メインコンテンツへジャンプ
構造化ストリーミングとは何ですか?
バッチ処理に使用するのと同じ Spark API を使用してリアルタイム データを処理する方法を学びます
によって Databricks Staff による投稿
- 構造化ストリーミングとは何か、そしてApache Sparkでストリーム処理のための高レベルAPIをどのように提供するのかを理解しましょう。
- 最小限のコード変更でバッチジョブをストリーミングに変換し、レイテンシを削減し、増分処理を実現する方法を学びましょう。
- 使い慣れたSpark構造化APIを使用することで、構造化ストリーミングがリアルタイムデータ処理を簡素化する方法を探ります。
構造化ストリーミングとは、Spark 2.2 以降で実運用が可能となった、ストリーミングデータ処理向けの高レベル API です。構造化ストリーミングでは、Spark の構造化 API を使用してバッチモードで実行するのと同じ操作が、ストリーミング形式で実行可能です。これにより、レイテンシの短縮、インクリメンタル処理が可能になります。構造化ストリーミングの最大のメリットは、事実上コードを変更することなく、ストリーミングシステムから迅速に価値を引き出し、AI(人工知能)によるリアルタイム分析や予測に活用できる点です。また、バッチジョブをプロトタイプとして記述し、それをストリーミングジョブに変換できるため、推論も容易になります。これはデータを段階的に処理することで可能になります。 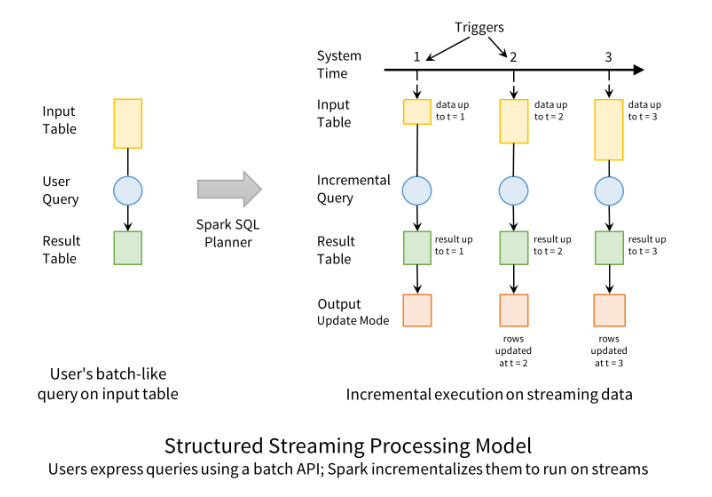
FAQ
1. 構造化ストリーミングとは何ですか?
Apache SparkのAPIの一つで、バッチ処理と同じ構文でストリーミングデータを扱える仕組みです。リアルタイム処理やAI連携に適しています。
2. 構造化ストリーミングはAIとどう関係しますか?
ストリーミングデータを即時に処理し、人工知能モデルの推論や特徴量更新に利用することで、リアルタイムAIを実現できます。
3. 従来のストリーミング処理との違いは何ですか?
バッチ処理と統一されたAPIにより、実装や運用が簡単で、AI分析基盤への統合が容易な点が大きな違いです。
レポート
エンタープライズ向けエージェントAIプレイブック

最新の投稿を受信トレイで受け取る
ブログを購読して、最新の投稿を受信トレイにお届けします。