データ上でアプリ、エージェント
、AIを構築、ラン
データとAIでイノベーターが成功する方法
受賞・表彰
データとAIのイノベーションで認められたリーダー
0%
フォーチュン500企業の60%以上がDatabricksを使用しています
0K+
世界中の2万を超える顧客
0x
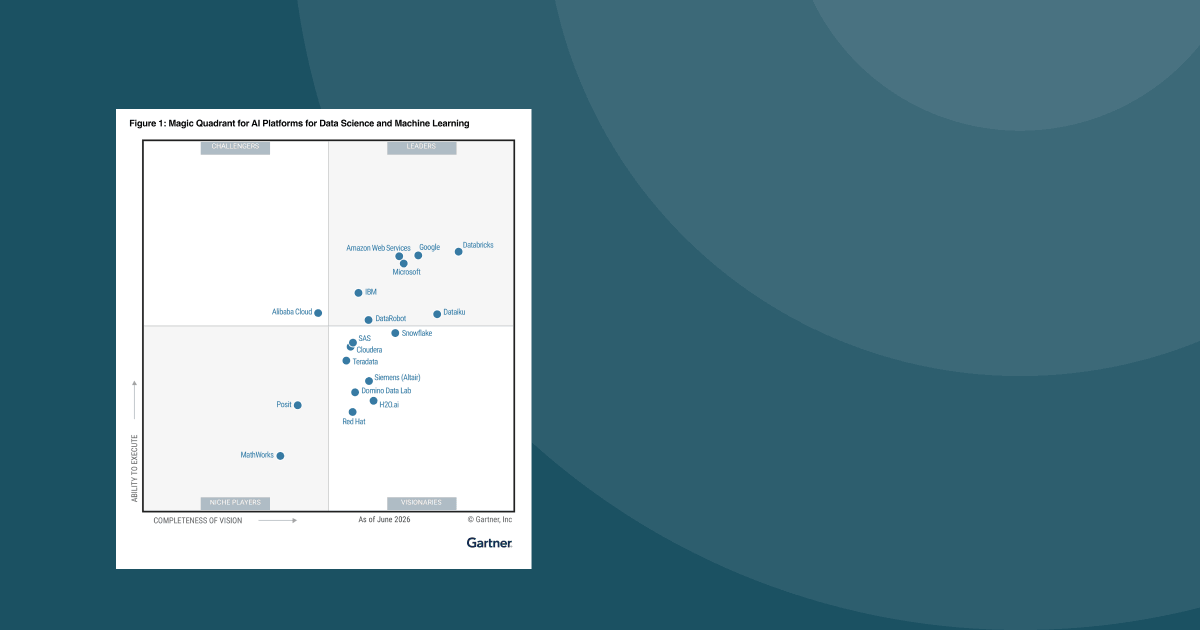
Gartner® Magic Quadrant™レポートで5回リーダーに選出
受賞・表彰
0%
フォーチュン500企業の60%以上がDatabricksを使用しています
0K+
世界中の2万を超える顧客
0x
Gartner® Magic Quadrant™レポートで5回リーダーに選出