し、MapReduce形式の処理でバッチビューを事前計算することで、正確で包括的な結果を提供しますが、レイテンシは数時間にわたります。
- スピードレイヤーは、StormやFlinkなどの低レイテンシシステムを使用して最新のデータストリームのみを処理し、バッチビューの更新時に結果整合性を確保することでバッチレイヤーの遅延を補正するリアルタイムビューを作成します。
- サービングレイヤーはバッチビューとスピードビューにインデックスを付けることで、両方の視点を融合した高速なアドホッククエリを可能にします。ただし、Apache Sparkなどのストリーミングシステムがバッチ機能とリアルタイム機能の両方を提供しているため、アーキテクチャの複雑さは軽減されています。
ラムダアーキテクチャとは
ラムダアーキテクチャとは、膨大なデータ「ビッグデータ」を処理するアプローチです。ハイブリッドアプローチを使用してバッチ処理やストリーム処理メソッドへのアクセスを提供し、あらゆる関数の計算課題を解決するために活用されます。ラムダアーキテクチャは3つのレイヤーから構��成されています。
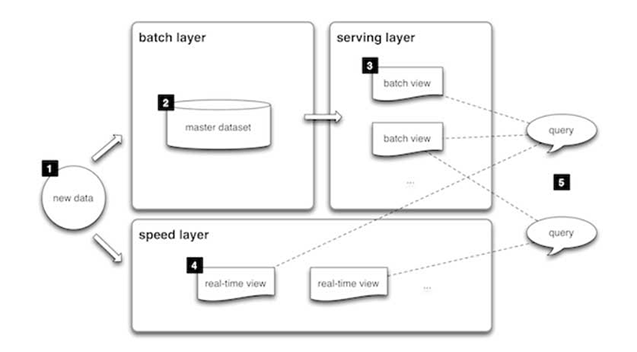
バッチレイヤー
新しいデータは、データシステムへのフィードとして継続的に提供されます。データはバッチレイヤーとスピードレイヤーに同時に供給されます。すべてのデータをまとめて分析し、最終的にストリームレイヤー内のデータを補正します。ここでは、多くの ETL と従来型のデータウェアハウスを見つけることができます。このレイヤーは、通常 1 日に 1 回または 2 回、事前定義されたスケジュールを使用して構築されます。バッチレイヤーには、次の 2 つの重要な機能があります。
- マスターデータセットの管理
- バッチビューの事前計算
サービングレイヤー
バッチビューの形式のバッチレイヤーからの出力と、ほぼリアルタイムビューの形でスピードレイヤーから出力されるデータは、このサービングレイヤーに転送されます。このレイヤーはバッチビューのインデックスを作成し、アドホックベースで低待機時間でクエリを実行できるようにします。
スピードレイヤー(ストリームレイヤー)
このレイヤーは、バッチレイヤーのレイテンシで処理できずバッチビューでまだ配信されていないデータを処理します。また、リアルタイムビューを作成して、最新データを処理し、ユーザーにより完全なリアルタイムビューを提供します。
エンタープライズ向けエージェントAIプレイブック

ラムダアーキテクチャのメリット
ラムダアーキテクチャの主なメリットは次のとおりです。
- サーバー管理は不要: ソフトウェアのインストール、保守、管理する必要はありません。
- 柔軟なスケーリング :容量の調整によってアプリケーションを自動的にスケーリングできます。
- 自動化された高可用性:サーバレスアプリケーションのため、高可用性とフォールトトレランスが標準搭載され、すべての要求の結果を確実に受け取れます。
- ビジネスの俊敏性:変化するビジネス/マーケットのシナリオにリアルタイムで対応
ラムダアーキテクチャの課題
- 複雑さ:ラムダアーキテクチャは、非常に複雑になる可能性があります。管理者によるバッチレイヤーとストリーミングレイヤー用の 2 つの別のコードベースをメンテナンスする必要とするため、デバッグが困難です。
関連リンク
Delta Lake: バッチ、ストリーミングソースおよびシンクの統合
FAQ
1. ラムダアーキテクチャの目的は?
ビッグデータをリアルタイムとバッチの両方で処理し、正確かつ迅速な分析を可能にすることです。
2. 主要な構成要素は何ですか?
バッチレイヤー、スピードレイヤー(ストリームレイヤー)、サービングレイヤーの3層構造で構成されます。
3. 課題は何ですか?
バッチとストリームの両処理を維持する必要があり、コードの複雑化やデバッグの難しさが挙げられます。
関連資料
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。