リレーショナル データベース (RDBMS) とは何ですか?
定義された関係を持つテーブルに構造化されたデータを保存および管理し、ACID プロパティを通じてデータの整合性を確保します。
によって Databricks Staff による投稿
- リレーショナルデータベース管理システム(RDBMS)とは何か、そしてそれらがどのようにしてデータを関係性を持つ構造化されたテーブルに整理するのかを理解する
- 主キー、外部キー、正規化、SQLベースのクエリなど、リレーショナルデータベースの原則について学ぶ
- データの一貫性と参照整合性が求められるトランザクションシステムにおいて、RDBMSソリューションが依然として不可欠な理由を理解する
リレーショナルデータベースとは?
リレーショナル データベースは、リレーション(関係)と呼ばれる共有の列と行を介して相互にリンクできるテーブルにデータを格納し、アクセスを提供するデータベースの一種です。テーブルには、テーブル間のさまざまな関係を示す一意の識別子(キー)があります。
このリレーショナルモデルはスプレッドシートモデルと似ており、行は顧客、口座、取引などの個々のレコードを表し、列は顧客ID、口座番号、取引額などのレコードの属性を表します。このモデルでは、テーブル間のリレーションシップを確立する共通のキーを使用して、あるテーブルの行を別のテーブルの行にリンクできます。
このモデルは、多数のアプリケーションで使用できる、データを表現しクエリーを実行するための標準的な方法を提供します。
リレーショナルデータベース管理システム(RDBMS)は、リレーショナルデータベースモデルを実装し、ディスクへの書き込みや読み取りから、インデックスの維持、クエリーの実行、データ完全性の確保に至るまで、テーブルだけでなくリレーショナルデータを管理するソフトウェアシステム(データベースエンジンと呼ばれることもあります)です。
リレーショナルモデルのコアコンセプト
テーブル、行、列
リレーショナル モデルの基本的な構造は、データをテーブル、行、列に整理することです。テーブルとは、関連するデータの集合を論理的に整理して表示し、構造化クエリーを実行できるようにするために作成された 2 次元のデータ構造です。
行は、リレーショナルデータベースのテーブル内の特定のエンティティまたはレコード(タプル)を表し、すべての列の値を含みます。
列は、各行のレコードの属性のカテゴリを表します。
要するに、列が構造を定義し、行が実際のデータを提供します。簡単な製品テーブルには、特定の製品の行と、それに関連付けられた属性の列が次のように含まれている場合があります。
| 製品 ID | 製品名 | 製品タイプ | 価格($) |
|---|---|---|---|
| PSHL16 | チャックのホットポークソーセージ | ホットポークリンク(1ポンド) | 5.99 |
| PSML16 | チャックのマイルドポークソーセージ | マイルド ポーク Link (1ポンド) | 5.99 |
| GTS16 | チャックのターキーソーセージ | 味付け七面鳥ひき肉(1ポンド) | 6.59 |
| GT48 | チャックの七面鳥のひき肉 | 七面鳥のひき肉(3ポンド) | 18.59 |
スキーマと構造化データ
リレーショナルデータベースのスキーマは、データベースの構造を記述します。データがどのような形式であるべきか、そしてどのようなルールに従うべきかの設計図を定義します。構造化データは、そのスキーマに従って一貫性のある予測可能な形式で保存されます(どのデータ型をどこに配置でき、どのように表現しなければならないかを定義する一貫した関係を持つ行と列)。
優れたスキーマによって、データ型の整合性と一貫性が保たれます。既知の構造があれば、すべてのテーブルと列が同じ意味を持つため、ストレージとクエリを最適化してパフォーマンスを維持し、理解を深めることができます。 ```
制約とインデックス
テーブルへの書き込みには制約やルールが存在する場合があります。たとえば上記の例では、すべての製品が実際の製品 ID に関連付けられている必要があり、各製品タイプはケース入り(リンク)製品かひき肉製品かを重量とともに一貫した方法で記述します。さらに、価格を除き、各列には値が含まれている必要があり(NOT NULL)、重複があってはならない(UNIQUE)といったガードレールを設定できます。
これは、すべての行が同じフィールドを持ち、すべてのフィールドが同じ意味を持つことを意味します。厳密なスキーマを使用することで、データはクリーンに保たれ、関係は有効性を維持し、クエリーは予測可能になります。
リレーショナルデータベースには、テーブル全体をスキャンすることなく、より高速に行を検索するためのインデックスを設定することもできます。インデックスは列の値を保存し、それらの値が出現するテーブル内の行へのポインタを提供します。大規模なテーブルにクエリを実行するとパフォ��ーマンスが低下する可能性がありますが、インデックスを使用すると、テーブル内のすべての行をスキャンすることを回避できます。
データベースは、データ検索の速度を向上させるために、インデックスをいくつかの種類の最適化された構造に格納します:
- B-Treeインデックスは、木の高さをおさえることで、大規模なデータセットを効率的に処理するように設計された一般的なデータ構造です。B-Treeの各ノードは複数のキーを格納し、複数の子を持つことができるため、データアクセスに必要なディスクI/O操作の数を最小限に抑えることができます。通常の自己平衡二分探索木よりも1つのノードの下に多くの子を持てるようにすることで、B-Treeは木の高さをおさえ、データをより少ない個別のブロックに配置します。
- ハッシュテーブルは、キーを値にマッピングするデータ構造です。ハッシュ関数を使用してキーを、対応する値が格納されているインデックスに変換します。ハッシュベースのインデックスは完全一致検索には効果的ですが、すべてのRDBMSで汎用的にサポートされているわけでも、デフォルトのインデックスタイプとして使用されているわけでもなく、B-Treeのように順序を保持しません。
キーと関係
キーは、データの一意性、完全性を確保し、効率的に取得するために不可欠です。それらは行を一意に識別し、テーブル間のリレーションシップを確立して重複を防ぎ、リレーショナルスキーマ設計の根幹を形成します。テーブル内のデータポイントは共通キーで結合でき、テーブルにクエリーを実行してレポートを作成することが可能にな�ります。共通のキーを使用することで、リレーションシップは1対1、1対多、多対多にすることができます。
テーブルは、いくつかの種類のキーで接続されます。
- スーパーキーは、レコードを一意に識別できる1つ以上の属性のセットです。
- 候補キーは、レコードを一意に識別できる属性の最小セットです
- 主キーは、テーブル内の行を識別する一意のキーです。たとえば、顧客テーブルでは顧客IDが主キーになります。
- 代替キーとは、主キーとして選択されなかった候補キーのことです。
- 外部キーとは、別のテーブルの主キーを指す列のことです。たとえば、トランザクション テーブルは Orders.customer_id を使用して、顧客テーブルの顧客 ID を参照することがあります。
- テーブルのすべてのレコードを識別するために2つ以上の属性の組み合わせが必要な場合、複合キーが必要になります。
リレーショナル データベースの主な特性
リレーショナルデータベースは、連携して動作する操作のグループ(トランザクション)であり、信頼性を確保するためのいくつかの決定的な特徴を持っています。これらのトランザクションは ACID と呼ばれる一連のルールに従います。ACID は以下を表します。
- 原子性: すべての更新は完全に完了する必要があります
- 一貫性: ルールは常に適用されます
- 分離性(Isolation):並列トランザクションは、互いの中間状態に干渉しません。
- 耐久性: 一度コミットされると、データはクラッシュやシステム障害が発生しても存続できます。
これらのルールは、トランザクションレベルでデータ完全性を確保し、データベース操作が確実かつ正しく完了することを保証します。スキーマ設計、データ型、制約は、列の値がアトミックで意味的に一貫していることを保証する役割を果たします。制約は、複数のテーブル間で一貫性を維持するために使用されます。
リレーショナルデータベースのもう一つの重要な特性は、データを抽出するための最も一般的な言語である構造化クエリ言語 (SQL) です。データはリレーションシップを持つ予測可能なテーブルに格納されるため、SQL を使用して複雑な質問に効率的に回答し、データ分析に役立てることができます。クエリーの実行、データの取得、レコードの挿入・更新・削除、新規データベースやテーブルの作成、テーブル・プロシージャ・ビューへの権限設定など、標準的な手法を提供します。
リレーショナルデータベースは、いくつかの側面からデータを保護するために、セキュリティ/アクセス制御も確保する必要があります。
- 認証 – データベースにアクセスするユーザーが本人であることを確認します
- 認可 – 許可されていることを実行すること
- 監査 – いつ何を行ったかの確認
データベース セキュリティには、データが傍受されたり盗まれたりした場合にデータを保護するための暗号化や、システム障害時にデータが失われないようにするためのバックアップとリカバリといった機能も含まれます。
��リレーショナルデータベースは、その標準化と成熟度により、デフォルトの「記録システム」となっています。標準的な機能、構造、および能力により、RDBMSは長期にわたって予測可能で、信頼性が高く、安全で、スケーラブルであり続けます。たとえば、SQLを標準的なクエリー方法として使用すると、主要な概念やスキルをあるRDBMSから別のRDBMSに移すことができ、データアプリケーションやツールは移行を通じて維持できます。標準化はまた、ベンダー間の競争と選択肢を増やします。
リレーショナル データベースには長い歴史があります。この成熟度は、それらが実世界の負荷に対して実戦でテストされており、非常に高度なトランザクション向けに最適化されていることを意味します。
リレーショナル データベースと非リレーショナル データベース
リレーショナルデータベースと非リレーショナルデータベースの最も明白な違いは、非リレーショナルデータベースが構造化データをテーブルに格納しないことです。保存されるデータに最適な形式で、データをコンテナに保存する柔軟性があります。この緩やかに定義された非構造化データには、Eメール、ビジネス文書、動画、画像などが含まれます。しかし、構造化されたトランザクションデータと非構造化データを混在させて保存することもできます。
非リレーショナルデータベースは、しばしばNoSQLデータベースと呼ばれます。この用語はもともと「SQLだけでなく」という意味で、多くのシステムが現在SQLベースのクエリをサポートしているものの、これらのシステムがプライマリインターフェイスとしてSQLに依存していないことを反映しています。
リレーショナルデータベースは、行と列を持つ固定スキーマを使用し、キーとSQL結合で関係を定義します。一方、非リレーショナルデータベースは、キーと値のペア、ノード/エッジ、ドキュメントのように事前設定されたスキーマを必要としない柔軟な構造でデータを格納します。リレーショナルデータベースでは、データは書き込み時にスキーマと一致する必要がありますが、非リレーショナルデータベースではデータの形状は可変です。データは読み取り時に解釈され、関係は通常、データベースではなくアプリケーションで処理されます。
リレーショナル データベースはデフォルトで強力な ACID トランザクションを採用していますが、NoSQL データベースは従来、結果整合性に合わせて設計されており、正確性よりも可用性と速度を優先します。
リレーショナルデータベースは、データポイント間に豊富なリレーションシップがあるとともに、強力なルールを持つ明確な構造が必要な場合に選択されます。リレーショナルモデルは、常に正確でなければならないトランザクションを伴うレポート作成やアナリティクスに最適です。リレーショナルデータベースはアドホックアナリティクスや複雑なフィルタリング、グループ化に優れている一方、非リレーショナルデータベースは限定的なクエリーセットに最適化されていることが多いです。リレーショナルデータベースは通常、垂直方向にスケールしますが、最新のシステムではレプリカ、シャーディング、または分散実行を通じて水平方向のスケーリングをサポートしており、多くの場合、複雑さが増します。一方、非リレーショナルデータベースは水平方向にスケールするように設計されており、通常、大規模な分散ネットワークのために選択されます。
非リレーショナル データベースは、単純なクエリーパターンを持つ、大規模で柔軟性の高い、または急速に変化するデータ向けに選択されます。
一般的な RDBMS の例
- MySQL – SQL標準を実装したオープンソースのRDBMSで、現在はOracle Corp.が所有しています。高いパフォーマンスを必要とするウェブアプリケーション、ビジネスシステム、ミッションクリティカルなデータ駆動型サービスによく選ばれます。一般的に、ウェブアプリケーション、オンラインストアやカタログ、ユーザーアカウントと認証システム、ロギングとアナリティクス、SaaSアプリ、ダッシュボードなどに使用されます。
- PostgreSQL – 厳格な標準とACID準拠で知られ、信頼性と柔軟性のバランスが取れた、拡張性の高いオープンソースのRDBMS。SQLと半構造化JSON/JSONBストレージの両方をサポートし、Multi-Version Concurrency Controlを使用しています。PostgreSQLは、ウェブアプリ、SaaSマルチテナント プラットフォーム、金融取引、アナリティクスとレポート、科学データ、OLTPワークロードに使用されます。オンライン専門のビジネスに人気があります。この7年間で、Postgresは開発者コミュニティで最も人気のあるデータベースとなり、最新のアプリケーション向けの事実上のデータベースの選択肢となっています。
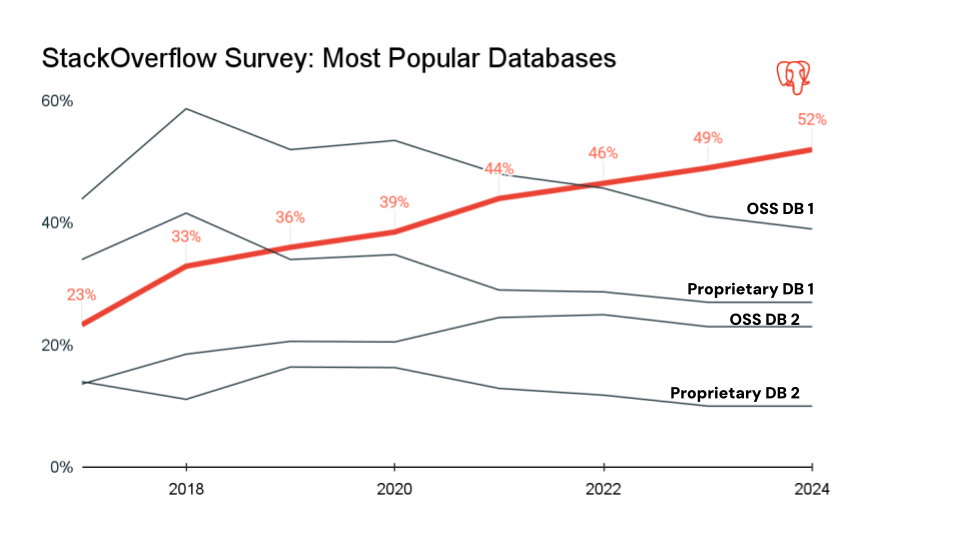
- SQLite – SQL を使用するserverlessでクロスプラットフォームなオープンソースのリレーショナル データベース。軽量の C ライブラリによってアプリケーション内で実行されます。セットアップや管理は不要です。SQLiteは、主に組み込みシステムや個人用デバイスの小規模なアプリケーションに使用されます。
- Oracle – Oracle Corp. が開発したプロプライエタリなエンタープライズグレードのRDBMS。スケーラビリティ、クラスタリング、信頼性で知られており、トランザクション(OLTP)と分析(OLAP)の両方のワークロードに最適化され、銀行、航空、ヘルスケア、テレコミュニケーション、政府、および大規模なERP/CRMシステムで使用されています。
- Microsoft SQL Server – Microsoft独自のSQL拡張であるTransact-SQL(T-SQL)をベースにした、エンタープライズグレードのRDBMSです。WindowsとLinuxで利用可能なSQL Serverは、その管理およびアドミニストレーションツール、そしてMicrosoft Azureやその他のMicrosoftテクノロジーとの強力な統合で知られています。代表的なユースケースには、ERP、CRM、HR、Eコマース、ビジネスインテリジェンス、アナリティクスなどがあります。SQL Serverは、金融、銀行、ヘルスケアの分野に強みがあります。
- IBM Db2 – 高性能、高信頼性、エンタープライズ規模のデータ処理のためにIBMによって開発された独自のRDBMSシステムファミリーです。Db2 RDBMSの各バージョンは、Linux、UNIX、Windows、IBM AS/400、IBMメインフレームなど、複数のプラットフォームで動作します。SQLベースですが、一部のバージ�ョンではJSONドキュメント、XKLストレージ、時系列データ、カラムナストレージ、グラフ機能をサポートしています。金融、政府、医療・保険、小売、航空、エンタープライズIT環境で広く使用されています。
- MariaDB – MySQLのコミュニティ主導のドロップイン代替として作成され、MariaDB Foundationによって管理されているオープンソースのRDBMSです。ウェブアプリ、SaaS プラットフォーム、クラウドシステム、企業における OLTP と OLAP の両方のワークロードに広く使用されており、Linux システムやオープンソース スタックで頻繁に選択されています。主な用途としては、ウェブアプリやウェブサイト、SaaS プラットフォーム、コンテンツ管理、E コマース、アナリティクスなどが挙げられます。
エンタープライズ向けエージェントAIプレイブック

SQL、RDBMSおよび関連するFAQ
SQLはリレーショナルデータベースですか?
いいえ、SQLはリレーショナルデータベースと対話するために使用されるクエリー言語であり、データベースシステムではありません。
MySQLはリレーショナルデータベースですか?
はい、MySQLはテーブル間のリレーションシップをサポートする、テーブルベースの構造を持つRDBMSです。
Excelはリレーショナルですか?
いいえ、ExcelはMicrosoftのスプレッドシートプログラムであり、RDBMSではありません。Excelはテーブル形式を使用しますが、一貫した構造と制約を持つ強制されたスキーマはありません。Excel は単体で SQL クエリーを実行できず、ACIDトランザクションもありません。
リレーショナルデータベースとRDBMSという用語の違いは何ですか?
密接に関連しており、しばしば同じ意味で使われますが、リレーショナルデータベースはデータモデルそのものを指すのに対し、RDBMSはそのデータモデルを管理するソフトウェアシステムです。
メリットとデメリット
リレーショナル データベースを使用するメリットは次のとおりです。
- ACIDトランザクションによって強力なデータ完全性と一貫性が確保され、部分的な更新やデータの破損がなく、信頼性の高いオペレーションが保証されます。構造化され、明確に定義されたデータにより、クリーンで予測可能なデータが保証されます。
- SQLによる標準化されたクエリ機能とツールは、フィルタリング、グループ化、集計、インデックス作成、および複雑な結合を提�供し、リレーショナルデータベースをアナリティクス、レポート作成、および複雑なビジネスロジックに理想的なものにします。
- 数十年にわたって成熟してきたリレーショナルデータベースは、信頼性の高いパフォーマンス、強力なセキュリティと可用性モデル、そしてリスクを軽減するためのツールのエコシステムによって十分にサポートされています。
制限事項は次のとおりです。
- リレーショナル データベースの厳格で固定的なスキーマは俊敏性を低下させ、非構造化データや半構造化データ、頻繁に変化するレコード形式には適していません。
- リレーショナルデータベースは垂直スケーリングに優れていますが、水平スケーリングは複雑です。
- 非常に大規模なデータセットや複雑な結合ではパフォーマンスが低下する可能性があり、分散ワークロードの速度が低下することがあります。
- 商用のRDBMSは、特に大規模な場合、高価になる可能性があります。
- OLTP は、複雑なアナリティクス クエリー向けではありません。
- データがサイロ化しやすく、ストレージ費用が増加します。
- ETL の複雑さ(オペレーショナル ストアと分析ストア間でデータをやり取りする場合)。
- 半構造化データ(Delta、Iceberg、Parquet -- レイクハウスにあるもの)の取り扱い。
- 機械学習/AI 統合のための非標準データ型の取り扱いが困難
- ストリーミングデータの処理に対応するようには設計されていません。
- ベンダーロックインの回避
従来のRDBMSからの進化
- データウェアハウス時代: RDBMSは現在のデータを使用するように設計されており、オンライン トランザクション処理(OLTP)のための多数の小規模な読み取り/書き込みに最適化されています。そのため、大規模なアナリティクスに苦労することがあります。その制限を克服するために、データウェアハウスは非正規化スキーマを使用します。これにより、オンライン分析処理(OLAP)のために、現在およびヒストリカルデータに対する大規模で複雑なクエリーを処理できます。
- ビッグデータの課題: RDBMS は、大量、高速、多様、分散したデータを扱う際に課題を抱えます。厳格なスキーマ、垂直スケーリング、ACIDトランザクションのオーバーヘッドにより、RDBMS は大規模な分散アナリティクスにはあまり適していませんでした。従来の RDBMS は、ローカルで管理されるストレージに対して実行される結合に依存しているため、分散環境でのスケーラビリティが制限されます。
- クラウドネイティブの要件:従来のリレーショナルデータベースシステムは、オブジェクトストレージを優先するクラウドネイティブアーキテクチャではうまく機能しません。これらは、密結合されたハードウェアと低レイテンシのディスクアクセスを備えたブロックストレージ向けに設計されています。これまで、オブジェクトストレージは古典的なACIDトランザクションに必要な低レイテンシを保証できなかったため、従来のRDBMSの設計では課題となっていました。オブジェクトストレージは、レイテンシよりもスループットに最適化されています。また、クラウドネイティブアプリケーションは水平方向にスケールしますが、従来のRDBMSの設計は、多くの場合プライマリサーバーを中心とした、密結合されたコンピュートとストレージに依存しています。
- 最新のデータレイク:Lakehouseアーキテクチャは、データレイクのスケーラビリティと低コストを、データウェアハウスやリレーショナルシステムの構造、ガバナンス、パフォーマンス特性と組み合わせることで、従来のデータレイクの限界に対処するために進化しました。
lakehouseは、データの永続化にクラウドネイティブのオブジェクトストレージを使用する一方で、そのストレージ上で直接スキーマ強制、SQLアクセス、ACIDトランザクションを可能にする、マネージドテーブル形式、メタデータレイヤー、トランザクションLogを導入しています。これにより、構造化データ、半構造化データ、非構造化データが単一のシステム内に共存できます。
スキーマオンリードや外部の処理ロジックに大きく依存していた初期のデータレイクとは異なり、レイクハウスはテーブルレベルでのスキーマオンライトまたは管理されたスキーマの進化をサポートします。これにより一貫したデータ定義、データ品質の確保、信頼性の高いアナリティクスが可能になります。ストレージとコンピュートを分離することで、lakehouseアーキテクチャでは、アナリティクス、データエンジニアリング、ストリーミング、machine learningのために複数のコンピュートエンジンが同じデータ上で動作できるようになります。この柔軟性により、レイクハウスは、オープンなファイル形式とテーブル形式を通じてコスト効率とオープン性を維持しながら、大規模なアナリティクス、ビジネスインテリジェンス、高度なデータワークロードに��適しています。 - レイクベースアーキテクチャ:レイクベースは、最新のインテリジェントなアプリケーション向けに設計された、オペレーショナルデータベースの新しいカテゴリです。RDBMSはトランザクションの整合性や構造化スキーマに優れていますが、アプリケーションがますます依存するようになっている分析データ、machine learningパイプライン、リアルタイムインテリジェンスからは分離されています。レイクベースは、トランザクション、インデックス作成、低レイテンシアクセスといったデータベースのコア機能と、レイクハウスへのネイティブ統合を組み合わせることで、アプリケーションが新鮮で共有された、分析およびAIに対応したデータに対して直接操作できるようにします。これにより、単一のシステムで、データを複製したりアーキテクチャを分割したりすることなく、オペレーショナルなワークロードと、インテリジェントでデータドリブンのアプリケーションの動作の両方をサポートできます。
よくある誤解への対応
- すべてのデータベースはリレーショナルである
リレーショナル モデル(テーブルにデータを格納し、SQL を使用して関係を定義、クエリーする)に従わない非リレーショナル データベースは数多く存在します。 - リレーショナル データベースは SQL のみ
ほとんどのリレーショナル データベースでは、主要言語として SQL が使用されています。SQL はリレーショナル モデルのために構築されましたが、一部のデータベースでは Quel、Tutorial D、Rel、Datalog などの他のリレーショナル言語が使用されていま�す。 - リレーショナル データベースは時代遅れである
リレーショナル データベースは時代遅れにはほど遠い存在です。複雑な構造化データに対しては依然として比類がなく、今日のミッションクリティカルなシステムのバックボーンであり続けています。そして、SQL は依然として最も広く使用されている言語の 1 つです。今日、データのユースケースが進化し続けるにつれて、リレーショナル データベースは NoSQL、データレイク、レイクハウスと共存しています。
まとめ
構造化スキーマによってデータをテーブル、行、列に整理し、キーと結合によって高速なデータ取得と信頼性の高いACIDトランザクションを実現するリレーショナルデータベースは、安全性が求められる企業のミッションクリティカルなアプリケーションにおいて、今もなお定番のアーキテクチャです。高速で信頼性の高いクエリー用に設計された構造により、リレーショナルデータベースはデータ型の整合性と一貫性を提供し、ストレージとクエリーを最適化してパフォーマンスを維持することができます。また、最新の分散データレイクおよびレイクハウス環境において、非リレーショナルデータベースと共存することも可能です。
RDBMSの標準化と成熟度は、それらが実世界の負荷に対して実証済みであり、非常に洗練されたトランザクションに最適化されていることを意味します。レイクベースなどの最新のアーキテクチャは、これらの実績のあるリレーショナルの基盤をクラウドネイティブ環境に拡張し、リレーショナルの信頼性とSQLベースの**アナリティクス**が、スケーラブルなオブジェクトストレージや分散**コンピュート**と共存できるようにします。
関連資料
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。