ノーコードのデータサイエンスと機械学習
データサイエンスを組織全体に普及させ、全員がデータドリブンな意思決定を行えるようにします。

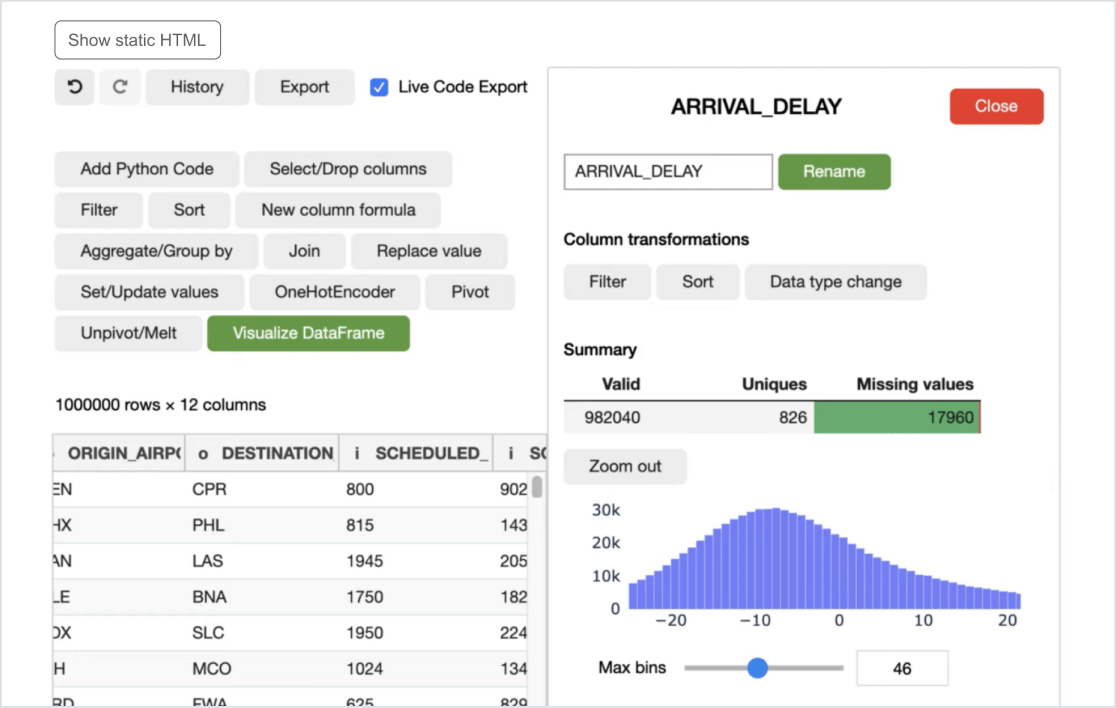
企業の信頼性と規模を備えた市民向けツール データサイエンティスト
Databricks 膨大で複雑なデータセットの分析、知見の発見、予測をわずか数クリックで行うことができます。 コードを1行も書くことなく、データを整理、変換、視覚化できます。
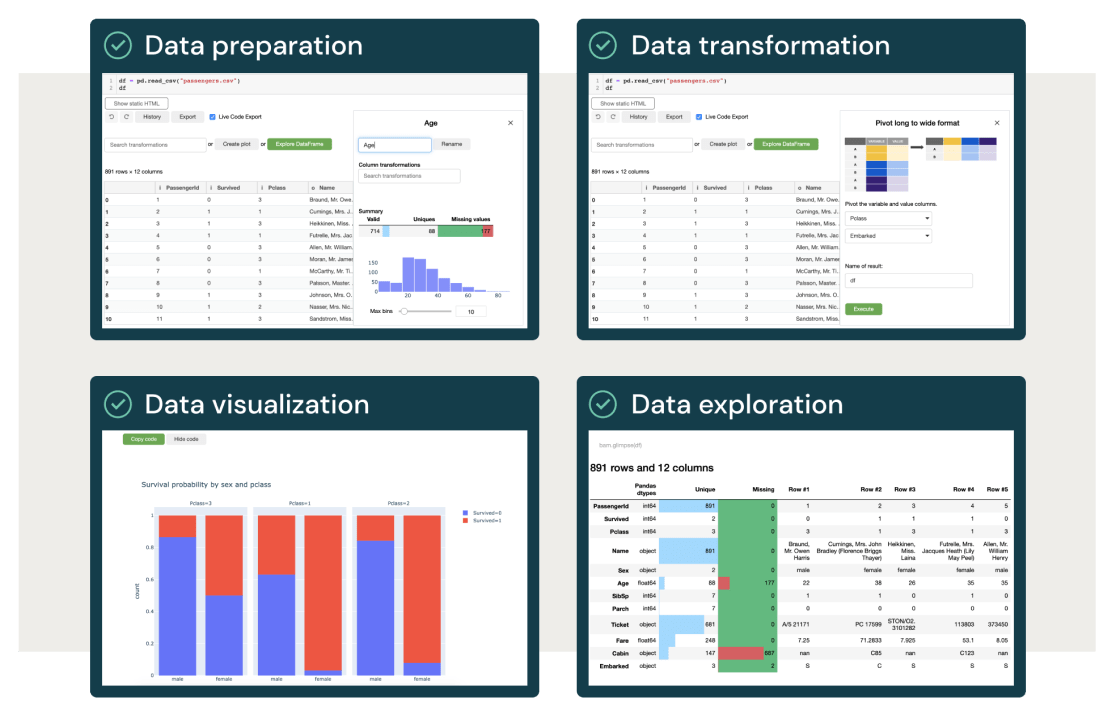
非エンジニアのためのデータエンジニアリング
機械学習はデータエンジニアリングから始まります。 コードを書くことなく、データの準備、変換、可視化、探索的データ分析ができるようになりました。 Databricksを使えば、組織内の誰でも、あらゆる下流のユースケースに対応するデータを準備することができます。
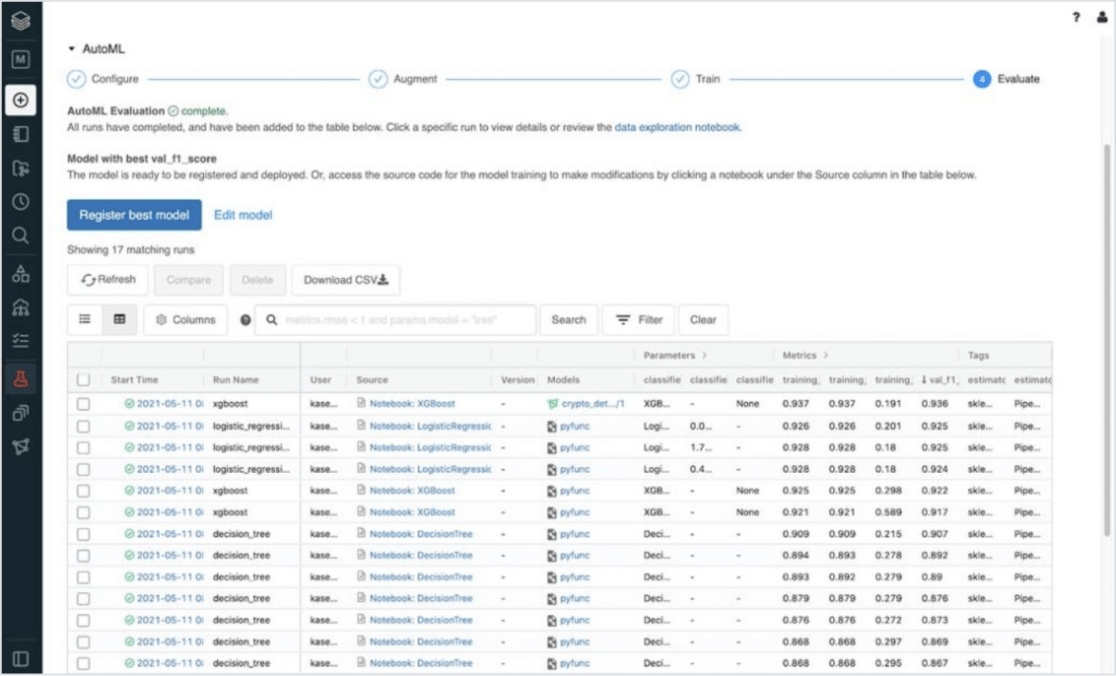
機械学習の完全自動化
Databricks AutoMLは、市民データサイエンスにグラスボックス型のアプローチを提供し、前処理、フィーチャーエンジニアリング、モデルのトレーニングおよびチューニングといった重労働を自動化することで、機械学習モデルの迅速な構築、トレーニング、デプロイを可能にします。 UIを離れることなく、データセットのインポート、トレーニングの設定、モデルのデプロイを行うことができます。
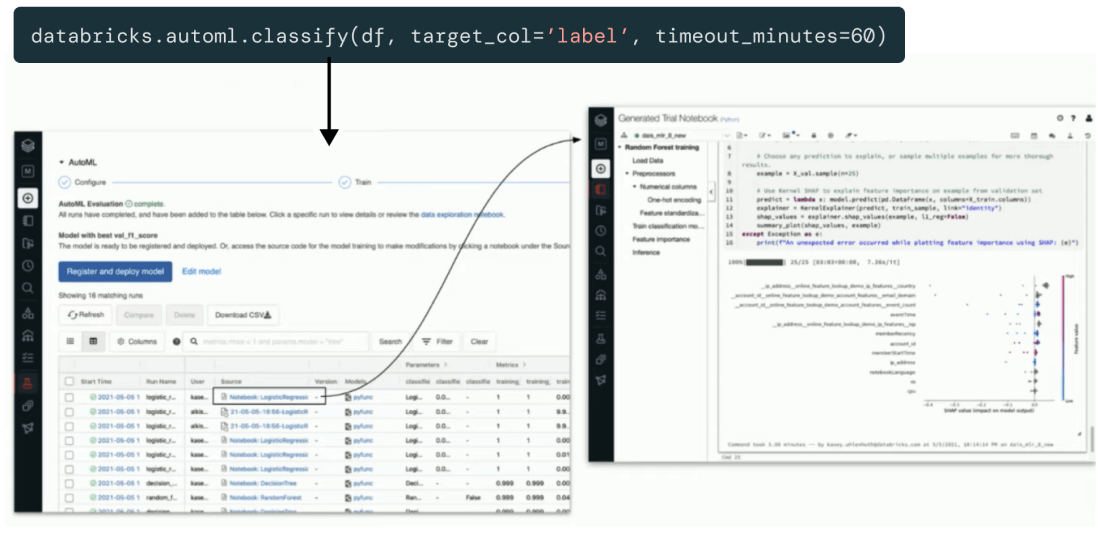
透明性と視認性により、必要なときに近くで見ることができます。
Databricks Machine Learning 独自の機能として、UIで実行されるすべてのステップで、本番レベルのコー��ドが生成されます。
専門家のデータサイエンティストや機械学習エンジニアは、このコードを検査し、独自のカスタマイズを加えることができます。また、規制当局は、再現性と透明性が重要な場合に、IT を参照することができます。 Databricks Machine Learning はMLflowとネイティブに統合されており、前処理、フィーチャーエンジニアリングからトレーニング、デプロイメントに至るまで、きめ細かな実験のトラッキングとバージョン管理が可能です。
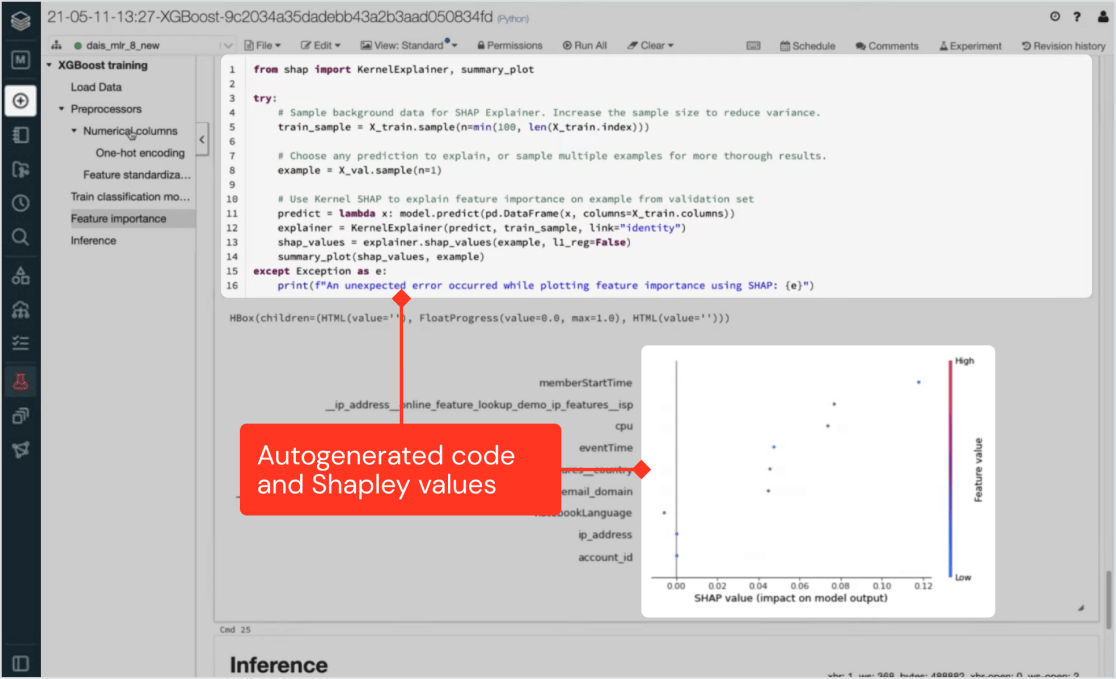
部門横断的なコラボレーションのために説明可能でコンプライアンスに準拠
Databricks は、完全なリネージ追跡と自動生成コードの登録をサポートすることで、すべてのデータサイエンスプロジェクトの安全性、コンプライアンス、トレーサビリティを保証します。 説明可能性の特徴は、どの入力が生成されたモデルに最も関係しているかを知見します。 これにより、ユーザーからデータサイエンティスト、機械学習エンジニア、IT 、法務、コンプライアンスに至るまで、さまざ�まなチームがコラボレーションできる基盤が構築されます。
関連リソース
eBook
ドキュメント
ソリューション
Ready to get started with Databricks?