フィーチャープラットフォームとは何ですか?
エンジニアリング、ストレージ、検出、監視、ガバナンスを含む機能ライフサイクル管理のためのインフラストラクチャ(作成と提供のための API を使用)
によって Databricks Staff による投稿
- コンポーネントには、変換を定義するための特徴量オーサリングツール、計算パイプラインをスケジュールするオーケストレーションシステム、オフラインおよびオンラインの特徴量用のストレージレイヤー、リアルタイムアクセス用のAPI提供、品質を追跡するモニタリングダッシュボードが含まれます。
- モデルトレーニングのためのバッチ特徴量計算、リアルタイムシステムのためのストリーミング特徴量更新、推論中�のオンデマンド特徴量計算、履歴実験のための特徴量バックフィルをサポートします。
- 高度な機能には、品質を保証する特徴量検証、特徴量パイプラインの自動テスト、特徴量実験のためのA/Bテストインフラストラクチャ、シームレスなモデル開発ワークフローを実現するMLプラットフォームとの統合が含まれます。
2年前までは、機械学習システムに完全に依存する製品を構築するためのリソースと専門知識を持っていたのは、巨大なテクノロジー企業だけでした。Google による広告オークション、TikTok によるコンテンツの推薦、Uber による動的な価格調整などを考えてみてください。これらのチームは、最も重要なアプリケーションを機械学習で動かすために、機械学習システムのデプロイという独自のニーズを満たすカスタム インフラストラクチャを構築しました。
それから数年が経ち、本番運用での機械学習を民主化するために、MLOpsツールのエコシステム全体が出現しました。しかし、世の中には何百もの異なるツールがあり、それぞれが何をするのかを理解することは、今やフルタイムのジョブになっています。特徴量プラットフォーム、およびその関連であるFeature Storeは、そのエコシステムで人気のある構成要素��です。要するに、特徴量プラットフォームは、オペレーショナル機械学習アプリケーション向けに、既存のデータインフラストラクチャ(データウェアハウス、Kafkaのようなストリーミングインフラ、Spark/Flinkのようなデータプロセッサなど)を有効化します。この記事では、特徴量プラットフォームとは何か、またそれがどのような問題を解決するのかを詳しく説明します。
オペレーショナル機械学習の構築は困難です
特徴量プラットフォームはオペレーショナル機械学習 (ML) を可能にします。これは、顧客向けのアプリケーションがMLを使い、ビジネスにリアルタイムで影響を与える意思決定を自律的かつ継続的に行うものです。私が紹介した Google、TikTok、Uber の例は、すべて運用 機械学習 アプリケーションです。すべての機械学習プロジェクトは、常に4つのステージで構成されています。
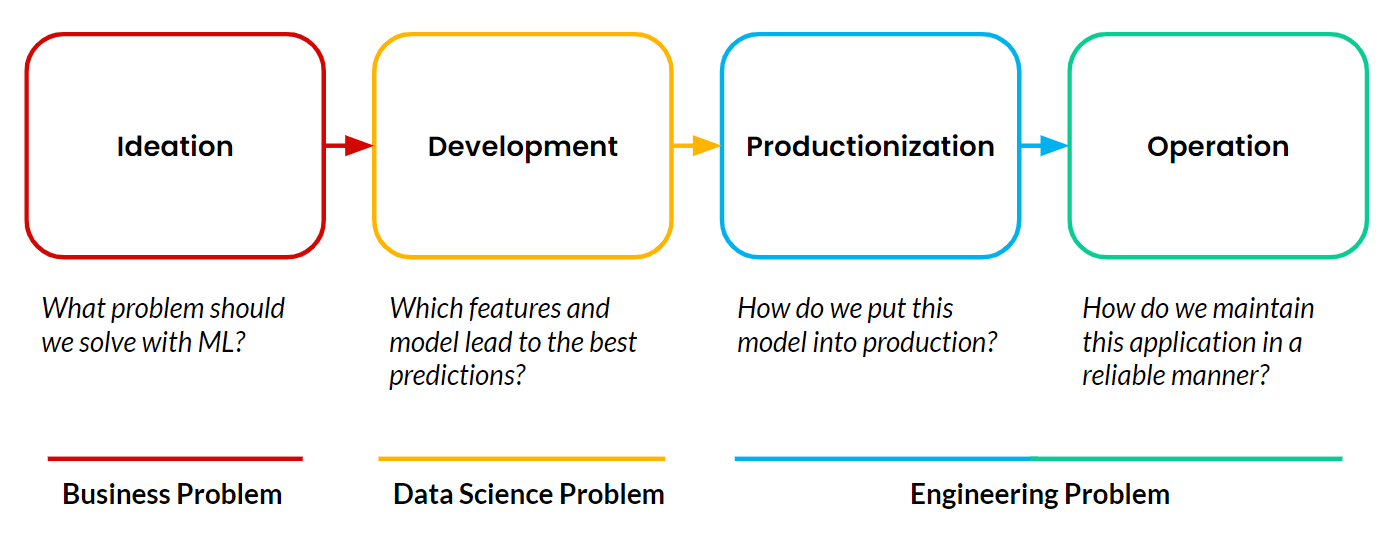
ほとんどのプロジェクトは開発段階を越えられません。機械学習アプリケーションの本番環境への導入と運用は、依然としてチームにとっての主な障害となっています。そして、機械学習の本番環境への導入と運用で最も難しいのは、これらのアプリケーションに継続的にデータを供給する必要があるデータパイプラインの管理です。
フィーチャープラットフォームは、プロダクション化と運用に関連するデータに関する課題を解決します。本番運用への道筋を構築します。これが何を意味するかの詳細については後ほど説明しますが、まずはフィーチャーとは何かを説明しましょう。
機械学習の特徴量とは?
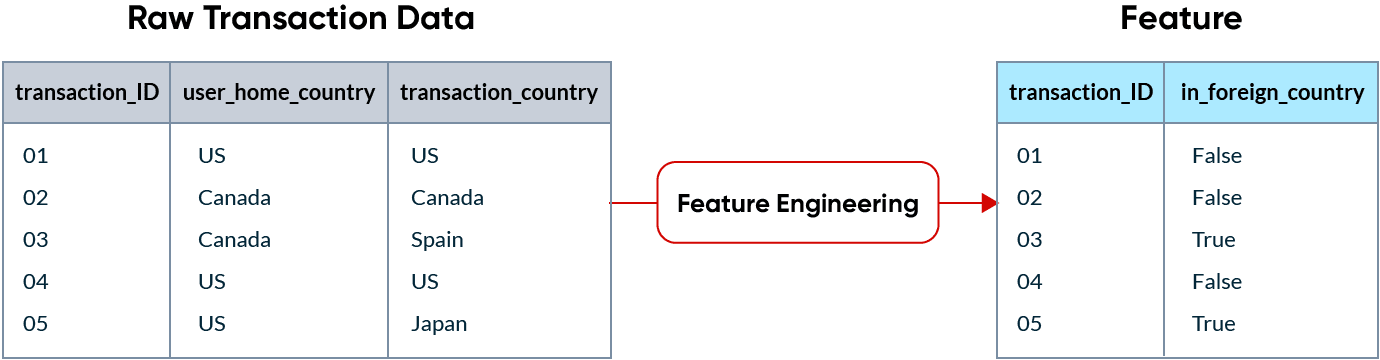
機械学習において、特徴量とは、機械学習モデルが予測を行うために入力として使用されるデータのことです。生データは機械学習モデルでそのまま利用できる形式であることは稀なため、特徴量に変換する必要があります。このプロセスは特徴量エンジニアリングと呼ばれます。
例えば、クレジットカード会社が不正な取引を検出しようとしている場合、海外で行われた取引は不正行為の良い指標となる可能性があります。特徴量は、最終的にモデルに送信されるデータの列になります。
機械学習のユニークな点は、特徴量が2つの異なる方法で使用されることです。
- モデルをトレーニングするには、大量のヒストリカルデータが必要です。
- ライブ予測を行うには、モデルに最新の特徴量のみを提供する必要がありますが、その情報をミリ秒単位で提供する必要があります。これはオンライン推論とも呼ばれます。この例では�、モデルは現在のトランザクションが海外で行われたものかどうかを知るだけでよく、トランザクションの実行中にその情報を処理する必要があります。
フィーチャープラットフォームはどのような問題を解決しますか?
機械学習プロジェクトの開発段階では、データサイエンティストは最高の予測精度につながる特徴量を見つけるために、大量の特徴量エンジニアリングを行います。そのプロセスが完了すると、通常はプロジェクトをエンジニアリングの同僚に引き継ぎ、その同僚がこれらの特徴量エンジニアリング パイプラインを本番運用に導入します。
データサイエンティストであれば、データがどのように利用可能になるか、あるいはどのようにコンピュートされるかを気にしたくはないでしょう。どの特徴量が必要かはわかっており、その特徴量をモデルがライブ予測を行うために利用できるようにしたいと考えています。一方、エンジニアは、これらのデータパイプラインを本番環境で再実装する必要がありますが、リアルタイムデータまたはニアリアルタイムのデータが関わってくると、それはすぐに非常に複雑になります。オペレーショナル機械学習アプリケーションを動かすには、これらのパイプラインは継続的に実行され、停止せず、非常に高速で、ビジネスに合わせて拡張できる必要があります。
データパイプラインを本番運用に再実装することは、運用中のMLプロジェクトにとって主な障害となります。不正検知の例に戻ると、企業が実装するであろう現実的な特徴量は次のとおりです。
- ユーザーの自宅所在地とトランザクション発生場所の間の距離で、トランザクションの発生時にコンピュートされます。
- 現在のトランザクション額が、その加盟店での過去の平均よりも1標準偏差以上高いかどうか。
- 過去30分間のユーザーのトランザクション数(1秒ごとに更新)。
これらの特徴量エンジニアリングパイプラインを実装するのは困難です。これらはデータウェアハウスで直接計算することはできず、データをリアルタイムで処理するためのストリーミングインフラストラクチャをセットアップする必要があります。特徴量プラットフォームは、これらの特徴量を本番環境に導入する際のエンジニアリングの課題を解決し、それによって本番環境への導入を容易にします。具体的には、特徴量プラットフォームは次のことを行います。
- データパイプラインをオーケストレーションし継続的に実行して特徴量を計算し、オフライン トレーニングとオンライン推論で利用できるようにします。
- 特徴量をコードとして管理し、チームがコードレビューやバージョン管理を行い、特徴量の変更をCI/CDパイプラインに統合できるようにします。
- 特徴量のライブラリを作成し、特徴量の定義を標準化して、データサイエンティストがチーム間で特徴量を共有および発見できるようにします。
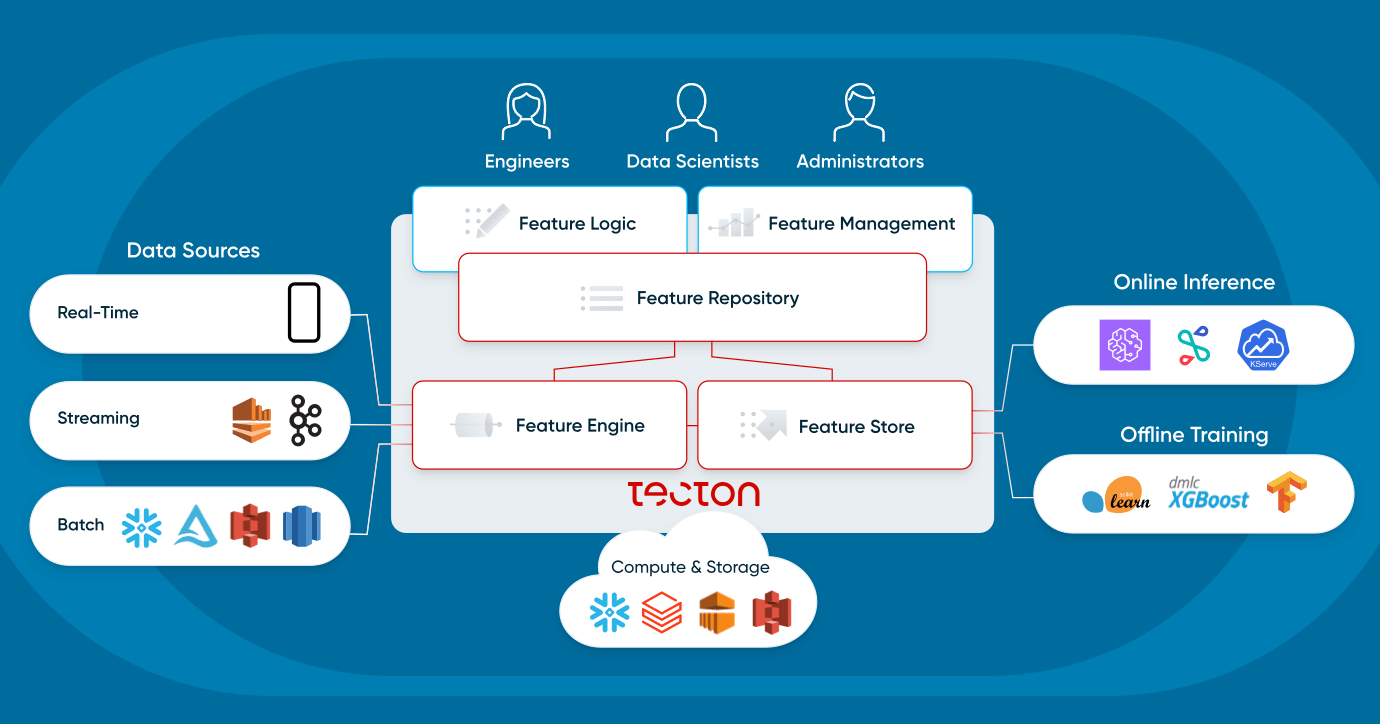
ユーザーがフィーチャー プラットフォームをどのように操作し、その構成要素は何かを詳しく見ていきましょう。
エンタープライズ向けエージェントAIプレイブック

特徴量プラットフォームとは何ですか?
特徴量プラットフォームは、既存のデータインフラをオーケストレーションして、本番環境の機械学習アプリケーション向けにデータを継続的に変換、保存、提供するシステムです。
ユーザーが特徴量プラットフォームを操作するには、主に2つの方法があります。
- 特徴量の作成と発見
- ユーザーは、宣言的なフレームワークを使用して、Pythonファイルのコードとして新しい特徴量を定義します。特徴量の定義はgitリポジトリで管理されます。
- ユーザーは、他のチームが定義した既存の特徴量を発見します。
- 特徴量の取得
- トレーニング時、ユーザーはノートブック内で特徴量プラットフォームを呼び出して、モデルのトレーニングに必要なすべてのヒストリカルデータを取得できます。これは get_historical_features(fraud_model) のよ�うな呼び出しで実行できます。特徴量プラットフォームは、特徴量のバックフィルや正しいポイントインタイム結合の実行といった複雑な処理を扱い、結果として得られるデータフレームは、XGBoost、Scikit-learnなどのあらゆるモデルトレーニングツールに取り込むことができます。
- 推論時には、特徴量プラットフォームが REST エンドポイントを公開し、ライブ アプリケーションから呼び出すことができます。これは、モデルが予測に使用する、特定のエンティティ ID の最新の特徴量ベクトルをミリ秒単位で返します。
特徴量プラットフォームは、既存のインフラストラクチャを置き換えるものではありません。むしろ、運用machine learningアプリケーションのために既存のインフラストラクチャを有効にするものです。つまり、(1) データレイクやデータウェアハウスなどのバッチデータソースや、(2) Kafka のようなストリーミングソースに接続します。それらは、(3) データウェアハウスやSparkなどの既存のコンピュートインフラストラクチャ、および (4) S3、DynamoDB、Redisなどの既存のストレージインフラストラクチャを使用します。最新の特徴量プラットフォームは、組織の既存のデータインフラストラクチャに柔軟に接続します。
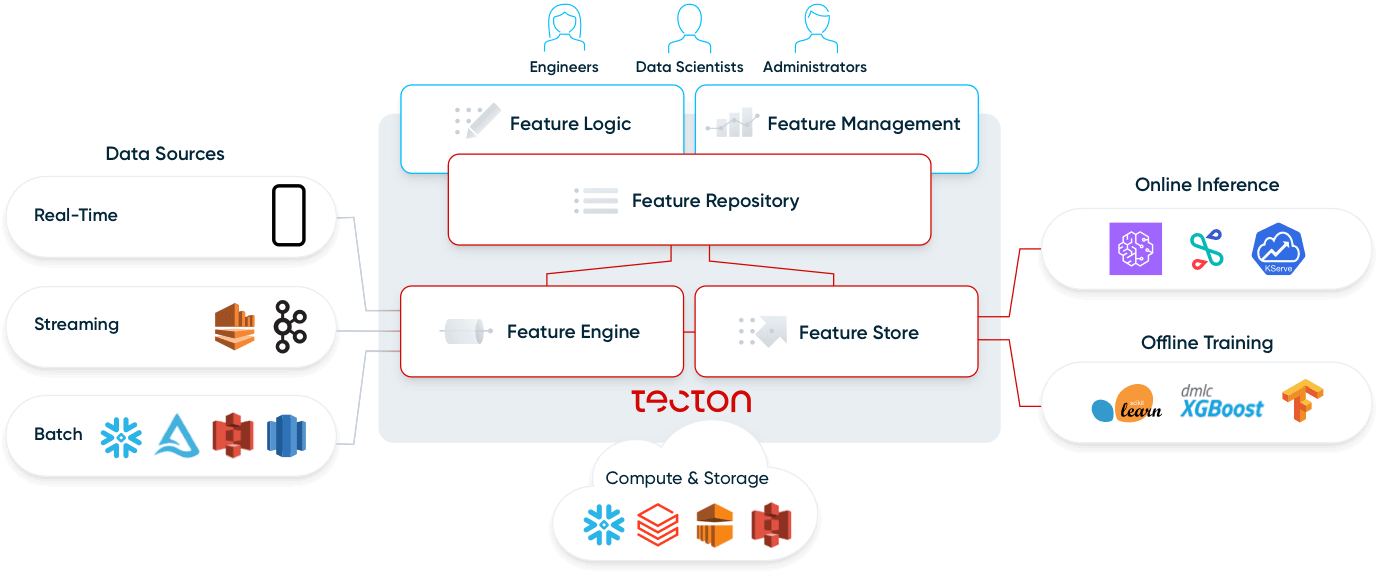
特徴量プラットフォームの4つのコンポーネントである、特徴量リポジトリ、特徴量パイプライン、Feature Store、モニタリングについて詳しく見ていきましょう。
フィーチャー リポジトリ
多くのデータ サイエンティストは、ノートブックでフィーチャー エンジニアリングを行います。これらはインタラクティブで使いやすく、開発サイクルを短縮します。問題は、それらのフィーチャーを本番運用に移行する必要があるときに始まります。CI/CD パイプラインに統合し、従来のソフトウェアで採用しているような制御を行うことは不可能です。
運用機械学習アプリケーションのデプロイに成功しているチームは、特徴量をコード資産として管理しています。これによりDevOpsのあらゆるメリットがもたらされます。コードレビューやリネージの追跡、CI/CDパイプラインへの統合が可能になり、チームはより迅速かつ確実に変更をリリースできるようになります。特徴量をコードとして管理していないチームによく見られる課題は、モデルの最初のバージョン以降、イテレーションを重ねられないことが多いという点です。
フィーチャー プラットフォームでは、ユーザーは 3 つの要素を含む宣言型インターフェースを使用して、フィーチャーをコードとして定義します。
- 特徴量をコンピュートする頻度に関する設定。
- 共有と発見可能性を可能にする、フィーチャー名や説明などのメタデータ。
- SQLまたはPythonで定義された変換ロジック。
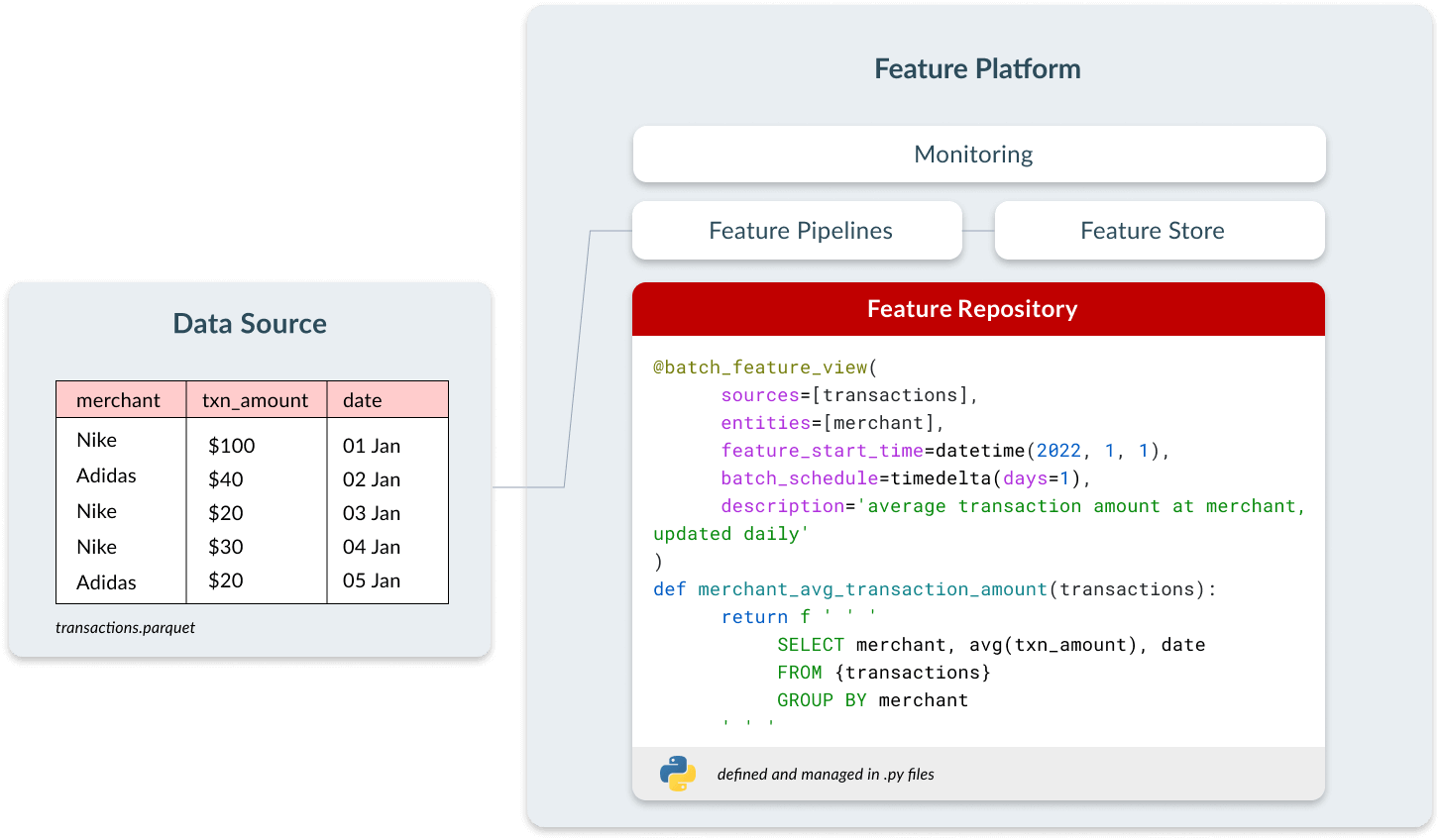
これにより、すべてのチームがこれらの特徴量を中央で発見し、独自のモデルで使用できるようになります。特徴量をさまざまなユースケースのために複数回計算する必要がなくなるため、開発時間の短縮、チーム間の一貫性の確保、コンピュートコストの節約につながります。
特徴量パイプライン
本番環境の機械学習アプリケーションでは、モデルが最新の状況に基づいて予測を行えるように、新しいデータを継続的に処理する必要があります。ユーザーがリポジトリで特徴量を定義すると、特徴量プラットフォームが自動的にデータパイプラインを処理してその特徴量を計算します。
フィーチャープラットフォームがサポートしなければならないデータ変換には、3つのタイプがあります。
| 変換 | 定義 | データソース | 例 |
|---|---|---|---|
| バッチ | 保存データにのみ適用される変換 | データウェアハウス、データレイク、データベース | 加盟店ごとの平均トランザクション額(毎日更新)。 |
| ストリーミング | ストリーミング ソースに適用される変換 | Kafka, Kinesis, PubSub, Flink | 過去30分間のユーザーのトランザクション数、1秒ごとに更新 |
| オンデマンド | 予測時にのみ利用可能なデータに基づいてフィーチャーを生成するために使用される変換。これらのフィーチャーは事前コンピュートできません。 | ユーザー向けアプリケーション、RPC サービスへの API、インメモリデータ | 現在のトランザクション額が、トランザクション時にコンピュートされたユーザーの平均トランザクション額よりも2標準偏差以上高いかどうか。 |
これらの変換は、特徴量プラットフォームが接続されているデータ処理エンジン(Spark、Snowflake、Python)で実行されます。特徴量プラットフォームは、ユーザー定義の変換コードを基盤となるデータ処理エンジンに1対1で渡します。これは、特徴量プラットフォームが独自のカスタムSQLダイアレクトやカスタムPython DSLを持つべきではないことを意味します。これにより、特徴量プラットフォームへのオンボーディング体験とデバッグ体験の両方が簡素化されます。
バッチ変換は簡単に実行できます。データウェアハウスに対する SQL クエリーや Spark ジョブの実行によって実行できます。しかし、運用中の ML アプリケーションは、ストリーミング変換やオンデマンド変換によってのみアクセスできる最新の情報から最も多くのメリットを得ます。不正検知の例では、モデルが最良の予測を行うことを可能にするフィーチャーには、金額、加盟店、場所などの現在のトランザクションに関する情報や、過去数分以内に行われたトランザクションに関する情報が含まれます。
私たちが話を聞くどのチームも、新鮮なデータにアクセスできれば、モデルの大部分のパフォーマンスが向上することに同意しています。ストリーミング変換とオンデマンド変換の管理は複雑なため、ほとんどの組織では依然としてバッチ変換のみを使用しています。特徴量プラットフォームはその複雑さを抽象化し、ユーザーが変換ロジックを定義して、バッチ、ストリーミング、またはオンデマンド変換として実行するかどうかを選択できるようにします。
開発段階で新しい特徴量を繰り返し開発する場合、トレーニングデータセットを生成するためにデータをバックフィルする必要があります。例えば、本日新しい特徴量 merchant_fraud_rate を開発した場合、モデルをトレーニングする期間全体にわたって、その値をバックフィルする必要があります。特徴量プラットフォームは、新しい特徴量を定義する際にこれらの変換を自動的にランし、開発プロセスにおける高速なイテレーションサイクルを可能にします。

特徴量ストア
フィーチャーストアは、2017年に Uber Michelangelo で初めてそのコンセプトが紹介されて以来、ますます人気が高まっています。それらには2つの目的があります。オフラインのトレーニング環境とオンラインの推論環境にわたって一貫して特徴量を保存し、提供することです。
フィーチャーが両方の環境で一貫して保存されていない場合、モデルのトレーニングに使用されるフィーチャーと、オンライン推論に使用されるフィーチャーとの間に微妙な違いが生じる可能性があります。この現象は train-serve スキューと呼ばれ、デバッグが非常に困難な、静かで壊滅的な方法でモデルのパフォーマンスを低下させる可能性があります。両方の環境で一貫したデータを持つことで、Feature Storeはこの問題を解決します。
オフラインでのトレーニングのために、Feature Storeは数ヶ月または数年分のデータを含む必要があります。これらは、S3、BigQuery、Snowflake、Redshiftなどのデータウェアハウスやデータレイクに保存されます。これらのデータソースは、大規模な取得に最適化されています。
オンライン推論の場合、アプリケーションは少量のデータに超高速でアクセスする必要があります。低レイテンシのルックアップを可能にするため、このデータは DynamoDB、Redis、Cassandra などのオンライン ストアに保持されます。オンラインストアには、各エンティティの最新の特徴量値のみが保持されます。

オフラインでデータを取得する場合、一般的にノートブックで使いやすい SDK を通じて特徴量値にアクセスします。オンライン推論では、Feature Storeは最新のデータを含む単一の特徴量ベクトルを提供します。これらの各リクエストのデータ量は少ないですが、特徴量ストアは1 秒あたり数千件のリクエストまでスケールできる必要があります。これらのレスポンスは、REST エンドポイントを介して、ライブアプリケーションにミリ秒単位で提供されます。パフォーマンスの高いFeature Storeは、可用性とレイテンシに関する SLA を提供する必要があります。

モニタリング
運用中の機械学習システムで何か問題が発生した場合、それは通常、データの問題です。フィーチャープラットフォームは生データからモデルまでのプロセスを管理するため、データの問題を検出するのに最適な立場にあります。フィーチャープラットフォームがサポートするモニタリングには、2つのタイプがあります。
データ品質監視
特徴量プラットフォームは、入力データの分布と品質を追跡できます。モデルを前回トレーニングしてから、データの分布に大幅な変化はありますか?欠損値が突然増えていませんか?これはモデルのパフォーマンスに影響を与えていますか?
運用モニタリング
本番運用システムを運用する際には、運用メトリクスを監視することも重要です。特徴量プラットフォームは、特徴量の鮮度を追跡して、データが期待されるレートで更新されていないことを検出するとともに、特徴量ストレージに関連するその他のメトリクス(可用性、容量、使用率)やfeature servingに関連するメトリクス(スループット、レイテンシー、秒間クエリー数、エラー率)も追跡します。特徴量プラットフォームは、特徴量パイプラインがジョブを期待どおりに実行しているかを監視し、ジョブが成功していないことを検出して、問題を自動的に解決します。
特徴量プラットフォー��ムは、既存のモニタリングインフラストラクチャでこれらのメトリクスを利用できるようにします。運用中の 機械学習 アプリケーションは、既存のオブザーバビリティツールで管理される他の本番運用アプリケーションと同様に、追跡する必要があります。
まとめ
フィーチャー プラットフォームの魅力の一部は、機械学習 チームが新しいフィーチャーを迅速に本番環境に導入できることです。しかし、価値が爆発的に高まるのは、フィーチャー プラットフォームが複数のチームによって使用され、複数のユースケースをサポートするようになったときです。

特徴量プラットフォームを利用することで、データエンジニアはこれまでよりも多くのデータサイエンティストをサポートできるようになります。特徴量プラットフォームがないと、1人のデータサイエンティストをサポートするのに2人のデータエンジニアが必要になる、と多くのチームから聞いています。特徴量プラットフォームによって、彼らはその比率を大幅に逆転させることができました。特徴量プラットフォームが広く採用されると、データサイエンティストはすでに計算されている特徴量を自分のモデルに簡単に追加できます。私たちは同じパターンが繰り返されるのを見てきました。チームが最初のユースケースを完全にデプロイするのに数か月、2 番目のユースケースには数週間かかり、その後�は新しいユースケースのデプロイや既存のユースケースのイテレーションにはわずか数日しかかからなくなります。
特徴量プラットフォームを導入すべき時とそうでない時
この記事の冒頭で、ここ数年で登場したMLOpsツールのエコシステム全体に追いつくのがいかに難しいかを説明しました。現実には、スタックをできるだけシンプルに保ち、ツールは本当に必要なときにのみ採用すべきです。
チームが特徴量プラットフォームに価値を見出すのは、次のような場合です。
- データサイエンティストとデータエンジニア間の引き継ぎプロセス、および本番運用用にデータパイプラインを再実装する際の苦痛を経験している。
- 厳格なSLAを満たし、スケールを達成し、本番運用で停止することが許されない、運用機械学習アプリケーションをデプロイしている。
- 複数のチームが、標準化された特徴量の定義を持ち、モデル間で特徴量を再利用したいと考えている。
チームは次のような場合に特徴量プラットフォームの導入を避けるべきです。
- アイデア出しや開発の段階にあり、本番運用にリリースする準備ができていない。
- バッチ データのみを扱う単一のチームしかいない。
使用方法
始めるには、いくつかの選択肢があります。
- Tectonは、マネージド特徴量プラットフォームです。これには上記のすべてのコンポーネントが含まれており、顧客がTectonを選ぶのは、ソリューションを自社で管理する必要がなく、本番運用のSLAとエンタープライズ機��能が必要だからです。Tectonは、技術系Startupから複数のFortune 500企業まで、さまざまな機械学習チームに利用されています。
- Feast は、最も人気のあるオープンソースのフィーチャー ストアです。すでにフィーチャーをコンピュートするための変換パイプラインがあり、それらのフィーチャーを本番運用で保存および提供したい場合に最適なオプションです。今後、Feast はフィーチャー パイプラインとモニタリング機能を追加し続け、完全なフィーチャー プラットフォームになるでしょう。
本ブログ記事は、現在、運用機械学習アプリケーション用スタックの中核コンポーネントとして定着したフィーチャープラットフォームの共通定義を提供するために執筆しました。
最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。